

3.2. Обработка выборки в среде Excel.
 При
большом объёме выборки её анализ требует
большого объёма вычислений, поэтому
естественно проводить его за компьютером.
Имеется большое число программных
средств, как специально предназначенных
для статистического анализа, так и
содержащихся в у
При
большом объёме выборки её анализ требует
большого объёма вычислений, поэтому
естественно проводить его за компьютером.
Имеется большое число программных
средств, как специально предназначенных
для статистического анализа, так и
содержащихся в у ниверсальных
программах в качестве подпрограмм и
опций. Достаточно возможностей для
этого предоставляет, в частности,
доступная всем программаExcel.
Команды для
проведения статистического анализа
можно найти в меню «Сервис
ниверсальных
программах в качестве подпрограмм и
опций. Достаточно возможностей для
этого предоставляет, в частности,
доступная всем программаExcel.
Команды для
проведения статистического анализа
можно найти в меню «Сервис![]() Анализ
данных» и в меню «Функции
Анализ
данных» и в меню «Функции![]() Статистические»
и «Функции
Статистические»
и «Функции![]() Работа
с базами данных».
Работа
с базами данных».
Т аблица
1.
аблица
1.
Рассмотрим
работу в этой среде на следующем примере.
В лабораторном практикуме группа из 25
студентов определяла концентрацию
некоторого вещества в выданном им
растворе. Каждый из них сделал по 4
параллельных определения. Их результаты,
округлённые до 0,5 г/л я занёс в таблицу
Excel
(табл.1).У
меня образовался массив, содержащий 4
столбца B,C,D
и E,
и 25 строк с №2 до №26. Далее я хочу найти
минимальное число из этого массива –
нижнюю границу выборки. Я щёлкаю по
пустой ячейке, в которой хочу найти
ответ, затем навожу курсор на «![]() »,
и нажимаю левую клавишу мыши. Открывается
окно выбора функций – «Мастер функций».
В разделе «Категории» я открываю
«статистические» и нахожу тамМИН.
»,
и нажимаю левую клавишу мыши. Открывается
окно выбора функций – «Мастер функций».
В разделе «Категории» я открываю
«статистические» и нахожу тамМИН.


После щелчка мышью по этому названию и “OK” открывается диалоговое окно «Аргументы функции» с пометкой МИН. В окошко, помеченное «Число 1», можно ввести сами числа, что, конечно, неудобно. Вместо этого я щёлкаю мышью по крайней левой верхней клетке массива, затем нажимаю “Shift” и одновременно щёлкаю по крайней правой нижней клетке. При этом в вышеуказанном окошке появляются границы массива в виде “$B$2:$E$26. Ответ «300,5» появляется сразу, а при щелчке «OK» - в заготовленной клетке. Точно так же я могу применить эту функцию к любой прямоугольной части этого массива, вызвав саму функцию МИН (теперь её позывной можно найти в категории «Последние») и отметив, как описано выше, щелчками мыши, клетки в начале и конце выбранной части массива. Впрочем, выделять массив можно и движением мыши, если сначала навести курсор на начало массива, нажать левую клавишу мыши, и, не снимая нажатия, провести курсор до конечной точки массива.
Конечно, такое подробное описание вызовет улыбку у продвинутого пользователя, но, возможно, среди читателей есть и такие, которые впервые в жизни откроют документ Excel.
Для краткого описания действий при использовании других функций будем использовать следующие обозначения:
ЩАа – щелчок по клетке начала диапазона,
ЪЩЯя - щелчок по клетке конца диапазона с одновременным нажатием Shift,
ЩСс – щелчок по свободной ячейке, в которой будет указан результат.
![]() ,
серв., дигр., адат, стат. – щелчки по
значкам
,
серв., дигр., адат, стат. – щелчки по
значкам
![]() ,
«сервис», «диаграмма», «анализ данных»,
«статистические» соответственно.
Напомним, что если какая-либо функция
используется повторно, то быстрее найти
её не через «статистические», а через
«последние».
,
«сервис», «диаграмма», «анализ данных»,
«статистические» соответственно.
Напомним, что если какая-либо функция
используется повторно, то быстрее найти
её не через «статистические», а через
«последние».
Итак, считаем, что в таблицу Excel внесены данные выборки в виде строки, столбца, или двумерного массива. Цели и действия представлены в таблице 2.
Таблица 2.
|
Что требуется найти |
Действия |
|
Объём выборки |
ЩСс, |
|
Нижнюю границу |
ЩСс, |
|
Верхнюю границу |
ЩСс, |
|
Среднее арифметическое |
ЩСс, |
|
Моду |
ЩСс, |
|
Медиану |
ЩСс, |
|
Нижний квартиль |
ЩСс, |
|
Верхний квартиль |
ЩСс, |
|
Выборочную
дисперсию
|
ЩСс, |
|
|
ЩСс, |
|
Доверительный интервал для среднего |
ЩСс, |
|
Асимметрию |
ЩСс, |
|
Эксцесс |
ЩСс, |
В таблице 1 в столбцах F-I вы видите результаты выполнения соответствующих функций для каждой из 25 строк массива. При этом нет необходимости вводить формулу функции в каждую строку отдельно – достаточно ввести её в первую строку, а в окошко аргументов ввести координаты начала и конца этой строки:
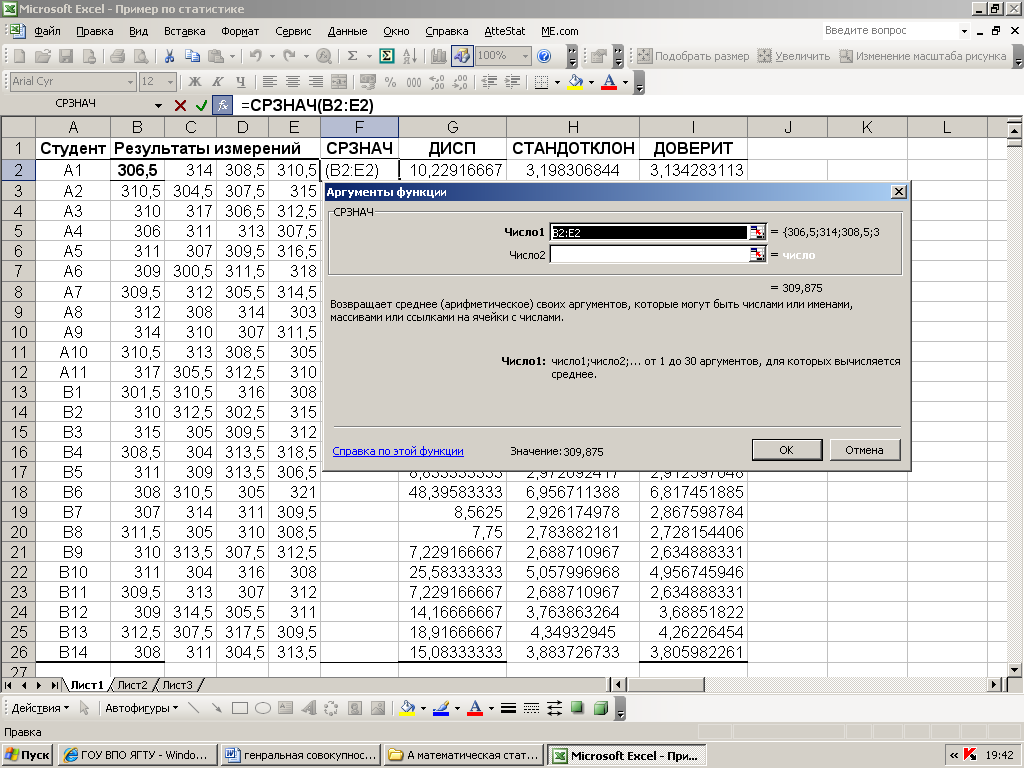
После
нажатия «![]() »
в ячейке, в которую введена данная
формула, появляется соответствующий
результат:
»
в ячейке, в которую введена данная
формула, появляется соответствующий
результат:

Если теперь навести курсор на чёрный квадратик в нижнем правом углу этой ячейки, и при нажатой левой клавише мыши провести его вдоль столбца до последней строки массива данных, то после отпускания клавиши весь столбец заполнится результатами, полученными для всех остальных строк по той же формуле.
Для
группировки данных и получения
интервального ряда можно использовать
функцию ЧАСТОТА.
Для её
применения
сначала
формируем столбец интервалов. Для нашего
примера, в котором объём выборки
![]() ,
,![]() ,
удобно выборку разбить на 7 равных
интервалов шириной 3 . При этом в ячейки
для массива интервалов вводим только
значения верхних границ интервалов.
Так, в ячейку
,
удобно выборку разбить на 7 равных
интервалов шириной 3 . При этом в ячейки
для массива интервалов вводим только
значения верхних границ интервалов.
Так, в ячейку![]() я внёс число 303 для интервала
я внёс число 303 для интервала![]() ,
в
,
в![]() - число 306 для интервала
- число 306 для интервала![]() ,
…, в
,
…, в![]() - 321 для интервала
- 321 для интервала![]() .
Затем я выделяю свободную ячейку
.
Затем я выделяю свободную ячейку![]() ,
и щёлкаю по
,
и щёлкаю по![]() .
Появляется мастер функций, в котором я
нахожуЧАСТОТА
и раскрываю
шаблон для ввода аргументов. После
ввода вышеописанным способом границ
массива данных щёлкаем по окну массив
интервалов и
выделяем для ввода ячейки
.
Появляется мастер функций, в котором я
нахожуЧАСТОТА
и раскрываю
шаблон для ввода аргументов. После
ввода вышеописанным способом границ
массива данных щёлкаем по окну массив
интервалов и
выделяем для ввода ячейки
![]() .
Обратите внимание, что выделена одна
дополнительная ячейка, как этого требует
синтаксис функции.
.
Обратите внимание, что выделена одна
дополнительная ячейка, как этого требует
синтаксис функции.
 После
нажатия
После
нажатия
![]() в ячейке
в ячейке![]() появляется число вариант со значением
появляется число вариант со значением![]() ,
,![]() .
Для вывода остальных значений
.
Для вывода остальных значений![]() надо выделить ячейки
надо выделить ячейки![]() ,
после чего нажать клавишу
,
после чего нажать клавишу![]() ,
а затем
,
а затем![]() .
В результате в столбце
.
В результате в столбце![]() и появятся все компоненты вектора
частот.
и появятся все компоненты вектора
частот.
|
ЧАСТОТА | |
|
303 |
4 |
|
306 |
12 |
|
309 |
23 |
|
312 |
31 |
|
315 |
21 |
|
318 |
7 |
|
321 |
2 |
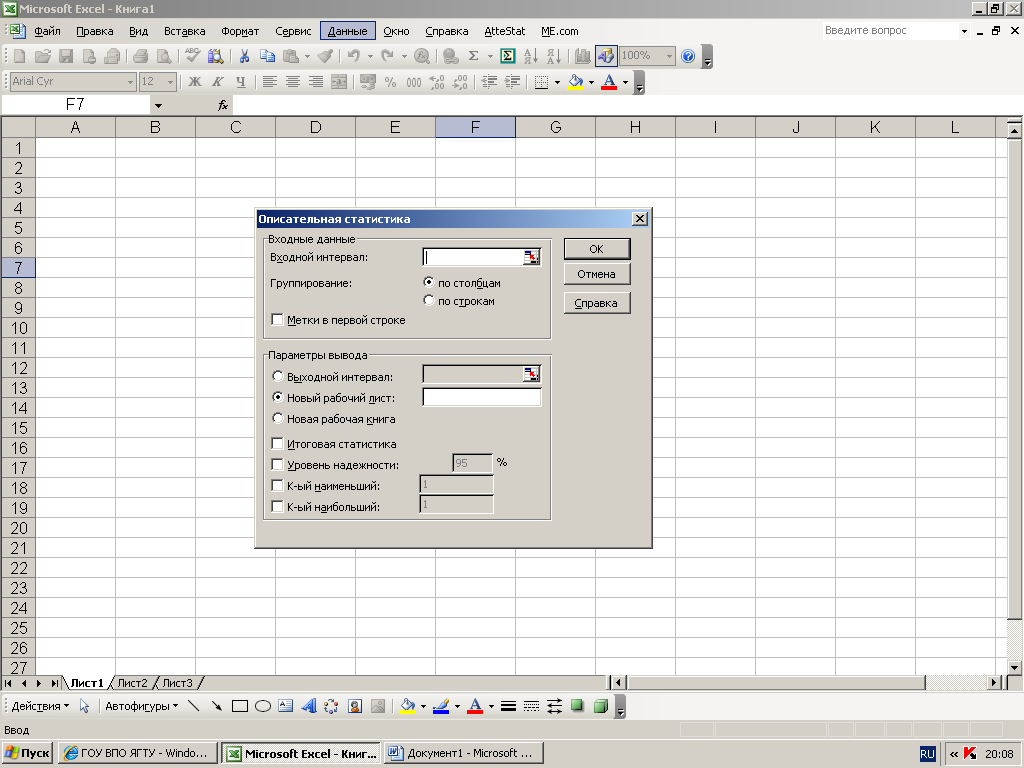
Рассмотрим
теперь, какие возможности для первичной
обработки выборки имеются в меню
«сервис
![]() анализ данных». Раскроем диалоговое
окно«описательная
статистика».
анализ данных». Раскроем диалоговое
окно«описательная
статистика».
Первая строка «Входной интервал» нам уже знакома: данные в неё можно внести действиями ЩАа, ЪЩЯя, или движениями мыши с нажатой правой кнопкой, или непосредственно введя в окошко номера левой верхней и правой нижней ячеек массива, разделённые двоеточием Аа:Яя. Далее предлагается выбрать группировку – «По строкам» или «По столбцам». Дело в том, что эта «описательная статистика» может обрабатывать одновременно большое количество выборок, каждая из которых может быть введена либо в виде строки, либо в виде столбца. Поэтому, если мы выделим массив, содержащий 25 строк и 4 столбца, то программа не будет рассматривать его как одну выборку, содержащую 100 вариант. Если мы пометим окошко «По столбцам», то программа будет обрабатывать массив как 4 выборки по 25 вариант в каждой. Соответственно, при флажке «По строкам» мы получим обработку 25 выборок по 4 варианта. Далее следует окошко «Метки в первой строке/столбце». Если его не помечать, то результаты обработки каждой из выборок будут помечены надписями «Строка (Столбец) 1», «Строка (Столбец) 2», «Строка (Столбец)3»… .Если же мы хотим , чтобы результаты были обозначены иначе, (например, фамилиями студентов), то мы при вводе указаний массива данных в строку Входной диапазон должны захватить и стоящий перед ним столбец (строку) меток (фамилий или номеров опытов в данном примере). На этом ввод данных завершается.
Куда выводить результаты:
|
Строка1 | |
|
Среднее |
309,875 |
|
Стандартная ошибка |
1,599153422 |
|
Медиана |
309,5 |
|
Мода |
#Н/Д |
|
Стандартное отклонение |
3,198306844 |
|
Дисперсия выборки |
10,22916667 |
|
Эксцесс |
-0,02453947 |
|
Асимметричность |
0,598903954 |
|
Интервал |
7,5 |
|
Минимум |
306,5 |
|
Максимум |
314 |
|
Сумма |
1239,5 |
|
Счет |
4 |
Что выводить.
При установке флажка «Итоговая статистика» для каждой выборки будет выведена таблица такого вида:
В
этой таблице под стандартным отклонением
понимается величина выборочного
стандарта
![]() ,
под стандартной ошибкой – выборочный
стандарт среднего
,
под стандартной ошибкой – выборочный
стандарт среднего![]() ,
интервал – разность между максимальным
и минимальным значениями выборки, сумма
– сумма всех значений выборки, счёт –
объём выборки. Остальные термины
пояснения не требуют.
,
интервал – разность между максимальным
и минимальным значениями выборки, сумма
– сумма всех значений выборки, счёт –
объём выборки. Остальные термины
пояснения не требуют.
Если
активизировать окошко «Уровень
надёжности»,
то выводится строка со значением
полуширины симметричного доверительного
интервала, соответствующим указанной
в этом окошке доверительной вероятности
и равным произведению
![]() на соответствующий квантиль распределения
Стьюдента:
на соответствующий квантиль распределения
Стьюдента:
|
Уровень надежности(95,0%) |
5,089219898 |
Активизация окошек К-ый наименьший и К-ый наибольший позволяет выводить к-ое в порядке возрастания и (или) к-ое в порядке убывания значения в выборке, соответствующие указанным номерам. Значениям к=1 соответствуют минимальное и максимальное значения вариант.

Обратимся
теперь к графическому изображению
данных. Для этого в меню Анализ
данных есть
функция Гистограмма,
в диалоговом окне которой в окошко
Входной
интервал вводим
одним из описанных ранее способов номера
ячеек начала и конца массива данных.
Затем в окошко Интервал
карманов вводим
таким же образом номера массива, в
котором указаны верхние границы
интервалов, на которые мы решили разбить
выборку (см. выше описание функции
Частота).
Флажок Метки
надо устанавливать только в том случае,
если в массив данных включён и столбец
меток. Как и в вышеописанных функциях
ставим флажок Новый
лист или
Новая книга (с
указанием номера или без), или Выходной
интервал. В
последнем случае в активизированное
окошко вводим номер левой верхней ячейки
диапазона вывода результата. Игнорируя
надпись Парето,
помечаем
Интегральный процент и
Вывод графика.
![]() выводит нам
во-первых,
таблицу, два первых столбца, как и после
исполнения функции Частота
представляют
интервальный вариационный ряд, а третий
столбец – аналог интегральной функции
распределения, показывает долю вариант
в выборки, имеющих значение меньшее или
равное указанного в первом столбце.
Кроме этого, появляется и графическое
изображение – гистограмма и график
интегрального процента. Можно редактировать
это изображение, но здесь мы не будем
рассматривать все многочисленные
возможности этого.
выводит нам
во-первых,
таблицу, два первых столбца, как и после
исполнения функции Частота
представляют
интервальный вариационный ряд, а третий
столбец – аналог интегральной функции
распределения, показывает долю вариант
в выборки, имеющих значение меньшее или
равное указанного в первом столбце.
Кроме этого, появляется и графическое
изображение – гистограмма и график
интегрального процента. Можно редактировать
это изображение, но здесь мы не будем
рассматривать все многочисленные
возможности этого.

