

1.2. Грамматики
Грамматика языка программирования является формальным описанием его синтаксиса или формы, в которой записаны отдельные предложения программы или вся программа. Грамматика не описывает семантику или значения различных предложений. Информация о семантике содержится в программах генерации объектного кода. В качестве иллюстрации разницы между синтаксисом и семантикой рассмотрим два предложения:
I := J + К
и
I := X + V,
где X и V являются действительными переменными, а I, J, K -целыми переменными. Эти два предложения имеют одинаковый синтаксис. Оба являются операторами присваивания, в которых присваиваемое значение определяется выражением, состоящим из двух имен переменных, разделенных оператором сложения. Однако семантика этих двух предложений совершенно различна. Первое предложение говорит о том, что переменные в выражении должны быть сложены с использованием целых арифметических операций, а результат сложения должен быть присвоен переменной I. Второе предложение задает сложение с плавающей точкой, результат которого должен быть преобразован в целое число перед присваиванием. Очевидно, что эти два предложения будут скомпилированы в совершенно различные последовательности машинных команд, хотя их грамматическое описание одинаково. Различия между ними проявятся на этапе генерации объектного кода.
Существует несколько различных форм записи грамматик. Первой получившей широкое распространение формальной системой обозначений для описания синтаксиса языков программирования была форма Бекуса-Наура (БНФ). БНФ не самое мощное из известных средств описания синтаксиса. Фактически она даже не является вполне адекватной для описания некоторых реально существующих языков программирования. Однако эта форма достаточно проста, широко используется и предоставляет достаточные для большинства приложений средства. На рис.2 изображена одна из возможных грамматик БНФ для языка Паскаль. Покажем, как она связана с примером программы, изображенным на рис.1.
1 <prog> ::= PROGRAM <prog-name> VAR <dec-list>
BEGIN <stmt-list> END .
2 <prog-name> ::= id
3 <dec-list> ::= <dec> | <dec-list> ; <dec>
4 <dec> ::= <id-list> : <type>
5 <type> ::= INTEGER
6 <id-list> ::= id | <id-list> , id
7 <stmt-list> ::= <stmt> | <stmt-list> ; <stmt>
8 <stmt> ::= <assign> | <read> | <write> | <for>
9 <assign> ::= id := <exp>
10 <exp> ::= <term> | <exp> + <term> | <exp> - <term>
11 <term> ::= <factor> | <term> * <factor> | <term> DIV <factor>
12 <factor> ::= id | int | <exp>
13 <read> ::= READ ( <id-list> )
14 <write> ::= WRITE ( <id-list> )
15 <for> ::= FOR <index-exp> DO <body>
16 <index-exp> ::= id = <exp> TO <exp>
17 <body> ::= <stmt> | BEGIN <stmt-list> END
Рис. 2. Грамматика БНФ языка Паскаль
Грамматика БНФ состоит из множества правил вывода, каждое из которых определяет синтаксис некоторой конструкции языка программирования. Рассмотрим, например, правило 13 на рис.2:
<read> ::= READ ( <id-list> )
Это определение синтаксиса предложения READ языка Паскаль, обозначенное в грамматике как <read> . Символ ::= можно читать как “является по определению”. С левой стороны от этого символа находится определяемая конструкция языка (в нашем случае - <read> ), а с правой - описание синтаксиса этой конструкции. Строки символов, заключенные в угловые скобки < и >, называются нетерминальными символами (т. е. являются именами конструкций, определенными внутри грамматики). То, что не заключено в угловые скобки, называется терминальными символами грамматики (лексемами). В этом правиле вывода нетерминальными символами являются <геаd> и <id-list>. Терминальными символами являются лексемы READ, (, ). Таким образом, это правило определяет, что конструкция <read> состоит из лексемы READ, за которой следует лексема (, за ней следует конструкция языка, называемая <id-list>, за которой следует лексема ). Пробелы при описании грамматических правил не существенны и вставляются только для наглядности.
Для распознавания нетерминального символа <геаd> необходимо, чтобы было определение для нетерминального символа <id-list>. Это определение дается правилом 6 на рис.2 :
<id-list> ::= id | <id-list> , id
Это правило предлагает две возможности, разделенные символом | , для синтаксиса нетерминального символа <id-list>. Первая возможность состоит в том, что <id-list> состоит просто из лексемы id (запись id означает идентификатор, распознаваемый сканером). Другой вариант состоит в том, что <id-list> состоит из <id-list>, за которым следует лексема “,” , за которой следует лексема id. Обратите внимание, что это правило является рекурсивным. Это означает, что конструкция <id-list> определяется фактически в терминах себя самой. Рассмотрев несколько примеров, можно убедиться, что в соответствии с этим правилом нетерминальным символом <id-list> вляется любая последовательность из одной или более лексем id , разделенных запятыми. Таким образом,
АLPHА
является нетерминальным символом <id-list>, состоящим из единственного идентификатора АLРНА ,
АLРНА, ВЕТА
также ярляются конструкцией <id-list>, состоящей из конструкции <id-list> АLРНА, за которой следует “,” , за которой идет идентификатор ВЕТА и т.д.
Результат анализа исходного предложения в терминах грамматических конструкций удобно представлять в виде дерева. Такие деревья обычно называют деревьями грамматического разбора или синтаксическими деревьями. На рис.3,а изображено дерево грамматического разбора для предложения
READ(VALUE)
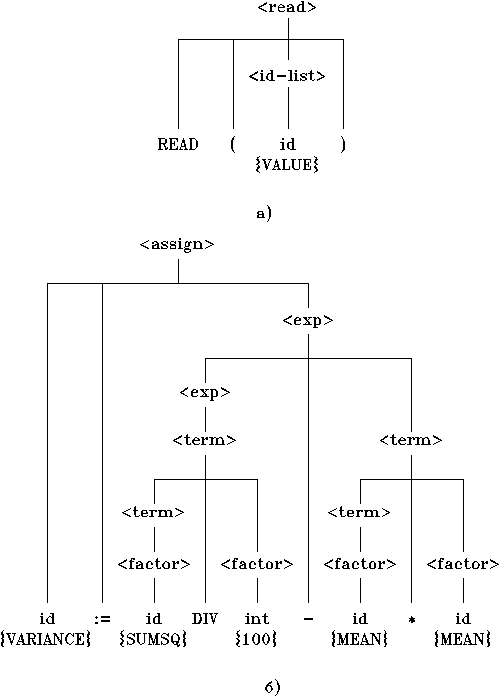
Рис. 3. Дерево грамматического разбора
для двух предложений программы на рис. 1
с использованием только что обсужденных двух правил вывода.
Правило вывода 9 на рис.2 дает определение синтаксиса предложения присваивания:
<assign> ::= id := <exp>
Это означает, что конструкция <assign> состоит из лексемы id , за которой следует лексема := , за кторой идет конструкция <exp>. Правило 10 дает определение конструкции <exp> :
<exp> ::= <term> | <exp> + <term> | <exp> - <term>
Используя те же соображения, что и при анализе конструкции <id-list>, мы видим, что это правило определяет конструкцию <ехр> как состоящую из любой последовательности конструкций <exp> и <term> , соединенных операторами плюс или минус. Аналогично правило 11 определяет конструкцию <term> как последовательность конструкций <fасtог>, разделенных знаками * или DIV. В соответствии с правилом 12 конструкция <fасtог> может состоять из идентификатора id или целого int , которое также распознается сканером, или из конструкции <ехр> , заключенной в круглые скобки.
На рис.3,б изображено дерево грамматического разбора для предложения 14 на рис.1, основанное на только что рассмотренных правилах вывода. Необходимо внимательно изучить этот рисунок, чтобы убедиться в правильном понимании того, как выполняется грамматический анализ исходного предложения на основе введенных грамматических правил.
Обратите внимание, что в соответствии с деревом грамматического разбора на рис.3,б умножение и деление производятся перед сложением или вычитанием. Прежде всего должны вычисляться термы SUMSQ DIV 100 и МЕАN * МЕАN, поскольку эти промежуточные результаты являются операндами (левым и правым поддеревом) операции вычитания. Иначе то же самое можно выразить, сказав, что операции умножения и деления имеют более высокий ранг, чем операции сложения и вычитания. Такое ранжирование операций является следствием того, как записаны правила 10-12.
Дерево грамматического разбора на рис.3 представляет собой единственно возможный результат анализа этих двух предложений в терминах грамматики, изображенной на рис.2. Для некоторых грамматик подобной единственности может не существовать. Если для одного и того же предложения можно построить несколько различных деревьев грамматического разбора, то соответствующая грамматика называется неоднозначной. При разработке компиляторов обычно предпочитают пользоваться однозначными грамматиками, поскольку в некоторых случаях неоднозначная грамматика оставляет сомнения относительно того, какой объектный код должен быть сгенерирован для анализируемого предложения.