

Object 21
Лабораторные по курсу оптимизация БД Oracle номер 6
1. Выполните скрипт join_setup.sql из-под учётной записи пользователя SYS.
|
|
|
|
|
|
|
|
|
|
|
|
join_setup.sql |
-- execute as sys user |
|
|
|
|
|
|
|
|||||
GRANT |
|
|
ANY |
|
|
|
|
|
|
|||
SELECT |
|
dictionary |
TO |
OE; |
||||||||
GRANT |
select |
_ |
catalog_role |
TO |
OE; |
|
||||||
GRANT |
|
|
|
|
||||||||
SELECT |
|
ANY |
dictionary |
|
TO |
SH; |
|
|||||
GRANT |
select |
_ |
catalog_role |
TO |
SH; |
|
||||||
EXIT |
; |
|
|
|
|
|
|
|
|
|
|
|
2.Подключитесь к схеме пользователя SCOTT и далее выполняйте запросы под этой учётной записью, пока не будет сказано иначе.
3.Соединение вложенными циклами (Nested Loop Join)
a. Выполните трассировку (autotrace) запроса small_tables_join.sql дважды - для загрузки буферного кэша.
(1) Приведите скриншот второго плана выполнения и статистики, отметьте стоимость и число логических чтений.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
small_tables_join.sql |
||||
SELECT |
ename |
, |
e.deptno |
, |
d.deptno |
, |
d.dname |
|
|
|
||||||||||
FROM |
emp e |
, |
dept |
d |
|
|
|
|
|
|
|
|
|
|
|
|||||
WHERE |
|
e.deptno |
= |
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
d.deptno |
AND |
ename |
LIKE |
'A%' |
; |
||||||||||||
b. Очистите буферный кэш
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;

и выполните трассировку запроса с добавлением хинта USE_HASH (small_tables_hash_join.sql).
(2) Приведите скриншот плана выполнения и статистики, прокомментируйте основные различия.
|
|
|
|
|
|
|
|
|
|
|
small_tables_hash_join.sql |
|
|||||||||
SELECT |
/*+ USE_HASH(E D) */ ename |
, |
e.deptno |
, |
d.deptno |
, |
d.dname |
||||||||||||||
FROM |
emp e |
, |
dept |
d |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
WHERE |
|
e.deptno |
= |
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
d.deptno |
AND |
ename |
LIKE |
'A%' |
; |
|||||||||||||
c.Снова очистите буферный кэш
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;

и выполните трассировку запроса с добавлением хинта USE_MERGE (small_tables_merge_join.sql).
(3) Приведите скриншот плана выполнения и статистики, прокомментируйте основные различия.
|
|
|
|
|
|
|
|
|
|
|
small_tables_merge_join.sql |
|
||||||||
SELECT |
/*+ USE_MERGE(E D) */ ename |
, |
e.deptno |
, |
|
d.deptno |
, |
d.dname |
||||||||||||
FROM |
emp e |
, |
dept |
d |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
WHERE |
|
e.deptno |
= |
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
d.deptno |
AND |
ename |
LIKE |
'A%' |
; |
||||||||||||
(4)Какой план, на Ваш взгляд, оказался лучшим и почему?

2задание
4.Подключитесь к схеме пользователя OE и далее выполняйте запросы под этой учётной записью, пока не будет сказано иначе.
5. Соединение слиянием (Merge Join)
a. Выполните трассировку (autotrace) запроса oe_query.sql дважды - для загрузки буферного кэша.
(1) Приведите скриншот второго плана выполнения и статистики, отметьте стоимость и число логических чтений.
|
|
|
|
|
|
|
|
|
oe_query.sql |
SELECT |
* |
|
|
|
|
|
|
|
|
FROM |
orders h |
, |
order_items l |
|
|
||||
WHERE |
l.order |
_ |
id |
= |
h.order_id; |
|
|||
b. Очистите буферный кэш
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
и выполните трассировку запроса с добавлением хинта USE_HASH (oe_query_hash.sql).

(2) Приведите скриншот плана выполнения и статистики, прокомментируйте основные различия.
oe_query_hash.sql
SELECT /*+ USE_HASH(h l) */ *
FROM orders h, order_items l WHERE l.order_id = h.order_id;
c.Снова очистите буферный кэш
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;

и выполните трассировку запроса с добавлением хинта USE_NL (oe_query_nl.sql).
(3) Приведите скриншот плана выполнения и статистики, прокомментируйте основныеразличия.
oe_query_nl.sql
SELECT /*+ USE_NL(h l) */ *
FROM orders h, order_items l WHERE l.order_id = h.order_id;
(4) Какой план, на Ваш взгляд, оказался лучшим и почему?

3задание
6.Подключитесь к схеме пользователя SH и далее выполняйте запросы под этой учётной записью, пока не будет сказано иначе.
7. Хэш-соединение (Hash Join)
a. Выполните трассировку (autotrace) запроса sh_query.sql дважды - для загрузки буферного кэша.
(1) Приведите скриншот второго плана выполнения и статистики, отметьте стоимость и число логических чтений.
sh_query.sql
SELECT c.cust_first_name, c.cust_last_name, c.cust_id, COUNT(s.prod_id)
FROM sh.customers c, sh.sales s WHERE c.cust_id = s.cust_id
AND c.cust_id < 100
GROUP BY c.cust_first_name, c.cust_last_name, c.cust_id;
BY c.cust_first_name, c.cust_last_name, c.cust_id;

b. Очистите буферный кэш
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
и выполните трассировку запроса с добавлением хинта USE_NL (sh_query_nl.sql).
(2) Приведите скриншот плана выполнения и статистики, прокомментируйте основныеразличия.
SELECT /*+ USE_NL(c s) */
sh_query_nl.sql
c.cust_first_name, c.cust_last_name, c.cust_id, COUNT(s.prod_id)
FROM sh.customers c, sh.sales s
WHERE c.cust_id = s.cust_id
AND c.cust_id < 100
GROUP BY c.cust_first_name, c.cust_last_name, c.cust_id;
BY c.cust_first_name, c.cust_last_name, c.cust_id;

c. Снова очистите буферный кэш
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;

и выполните трассировку запроса с добавлением хинта USE_MERGE (sh_query_merge.sql)
.(3) Приведите скриншот плана выполнения и статистики, прокомментируйте основные различия.
SELECT /*+ USE_MERGE(c s) */
sh_query_merge.sql
c.cust_first_name, c.cust_last_name, c.cust_id, COUNT(s.prod_id)
FROM sh.customers c, sh.sales s
WHERE c.cust_id = s.cust_id
AND c.cust_id < 100
GROUP BY c.cust_first_name, c.cust_last_name, c.cust_id;
BY c.cust_first_name, c.cust_last_name, c.cust_id;
(4) Какой план, на Ваш взгляд, оказался лучшим и почему?
Номер 7
Использование итератора значений списка IN (IN-list Iterator)
Подключитесь к схеме пользователя SH и выполните трассировку (autotrace) запроса query08.sql.
(1) Приведите скриншот плана выполнения и прокомментируйте результат.
|
|
|
|
|
|
|
|
|
|
|
|
|
query08.sql |
SELECT |
c. |
* |
|
|
|
|
|
|
|
|
|
|
|
FROM |
|
customers c |
|
|
|
|
|
|
|
|
|
||
WHERE |
cust_id |
IN |
( |
88340 |
, |
104590 |
, |
44910 |
) |
; |
|
||
Использование хэш-кластеров (Hach Clusters)
Выполните скрипт shc_setup.sql для создания и наполнения схемы SCH. В числе прочего будет
создана таблица BIGEMP_FACT, входящая в однотабличный (single table) хэш-кластер BIGEMP_CLUSTER. Таблица была отсортирована по столбцам deptno и sal перед применением хэшфункции.
shc_setup.sql
-- run with sqlplus /nolog @shc_setup.sql
CONNECT /
/ AS sysdba
AS sysdba
DROP USER shc CASCADE;
USER shc CASCADE;
CREATE USER shc IDENTIFIED BY shc;
GRANT DBA TO SHC;
GRANT select_catalog_role TO SHC;
GRANT SELECT
SELECT ANY dictionary TO SHC;
ANY dictionary TO SHC;
CONNECT shc/shc

SET echo ON
SET linesize 200
DROP CLUSTER bigemp_cluster including tables;
CLUSTER bigemp_cluster including tables;
CREATE CLUSTER bigemp_cluster (deptno NUMBER, sal NUMBER sort)
HASHKEYS 10000
single TABLE HASH IS deptno SIZE 50
TABLESPACE users;
CREATE TABLE bigemp_fact (
empno NUMBER PRIMARY KEY, sal NUMBER sort, job VARCHAR2(12) NOT NULL, deptno NUMBER NOT NULL, hiredate DATE NOT NULL)
CLUSTER bigemp_cluster (deptno, sal);
BEGIN
FOR i IN 1..1400000 LOOP
INSERT INTO bigemp_fact VALUES(i,i,'J1',10,SYSDATE);
END LOOP;
COMMIT;
END;
/
BEGIN
FOR i IN 1..1400000 LOOP
INSERT INTO bigemp_fact VALUES(1400000+i,i,'J1',20,SYSDATE);
END LOOP;
COMMIT;
END;
/
EXEC dbms_stats.gather_schema_stats('SHC');
EXIT
4. Создайте соединение для пользователя SCH со следующими параметрами:
Connection Name: shc Username: shc Password: shc
SID: orcl
Далее используйте это соединение, пока не будет сказано иначе.
5. Выполните скрипт query15a.sql - для задания значений параметров инициализации WORKAREA_SIZE_POLICY
иSORT_AREA_SIZE
иочистки буферного кэша и разделяемого пула.
query15a.sql
SET echo off
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION
SESSION SET sort_area_size=50000;
SET sort_area_size=50000;
ALTER SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;

6.Выполните трассировку (autotrace) запроса query15b.sql.
(1) Приведите скриншот плана выполнения, отметьте время выполнения запроса, стоимость и количество логических чтений. Прокомментируйте результат.
query15b.sql
SELECT *
* FROM bigemp_fact WHERE deptno=10;
FROM bigemp_fact WHERE deptno=10;
7.Снова выполните скрипт query15a.sql.
query15a.sql
SET echo off
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION
SESSION SET sort_area_size=50000;
SET sort_area_size=50000;
ALTER SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;

8.Выполните трассировку (autotrace) запроса query16.sql.
(2) Приведите скриншот плана выполнения и прокомментируйте результат.
query16.sql
SELECT *
* FROM bigemp_fact WHERE deptno=10
FROM bigemp_fact WHERE deptno=10 ORDER
ORDER BY sal;
BY sal;
9.Снова выполните скрипт query15a.sql.

query15a.sql
SET echo off
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION
SESSION SET sort_area_size=50000;
SET sort_area_size=50000;
ALTER SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
10.Выполните трассировку (autotrace) запроса query17.sql.
(3) Приведите скриншот плана выполнения и прокомментируйте результат.
query17.sql
SELECT *
* FROM bigemp_fact WHERE deptno=10
FROM bigemp_fact WHERE deptno=10 ORDER
ORDER BY sal DESC;
BY sal DESC;
11.Снова выполните скрипт query15a.sql.
query15a.sql
SET echo off
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION
SESSION SET sort_area_size=50000;
SET sort_area_size=50000;
ALTER SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
12.Выполните трассировку (autotrace) запроса query18.sql.
(4) Приведите скриншот плана выполнения и прокомментируйте результат.

query18.sql
SELECT *
* FROM bigemp_fact WHERE deptno=10
FROM bigemp_fact WHERE deptno=10 ORDER
ORDER BY empno;
BY empno;

13.Снова выполните скрипт query15a.sql.
query15a.sql
SET echo off
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION
SESSION SET sort_area_size=50000;
SET sort_area_size=50000;
ALTER SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
14.Выполните трассировку (autotrace) запроса query19.sql.
(5) Приведите скриншот плана выполнения и прокомментируйте результат.
query19.sql
SELECT *
* FROM bigemp_fact WHERE deptno=10
FROM bigemp_fact WHERE deptno=10 ORDER
ORDER BY sal, empno;
BY sal, empno;

3 задание
Использование индексированного кластера (Index Cluster)
15. Выполните скрипт nic_setup.sql для создания и наполнения схемы NIC. В числе прочего будут созданы большие таблицы EMP и DEPT и индексы для столбца deptno каждой из этих таблиц.
nic_setup.sql
-- run with sqlplus /nolog
CONNECT /
/ AS sysdba
AS sysdba
DROP USER NIC CASCADE;
USER NIC CASCADE;
CREATE USER nic IDENTIFIED BY nic;
GRANT DBA TO NIC;
GRANT SELECT_CATALOG_ROLE TO NIC;
GRANT SELECT
SELECT ANY dictionary TO NIC;
ANY dictionary TO NIC;
CONNECT nic/nic
SET echo ON
DROP CLUSTER emp_dept including tables;
CLUSTER emp_dept including tables;
DROP TABLE emp purge;
DROP TABLE dept purge;
TABLE dept purge;
CREATE TABLE emp ( empno NUMBER(7) ,
ename VARCHAR2(15) NOT NULL, job VARCHAR2(9) ,
mgr NUMBER(7) , hiredate DATE , sal NUMBER(7) , comm NUMBER(7) , deptno NUMBER(3)
);
CREATE TABLE dept ( deptno NUMBER(3) , dname VARCHAR2(14), loc VARCHAR2(14), c VARCHAR2(500)
);
CREATE INDEX emp_index
ON emp(deptno)
TABLESPACE users
STORAGE (INITIAL 50K
NEXT 50K
MINEXTENTS 2
MAXEXTENTS 10
PCTINCREASE 33);
CREATE INDEX dept_index
ON dept(deptno)
TABLESPACE users
STORAGE (INITIAL 50K
NEXT 50K
MINEXTENTS 2
MAXEXTENTS 10
PCTINCREASE 33);
BEGIN
FOR i IN 1..999 LOOP
INSERT INTO dept VALUES (i,'D'||i,'L'||i,dbms_random.string('u',500));
END LOOP;
COMMIT;
END;
/
BEGIN
FOR i IN 1..500000 LOOP
INSERT INTO emp VALUES
(i,dbms_random.string('u',15),dbms_random.string('u',9),i,SYSDATE,i,i,MOD(i,999));
END LOOP;
COMMIT;
END;
/
EXEC dbms_stats.gather_schema_stats('NIC');
EXIT;
16. Создайте соединение для пользователя NIC со следующими параметрами:
Connection Name: nic Username: nic Password: nic
SID: orcl
Далее используйте это соединение, пока не будет сказано иначе.
17.Выполните скрипт nic_query_a.sql, который выполняет те же действия, что
и query15a.sql + устанавливает значение параметра инициализации HASH_AREA_SIZE.
nic_query_a.sql
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION SET sort_area_size=50000;
ALTER SESSION
SESSION SET hash_area_size=5000;
SET hash_area_size=5000;

18.Выполните трассировку (autotrace) запроса nic_query_b.sql.
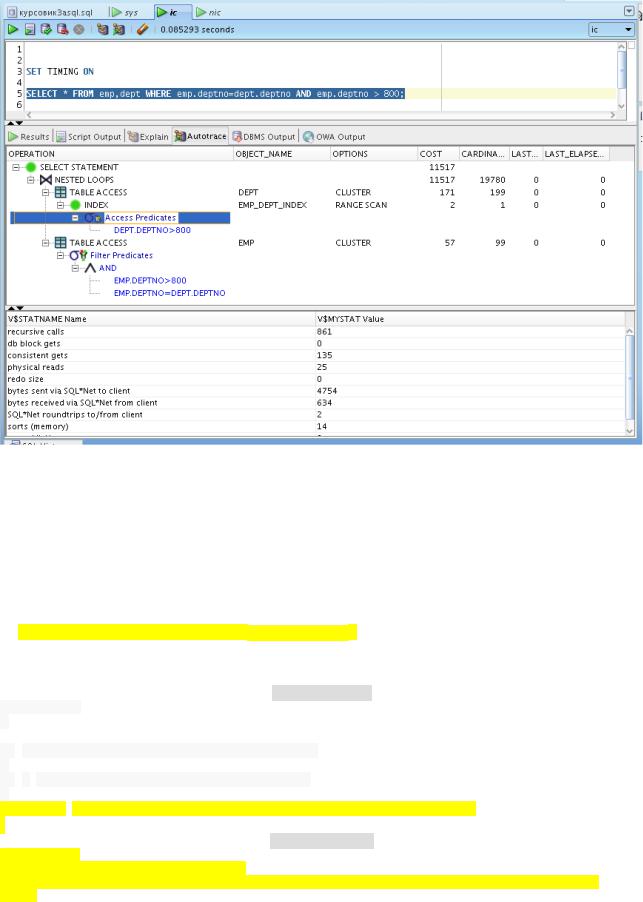
(1) Приведите план выполнения, отметьте время выполнения запросса, стоимость и количество логических чтений
Прокомментируйте результат.
nic_query_b.sql
SELECT *
* FROM emp,dept WHERE emp.deptno=dept.deptno AND emp.deptno >
FROM emp,dept WHERE emp.deptno=dept.deptno AND emp.deptno > 800;
800;
19.Как можно повысить производительность предыдущего запроса?
(2) Приведите своё решение (теоретическое описание, выполнять не нужно). Создать индексный кластер
20. Выполните скрипт ic_setup.sql для создания и наполнения схемы IC. ic_setup.sql
-- run with sqlplus /nolog
CONNECT /
/ AS sysdba
AS sysdba
DROP USER IC CASCADE;
USER IC CASCADE;
CREATE USER ic IDENTIFIED
USER ic IDENTIFIED BY ic;
BY ic;
|
|
|
|
|
|
|
|
|
|
GRANT |
DBA |
TO |
ic; |
|
|
|
|
GRANT |
SELECT_CATALOG_ROLE |
TO |
ic; |
|
||||
GRANT |
SELET |
ANY |
DICTIONARY |
TO |
ic; |
|||
CONNECT ic/ic
SET echo ON
DROP TABLE emp purge;
DROP TABLE dept purge;
TABLE dept purge;
DROP CLUSTER emp_dept including tables;
CLUSTER emp_dept including tables;
CREATE CLUSTER emp_dept (deptno NUMBER(3))
SIZE 600
TABLESPACE users
STORAGE (INITIAL 200K
NEXT 300K

MINEXTENTS 2
PCTINCREASE 33);
CREATE TABLE emp ( empno NUMBER(7) ,
ename VARCHAR2(15) NOT NULL, job VARCHAR2(9) ,
mgr NUMBER(7) , hiredate DATE , sal NUMBER(7) , comm NUMBER(7) , deptno NUMBER(3))
CLUSTER emp_dept (deptno);
CREATE TABLE dept ( deptno NUMBER(3) , dname VARCHAR2(14), loc VARCHAR2(14), c VARCHAR2(500))
CLUSTER emp_dept (deptno);
CREATE INDEX emp_dept_index
ON CLUSTER emp_dept
TABLESPACE users
STORAGE (INITIAL 50K
NEXT 50K
MINEXTENTS 2
MAXEXTENTS 10
PCTINCREASE 33);
BEGIN
FOR i IN 1..999 LOOP
INSERT INTO dept VALUES (i,'D'||i,'L'||i,dbms_random.string('u',500));
END LOOP;
COMMIT;
END;
/
BEGIN
FOR i IN 1..500000 LOOP
INSERT INTO emp VALUES
(i,dbms_random.string('u',15),dbms_random.string('u',9),i,SYSDATE,i,i,MOD(i,999));
END LOOP;
COMMIT;
END;
/
EXEC dbms_stats.gather_schema_stats('IC');
EXIT;
21. Создайте соединение для пользователя IC со следующими параметрами:
Connection Name: ic Username: ic Password: ic
SID: orcl
Далее используйте это соединение, пока не будет сказано иначе.
22.Снова выполните скрипт nic_query_a.sql.
nic_query_a.sql
ALTER SESSION SET workarea_size_policy=manual;
ALTER SESSION SET sort_area_size=50000;
ALTER SESSION
SESSION SET hash_area_size=5000;
SET hash_area_size=5000;
23. Ещё раз выполните трассировку (autotrace) запроса nic_query_b.sql.
(3) Приведите план выполнения и прокомментируйте результат.
nic_query_b.sql
SELECT *
* FROM emp,dept WHERE emp.deptno=dept.deptno AND emp.deptno >
FROM emp,dept WHERE emp.deptno=dept.deptno AND emp.deptno > 800;
800;

24.Важно: закройте все окна SQL Developer, относящиеся к сессиям пользователя SH и разорвите соединение (disconnect). Завершите также сессии SQL*Plus, если таковые есть.
25.В окне терминала выполните скрипт ap_cleanup.sh - для очистки окружения. Этот скрипт
пересоздаёт схему SH. Если Вы не увидели сообщения об успешном удалении пользователя или появилось сообщение об ошибке, подождите, пока скрипт завершит свою работу, убедитесь, что все сессии для пользователя SH завершены и соединения закрыты, после чего запустите скрипт снова.
ap_cleanup.sh
#!/bin/bash
cd /home/oracle/labs/SQL_Access_Advisor/shсв
/home/oracle/labs/SQL_Access_Advisor/shсв
cp *
* $ORACLE_HOME/demo/schema/sales_history
$ORACLE_HOME/demo/schema/sales_history
sqlplus / as sysdba @/home/oracle/labs/Access_Paths/ap_cleanup.sql
as sysdba @/home/oracle/labs/Access_Paths/ap_cleanup.sql
SET echo ON
@sh_main sh example temp oracle_4U /u01/app/oracle/product/11.2.0/dbhome_1/demo/SCHEMA/sales_history/ /home/oracle/ v3
EXIT;

@sh_main
номер 7.2
Скрипты, упоминаемые в данном блоке упражнений, расположены в каталоге $HOME/labs/Query_Result_Cache.
$HOME/labs/Query_Result_Cache.
1. Выполните скрипт result_cache_setup.sh
result_cache_setup.sh для создания и наполнения схемы QRC.
для создания и наполнения схемы QRC.
result_cache_setup.sql
SET echo ON
DROP USER qrc CASCADE;
USER qrc CASCADE;
CREATE USER qrc IDENTIFIED BY qrc
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp;
TABLESPACE temp;
GRANT CONNECT,
CONNECT, RESOURCE, dba TO qrc;
RESOURCE, dba TO qrc;
CONNECT qrc/qrc
EXEC dbms_result_cache.flush;
DROP TABLE cachejfv purge;
TABLE cachejfv purge;

CREATE TABLE cachejfv(c VARCHAR2(500))
TABLE cachejfv(c VARCHAR2(500)) TABLESPACE users;
TABLESPACE users;
INSERT INTO cachejfv
VALUES('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaa');
INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT * FROM cachejfv; INSERT INTO cachejfv SELECT
INTO cachejfv SELECT *
* FROM cachejfv;
FROM cachejfv;
INSERT INTO cachejfv VALUES('b');
INTO cachejfv VALUES('b');
COMMIT;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
2. Создайте соединение для пользователя QRC со следующими параметрами:
Connection Name: qrc Username: qrc Password: qrc
SID: orcl
Далее используйте это соединение, пока не будет сказано иначе.
3. Определите текущее содержимое кэша результатов с помощью скрипта check_result_cashe.sql.
(1) Прокомментируйте
SELECT TYPE, status, name, object_no, row_count,row_size_avg
FROM v$result_cache_objects
ORDER BY
BY 1;
1;

4.Выполните скрипт query1.sql.
(2) Зафиксируйте время, в течение которого он выполнялся.
SELECT /*+ result_cache q_name(Q1) */
query1.sql
COUNT(*)
FROM cachejfv c1, cachejfv c2, cachejfv c3, cachejfv c4, cachejfv c5,
cachejfv c6, cachejfv c7
WHERE c1.c='b' AND c2.c ='b' AND c3.c ='b' AND c4.c ='b' AND c5.c ='b' AND c6.c ='b'
AND c6.c ='b' AND c7.c ='b';
AND c7.c ='b';
время 1.544ms elasted
5.С помощью кнопки Explain Plan
(3) выведите план выполнения запроса из скрипта query1.sql. Что Вы можете отметить (по теме лабораторной)?

6. Снова определите текущее содержимое кэша результатов с помощью
скрипта check_result_cashe.sql. (4) Приведите и прокомментируйте результат.

check_result_cache.sql
SELECT TYPE, status, name, object_no, row_count,row_size_avg
FROM v$result_cache_objects
ORDER BY
BY 1;
1;
7.Очистите буферный кэш Вашего экземпляра:
ALTER SYSTEM FLUSH buffer_cache;
SYSTEM FLUSH buffer_cache;
8.Снова выполните скрипт query1.sql. (5) Зафиксируйте время выполнения и прокомментируйте результат.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
query1.sql |
|
|
|
|
|
|
||||
SELECT |
/*+ result_cache q_name(Q1) */ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
COUNT |
(*) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
FROM |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
cachejfv c1 |
, |
cachejfv c2 |
, |
cachejfv c3 |
, |
cachejfv c4 |
, |
cachejfv c5 |
, |
|||||||||||||||||||||||
cachejfv c6 |
, |
cachejfv c7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
= |
'b' |
|
AND |
c2.c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
WHERE |
c1.c |
|
= |
'b' |
|
AND |
c3.c |
= |
'b' |
|
AND |
c4.c |
= |
'b' |
|||||||||||||||||||
AND |
|
c5.c |
= |
'b' |
|
AND |
c6.c |
= |
'b' |
AND |
c7.c |
= |
'b' |
; |
|
||||||||||||||||||

9.Вставьте новую строку в таблицу CACHEJFV:
INSERT INTO cachejfv VALUES('c'); COMMIT;
10.Снова определите текущее содержимое кэша результатов с помощью скрипта check_result_cashe.sql.
(6) Приведите и прокомментируйте результат.
check_result_cache.sql
SELECT TYPE, status, name, object_no, row_count,row_size_avg
FROM v$result_cache_objects
ORDER BY
BY 1;
1;
11. Снова выполните скрипт query1.sql. (7) Зафиксируйте время выполнения.
SELECT /*+ result_cache q_name(Q1) */
query1.sql
COUNT(*)
FROM cachejfv c1, cachejfv c2, cachejfv c3, cachejfv c4, cachejfv c5,
cachejfv c6, cachejfv c7
WHERE c1.c='b' AND c2.c ='b' AND c3.c ='b' AND c4.c ='b' AND c5.c ='b' AND c6.c ='b'
AND c6.c ='b' AND c7.c ='b';
AND c7.c ='b';
1,084ms elapsed
12. Определите текущее содержимое кэша результатов с помощью
скрипта check_result_cashe.sql. (8) Приведите и прокомментируйте результат.
check_result_cache.sql
SELECT TYPE, status, name, object_no, row_count,row_size_avg
FROM v$result_cache_objects
ORDER BY
BY 1;
1;

13. Сгенерируйте детализированный отчёт по использованию кэша результатов и
(9) приведите результат.
SET SERVROUTPUT ON
EXEC DBMS_RESULT_CACHE.MEMORY_REPORT(detailed=>true);
14. Очистите буферный кэш:
ALTER SYSTEM FLUSH buffer_cache;
и снова выполните скрипт query1.sql.
(10) Зафиксируйте время выполнения и прокомментируйте результат.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
query1.sql |
|
|
|
|
|
|
||||
SELECT |
/*+ result_cache q_name(Q1) */ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
COUNT |
(*) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
FROM |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
cachejfv c1 |
, |
cachejfv c2 |
, |
cachejfv c3 |
, |
cachejfv c4 |
, |
cachejfv c5 |
, |
|||||||||||||||||||||||
cachejfv c6 |
, |
cachejfv c7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
= |
'b' |
|
AND |
c2.c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
WHERE |
c1.c |
|
= |
'b' |
|
AND |
c3.c |
= |
'b' |
|
AND |
c4.c |
= |
'b' |
|||||||||||||||||||
AND |
|
c5.c |
= |
'b' |
|
AND |
c6.c |
= |
'b' |
AND |
c7.c |
= |
'b' |
; |
|
||||||||||||||||||
36ms elapsed

15.Выключите использование кэша результатов с помощью следующей команды:
EXEC DBMS_RESULT_CACHE.BYPASS(bypass_mode=>true);
16.Снова выполните скрипт query1.sql.
(11) Зафиксируйте время выполнения и прокомментируйте результат.
SELECT /*+ result_cache q_name(Q1) */
query1.sql
COUNT(*)
FROM cachejfv c1, cachejfv c2, cachejfv c3, cachejfv c4, cachejfv c5,
cachejfv c6, cachejfv c7
WHERE c1.c='b' AND c2.c ='b' AND c3.c ='b' AND c4.c ='b' AND c5.c ='b' AND c6.c ='b'
AND c6.c ='b' AND c7.c ='b';
AND c7.c ='b';
1,444ms elapsed
17.
a.Включите использование кэша результатов и очистите буферный кэш:
EXEC DBMS_RESULT_CACHE.BYPASS(bypass_mode=>false); ALTER SYSTEM FLUSH buffer_cache;
SYSTEM FLUSH buffer_cache;
b.Убедитесь, что он снова используется (ещё раз выполните скрипт query1.sql и
(12) зафиксируйте время выполнения):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
query1.sql |
|
|
|
|
|
|
||||
SELECT |
/*+ result_cache q_name(Q1) */ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
COUNT |
(*) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
FROM |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
cachejfv c1 |
, |
cachejfv c2 |
, |
cachejfv c3 |
, |
cachejfv c4 |
, |
cachejfv c5 |
, |
|||||||||||||||||||||||
cachejfv c6 |
, |
cachejfv c7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
= |
'b' |
|
AND |
c2.c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
WHERE |
c1.c |
|
= |
'b' |
|
AND |
c3.c |
= |
'b' |
|
AND |
c4.c |
= |
'b' |
|||||||||||||||||||
AND |
|
c5.c |
= |
'b' |
|
AND |
c6.c |
= |
'b' |
AND |
c7.c |
= |
'b' |
; |
|
||||||||||||||||||
81ms elasted

задание 2
18. Выполните скрипт query2.sql.
query2.sql. (1)
(1) Зафиксируйте время выполнения и прокомментируйте результат.
Зафиксируйте время выполнения и прокомментируйте результат.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
query2.sql |
|
|
|
|
||||
SELECT |
COUNT |
(*) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
FROM |
|
cachejfv |
|
|
c1 |
, |
cachejfv c2 |
, |
cachejfv c3 |
, |
cachejfv c4 |
, |
||||||||||||||||||
cachejfv c5 |
, |
|
cachejfv c6 |
, |
cachejfv c7 |
|
|
|
|
|
|
|
||||||||||||||||||
WHERE |
c1.c |
= |
'b' |
|
AND |
c2.c |
= |
'b' |
|
AND |
c3.c |
|
= |
'b' |
|
AND |
c4.c |
= |
'b' |
|||||||||||
AND |
c5.c |
= |
'b' |
|
AND |
c6.c |
= |
'b' |
AND |
|
c7.c |
= |
'b' |
; |
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1,195 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
19. Каким образом можно заставить предыдущий запрос использовать кэшированные результаты без применения подсказок (hints)?
(2) Зафиксируйте своё решение.
|
Параметр |
|
Описание |
|
|
|
|
|
|
|
result_cache_max_size |
|
Максимальный размер кэша (например, 5M для 5 MB). Если |
|
|
|
установить в 0, кэш результатов будет полностью выключен. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
пределяет процент от максимального размера кэша |
|
|
result_cache_max_result |
|
(result_cache_max_size), который может использоваться одним |
|
|
|
|
запросом. |
|
|
|
|
|
|
|
|
|
Если задано значение FORCE, то все запросы кэшируются, |
|
|
result_cache_mode |
|
если они умещаются в кэш. Значение по умолчанию MANUAL |
|
|
|
|
означает, что кэшируются только запросы с подсказкой. |
|
|
|
|
|
|
|
result_cache_remote_expiratio |
|
Определяет количество минут, которое результат в кэше, |
|
|
n |
|
который обращался к удаленному объекту, остается |
|
|
|
действительным. По умолчанию 0. |
|
|
|
|
|
|
|
|
|
|
|
|
alter session set RESULT_CACHE_MODE='FORCE';
a.(3)Просмотрите текущее содержимое кэша результатов и примените своё решение.

alter session set RESULT_CACHE_MODE='FORCE';
b. Проверьте результат, просмотрев план выполнения запроса из скрипта query2.sql (с помощью кнопки explain plan).
(4) Приведите и прокомментируйте план (по теме данной лабораторной).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
query2.sql |
|
|
|
|
||||
SELECT |
COUNT |
(*) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
FROM |
|
cachejfv |
|
|
c1 |
, |
cachejfv c2 |
, |
cachejfv c3 |
, |
cachejfv c4 |
, |
||||||||||||||||||
cachejfv c5 |
, |
|
cachejfv c6 |
, |
cachejfv c7 |
|
|
|
|
|
|
|
||||||||||||||||||
WHERE |
c1.c |
= |
'b' |
|
AND |
c2.c |
= |
'b' |
|
AND |
c3.c |
|
= |
'b' |
|
AND |
c4.c |
= |
'b' |
|||||||||||
AND |
c5.c |
= |
'b' |
|
AND |
c6.c |
= |
'b' |
AND |
|
c7.c |
= |
'b' |
; |
|
|||||||||||||||
c.Очистите буферный кэш Вашего экземпляра
ALTER SYSTEM FLUSH buffer_cache;
SYSTEM FLUSH buffer_cache;
Запустите скрипт query2.sql и убедитесь, что он выполняется практически мгновенно ((5) зафиксируйте время выполнения).
58ms
d. (6) Отмените изменения, сделанные Вами в п. a).
alter session set RESULT_CACHE_MODE='MANUAL';
20. Очистите кэш результатов:
EXEC DBMS_RESULT_CACHE.FLUSH;
Просмотрите содержимое представления V$RESULT_CACHE_OBJECTS, чтобы убедиться, что кэш пуст.
SELECT TYPE, status, name, object_no, row_count,row_size_avg
FROM v$result_cache_objects
ORDER BY 1;
21. Выполните скрипт cre_func.sql - для создания PL/SQL функции, использующей кэш результатов.
cre_func.sql
CREATE OR REPLACE FUNCTION CACHEJFV_COUNT(v VARCHAR2)
RETURN NUMBER
result_cache relies_on (cachejfv)
IS
cnt NUMBER;
BEGIN
SELECT COUNT(*) INTO cnt
FROM cachejfv c1,cachejfv c2,cachejfv c3,cachejfv c4,cachejfv c5,cachejfv c6, cachejfv c7 WHERE c1.c=v AND c2.c=v AND c3.c=v AND c4.c=v AND c5.c=v AND c6.c=v AND c7.c=v;
RETURN cnt; END;
/
дополнение
КЭШИРОВАНИЕ РЕЗУЛЬТАТОВ PL/SQL
ФУНКЦИЙ В ORACLE DATABASE 11G
SEPTEMBER 8, 2010 DBA_WP_USER LEAVE A COMMENT
В версии Oracle Database 11g появилась новая замечательная возможность кэширования результатов PL/SQL функций. Кэшировать можно как результаты обычных PL/SQL функций, так и результаты функций в PL/SQL пакетах. Замечательной особенностью нового механизма кэширования Oracle является то, что кэширование результатов функций осуществляется на уровне SGA, т.е. кэш результатов разделяется между всеми сессиями пользователей, что ведет к уменьшению использования памяти сервером базы данных. Также при объявлении PL/SQL функции можно указать, когда кэш должен стать недействительным. Это может происходить автоматически при фиксации изменений данных в некоторых таблицах, список которых можно указать при объявлении PL/SQL функции или же выполнением соответствующей команды из встроенного
пакета DBMS_RESULT_CACHE .
Эти новые возможности реализуются при помощи ключевых
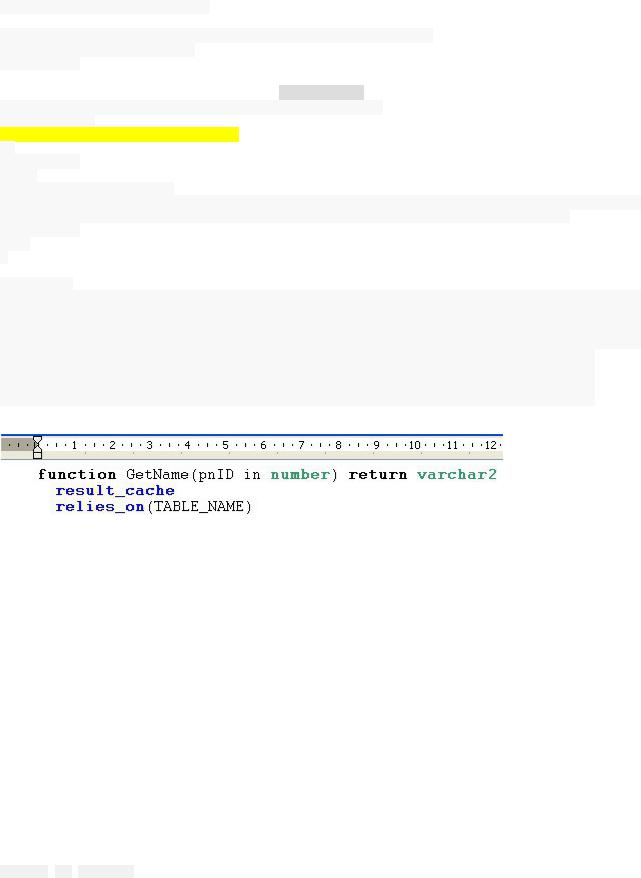
слов result_cache и relies_on. Пример объявления кэширующей функции:
CREATE OR
OR REPLACE
REPLACE

FUNCTION test
test (pnID
(pnID IN
IN NUMBER)
NUMBER) RETURN
RETURN VARCHAR2
VARCHAR2
result_cache relies_on (TABLE_NAME1,TABLE_NAME2)
(TABLE_NAME1,TABLE_NAME2)
IS
BEGIN
 ...
...
END test;
test;
/
В этом примере ключевое слово result_cache заставляет Oracle кэшировать результаты функции для заданного входного параметра, а ключевое
слово relies_on позволяет перечислить список таблиц, при фиксации изменений в которых (в любой пользовательской сессии) кэш функции становится недействительным, и будет вычисляться заново при следующем обращении к этой функции.
Если кэшируемая функция объявлена в PL/SQL пакете, то ключевое
слово result_cache в спецификации пакета указывать нельзя (если это сделать, то произойдет ошибка компиляции), это возможно только при объявлении функции в теле пакета.
Чтобы использовать новые возможности кэширования сервера баз
данных 11g необходимо оценить выигрыш в скорости, предоставляемый новой технологией. Для оценки создадим тестовый PL/SQL пакет, при помощи которого будем сравнивать скорость выполнения с использованием традиционного подхода к выборке данных, с использованием result_cache, а также технологию кэширования при помощи индексных массивов, описанную нами ранее в статьях Индексные массивы в Oracle PL/SQL и PL/SQL и Java. Кто быстрее?
и PL/SQL и Java. Кто быстрее?
Для тестирования будем выполнять поиск по маске в имени объекта из системного представления ALL_OBJECTS. Код тестового пакета приведен ниже:
CREATE OR
OR REPLACE
REPLACE
PACKAGE test_result_cache
test_result_cache
IS
 FUNCTION
FUNCTION GetCountStd(psMASK
GetCountStd(psMASK IN
IN VARCHAR2)
VARCHAR2) RETURN
RETURN PLS_INTEGER;
PLS_INTEGER;
 PROCEDURE
PROCEDURE TestCountStd(pnCOUNT
TestCountStd(pnCOUNT IN
IN PLS_INTEGER);
PLS_INTEGER);
 TYPE
TYPE ttArr
ttArr IS
IS TABLE
TABLE OF
OF PLS_INTEGER
PLS_INTEGER INDEX
INDEX BY
BY VARCHAR2(8);
VARCHAR2(8);
gtArr ttArr;
 FUNCTION
FUNCTION GetCountArr(psMASK
GetCountArr(psMASK IN
IN VARCHAR2)
VARCHAR2) RETURN
RETURN PLS_INTEGER;
PLS_INTEGER;
 PROCEDURE
PROCEDURE TestCountArr(pnCOUNT
TestCountArr(pnCOUNT IN
IN PLS_INTEGER);
PLS_INTEGER);

 FUNCTION
FUNCTION GetCountCache(psMASK
GetCountCache(psMASK IN
IN VARCHAR2)
VARCHAR2) RETURN
RETURN PLS_INTEGER
PLS_INTEGER result_cache;
result_cache;
 PROCEDURE
PROCEDURE TestCountCache(pnCOUNT
TestCountCache(pnCOUNT IN
IN PLS_INTEGER);
PLS_INTEGER);
END test_result_cache;
test_result_cache;
/
CREATE OR
OR REPLACE
REPLACE
PACKAGE BODY
BODY test_result_cache
test_result_cache
IS
 FUNCTION
FUNCTION GetCountStd(psMASK
GetCountStd(psMASK IN
IN VARCHAR2)
VARCHAR2) RETURN
RETURN PLS_INTEGER
PLS_INTEGER
 IS
IS
n PLS_INTEGER;
PLS_INTEGER;
 BEGIN
BEGIN

 SELECT
SELECT COUNT(*)
COUNT(*)


 INTO
INTO n
n


 FROM
FROM ALL_OBJECTS
ALL_OBJECTS


 WHERE
WHERE OBJECT_NAME
OBJECT_NAME LIKE
LIKE '%'||psMASK||'%';
'%'||psMASK||'%';

 RETURN
RETURN n;
n;
 END
END GetCountStd;
GetCountStd;
 PROCEDURE
PROCEDURE TestCountStd(pnCOUNT
TestCountStd(pnCOUNT IN
IN PLS_INTEGER)
PLS_INTEGER)
 IS
IS
n PLS_INTEGER;
PLS_INTEGER;
 BEGIN
BEGIN

 FOR
FOR i
i IN
IN 1..pnCOUNT
1..pnCOUNT LOOP
LOOP
n:=GetCountStd('IN');
n:=GetCountStd('OUT');
n:=GetCountStd('PARAM');
n:=GetCountStd('END');
n:=GetCountStd('OPT');

 END
END LOOP;
LOOP;
 END
END TestCountStd;
TestCountStd;
 FUNCTION
FUNCTION GetCountArr(psMASK
GetCountArr(psMASK IN
IN VARCHAR2)
VARCHAR2) RETURN
RETURN PLS_INTEGER
PLS_INTEGER
 IS
IS
n PLS_INTEGER;
PLS_INTEGER;
 BEGIN
BEGIN

 IF
IF gtArr.EXISTS(psMASK)
gtArr.EXISTS(psMASK)

 THEN
THEN


 RETURN
RETURN gtArr(psMask);
gtArr(psMask);


 END
END IF;
IF;

 SELECT
SELECT COUNT(*)
COUNT(*)


 INTO
INTO n
n


 FROM
FROM ALL_OBJECTS
ALL_OBJECTS


 WHERE
WHERE OBJECT_NAME
OBJECT_NAME LIKE
LIKE '%'||psMASK||'%';
'%'||psMASK||'%';
gtArr(psMask):=n;

 RETURN
RETURN n;
n;
 END
END GetCountArr;
GetCountArr;
 PROCEDURE
PROCEDURE TestCountArr(pnCOUNT
TestCountArr(pnCOUNT IN
IN PLS_INTEGER)
PLS_INTEGER)
 IS
IS
n PLS_INTEGER;
PLS_INTEGER;
 BEGIN
BEGIN
gtArr.DELETE;

 FOR
FOR i
i IN
IN 1..pnCOUNT
1..pnCOUNT LOOP
LOOP
n:=GetCountArr('IN');
n:=GetCountArr('OUT');
n:=GetCountArr('PARAM');
n:=GetCountArr('END');
n:=GetCountArr('OPT');

 END
END LOOP;
LOOP;
 END
END TestCountArr;
TestCountArr;
 FUNCTION
FUNCTION GetCountCache(psMASK
GetCountCache(psMASK IN
IN VARCHAR2)
VARCHAR2) RETURN
RETURN PLS_INTEGER
PLS_INTEGER result_cache
result_cache
 IS
IS
n PLS_INTEGER;
PLS_INTEGER;
 BEGIN
BEGIN

 SELECT
SELECT COUNT(*)
COUNT(*)


 INTO
INTO n
n


 FROM
FROM ALL_OBJECTS
ALL_OBJECTS


 WHERE
WHERE OBJECT_NAME
OBJECT_NAME LIKE
LIKE '%'||psMASK||'%';
'%'||psMASK||'%';

 RETURN
RETURN n;
n;
 END
END GetCountCache;
GetCountCache;
 PROCEDURE
PROCEDURE TestCountCache(pnCOUNT
TestCountCache(pnCOUNT IN
IN PLS_INTEGER)
PLS_INTEGER)
 IS
IS
n PLS_INTEGER;
PLS_INTEGER;
 BEGIN
BEGIN
DBMS_RESULT_CACHE.INVALIDATE(USER,'TEST_RESULT_CACHE');

 FOR
FOR i
i IN
IN 1..pnCOUNT
1..pnCOUNT LOOP
LOOP

n:=GetCountCache('IN');
n:=GetCountCache('OUT');
n:=GetCountCache('PARAM');
n:=GetCountCache('END');
n:=GetCountCache('OPT');

 END
END LOOP;
LOOP;
 END
END TestCountCache;
TestCountCache;
END test_result_cache;
test_result_cache;
/
Перед компиляцией тестового пакета необходимо дать разрешение владельцу схемы на выполнение встроенного PL/SQL пакета DBMS_RESULT_CACHE:
GRANT EXECUTE
EXECUTE ON
ON SYS.DBMS_RESULT_CACHE
SYS.DBMS_RESULT_CACHE TO
TO SCHEMA_OWNER;
SCHEMA_OWNER;
Для выполнения тестов запускаем sql*plus, выполнив предварительно команду set timing on;
Каждая процедура тестирования имеет параметр количества повторов в цикле групп поисков по ALL_OBJECTS. Для получения разумного времени выполнения примем это значение в 50 итераций. Результаты тестирования:
Традиционный подход:
EXEC test_result_cache.TestCountStd(50);
test_result_cache.TestCountStd(50);
Elapsed: 00:00:25.23
Использование индексных массивов:
EXEC test_result_cache.TestCountArr(50);
test_result_cache.TestCountArr(50);
Elapsed: 00:00:00.50
Использование result_cache:
EXEC test_result_cache.TestCountCache(50);
test_result_cache.TestCountCache(50);
Elapsed: 00:00:00.51
Как видно, обе технологии кэширования обеспечили выигрыш в скорости около 30 раз. Однако применение индексных массивов использует пользовательскую память для каждой сессии, а технология result_cache использует SGA, единую память для всех сессий пользователей. Сброс кэша в обоих случаях в нашем примере необходимо производится вручную, однако для технологии с result_cache можно указать список таблиц, изменения в которых приведет к автоматическому сбросу кэша. Скорость кэширования в этих тестах оказалась примерно одинаковой. Но все таки попробуем выяснить, какая технология кэширования быстрее. Для этого увеличим на несколько порядков количество итераций:
Использование индексных массивов:
EXEC test_result_cache.TestCountArr(500000);
test_result_cache.TestCountArr(500000);
Elapsed: 00:00:02.32
Использование result_cache:
EXEC test_result_cache.TestCountCache(500000);
test_result_cache.TestCountCache(500000);
Elapsed: 00:00:03.25
Как видно, все же технология индексных массивов выигрывает примерно на 40 процентов. И это при том, что индексом в массиве в нашем случае
является varchar2. В тех случаях, если можно будет использовать в качестве индекса pls_integer, выигрыш в скорости будет еще более значительным. Как показали наши тесты, полностью технологию кэширования с применением
индексных массивов кэширование result_cache вытеснить не сможет. Использование индексных массивов может быть предпочтительнее в тех случаях, где критично время выполнения расчетных задач. Однако новая технология кэширования несомненно получит широкое применение. Множество функций в уже существующих приложениях можно перевести на технологию result_cache, гарантированно получив значительный выигрыш в производительности. Например, во многих приложениях есть функции получения записи по идентификатору. Теперь такие функции могут быть быстро и эффективно переписаны по новому, например, для таблицы с именем TABLE1:
SUBTYPE trRCRD
trRCRD IS
IS TABLE1%ROWTYPE;
TABLE1%ROWTYPE;
...
FUNCTION GET_RCRD(pnID
GET_RCRD(pnID IN
IN NUMBER)
NUMBER) RETURN
RETURN trRCRD
trRCRD result_cache relies_on(TABLE1)
result_cache relies_on(TABLE1)
IS
lrRCRD trRCRD;
BEGIN
 SELECT
SELECT *
*

 INTO
INTO lrRCRD
lrRCRD

 FROM
FROM TABLE_NAME
TABLE_NAME

 WHERE
WHERE ID=pnID;
ID=pnID;
 RETURN
RETURN lrRCRD;
lrRCRD;
END GET_RCRD;
GET_RCRD;
Новая технология кэширования может быть использована и в SQL запросах в вашем PL/SQL коде при помощи нового хинта (подсказки оптимизатору), например:
PROCEDURE A1
A1
IS
n PLS_INTEGER;
PLS_INTEGER;
BEGIN
 ...
...
 SELECT
SELECT /*+ result_cache */
/*+ result_cache */ COUNT(*)
COUNT(*)

 INTO
INTO n
n


 FROM
FROM TABLE1;
TABLE1;
 ...
...
END A1;
A1;
Вэтом случае система автоматически будет отслеживать возможные изменения таблиц в запросе и перезагружать кэш.
Внашем тестовом примере был использован встроенный
пакет DBMS_RESULT_CACHE, который позволяет принудительно сбрасывать кэш (делать его недействительным) и выполнять некоторые другие функции по управлению кэшем. Для целей разработки наиболее востребованными могут быть следующие функции этого пакета:
–DBMS_RESULT_CACHE.FLUSH – общий сброс всего кэша экземпляра базы данных.
–DBMS_RESULT_CACHE.INVALIDATE – принудительный сброс кэша для заданной
функции или PL/SQL пакета. В качестве первого параметра здесь передается имя владельца схемы, в качестве второго имя функции, процедуры или пакета. К сожалению, нет возможности указать конкретную функцию в заданном пакете, сброс кэша происходит целиком для всех функций PL/SQL пакета.
Более подробно о пакете DBMS_RESULT_CACHE можно прочитать в официальной документации.
можно прочитать в официальной документации.
Для просмотра текущего состояния кэша могут быть полезны следующие динамические представления:
V$RESULT_CACHE_MEMORY
V$RESULT_CACHE_OBJECTS
V$RESULT_CACHE_DEPENDENCY
Размер кэша в SGA задается с помощью параметра экземпляра базы данных RESULT_CACHE_SIZE
22. Определите текущее содержимое кэша результатов с помощью скрипта check_result_cashe.sql.
(7) Прокомментируйте результат
SELECT TYPE, status, name, object_no, row_count,row_size_avg
FROM v$result_cache_objects
ORDER BY
BY 1;
1;

23. Вызовите созданную в п.21 функцию, передав в качестве значения параметра 'b'.
(8) Зафиксируйте время выполнения и прокомментируйте результат.
24. Очистите буферный кэш:
ALTER SYSTEM FLUSH buffer_cache;
SYSTEM FLUSH buffer_cache;
и снова вызовите функцию CACHEJFV_COUNT, передав в качестве значения параметра 'b'.
(9) Зафиксируйте время выполнения и прокомментируйте результат.
25. Ещё раз очистите буферный кэш:
ALTER SYSTEM FLUSH buffer_cache;
SYSTEM FLUSH buffer_cache;
и вызовите функцию CACHEJFV_COUNT, теперь передав в качестве значения параметра 'c'. (10) Зафиксируйте время выполнения и прокомментируйте результат.

Лабораторная 9 9.1
Вопрос 1
1
Пока нет ответа Балл: 1
Отметить вопрос
Текст вопроса
1. Откройте окно терминала и запустите скрипт sysstats_setup.sh
sysstats_setup.sh (под пользователем oracle) - для создания и наполнения схемы JFV и сбора объектной статистики.
(под пользователем oracle) - для создания и наполнения схемы JFV и сбора объектной статистики.
sysstats_setup.sh
#!/bin/bash
cd /home/oracle/labs/System_Stats sqlplus / as sysdba @sysstats_setup.sql
as sysdba @sysstats_setup.sql
SET echo ON
CONNECT /
/ AS sysdba;
AS sysdba;
DROP USER jfv CASCADE;
USER jfv CASCADE;
CREATE USER jfv IDENTIFIED
USER jfv IDENTIFIED BY jfv DEFAULT
BY jfv DEFAULT TABLESPACE users TEMPORARY
TABLESPACE users TEMPORARY TABLESPACE temp; GRANT
TABLESPACE temp; GRANT CONNECT,
CONNECT, RESOURCE, dba TO jfv;
RESOURCE, dba TO jfv;
CONNECT jfv/jfv
DROP TABLE t purge;
TABLE t purge;
DROP TABLE z purge;
TABLE z purge;
CREATE TABLE t(c NUMBER);
TABLE t(c NUMBER);
INSERT INTO t VALUES
INTO t VALUES (1);
(1);
COMMIT;
INSERT INTO t SELECT
INTO t SELECT *
* FROM t;
FROM t;
COMMIT;
INSERT INTO t SELECT
INTO t SELECT *
* FROM t;
FROM t;
COMMIT;
CREATE TABLE z(d NUMBER);
TABLE z(d NUMBER);
BEGIN
FOR i IN 1..100 LOOP
INSERT INTO z VALUES (i);
END LOOP;
COMMIT;
END;
/
CREATE UNIQUE
UNIQUE INDEX iz ON z(d);
INDEX iz ON z(d);
EXECUTE dbms_stats.gather_table_stats('JFV','T',CASCADE=>true);
EXECUTE dbms_stats.gather_table_stats('JFV','Z',CASCADE=>true);
EXIT;
2. Выполните скрипт sysstats_start.sh
sysstats_start.sh для очистки кэшей и установки параметра CPUSPEEDNW=0 (для проверки обратите внимание на значение параметра CPUSPEEDNW в представлении aux_stats$,
для очистки кэшей и установки параметра CPUSPEEDNW=0 (для проверки обратите внимание на значение параметра CPUSPEEDNW в представлении aux_stats$,

данные из которого выводятся в конце выполнения скрипта). (1)
(1) Поясните что означает установленное значение для данного параметра.
Поясните что означает установленное значение для данного параметра.
sysstats_start.sh
#!/bin/bash
cd /home/oracle/labs/System_Stats sqlplus /nolog @sysstats_start.sql
sysstats_start.sql
CONNECT /
/ AS sysdba;
AS sysdba;
ALTER SYSTEM flush shared_pool;
SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
EXECUTE dbms_stats.delete_system_stats;
EXECUTE DBMS_STATS.SET_SYSTEM_STATS (pname => 'cpuspeednw', pvalue =>
'cpuspeednw', pvalue => 0);
0);
SELECT sname,pname,pval1 FROM aux_stats$;
EXIT;

Вопрос 2
2
Пока нет ответа Балл: 1
Отметить вопрос
Текст вопроса
3. Подключитесь к SQL*Plus как пользователь JFV и выполните скрипт select_without_sysstats.sql. (1) Зафиксируйте время его выполнения.
select_without_sysstats.sql
SET echo ON
SET TIMING
TIMING ON
ON
SELECT /* Without system stats */ COUNT(*)
FROM t,z
WHERE t.c=z.d;
SET TIMING off
TIMING off
4. Запустите скрипт show_latest_exec_plan.sql для просмотра плана выполнения запроса из п.3 и
определения стоимости запроса, рассчитанной оптимизатором, а также стоимости использования CPU и стоимости операций ввода-вывода при последнем выполнении запроса. (2) Зафиксируйте и прокомментируйте результат (обратите внимание на примечания к плану).
show_latest_exec_plan.sql
SET echo ON

SELECT *
* FROM
FROM TABLE(dbms_xplan.display_cursor);
TABLE(dbms_xplan.display_cursor);

col operations format a20 col object_name format a11 col options format a15 col cost_cpu_io format a30
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SELECT |
operation operations |
, |
object_name |
, |
options |
, |
||||||||||||||||||||
COST |
|| |
' -- ' |
|| |
cpu_cost |
|| |
' -- ' |
|| |
io_cost cost_cpu_io |
|
|
|||||||||||||||||
FROM |
|
( |
SELECT |
* |
|
FROM |
v$ |
sql_plan |
WHERE |
address |
IN |
( |
SELECT |
address |
|||||||||||||
FROM |
|
v |
$sql |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
WHERE |
|
|
sql_ |
|
|
|
|
|
|
|
|||||||||||||||||
|
|
text |
LIKE |
'%system stats%' |
AND |
||||||||||||||||||||||
sql_ |
text |
NOT |
LIKE |
'%connect%' |
)) |
; |
|
|
|
|
|
|
|
|
|
|
|||||||||||

5. Каким образом можно помочь оптимизатору найти более оптимальный план в следующий раз?
(3) Зафиксируйте и примените своё решение собрать системную статистику. Из нее будет понятно какой метод соединения применить. Например,
если недопустимо нагружать процессор из за большого количества открытых сессий, то hash_join может быть менее предпочтителен , а если идет большая нагрузка на I/o , то nested_loop окажется не оптимальным решением. В связи с тем, что оптимизатор учитывает нагрузку системы, то планы запросов будут отличаться , если отличается системная статистика.
Режимы
GATHERING_MODE = NOWORKLOAD вначале, когда нет нагрузки
EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( GAVERING_MODE => 'NOWORKLOAD')
запускается внутренний тест и на его основе собирается информация
DBMS_STATS.GATHER_SYSTEM_STATS( INTERVAL => 120 , STATTAB => 'TABLE_FOR_STATS', STATID => 'oltp' )
EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( GAVERING_MODE => 'START') EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS( GAVERING_MODE => 'STOP')
6.Выполните скрипт show_ss.sql и
(4) прокомментируйте результат.
|
|
|
|
|
|
|
|
|
|
|
show_ss.sql |
|
SET |
echo |
ON |
|
|
|
|
|
|
|
|
|
|
SELECT |
sname |
, |
pname |
, |
pval1 |
FROM |
aux_stats$; |
|
||||

7. Перед проверкой влияния внесённых изменений очистите разделяемый пул и буферный кэш с помощью скрипта flush_sga.sql.
flush_sga.sql
SET echo ON
ALTER SYSTEM flush shared_pool;
ALTER SYSTEM flush buffer_cache;
SYSTEM flush buffer_cache;
8.Проверьте своё решение, выполнив скрипт select_with_sysstats.sql.
(5) Прокомментируйте результат.
select_with_sysstats.sql
SET TIMING
TIMING ON
ON
SELECT /* With system stats */ COUNT(*)
FROM t,z
WHERE t.c=z.d;
SET TIMING off
TIMING off

9. Очистите окружение с помощью скрипта sysstats_cleanup.sh.
sysstats_cleanup.sh
#!/bin/bash
cd /home/oracle/labs/System_Stats
sqlplus / as sysdba @sysstats_cleanup.sql
as sysdba @sysstats_cleanup.sql
sysstats_cleanup.sql
SET echo ON
DROP USER jfv CASCADE;
USER jfv CASCADE;
ALTER SYSTEM flush shared_pool;
SYSTEM flush shared_pool;
EXIT;

9.2
1. Откройте окно терминала и запустите скрипт ags_setup.sh
ags_setup.sh (под пользователем oracle) - для создания схемы AGS, таблицы EMP и индекса для неё.
(под пользователем oracle) - для создания схемы AGS, таблицы EMP и индекса для неё.
ags_setup.sh
#!/bin/bash
cd /home/oracle/labs/Automatic_Gather_Stats sqlplus / as sysdba @ags_setup.sql
as sysdba @ags_setup.sql
ags_setup.sql
SET echo ON
DROP USER ags CASCADE;
USER ags CASCADE;
CREATE USER ags IDENTIFIED
USER ags IDENTIFIED BY ags;
BY ags;
grant dba TO ags;
connect ags/ags
DROP TABLE emp purge;
TABLE emp purge;
CREATE TABLE emp
(
empno NUMBER, ename VARCHAR2(20), phone VARCHAR2(20), deptno NUMBER
);
INSERT INTO emp with tdata AS (select rownum empno from all_objects where rownum<= 1000) select rownum,
dbms_random.string ('u', 20),
dbms_random.string ('u', 20),
CASE
when rownum/100000 <= 0.001 THEN MOD(ROWNUM, 10)
ELSE 10
END
FROM tdata a, tdata b
WHERE rownum<= 100000;
100000;
COMMIT;
CREATE INDEX emp_i1 ON emp(deptno);
INDEX emp_i1 ON emp(deptno);
EXIT;
2. Выполните скрипт ags_start.sh.
ags_start.sh
#!/bin/sh
sqlplus /nolog @ags_start.sql
ags_start.sql
SET echo ON
CONNECT /
/ AS sysdba
AS sysdba
ALTER SYSTEM flush shared_pool;
SYSTEM flush shared_pool;
--
-- Turn off AUTOTASK
--

ALTER SYSTEM
SYSTEM SET
SET "_enable_automatic_maintenance"=0;
"_enable_automatic_maintenance"=0;
exec dbms_stats.delete_schema_stats('AGS');
EXIT;
3. В SQL-Developer создайте соединение для пользователя AGSсо следующими параметрами: Connection Name: ags_connection
Username: ags Password: ags
SID: orcl
Далее используйте это соединение, пока не будет сказано иначе.
4.С помощью скрипта show_deptno_distribution.sql
show_deptno_distribution.sql посмотрите распределение значений в столбце deptno таблицы EMP.
посмотрите распределение значений в столбце deptno таблицы EMP.
5.(1) Прокомментируйте результат.
Прокомментируйте результат.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
show_deptno_distribution.sql |
|
||||||||
SELECT |
deptno |
, |
COUNT |
(*) |
cnt_per |
|
_deptno |
, |
( |
COUNT |
(*)* |
100 |
)/ |
nr |
deptno_percent |
||||||||||||
FROM |
|
emp |
, |
( |
SELECT |
MAX |
( |
empno |
) |
nr |
|
||||||||||||||||
FROM |
|
emp |
) |
|
|
|
|
|
|
|
|
|
|
||||||||||||||
GROUP |
|
|
|
|
|
|
|||||||||||||||||||||
|
|
BY |
|
deptno |
, |
nr |
|||||||||||||||||||||
ORDER |
|
BY |
|
deptno; |
|
|
|
||||||||||||||||||||
5. (2) Определите, созданы ли гистограммы
для какого-либо из столбцов таблицы EMP (используйте представление user_tab_columns).

6. (3) Определите, собрана ли статистика по таблице EMP:
a. В браузере соединения ags_connection выберите таблицу EMP. b. В открывшемся справа окне выберите вкладку Statictics. Обновите (F5) информацию при необходимости.
7.Аналогичным образом
(4) определите, собрана ли статистика по индексу таблицы EMP
(сначала необходимо узнать его имя - на вкладке Indexes для таблицы Emp, затем открыть соответствующий индекс из браузера соединения). Обратите внимание на значение параметра LAST_ANALYZED.

8. Выполните трассировку (autotrace) запросов из скриптов literal9.sql и literal10.sql.
(5) Зафиксируйте и прокомментируйте результат (предположите, почему были выбраны правильные методы доступа).
literal9.sql
SELECT COUNT(*),
COUNT(*), MAX(empno)
MAX(empno) FROM emp WHERE deptno =
FROM emp WHERE deptno = 9;
9;

literal10.sql
SELECT COUNT(*),
COUNT(*), MAX(empno)
MAX(empno) FROM emp WHERE deptno =
FROM emp WHERE deptno = 10;
10;
9. (6) Проверьте своё предположение,
просмотрев содержимое столбцов name и value в представлении v$parameter (для соответствующего параметра инициализации).