

malyshkin_ve_korneev_vd_-_parallelnoe_programmirovanie_multikompyuterov
.pdfисполнения ресурсов, включая ПЭ, входной и
выходной буферы.
PARDO M,I
READ (10'I) A
READ (20'I) B
PASS 0, A, I, AAP, MIN
PASS 0, B, I, BAP, MIN
Считываются во входной буфер входные данные формируемого процесса и пересылаются в память ПЭ.
EID
Как только I-й процесс исполнит оператор EID,
(I+1)-й процесс сможет использовать входной буфер для ввода своих данных в память управляющей ЭВМ
CALL VADD (AAP, 1, BAP, 1, CAP, 1, M)
Программа VADD I-го процесса загружается в ПЭ для исполнения, но не исполняется.
WAITR
PASS I, CAP, 0, C, MIN
EXEC
WAITP
WRITE (30'I) C
BOD
178
Как только I-й процесс исполнит оператор BOD, (I+1)-й процесс сможет использовать выходной буфер.
PAREND
Выполнение фрагмента программы от PARDO до
PAREND происходит следующим образом. Вначале вводятся входные данные I-го процесса в память управляющей ЭВМ и вводятся в память ПЭi. Затем
формируется |
программа I-го процесса и вводится |
|||
в |
память |
ПЭi. |
Сформируется |
следующая |
результирующая программа I-го процесса в памяти
ПЭ (понятно, что вместо параметров заданы их значения):
PASS 0, A, I, AAP, MIN
PASS 0, B, I, BAP, MIN
EID
VADD (AAP, 1, BAP, 1, CAP, 1, M)
WAITR
PASS I, CAP, 0, C, MIN
По оператору EXEC программа I-го процесса запускается на счет, а программа управляющей ЭВМ “зависает” в ожидании на операторе WAITPR.
Программа I-го процесса начинается с выполнения операторов PASS, пересылающих входные данные I-
179
го процесса в ПЭi. Затем исполняется оператор
EID. Оператор сообщит управляющей ЭВМ, что I-й
процесс освободил входной буфер, он может быть использован (I+1)-м процессом для ввода своих данных. Когда программа I-го процесса завершит выполнение оператора EID, начнется исполнение
программы VADD в ПЭi, а параллельно с этим управляющая ЭВМ начнет исполнение (I+1)-й
итерации цикла PARDO-PAREND. При этом
незавершенная I-я итерация составляет ожидающий процесс, который продолжит исполнение после выполнения условия ожидания.
Далее, (I+1)-я итерация цикла PARDO-
PAREND |
введет |
входные |
данные |
(I+1)-го |
|
процесса, |
сформирует |
программу |
(I+1)-го |
||
процесса |
в памяти ПЭi+1. Предположим, что |
|
выходной |
буфер еще |
занят I-м процессом. Будет |
сформирована только |
частичная программа, потому |
|
что выходной буфер |
к этому моменту не может |
|
быть захвачен: |
|
|
PASS 0, A, I+1, AAP, MIN
PASS 0, B, I+1, BAP, MIN
EID
Оператор EID стартует выполнение программы
(I+1)-го процесса в памяти ПЭi+1. Параллельно с
180
работой I-го процесса (I+1)-й процесс введет свои входные данные из памяти управляющей ЭВМ в память ПЭi+1. Если к этому моменту выполнение I-
го процесса в ПЭi не завершилось, то (I+1)-й
процесс выполнит оператор EID и зависнет на ожидании освобождения выходного буфера I-м
процессом. Параллельно может стартовать (I+2)-я
итерация цикла PARDO-PAREND, которая начнет работу по формированию (I+2)-го процесса. Когда
I-й процесс исполнит оператор BOD, тогда может продолжиться приостановленное исполнение (I+1)-
яитерация цикла. Продолжится формирование
(I+1)-го процесса, в памяти |
ПЭi+1 будет |
доформирован следующий фрагмент программы
(I+1)-го процесса:
VADD (AAP, 1, BAP, 1, CAP, 1, M)
WAITR
PASS I+1, CAP, 0, C, MIN
и начнется исполнение этого фрагмента в ПЭi+1.
Каждый процесс pi программы состоит из фрагментов in1
-ввод данных в память управляющей ЭВМ, put1 - передача входных данных из памяти управляющей ЭВМ в память ПЭ, run1
-исполнение программы в ПЭ, geti - передача результата из памяти ПЭ в память управляющей ЭВМ, outi - пересылка данных
181
из памяти управляющей ЭВМ во внешнюю память. Временнáя
диаграмма (рис. 5.11) исполнения системы процессов может
выглядеть так:
ПЭi+2 |
|
|
|
|
pi+2 |
|
ini+2 |
put |
runi+2 |
geti+2 outi+2 |
|
|
|
||||
ПЭi+1 |
|
|
|
pi+1 |
|
ini+1 |
puti+1 |
runi+1 |
geti+1 outi+1 |
|
|
|
|
||||
ПЭi |
|
|
pi |
|
pi+3 |
|
|
ini+3 puti+3 |
runi+3 geti+3 outi+3 |
||
|
ini put runi geti outi |
|
|||
Рис. 5.11.
Как видим, наличие одного входного и одного выходного буферов в памяти управляющей ЭВМ уже делает возможным параллельное исполнение системы процессов (конечно при условии, что время работы ПЭ заметно больше времени ввода/вывода входных/выходных данных процессов).
в) С использованием операторов SECT - захватить некоторый ресурс - и POST - освободить ранее захваченный ресурс,
разделение ресурсов может быть выполнено еще более эффективно.
Первая половина программы совпадает с
программой примера б).
Памяти хватает только для одного входного и
одного выходного буферов.
182
PARDO M, I
SECT
Некоторый ресурс захвачен, здесь на самом деле имеется ввиду входной буфер.
I-ый процесс продолжает выполнение, вводя свои входные данные в захваченный буфер. (I+1)-ый процесс должен будет здесь задержаться, т.к.
нет другого экземпляра этого ресурса.
READ (10'I) A
READ (20'I) B
PASS 0, A, I, AAP, MIN
PASS 0, B, I, BAP, MIN
POST
Входные данные пересданы в ПЭ, входной буфер свободен и его можно освободить для использования другим процессом.
CALL VADD (AAP, 1, BAP, 1, CAP, 1, M)
CALL APWR
SECT
Захвачен выходной буфер
PASS I, CAP, 0, С, MIN
Как только I-й процесс пройдет SECT, (I+L)-й
процесс может выполняться до оператора SECT,
используя тот же процессор
EXEC
183
WRITE (30'I) C
POST
Выходной буфер освободился
PAREND
Структура коммутаций крупноблочного иерархического линейного мультикомпьютера фиксирована и это позволяет обеспечивать переносимость прикладных программ, написанных на Ине также тем, что оператор PASS, определяющий взаимодействие между процессами, реализуется по разному в зависимости от реализации межпроцессорного интерфейса:
каналов, общая шина или общая электронная память. Поэтому прикладные программы, в которых обмен реализуется только через каналы с синхронизацией процессов в момент обмена,
будут исполняться без изменений и в мультикомпьютере, в
котором возможен обмен через общую память, причем обмен будет выполнен уже асинхронно.
184
VI. ОТОБРАЖЕНИЕ АЛГОРИТМОВ НА РЕСУРСЫ МУЛЬТИКОМПЬЮТЕРА
Одной из наиболее сложных проблем организации параллельных вычислений на мультикомпьютере, от качества решения которой существенно зависит качество исполнения параллельной программы, является распределение ресурсов вычислителя. Один из вариантов динамического решения этой проблемы был рассмотрен в предыдущей главе.
6.1.Статическая задача
Проблема формулируется как задача отображения алгоритма в/на ресурсы мультикомпьютера. Предполагается, что программа представляется множеством программ процессов,
связанных передачами данных (взаимодействиями), и
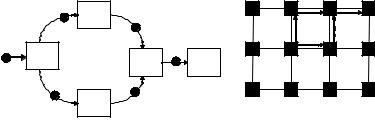
изображается ориентированным графом процессов (рис. 6.1.а).
Если структура коммутационной сети мультикомпьютера образует, к примеру, двумерную решетку, то массовый алгоритм на рис. 6.1.а мог бы быть отображен в мультикомпьютер так, как это показано на рис. 6.1.б. Для обеспечения конвейерного исполнения массового алгоритма каждая операция назначается на исполнения на отдельный процессор, причем непосредственно информационно зависимые операции должны быть назначены на процессоры, связанные физическими линками
(коммутационными каналами).
Параллельная программа составляется из фрагментов,
каждый из которых определяет программу выполнения процесса.
185
Эти фрагменты загружаются в процессорные элементы мультикомпьютера в соответствии с отображением М и
запускаются на исполнение. Компилятор системы программирования должен уметь формировать процессы, строить отображение М и определять загрузку программ процессов в ПЭ мультикомпьютера в соответствии с этим отображением. При переносе параллельной программы на другой мультикомпьютер
(с другим числом ПЭ и другой коммутационной сетью)
отображение М должно строиться заново. Таким образом, именно алгоритмы конструирования отображения М в первую очередь ответственны за обеспечение переносимости параллельной программы.
y[i] |
|
|
b |
d |
e |
b |
t[i] |
|
|
|
|
|
|
|
|
||
x[i] |
|
|
a |
c |
|
|
|
|
|
|
|
a |
|
d |
e |
|
|
|
|
|
|
||
|
|
|
r[i] |
|
|
z[i] |
c |
s[i] |
|
|
|
|
|
|
|
||
|
|
Рис. 6.1.а |
|
|
Рис. |
Отображение М может сопоставлять некоторому ПЭ (назначать на ПЭ) более одного процесса.
Для достижения хорошего качества параллельной программы отображение М должно обладать рядом полезных свойств.
186
Свойство 1. Взаимодействующие процессы должны отображаться в один и тот же ПЭ либо в соседние ПЭ (связанные физическими линками).
Свойство 2. Все ПЭ должны быть загружены работой примерно одинаково, одновременно начинать работу и одновременно ее завершать.
∙Замечание 1. Как обычно, качество отображения М оценивается некоторым функционалом. Время выполнения параллельной программы Т, потребляемые ресурсы R
мультикомпьютера могут служить примерами такого функционала. Свойства 1 и 2 одновременно выполнимы с приемлемым качеством далеко не всегда. Всегда, однако,
существуют отображения, удовлетворяющие свойствам 1 и 2,
но мало пригодные в практике. Например, отображение всех процессов в один ПЭ существует всегда. Практической пользы от этого отображения немного. Распараллеливаются обычно большие программы и ресурсов одного ПЭ, как правило,
недостаточно для ее исполнения. Другая крайность, когда для исполнения конкретной программы собирается мультикомпьютер, в котором для выполнения каждой операции алгоритма есть отдельный процессор, а для реализации каждого взаимодействия - свой неразделяемый линк. Такое отображение также удовлетворит обоим условиям, но для реализации алгоритма понадобится слишком
187