

Изучаем.SQL
.pdf> ON e1.emp_id != e2.emp_id
> WHERE e1.title = 'Teller' AND e2.title = 'Teller';
+ + + + + + | fname | lname | vs | fname | lname | + + + + + +
| Sarah |
| Parker |
| VS |
| |
Chris |
| Tucker |
| |
| Jane |
| Grossman |
| VS |
| |
Chris |
| Tucker |
| |
| Thomas |
| Ziegler |
| VS |
| |
Chris |
| Tucker |
| |
| Samantha |
| Jameson |
| VS |
| |
Chris |
| Tucker |
| |
| Cindy |
| Mason |
| VS |
| |
Chris |
| Tucker |
| |
| Frank |
| Portman |
| VS |
| |
Chris |
| Tucker |
| |
| Beth |
| Fowler |
| VS |
| |
Chris |
| Tucker |
| |
| Rick |
| Tulman |
| VS |
| |
Chris |
| Tucker |
| |
| Chris |
| Tucker |
| VS |
| |
Sarah |
| Parker |
| |
| Jane |
| Grossman |
| VS |
| |
Sarah |
| Parker |
| |
| Thomas |
| Ziegler |
| VS |
| |
Sarah |
| Parker |
| |
| Samantha |
| Jameson |
| VS |
| |
Sarah |
| Parker |
| |
| Cindy |
| Mason |
| VS |
| |
Sarah |
| Parker |
| |
| Frank |
| Portman |
| VS |
| |
Sarah |
| Parker |
| |
| Beth |
| Fowler |
| VS |
| |
Sarah |
| Parker |
| |
| Rick |
| Tulman |
| VS |
| Sarah |
| Parker |
| |
|
... |
|
|
|
|
|
|
| Chris |
| Tucker |
| VS | Rick |
| Tulman |
| |
||
| Sarah |
| Parker |
| VS | Rick |
| Tulman |
| |
||
| Jane |
| Grossman |
| VS |
| Rick |
| Tulman |
| |
|
| Thomas |
| Ziegler |
| VS |
| Rick |
| Tulman |
| |
|
| Samantha |
| Jameson |
| VS |
| Rick |
| Tulman |
| |
|
| Cindy |
| Mason |
| VS |
| Rick |
| Tulman |
| |
|
| Frank |
| Portman |
| VS |
| Rick |
| Tulman |
| |
|
| Beth |
| Fowler |
| VS |
| Rick |
| Tulman |
| |
|
+ + + + + + 72 rows in set (0.01 sec)
Мы на правильном пути, но проблема здесь в том, что для каждой па ры (например, Сара Паркер (Sarah Parker) против Криса Такера (Chris Tucker)) имеется «обратная» пара (т. е. Крис Такер против Сары Пар кер). Один из способов достигнуть желаемого результата – использо вать условие соединения e1.emp_id < e2.emp_id, чтобы каждый опера ционист входил в пару только с теми, у кого ID сотрудника больше (можно также использовать e1.emp_id > e2.emp_id, если вам так больше нравится):
mysql> |
SELECT e1.fname, |
e1.lname, 'VS' vs, e2.fname, e2.lname |
|
> |
FROM employee e1 |
INNER JOIN employee e2 |
|
> |
ON e1.emp_id |
< |
e2.emp_id |
> |
WHERE e1.title |
= |
'Teller' AND e2.title = 'Teller'; |
+ + + + + + | fname | lname | vs | fname | lname | + + + + + +
| |
Chris |
| |
Tucker |
| |
VS |
| |
Sarah |
| |
Parker | |
| |
Chris |
| |
Tucker |
| |
VS |
| |
Jane |
| |
Grossman | |
| Chris |
| Tucker |
| VS |
| Thomas |
| Ziegler |
| |
| Chris |
| Tucker |
| VS |
| Samantha |
| Jameson |
| |
| Chris |
| Tucker |
| VS |
| Cindy |
| Mason |
| |
| Chris |
| Tucker |
| VS |
| Frank |
| Portman |
| |
| Chris |
| Tucker |
| VS |
| Beth |
| Fowler |
| |
| Chris |
| Tucker |
| VS |
| Rick |
| Tulman |
| |
| Sarah |
| Parker |
| VS |
| Jane |
| Grossman | |
|
| Sarah |
| Parker |
| VS |
| Thomas |
| Ziegler |
| |
| Sarah |
| Parker |
| VS |
| Samantha |
| Jameson |
| |
| Sarah |
| Parker |
| VS |
| Cindy |
| Mason |
| |
| Sarah |
| Parker |
| VS |
| Frank |
| Portman |
| |
| Sarah |
| Parker |
| VS |
| Beth |
| Fowler |
| |
| Sarah |
| Parker |
| VS |
| Rick |
| Tulman |
| |
| Jane |
| Grossman |
| VS |
| Thomas |
| Ziegler |
| |
| Jane |
| Grossman |
| VS |
| Samantha |
| Jameson |
| |
| Jane |
| Grossman |
| VS |
| Cindy |
| Mason |
| |
| Jane |
| Grossman |
| VS |
| Frank |
| Portman |
| |
| Jane |
| Grossman |
| VS |
| Beth |
| Fowler |
| |
| Jane |
| Grossman |
| VS |
| Rick |
| Tulman |
| |
| Thomas |
| Ziegler |
| VS |
| Samantha |
| Jameson |
| |
| Thomas |
| Ziegler |
| VS |
| Cindy |
| Mason |
| |
| Thomas |
| Ziegler |
| VS |
| Frank |
| Portman |
| |
| Thomas |
| Ziegler |
| VS |
| Beth |
| Fowler |
| |
| Thomas |
| Ziegler |
| VS |
| Rick |
| Tulman |
| |
| Samantha |
| Jameson |
| VS |
| Cindy |
| Mason |
| |
| Samantha |
| Jameson |
| VS |
| Frank |
| Portman |
| |
| Samantha |
| Jameson |
| VS |
| Beth |
| Fowler |
| |
| Samantha |
| Jameson |
| VS |
| Rick |
| Tulman |
| |
| Cindy |
| Mason |
| VS |
| Frank |
| Portman |
| |
| Cindy |
| Mason |
| VS |
| Beth |
| Fowler |
| |
| Cindy |
| Mason |
| VS |
| Rick |
| Tulman |
| |
| Frank |
| Portman |
| VS |
| Beth |
| Fowler |
| |
| Frank |
| Portman |
| VS |
| Rick |
| Tulman |
| |
| Beth |
| Fowler |
| VS |
| Rick |
| Tulman |
| |
+ + + + + + 36 rows in set (0.01 sec)
Теперь у нас есть список из 36 пар. Как раз столько, сколько должно быть при наличии девяти участников.
Сравнение условий соединения и условий фильтрации
Теперь мы знаем, что условия соединения относятся к подблоку on, то гда как условия фильтрации располагаются в блоке where. Однако SQL не налагает жестких ограничений на размещение условий, поэтому соз давать запросы следует очень внимательно. Например, следующий за прос соединяет две таблицы с помощью одного блока соединения и од ного условия фильтрации в блоке where:
mysql> SELECT a.account_id, a.product_cd, c.fed_id
> FROM account a INNER JOIN customer c> ON a.cust_id = c.cust_id
> WHERE c.cust_type_cd = 'B';
+ + + + | account_id | product_cd | fed_id | + + + +
| |
20 |
| CHK |
| 04 1111111 | |
|||
| |
21 |
| BUS |
| 04 1111111 |
| |
||
| |
22 |
| BUS |
| 04 2222222 |
| |
||
| |
23 |
| |
CHK |
| |
04 3333333 |
| |
| |
24 |
| |
SBL |
| |
04 4444444 |
| |
+ + + + 5 rows in set (0.08 sec)
Достаточно просто, но что произойдет, если по ошибке поместить усло вие фильтрации в подблок on, а не в блок where?
mysql> SELECT a.account_id, a.product_cd, c.fed_id
> FROM account a INNER JOIN customer c> ON a.cust_id = c.cust_id
> AND c.cust_type_cd = 'B';
+ + + + | account_id | product_cd | fed_id | + + + +
| |
20 |
| CHK |
| 04 1111111 | |
|||
| |
21 |
| BUS |
| 04 1111111 |
| |
||
| |
22 |
| BUS |
| 04 2222222 |
| |
||
| |
23 |
| |
CHK |
| |
04 3333333 |
| |
| |
24 |
| |
SBL |
| |
04 4444444 |
| |
+ + + + 5 rows in set (0.00 sec)
Как видите, второй вариант, в котором оба условия находятся в подбло ке on и нет блока where, обеспечивает аналогичные результаты. А что ес ли оба условия помещены в блок where, но блок from по прежнему ис пользует ANSI синтаксис соединения?
mysql> SELECT a.account_id, a.product_cd, c.fed_id
> FROM account a INNER JOIN customer c> WHERE a.cust_id = c.cust_id
> AND c.cust_type_cd = 'B';
+ + + + | account_id | product_cd | fed_id | + + + +
| |
20 |
| CHK |
| 04 1111111 | |
|||
| |
21 |
| BUS |
| 04 1111111 |
| |
||
| |
22 |
| BUS |
| 04 2222222 |
| |
||
| |
23 |
| |
CHK |
| |
04 3333333 |
| |
| |
24 |
| |
SBL |
| |
04 4444444 |
| |
+ + + + 5 rows in set (0.00 sec)
Сервер MySQL снова сгенерировал тот же результирующий набор. Рас положить условия на соответствующих местах, чтобы запрос был пра вильно понят и обработан, – ваша задача.
Упражнения
Следующие упражнения призваны протестировать понимание внут ренних соединений. Решения приведены в приложении С.
5.1
Заполните в следующем запросе пробелы (обозначенные как <число>), чтобы получить такие результаты:
mysql> |
SELECT e.emp_id, e.fname, |
e.lname, b.name |
|
> |
FROM |
employee e INNER JOIN <1> b |
|
> |
ON |
e.assigned_branch_id |
= b.<2>; |
+ + + + + | emp_id | fname | lname | name | + + + + +
| |
1 |
| |
Michael |
| Smith |
| Headquarters |
| |
| |
2 |
| |
Susan |
| Barker |
| Headquarters |
| |
| |
3 |
| |
Robert |
| Tyler |
| Headquarters |
| |
| |
4 |
| |
Susan |
| Hawthorne |
| Headquarters |
| |
| |
5 |
| |
John |
| Gooding |
| Headquarters |
| |
| |
6 |
| |
Helen |
| Fleming |
| Headquarters |
| |
| |
7 |
| |
Chris |
| Tucker |
| Headquarters |
| |
| |
8 |
| |
Sarah |
| Parker |
| Headquarters |
| |
| |
9 |
| |
Jane |
| Grossman |
| Headquarters |
| |
| |
10 |
| |
Paula |
| Roberts |
| Woburn Branch | |
|
| |
11 |
| |
Thomas |
| Ziegler |
| Woburn Branch | |
|
| |
12 |
| |
Samantha |
| Jameson |
| Woburn Branch | |
|
| |
13 |
| |
John |
| Blake |
| Quincy Branch | |
|
| |
14 |
| |
Cindy |
| Mason |
| Quincy Branch | |
|
| |
15 |
| |
Frank |
| Portman |
| Quincy Branch | |
|
| |
16 |
| |
Theresa |
| Markham |
| So. NH Branch | |
|
| |
17 |
| |
Beth |
| Fowler |
| So. NH Branch | |
|
| |
18 |
| |
Rick |
| Tulman |
| So. NH Branch | |
|
+ + + + + 18 rows in set (0.03 sec)
5.2
Напишите запрос, по которому для каждого клиента физического ли ца (customer.cust_type_cd = 'I') возвращаются ID счета, федеральный ID (customer.fed_id) и тип созданного счета (product.name).
5.3
Создайте запрос для выбора всех сотрудников, начальник которых при писан к другому отделу. Извлеките ID, имя и фамилию сотрудника.
Работа с множествами
Хотя можно работать и с отдельными строками данных, реляционные БД на самом деле приспособлены для работы с наборами (множества ми). Вы уже видели, как можно создавать таблицы посредством запро сов или подзапросов, делать их постоянными с помощью выражений insert и сводить вместе через соединения. В данной главе будут иссле дованы комбинации нескольких таблиц с использованием различных операторов работы с множествами.
Основы теории множеств
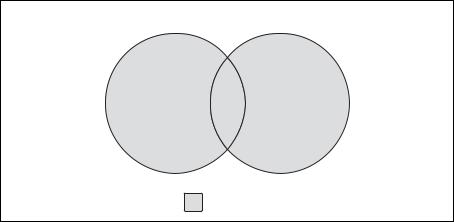
Во многих странах основы теории множеств включены в программы начального курса математики. Возможно, кое что на рис. 6.1 покажет ся вам знакомым.
A B
= A union B
Рис. 6.1. Операция объединения
Заштрихованные области на рис. 6.1 представляют объединение (union) множеств А и В, которое является комбинацией двух множеств (при этом все пересекающиеся области включены только один раз). Что то припоминаете? Если да, то наконец появился шанс применить эти зна ния на практике. Если нет, не волнуйтесь, потому что без труда пойме те все, взглянув на пару диаграмм.
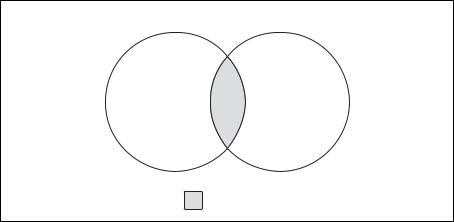
Представим множества (А и В) в виде кругов; область перекрытия представляет подмножество данных, общих для обоих множеств (рис. 6.1). Поскольку без перекрытий множеств данных теория мно жеств совершенно неинтересна, я буду использовать такую же диа грамму для иллюстрации всех операций с множествами. Есть другая операция, результат которой – только перекрытие двух множеств данных. Эту операцию называют пересечением (intersection) (рис. 6.2).
Множество данных, получаемое в результате пересечения множеств А и В, – это собственно область перекрытия между двумя множествами. Если два множества не перекрываются, операция пересечения дает пустое множество.
Третья и последняя операция с множествами (рис. 6.3) известна как операция разности (except). На рис. 6.3 показан результат операции A except B, который представляет собой множество А минус все пересе чения с множеством В. Если два множества не пересекаются, в резуль тате операции A except B будет получено полное множество А.
Применяя эти три операции или их сочетания, можно получать любые нужные результаты. Например, представим, что требуется создать множество, показанное на рис. 6.4.
Искомое множество включает множества А и В без области пересече ния. Такое множество не может быть получено в результате ни одной из трех представленных ранее операций. Понадобится сначала создать
A B
= A intersect B
Рис. 6.2. Операция пересечения
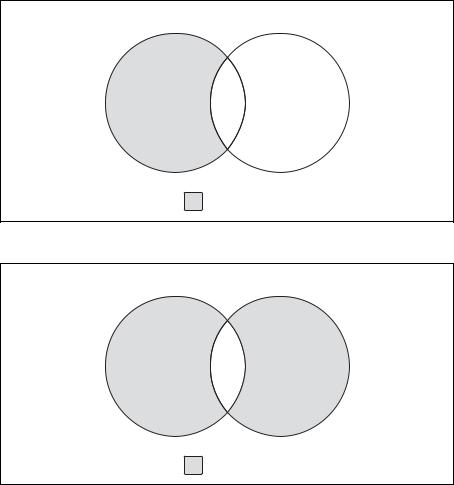
A B
= A except B
Рис. 6.3. Операция разности
A B
= ????
Рис. 6.4. Загадочное множество данных
множество данных, объединяющее множества А и В целиком, а затем применить вторую операцию, чтобы удалить область пересечения. Ес ли составное множество описать как A union B, а область пересечения – как A intersect B, операция, необходимая для формирования представ ленного на рис. 6.4 множества, выглядела бы так:
(A union B) except (A intersect B)
Конечно, часто есть несколько способов получения одного и того же результата. Аналогичное множество можно было бы получить с помо щью следующей операции:
(A except B) union (B except A)
Эти концепции, наглядно представленные диаграммами, достаточно просты для понимания. В следующих разделах будет показано, как эти идеи реализуются в реляционных СУБД с помощью SQL операто ров работы с множествами.
Теория множеств на практике
Круги, представляющие множества данных на диаграммах предыду щего раздела, никак не отражают содержимое множеств. Однако при работе с реальными данными необходимо описывать структуру таб лиц, если предполагается их комбинирование. Представим, например, что произошло бы при попытке сгенерировать объединение описанных ниже таблиц product и customer:
mysql> DESC product; |
|
|
|
|
|
|
|
|
+ + + + + + + |
||||||||
| Field |
| |
Type |
| Null |
| Key |
| |
Default |
| Extra | |
|
+ + + + + + + |
||||||||
| product_cd |
| |
varchar(10) |
| |
| PRI | |
|
| |
| |
|
| name |
| |
varchar(50) |
| |
| |
| |
|
| |
| |
| product_type_cd | |
varchar(10) |
| |
| MUL |
| |
|
| |
| |
|
| date_offered |
| |
date |
| YES |
| |
| NULL |
| |
| |
|
| date_retired |
| date |
| YES |
| |
| NULL |
| |
| |
||
+ + + + + + + |
||||||||
5 rows in set (0.23 |
sec) |
|
|
|
|
|
|
|
mysql> DESC customer; + + + + + + + | Field | Type | Null | Key | Default | Extra | + + + + + + +
| cust_id |
| int(10) unsigned |
| |
| PRI | NULL |
| auto_increment | |
||
| fed_id |
| varchar(12) |
| |
| |
| |
| |
| |
| cust_type_cd |
| enum('I','B') |
| |
| |
| I |
| |
| |
| address |
| varchar(30) |
| YES |
| |
| NULL |
| |
| |
| city |
| varchar(20) |
| YES |
| |
| NULL |
| |
| |
| state |
| varchar(20) |
| YES |
| |
| NULL |
| |
| |
| postal_code |
| varchar(10) |
| YES |
| |
| NULL |
| |
| |
+ + + + + + + 7 rows in set (0.04 sec)
После комбинирования первый столбец результирующей таблицы был бы комбинацией столбцов product.product_cd и customer.cust_id, второй – комбинацией столбцов product.name и customer.fed_id и т. д. Хотя неко торые пары столбцов сочетаются без труда (т. е. два столбца числового типа), неясно, как должны объединяться пары столбцов разного типа, такие как числовой со строковым или строковый с датой. Кроме того, в шестом и седьмом столбцах комбинированной таблицы будут только данные шестого и седьмого столбцов таблицы customer, поскольку в таб лице product всего пять столбцов. Очевидно, что таблицы, подлежащие объединению, должны обладать некоторой общностью.
Поэтому при применении операций с множествами к реальным табли цам необходимо соблюдать такие правила:
•В обеих таблицах должно быть одинаковое число столбцов.
•Типы данных столбцов двух таблиц должны быть одинаковыми (или сервер должен уметь преобразовывать один тип в другой).
Эти правила позволяют уяснить, что представляет собой «перекрытие данных» на практике. Чтобы комбинируемые строки двух таблиц счи тались одинаковыми, каждая пара столбцов комбинируемых таблиц должна содержать одинаковые строки, числа или даты.
Операции с множествами осуществляются путем помещения операто ра работы с множествами (set operator) между двух выражений se lect, как показано ниже:
mysql> SELECT 1 num, 'abc' str
> UNION
> SELECT 9 num, 'xyz' str; + + +
| num | str | + + + | 1 | abc | | 9 | xyz | + + +
2 rows in set (0.02 sec)
Каждый запрос формирует таблицу, состоящую из единственной стро ки с числовым и строковым столбцами. Оператор работы с множества ми, в данном случае union, указывает серверу БД объединить все строки двух таблиц. Таким образом, конечная таблица включает две строки и два столбца. Такой запрос называют составным запросом (compound query), потому что он объединяет несколько независимых запросов. Как будет показано позже, если для получения окончательного ре зультата требуется выполнить несколько операций с множествами, со ставные запросы могут включать больше двух запросов.
Операторы работы с множествами
Язык SQL включает три оператора работы с множествами, позволяю щие осуществлять всевозможные операции над множествами, уже упо мянутые в этой главе. Кроме того, у каждого из этих операторов есть две разновидности: первая включает дублирующие данные, а вторая удаляет их (но необязательно все). В следующих разделах даны опреде ления всех операторов и показано их применение.
Оператор union
Операторы union (объединить) и union all (объединить все) позволяют комбинировать несколько таблиц. Разница в том, что если требуется объединить две таблицы, включая в окончательный результат все их
строки, даже дублирующие значения, нужно использовать оператор union all. Благодаря оператору union all в конечной таблице всегда бу дет столько строк, сколько во всех исходных таблицах в сумме. Эта опе рация – самая простая из всех операций работы с множествами (с точки зрения сервера), поскольку серверу не приходится проверять перекры вающиеся данные. Следующий пример демонстрирует применение опе ратора union all для формирования полного множества данных клиен тов из двух таблиц подтипов клиентов:
mysql> SELECT cust_id, lname name
> FROM individual> UNION ALL
> SELECT cust_id, name> FROM business;
+ + + | cust_id | name | + + +
| |
1 |
| Hadley |
| |
| |
2 |
| Tingley |
| |
| |
3 |
| Tucker |
| |
| |
4 |
| Hayward |
| |
| |
5 |
| Frasier |
| |
| |
6 |
| Spencer |
| |
| |
7 |
| Young |
| |
| |
8 |
| Blake |
| |
| |
9 |
| Farley |
| |
| |
10 |
| Chilton Engineering |
| |
|11 | Northeast Cooling Inc. |
| |
12 |
| |
Superior Auto |
Body |
| |
| |
13 |
| |
AAA Insurance |
Inc. |
| |
+ + + 13 rows in set (0.04 sec)
Запрос возвращает все 13 клиентов: 9 строк поступают из таблицы in dividual (физические лица), а остальные 4 – из таблицы business (юри дические лица). Таблица business включает всего один столбец с назва нием компании, а в таблице individual присутствуют два столбца: имя и фамилия физического лица. В данном случае из таблицы individual берется только фамилия.
Проверим, что оператор union all не удаляет дублирующие значения. Для этого приведем такой же запрос, как в предыдущем примере, но с дополнительным запросом к таблице business:
mysql> |
SELECT cust_id, lname name |
> |
FROM individual |
> |
UNION ALL |
> |
SELECT cust_id, name |
> |
FROM business |
> |
UNION ALL |
> |
SELECT cust_id, name |
> |
FROM business; |