

malyshkin_ve_korneev_vd_-_parallelnoe_programmirovanie_multikompyuterov
.pdfDO 50 K=1,10
J=MOD(K, NP)+1
Подпрограмма MOD вырабатывает значение kmod(NP), таким образом 1≤ j ≤NP.
CALL SET (J)
Текущим ПЭ объявлен процессор с номером J. Все последующие подпрограммы PUT, PRODUCT, WR, GET
- не немедленно исполняемые, они дишь
формируют работу для ПЭ и начнут реально исполняться только по команде START.
CALL PUT (V(*, K), IV, ... ) |
|
CALL PUT (W(*, K), IW, ...) |
|
Пересылаются в ПЭJ значения K-ых |
столбцов |
матриц V и W в массивы IV и IW |
памяти ПЭ |
соответственно. |
|
CALL PRODUCT (IV, IW, IC, ...)
Вычисляется скалярное произведение k-ой пары векторов.
CALL WR
Ожидание завершения счета в ПЭ
CALL GET (IC, C(K))
Значение K-го скалярного произведения
пересылается из ПЭ в управляющую ЭВМ
168
Вот теперь программа работы ПЭ сформирована и
ее можно запустить на счет
50 CALL START
Сформированная программа ПЭ выполняется без участия управляющей ЭВМ средствами ПЭ. Поэтому управляющая ЭВМ
после запуска программы START начнет исполнение
следующей итерации цикла, чтобы загрузить работой следующий ПЭ.
5.5.3. Централизованное управление
Централизованный монитор имеет все описанные выше подпрограммы. Организация монитора другая и функций он может выполнять больше. В момент старта монитор захватывает монопольно все доступные ПЭ, а затем выделяет их прикладным задачам по их запросам. Если запрошенное число свободных ПЭ имеется в наличии, монитор выделяет их задаче, а если нет -
ставит запрос в очередь, которая обслуживается по известным дисциплинам. За счет централизованного сбора информации о состоянии ресурсов мультикомпьютера не возникает неоправданных задержек программ. Кроме того гарантируется,
что стартовавшая задача получит все необходимые ресурсы и сможет исполниться, минимизируются простои как программ,
так и ПЭ.
169
Запросы монитора устроены сложно, можно сформулировать из задачи требование на предоставление ПЭ,
связанных каналами в кольцо, или на кластер, потребовать,
чтобы в каждом выделенном ПЭ память данных была, к примеру,
не менее 64 Мбайт и т.п.
Монитор имеет очень важную для эксплуатации многокомпонентного мультикомпьютера подсистему обеспечения надежности вычислений и живучести всего мультикомпьютера. Для поддержки работоспособности мультикомпьютера монитор периодически либо по аварийным ситуациям проводит тестирование компонент мультикомпьютера разной сложности, своевременно выводит из состава мультикомпьютера дефектные устройства и сообщает об ошибках. Каждой задаче по ее запросу монитор выдает работоспособные на момент удовлетворения запроса ресурсы мультикомпьютера.
5.5.4.Язык и система параллельного программирования Иня
Для реализации линеаризованных алгоритмов разработаны язык и система сборочного параллельного программирования Иня. Язык Иня - это расширение Фортрана, в
Фортран добавлены операторы PARDO, PAREND, операторы для работы с ресурсами мультикомпьютера и описания
170
взаимодействий между процессами, а также набор вспомогательных подпрограмм подготовки данных для процессов.
Операторы PARDO и PAREND определяют участок программы, в котором формируется процесс: готовятся данные процесса (вводятся, переформируются), создается программа для ПЭ (набирается из готовых подпрограмм), организуются вычисления (захватываются ПЭ, загружаются работой,
выполняются взаимодействия между процессами, выгружаются результаты и т.д.).
Программа в Ине компонуется из готовых подпрограмм
так же, как и сам мультикомпьютер. Язык Иня предназначен не столько для определения вычислений, сколько для их организации. Конкретные вычисления (модули, процедуры)
задаются с использованием систем программирования,
существующих в математическом обеспечении вычислителей из состава мультикомпьютера.
Взаимодействия между процессами определяются в Ине оператором PASS, ожидания - оператором WAIT, точки захвата и освобождения ресурсов и требования на них указываются
операторами EID, BOD, SECT, POST. Предусмотрено также
большое число процедур для преобразования данных,
подготавливаемых для передачи |
в ПЭ. При исполнении |
|
параллельной |
программы Иня |
обеспечивает совмещение |
171
всевозможных работ, разделение таких ресурсов
мультикомпьютера, как ПЭ и оперативная память управляющей ЭВМ, настройку на доступные ресурсы мультикомпьютера.
Структура коммутации крупноблочного иерархического линейного мультикомпьютера фиксирована, и это позволяет обеспечивать переносимость прикладных программ, написанных на Ине также тем, что оператор PASS, определяющий взаимодействие между процессами, реализуется по разному в зависимости от имеющихся в мультикомпьютере на момент исполнения параллельной программы средств реализации межпроцессорных взаимодействий: каналов, общая шина или общая электронная память. Поэтому прикладные программы, в
которых обмен реализуется только через каналы с синхронизацией процессов в момент обмена, будут исполняться без изменений и в мультикомпьютере, в которой возможен обмен через общую память, причем обмен будет выполнен уже асинхронно.
Чтобы разобраться со средствами программирования языка ИНЯ, рассмотрим несколько различных параллельных программ решения одной и той же задачи.
Пусть необходимо поэлементно суммировать два вектора большой длины MAX, расположенные на внешнем устройстве.
Векторы делятся на отрезки равной длины, которые
172
суммируются параллельной в ПЭ. Число элементов вектора,
обрабатываемых в одном процессе (длина отрезка), обозначается
MIN, MIN << MAX. Длина отрезка выбирается таким образом,
чтобы поместиться в памяти одного ПЭ. Число отрезков, на которые разбиваются векторы для обработки, а следовательно, и
число параллельных процессов, равно M=MAX/MIN.
Для ввода/вывода данных в/из управляющей ЭВМ используются входные/выходные буферы в оперативной память управляющей ЭВМ. Каждый входной/выходной буфер содержит все входные/выходные данные процесса. Исполнение программы в управляющей ЭВМ образует процесс с номером 0, остальные процессы нумеруются 1, 2, ... , k. Там, где это необходимо, мы будем в примерах для определенности предполагать, что мультикомпьютер имеет 3 ПЭ.
а).Пусть допускается использование только одного входного и одного выходного буферов.
Тогда программа имеет вид:
DIMENSION A(MIN), B(MIN), C(MIN)
A и B - векторы-слагаемые, C - вектор-сумма,
BUF содержит три отрезка векторов длины MIN -
два входных отрезка и один выходной. Таким образом, массив BUF может рассматриваться как один входной и один выходной буферы.
173
M = MAX/MIN + 1
Число процессов равно числу отрезков
SET 1, M
Оператор SET требует захватить от 1 до M ПЭ
PARDO M, I
Оператор PARDO определяет начало цикла, число итераций цикла равно M, I - параметр цикла,
изменяющийся от 1 до M, I-я итерация цикла формирует I-ый процесс. Захватывается ПЭ для исполнения I-ого процесса.
READ (10'I) A
Считываются I-ые отрезки векторов в память
управляющей ЭВМ
PASS 0, A, I, AAP, MIN
Оператор PASS пересылает данные из массива A
старшего процесса (с номером 0) в I-й
подчиненный процесс в массив AAP, размещенный в памяти ПЭ. Количество передаваемых элементов массива равно MIN. Оператор PASS не исполняется немедленно, он включается в программу формируемого процесса и будет исполнен после ее запуска.
READ (20'I) B
174
PASS 0, B, I, BAP, MIN
CALL VADD (AAP,1,BAP,1,CAP,1,M)
Процедура VADD вычисляет поэлементную сумму векторов A и B, результат C содержится в массиве CAP в памяти ПЭ. VADD не исполняется немедленно, процедура VADD включается в программу формируемого процесса.
WAITR
Оператор WAITR ожидает завершения счета VADD
в ПЭ, он тоже не исполняется немедленно, а
включается в состав программы процесса.
PASS I, CAP, 0, C, MIN
Оператор PASS пересылает результат из I-го подчиненного процесса в старший процесс.
EXEC
Сформированная программа процесса запускается
на счет в этом ПЭ. Далее может продолжиться формирование программы процесса на фоне счета ее первой части в ПЭ.
WAITP
В управляющей ЭВМ ожидается конец счета в ПЭ,
чтобы продолжить дальнейшую обработку результата в управляющей ЭВМ
WRITE (30'I) C
175
Отрезок результирующего вектора записывается на
внешнее устройство
PAREND
Происходит переход к формированию программы (I+1)-го
процесса
END
Так как имеется только по одному неразделяемому входному и выходному буферу, то процессы выполнятся строго последовательно,
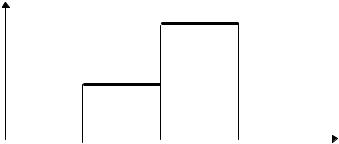
хотя и будут последовательно использованы несколько ПЭ. Схематически исполнение процессов на 3-х ПЭ показано на временной диаграмме
(рис. 5.10).
I-ый сформированный процесс захватывает очередной ПЭ по схеме роллинга и исполняется на нем, остальные ПЭ простаивают, так как они не могут ввести свои входные данные.
Таким образом, исполнение программы происходит фактически последовательно.
176
ПЭ
ПЭ3
ПЭ2
ПЭ1 |
|
|
|
|
|
t |
|
|
|
|
|
||
|
|
|
Рис. 5.10. |
|||
б) С использованием операторов EID и BOD, указывающих особые точки процессов, эта же задача может быть решена значительно более эффективно. В этом примере оператор EID
отмечает точку в программе формирования процессов, после которой входной буфер процессом освобождается, а BOD
указывает, что с этого момента выходной буфер захвачен процессом. Теперь можно реально организовать вычисления на нескольких ПЭ с использованием лишь одного входного и одного выходного буферов.
Начало программы совпадает с программой примера а). Памяти управляющей ЭВМ хватает для размещения только для одного входного и одного выходного буферов. Каждый процесс начинает исполнение с захвата необходимых для его
177