

2. Навести класифікацію обчислювальних систем згідно з м.Флінном.
Найбільш відомою класифікацією архітектур обчислювальних систем є класифікація М. Флінн, запропонована в 1966 році. Класифікація базується на понятті потоку - послідовність команд або даних, обробляється процесором. На основі кількості потоків даних М. Флінн виділив 4 класу архітектур:
SISD (Single Instruction stream / Single Data stream) - одиночний потік команд і одинарний потік даних, їх обробки. Сюди можна віднести звичайні послідовні ЕОМ.
SIMD (Single Instruction stream / Multiple Data stream) - одиночний потоком команд і множинний потік даних. В архітектурі зберігається один потік команд, що включає, на відміну від попереднього класу, векторні команди, тобто це системи, в яких в кожний момент часу може виконуватися одна і та ж команда для обробки декількох інформаційних елементів, наприклад над елементами вектора.
MISD (Multiple Instruction stream / Single Data stream) - множинний потік команд і одинарний потік даних, тобто в архітектурі присутній багато процесорів, що обробляють один і той же потік даних. Однак прикладів конкретних ЕОМ, які відповідають даному типу обчислювальних систем, не існує. Введення даної архітектури починається для повноти системи класифікації.
MIMD (Multiple Instruction stream / Multiple Data stream) - множинний потоком команд і множинним потоком даних. У обчислювальної системі є декілька пристроїв обробки команд, об'єднаних у комплекс, що працюють кожне зі своїм потоком команд і даних. До подібного класу систем відноситься більшість паралельних багатопроцесорних обчислювальних систем.
3. Навести класифікацію обчислювальних систем згідно з р.Хокні.
Класифікація за Р. Хокні
1. Конвеєрні
2. - зі спільною пам»ятю
- системи з розподіленою пам»ятю
- з перемикачем (switch)
3. мережеві(регулярні решітки, гіперкуби, ієрархічні структури, зі змінною конфігурацією).

4. Навести основні архітектури високопродуктивних систем опрацювання даних.
Характеристика симетричного багатопроцесорного вузла (SMP):
вузол містить два або більше однакових рівноправно використовуваних процесорів;
всі процесори мають однаковий доступ до обчислювальних ресурсів вузла;
Операційна система майже автоматично масштабує додатки, даючи їм можливість використовувати нарощувані ресурси;
Додатки не міняються при додаванні процесорів і стежать за тим, на яких процесорах вони працюють;
Переносимість програм - одне з основних достоїнств SMP-платформ.
Простота і універсальність для програмування;
Для SMP-систем існують порівняно ефективні засоби автоматичного розпаралелювання;
Легкість в експлуатації;
Відносно невисока ціна.
Масивно-паралельні системи (МРР)
Вузли в архітектурі MPP складаються з одного ЦПУ, невеликої пам'яті і декількох пристроїв введення-виведення;
У кожному вузлі працює своя копія OC;
Вузли об'єднуються між собою спеціалізованим швидким з'єднанням;
Взаємозв'язки між вузлами не вимагають апаратної підтримуваної когерентності;
Когерентність реалізується програмними засобами, з використанням техніки передачі повідомлень.
Затримки, властиві програмній підтримці когерентності в тисячі разів більші, однак реалізація – дешевша;
В МРР-вузлах затримкою доводиться жертвувати, щоб під'єднати більшу кількість процесорів - тисячі вузлів;
П
 ід'єднати
велику кількість процесорів дуже
просто.
ід'єднати
велику кількість процесорів дуже
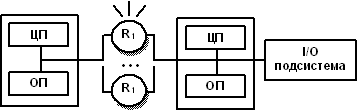
просто.Головною перевагою систем з роздільною пам'яттю є хороша масштабованість: на відміну від SMP-систем в машинах з роздільною пам'яттю кожен процесор має доступ тільки до своєї локальної пам'яті, у зв'язку з чим не виникає необхідності в потактовой синхронізації процесорів. Схема архітектури МРР з розподіленою пам'яттю
Системи з неоднорідним доступом до пам'яті (NUMA)
Система складається з однорідних базових модулів, що включають декілька процесорів і блок пам'яті.
Модулі об'єднані за допомогою високошвидкісного комутатора.
Підтримується єдиний адресний простір та апаратний доступ до віддаленої пам'яті інших модулів.
Доступ до локальної пам'яті у декілька разів швидший, ніж до віддаленої.
Існують архітектури системи з апаратною когерентністю кешів у всій системі (cc-NUMA).
Зазвичай вся система працює під управлінням єдиної ОС, як в SMP. Але можливі варіанти динамічного "підрозділу" системи, коли окремі "розділи" системи працюють під управлінням різних ОС.
Паралельно-векторні системи (PVP)
Основною ознакою PVP-систем є наявність спеціальних векторно-конвейєрних процесорів, в яких передбачені команди однотипної обробки векторів незалежних даних;
Векторно-конвейєрні процесори можуть об'єднуватися в системи з використанням загальної або розподіленої пам'яті;
Декілька процесорів працюють одночасно над загальною пам'яттю (аналогічно SMP) і декілька вузлів можуть бути об'єднані за допомогою комутатора (аналогічно MPP);
Ефективне програмування - векторизація циклів (для досягнення розумної продуктивності одного процесора) і їх розпаралелювання (для одночасного завантаження декількох процесорів одним додатком).