

Свойства нормального распределения
Как уже отмечалось,
закон распределения показывает, как
часто встречаются те или иные значения
случайной величины (его вероятность).
Нормальное распределение имеет
симметричный колоколообразный вид и
обладает рядом свойств. При таком
распределении среднее значение случайной
величины встречается наиболее часто,
оно же находится ровно в середине
ранжированной выборки - делит ее пополам,
т.е.
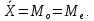
По мере удаления от среднего вправо и влево частота встречаемости симметрично уменьшается.
При изменении только среднего значения форма кривой не меняется, а только смещается влево или вправо по горизонтальной оси (рисунок 12А).
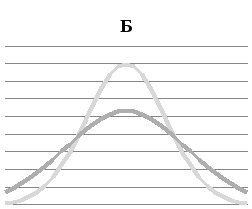
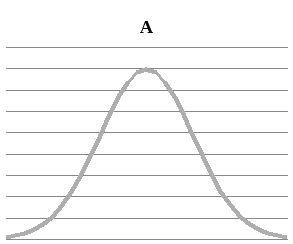
Рисунок 12. Свойства нормального распределения
При изменении среднеквадратического отклонения изменяется ширина кривой: малым σ соответствуют узкие вытянутые вверх кривые, большим σ – более пологие, со слабо выраженными вершинами (рисунок 12Б).
Все возможные нормальные распределения отличаются друг от друга средними значениями и среднеквадратическими отклонениями.
Если случайная величина имеет нормальное распределение, то
68,26% всех значений генеральной совокупности лежит в интервале
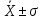
95,44% всех значений генеральной совокупности лежит в интервале
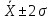
99,73% всех значений генеральной совокупности лежит в интервале
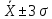
Значения, лежащие
за пределами
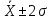 можно
считать выбросами, а значения, лежащие
за пределами
можно
считать выбросами, а значения, лежащие
за пределами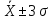 ,
практически всегда являются выбросами.
,
практически всегда являются выбросами.
Данное
свойство можно использовать для
определения референтных величин. В
качестве нормы в здоровой популяции
берется интервал
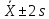 ,
гдеs
– выборочное стандартное отклонение
(это статистический метод определения
нормы, есть еще терапевтический метод).
,
гдеs
– выборочное стандартное отклонение
(это статистический метод определения
нормы, есть еще терапевтический метод).
|
Пример. Известно, что физиологические и биохимические показатели у здорового человека значительно варируют в зависимости от ряда факторов: региона проживания, типа питания, условий труда расовой принадлежности и т.д. В литературе активно обсуждается необходимость разработки региональных норм. Не вдаваясь в суть этих дискуссий, рассмотрим на следующем примере, как это можно сделать. Норма содержания железа в крови у женщин составляет 8,95 – 30,4 мкмоль/л. Предположим, в интересующем нас географическом районе было проведено выборочное обследование здоровых женщин, результаты которого сведены в таблицу 10.
Таблица 10. Результаты статобработки
Согласно этим данным региональная норма составляет 15,3-27,3 мкмоль/л. |
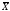
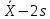
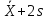
Теория проверки статистических гипотез
Важное место в практике врача занимает процесс сравнения. По сути, вся его деятельность – это постоянное сравнение: больного со здоровым, состояния организма до и после лечения, эффективности диагностических или лечебных методов и т.д. При этом надо учитывать, что если врачу важны результаты отдельного больного, то общество в целом интересуют эффекты на популяционном уровне (на уровне генеральной совокупности), т.е. поможет ли новый препарат всем больным данной нозологии, сколько процентов из всех больных правильно диагностируется с помощью нового метода, как часто встречается то или иное заболевание в различных популяциях.
Как правило, ответить на эти вопросы можем, лишь опираясь на выборочные данные, на выборку. Мы уже указывали, что выборочные данные не совсем точно отражают истинное положение дел - делая по ним то или иное заключение, надо учитывать, что есть вероятность ошибиться и эта вероятность может быть достаточно большой. Исследователь сам должен решить устраивает ли его такая ошибка, принимать или не принимать эти результаты.
В связи с этим в статистике выработана специальная процедура, которая носит название проверка статистических гипотез. Т.е. при наличии выборочных данных предварительно высказываются предположения – гипотезы. Различают нулевую Н(0) и альтернативную Н(1) гипотезы. Нулевая гипотеза содержит предположение о равенстве (отсутствии эффекта), о соответствии, о независимости. Например, о равенстве средних значений гемоглобина у жителей двух различных районов (т.е. эффект от места жительства отсутствует). Или - распределение случайной величины соответствует нормальному закону. Или - заболеваемость не зависит от профессиональной принадлежности.
Для исследователя больший интерес представляет альтернативная гипотеза, поскольку она соответствует целям большинства исследований – найти различия, зависимости, несоответствия.
Максимальная вероятность ошибки, которую может себе позволить исследователь, принимая альтернативную гипотезу (т.е. отклонив нулевую) называется уровнем значимости и обозначается буквой α (альфа). Эту ошибку также называют ошибкой I рода.
Уровень значимости – это вероятность того, что мы сочли различия существенными, в то время как они на самом деле случайны.
Уровень значимости α задается самим исследователем, исходя из сути решаемой проблемы. В медико-биологических задачах обычно принимают α =0,05 (5%), 0,01(1%) или 0,001 (0,1%).
При α =0,05 если мы примем альтернативную гипотезу, то в более чем 95% случаях гипотеза будет верна, а в менее чем 5% - ошибочна.
Также может возникнуть ошибка, если мы принимаем нулевую гипотезу, в то время как она не верна, другими словами, не находим существующие различия. Эта ошибка II рода, ее вероятность обозначается буквой β. Величина (1-β) называется мощностью критерия – это способность критерия найти различия там, где они заведомо существуют.
Для принятия или отклонения гипотезы используются статистические критерии. Они подразделяются на два вида:
параметрические критерии - используются если
признаки количественные
совокупности имеют нормальное распределение
дисперсии совокупностей не сильно различаются
непараметрические критерии - используются если
признаки количественные, но распределение не соответствует нормальному
или если распределение неизвестно и нельзя его проверить (т.е. n<30)
или если признаки качественные
Выбор критерия определяется также тем, являются ли сравниваемые выборки зависимыми или независимыми.
Независимые выборки – это выборки, состоящие из разных объектов, причем значения случайной величины в одной выборке не зависят от его значений в другой выборке. Например, сравниваются выборки, состоящие из больных и здоровых, или одна группа принимает один препарат, вторая группа – другой, выборки мужчин и женщин, строителей и шахтеров и т.д.
Зависимые выборки состоят из одних и тех же объектов, исследованных «до» и «после». Например, гемоглобин у больных до и после лечения, ЧСС спортсменов до и после физической нагрузки, АД у гипертоников в динамике по годам и т.д.
Гипотезы можно проверить двумя путями