

Избыточность кода.
Каждый конкретный корректирующий код не гарантирует исправления любой комбинации ошибок. Коды предназначены для исправления комбинации ошибок, наиболее вероятных для заданного канала и наиболее опасных по последствиям.
Если характер и уровень помехи отличаются от предполагаемых, эффективность применения кода резко снизится. Применение корректирующего кода не может гарантировать безошибочного приема, но дает возможность повысить вероятность получения на выходе правильного результата.
О дной
из основных характеристик корректирующего
кода является избыточность кода, которую
можно рассчитать по общей формуле
(1.26). Однако в случае блоковых кодов
удобнее пользоваться более простыми
формулами, указывающими степень удлинения
кодовой комбинации для достижения
определенной корректирующей способности.
Если на каждыеn
символов выходной последовательности
кодера приходится k
информационных и (n-k)
проверочных, то относительная избыточность
кода может быть выражена:
дной
из основных характеристик корректирующего
кода является избыточность кода, которую
можно рассчитать по общей формуле
(1.26). Однако в случае блоковых кодов
удобнее пользоваться более простыми
формулами, указывающими степень удлинения
кодовой комбинации для достижения
определенной корректирующей способности.
Если на каждыеn
символов выходной последовательности
кодера приходится k
информационных и (n-k)
проверочных, то относительная избыточность
кода может быть выражена:
В
первом случае
![]() .
Во втором выражении
.
Во втором выражении![]()
Коды, обеспечивающие заданную корректирующую способность при минимально возможной избыточности, называются оптимальными.
Однако не всегда целесообразно стремиться к использованию кодов, близких к оптимальным. Необходимо учитывать другой не менее важный показатель качества корректирующего кода – сложность технической реализации процессов кодирования и декодирования. Так, в случае использования надежной и высокоскоростной линии связи для повышения общей надежности СПИ более целесообразно использовать коды с большой избыточностью, но зато требующих наиболее простую (и, следовательно, надежную) техническую реализацию кодирующих и декодирующих устройств.
Краткая характеристика блоковых и непрерывных кодов.
Рассмотрим классификацию помехоустойчивых кодов.

Рис. 6.3. Классификация основных помехоустойчивых кодов.
У линейных кодов значения проверочных символов определяются в результате проведения линейных операций над определенными информационными символами. При большой длине практически могут быть использованы только линейные коды. Для относительно коротких кодов сложность построения и реализации линейных и нелинейных кодов примерно одинакова.
Линейный код называется систематическим, если первые k символов его любой кодовой комбинации являются информационными, остальные (n-k) символов – проверочными.
Величина B = qk называется мощностью кода, где q – количество различных символов (у двоичного кода q=2, B=2k).
Для случая двоичных кодов каждый проверочный символ выбирают таким образом, чтобы его сумма по модулю 2 с определенными информационными символами была равна 0. Символ проверочной позиции имеет значение 1, если число единиц нечетно, и 0, если четно. Число проверочных равенств (а, следовательно, и число проверочных символов) и номера конкретных информационных разрядов, входящих в каждое из равенств, определяются тем, какие и сколько ошибок должен исправлять или обнаруживать данный код. Проверочные символы могут располагаться на любом месте кодовой комбинации.
Наиболее простым линейным систематическим кодом является код, содержащий проверочный символ, который равен сумме по модулю 2 всех информационных символов. Этот код, называемый кодом с проверкой на четность, позволяет обнаружить все сочетания ошибок нечетной кратности.
Основой математического описания линейных кодов является линейная алгебра (теория векторных пространств, теория матриц, теория групп), поэтому методику построения таких кодов Вы будете изучать позднее в других курсах.
Наибольшую практическую ценность среди линейных кодов имеют циклические коды. Комбинации последних обладают свойством цикличности (повторяемости), т.е. могут быть получены циклическим сдвигом одной комбинации, называемой образующей для данного кода.
Например, из комбинации 001011 циклическим сдвигом справа налево (левый символ каждый раз переносится в конец комбинации) можно получить 010110, 101100, 011001 и т.д. Все n перестановок образуют цикл.
Это свойство позволяет значительно упростить кодирующие и декодирующие устройства, особенно при обнаружении ошибок. Примером являются коды Боуза-Чоудхури-Хоквингема (БЧХ-коды), которые имеют кодовое расстояние d≥5 и позволяют обнаруживать и исправлять любое число ошибок.
Рассмотрим более подробно один из наиболее эффективных линейных циклических кодов, позволяющий исправлять все одиночные ошибки – код Хэмминга с кодовым расстоянием d=3. Код образуется путем дополнения информационной части передаваемого блока, состоящего из k бит, r проверочными битами. При выборе длины передаваемого блока n и количества проверочных битов r исходят из условия:
Т![]()
 аккак
r=(n
- k),
то
аккак
r=(n
- k),
то
где n, k – натуральные числа.
При заданном k по данному неравенству определяют n.
П![]() ервыйпроверочный
символ П1
кода Хэмминга образуется суммированием
по модулю 2 всех нечетных бит блока,
начиная с первого:
ервыйпроверочный
символ П1
кода Хэмминга образуется суммированием
по модулю 2 всех нечетных бит блока,
начиная с первого:
Второй проверочный бит вычисляется суммированием тех бит блока, номера которых соответствуют n-разрядным двоичным числам, имеющим единицу во втором разряде.
Т![]() ретья
проверка охватывает разряды, номера
которых соответствуют n-разрядным
числам, имеющим единицу в третьем
разряде. Аналогично находятся разряды,
охватываемые 4-й, 5-й и т.д. проверками.
ретья
проверка охватывает разряды, номера
которых соответствуют n-разрядным
числам, имеющим единицу в третьем
разряде. Аналогично находятся разряды,
охватываемые 4-й, 5-й и т.д. проверками.
Е сли
проверочные символы расположить на
местах, кратных степени 2, т.е. на позициях
1, 2, 4, 8 и т.д., то код двоичного числа,
образованного проверочными битами на
приемной стороне будет указывать номер
разряда, в котором произошла ошибка.
сли
проверочные символы расположить на
местах, кратных степени 2, т.е. на позициях
1, 2, 4, 8 и т.д., то код двоичного числа,
образованного проверочными битами на
приемной стороне будет указывать номер
разряда, в котором произошла ошибка.
Пусть нам необходимо закодировать 15 знаков. Тогда требуемое число информационных двоичных разрядов k=4. Пользуясь соотношением (1.36) определим минимальное число разрядов кода n=7, а следовательно и число ошибок, подлежащих исправлению. Предположим нам надо передать знак №2, который имеет двоичный код 0010. При расположении проверочных символов на позициях 1,2,4 передаваемый блок будет выглядеть так 0011001. Пусть в результате передачи произошла ошибка в 6-ом разряде, т.е. мы получим код– 0111001. Вычисление проверочных равенств даст опознаватель 110 т.е. 6 в двоичной системе счисления.
Примером нелинейного кода является код Бергера, у которого проверочные символы представляют двоичную запись числа единиц в последовательности информационных символов. Например, таким является код: 00000, 00101, 01001, 01110, 10001, 10110, 11010, 11111. Коды Бергера применяют, как правило, в асимметричных каналах. В симметричных каналах они обнаруживают все единичные ошибки и некоторую часть многократных.
К неразделимым блоковым кодам относят коды с постоянным весом и коды на основе матриц Адамара. Двоичные коды с постоянным весом характеризуются тем, что их кодовые комбинации содержат одинаковое число единиц. Примером такого кода является код «3 из 7», в котором каждая кодовая комбинация содержит 3 единицы и 4 нуля (стандартный телеграфный код №3).
Коды с постоянным весом позволяют обнаружить все ошибки кратности r=1,…,n (где n – длина кода) за исключением случаев, когда число единиц, перешедших в нули, равно числу нулей, перешедших в единицы. Очевидно, что в полностью асимметричных каналах, в которых имеет место только один вид ошибок (преобразование нулей в единицы или единиц в нули), такой код позволяет обнаружить все ошибки.
В симметричных каналах вероятность необнаруженной ошибки в первом приближении можно определить как вероятность одновременного искажения одной единицы и одного нуля.
![]()
В заключение, несколько слов о непрерывных кодах. Среди непрерывных наиболее применимы сверточные коды (рекуррентные коды). Например они применяются в спутниковых системах ИРИДИУМ и ГОНЕЦ для связи с КА. В общем случае сверточные коды образуются следующим образом.
В каждый i-й дискретный момент времени на вход кодирующего устройства поступают k0 информационных символов: ai1, ai2, …, aik0, с его выхода в канал связи выдаются n0 выходных символов: bi1, bi2, …, bin, причем n0>k0. Выходные символы формируются с помощью рекуррентного соотношения из K символов сообщения, поступивших в данный и предшествующие моменты времени.
З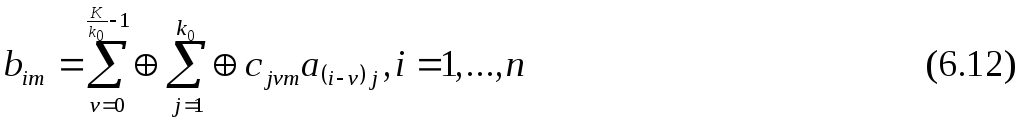 десь
cjm
коэффициенты, принимающие значение 0
или 1.
десь
cjm
коэффициенты, принимающие значение 0
или 1.
Символы сообщения, из которых формируются выходные символы, хранятся в памяти кодирующего устройства. Величина K называется длиной кодового ограничения. Она показывает, на какое максимальное число выходных символов влияет данный информационный символ, и играет ту же роль, что и длина блокового кода.
Избыточность сверточного кода определяется как:
Т![]() ипичные
параметры сверточного кода:k0/n0
= 1/4…7/8 – скорость непрерывного кода
k0=
1…7, n0=
4…8, K=
3…10.
Параметр k0/n0
используется для обозначения кода. В
спутниковых системах связи обычно
используют K=7,
R=1/2.
ипичные
параметры сверточного кода:k0/n0
= 1/4…7/8 – скорость непрерывного кода
k0=
1…7, n0=
4…8, K=
3…10.
Параметр k0/n0
используется для обозначения кода. В
спутниковых системах связи обычно
используют K=7,
R=1/2.
Для передачи сообщений, закодированных обнаруживающим кодом, необходимо применение так называемой решающей обратной связи (в отличие от информационной обратной связи). На стороне приема проверяется наличие искажений в кодовой комбинации (или в пакете принимаемых сообщений). Если ошибки обнаружены, то по обратному каналу посылается сигнал с требованием повторить передачу («сигнал переспрос»), и передатчик повторяет переданную комбинацию. При отсутствии сигнала «переспрос», обратный канал может быть использован для передачи полезной информации от приемника к передатчику.