

ОБДЗ / Лекции Access / Проектування РБД / 6_проектування_РБД
.pdfЗазвичай початковий набір таблиць без використання формальних методик за принципом “Один факт зберігається в одному місці”. На основі аналізу ПО АБД виділяє об’єкти, ставить їм у відповідність таблиці, а потім розміщує властивості об’єктів як поля по різних таблицях.
Далі для кожного об’єкта (таблиці) необхідно визначити або створити простий ключ. Таким чином ми переведемо всі таблиці в 2НФ і позбавимося часткових залежностей неключових полів від ключа.
Після формування такого початкового набору таблиць БД треба виконати процедуру подальшої нормалізації.
Нормалізація – це процес послідовної заміни таблиці її повними декомпозиціями доти, поки всі вони не будуть повністю нормалізовані та перебувати в 5НФ або ДКНФ.
Процес нормалізації методом НФ вимагає послідовне вилучення наступних залежностей між полями:
–часткових залежностей неключових полів від ключа (2НФ);
–транзитивних залежностей неключових полів від ключа (3НФ);
–залежностей ключів (полів складового ключа) від неключових полів
(БКНФ).
При аналізі ФЗ між полями та переході до 3НФ треба або проводити декомпозицію, або зовсім вилучати залежні поля з таблиць та ставити завдання на подальшу розробку відповідних запитів.
Далі аналізуються зв’язки між таблицями та проектується перший варіант схеми БД у вигляді діаграми “Таблиці – Зв’язки ”.
Далі визначаються БЗ, які вилучаються за допомогою подальшої декомпозиції.
Таким чином формується ЛМД майбутньої РБД. Для наочності на всіх етапах нормалізації створюються діаграми (схеми).
Якщо на початку моделювання була створена ІМД, а в процесі нормалізації був зроблений поділ яких-небудь таблиць, то варто модифікувати ІМД для збереження відповідності між ІМЛ та ЛМД.
Після розробки нормалізованої ЛМД треба вказати для неї обмеження цілісності. Таким чином, ми переведемо таблиці в ДКНФ.
Вернемося до попереднього приклада.
В тСтуденти залишилась БЗ: керівник у студента може змінитись. Крім того, не можна вважати, що викладач – це властивість студента. Тому поле Код_викл в тСтуденти можна вважати надлишковим. Краще це поле вилучити, керівництво НДРС, практикою, дипломним проектом розглядати як звичайну дисципліну. В такому випадку інформацію можна зберігати в тВикладання.
В тУспішність визначається, в якому семестрі була отримана оцінка. Але якщо навчальним планом визначено, що екзамен по ОБДЗ здається в 4-ому семестрі, то і оцінка має бути проставлена за цей семестр, навіть якщо езамен буде здано лише в кінці 5-ого семестру.
Таким чином, необхідно продовжувати нормалізацію таблиць і вилучати
БЗ.
На рис. 6.9 наведені дві частини логічної моделі БД ”ВНЗ”.
59
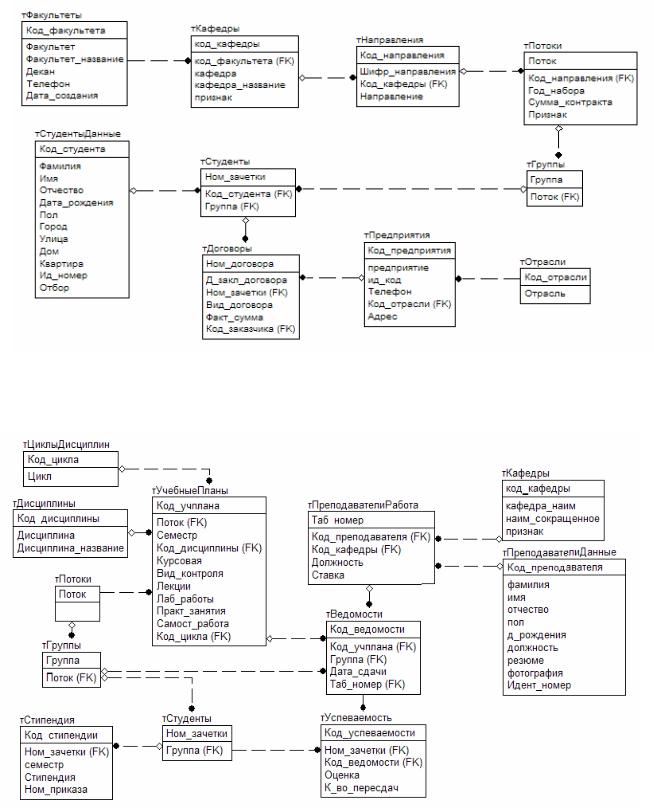
а) облік студентів
б) облік успішності Рисунок 6.9 – Логічна модель БД “ВНЗ”
На рис. 6.9а наведена та частина діаграми БД, яка може бути використана для обліку студентів ВНЗ, контрактів на навчання та угод про працевлаштування. В БД враховано, що студенти можуть навчатися на різних
60
спеціальностях.
Для обліку успішності студентів ВНЗ можна використати БД, діаграма якої наведена на рис. 6.9б. В моделі враховано, що перелік дисциплін, що вивчаються, встановлюється навчальними планами. В цій моделі вилучені БЗ між викладачами та кафедрами, між оцінками та дисциплінами. Крім того, зберігається інформація про заліково-екзаменаційні відомості, а також про стипендії, які призначалися студентам.
Процедура логічного проектування закінчується реєстрацією прийнятих проектних рішень за допомогою мови опису даних. При опису використовують речення, в яких наводиться структура таблиць, обмеження на значення, характеристики зв’язків. При визначенні полів іноді вказують тип даних, що будуть зберігатися, їх розмір, інші властивості. Це дозволяє дати зручний і повний опис будь-якої таблиці і всієї БД.
Структура речень, які використовуються при опису МД, може бути легко трансформована на мову створення фізичних реалізацій БД. Але мова опису даних на рівні ЛМД не має програмної реалізації. Тому на практиці етап опису ЛМД не виконується.
На основі ЛМД розробляється ФМД з врахуванням можливостей конкретної СУБД. Для кожного поля визначається тип та розмір даних, інші властивості, встановлюються правила підтримки цілісності даних. ФМД оформлюється у виді діаграм типу “Таблиці – зв’язки ”. На них показують таблиці, поля та зв’язки. Для кожного поля вказується тип та розмір даних у позначеннях СУБД, відповідними знаками помічаються первинні та альтернативні ключі.
ФМД – це основа для реєстрації кінцевих проектних рішень. Ці рішення зазвичай оформлюються у виді програми генерації БД і її об’єктів. В даний час основним стандартом для визначення об’єктів БД вважається структурована мова запитів SQL (Structured Query Language). До складу цієї мови входять команди визначення даних (Data Definition Commands), які служать для створення структур таблиць, їх редагування, а також для визначення схеми БД.
6.13 Оптимізація БД
Як було зазначено вище, ЛМД і ФМД зв’язані: результати логічного проектування використовують при побудові ФМД, а зміни у ФМД можуть бути показані у ЛМД. Разом з тим даталогічну ЛМД можна розглядати як статичну модель, а ФМД – як динамічну модель. На практиці проводять оптимізацію ФМД, виходячи з міркувань ефективної роботи, насамперед мінімізації часу обробки запитів до БД та обсягу БД.
Однією з переваг нормалізованих БД є те, що в них мінімізується дублювання даних. Але з метою підвищення продуктивності іноді доречним є навмисне дублювання даних.
Розглянемо таблицю тСтудентиДані (*Ін_ст, Прізвище,..., Індекс, Область, Нас_пункт, Вулиця, Будинок, Квартира), де зберігається інформація про студентів та адреси постійної реєстрації.
61
При подачі документів до ВНЗ ми можемо не мати інформацію про Ін_ст. Тому це поле не може бути ключем. Введемо штучний ключ Код_ст. Отримаємо тСтудентиДані (Код_ст, Ін_ст, Прізвище,...).
Нормалізація вимагає рознести цю інформацію у різні таблиці тСтудентиД1 (Код_ст, Прізвище,...).
тСтудентиД2 (Код_ст, Ін_ст).
Ці дві таблиці мають більш високу ступінь нормалізації, ніж початкова таблиця. Але це приведе до появи у БД додаткової таблиці та зв’язку типу 1:1. І у випадках, коли необхідно комбінувати дані із двох таблиць, СУБД або ПД мають виконувати додаткову роботу. У більшості випадків для цього потрібно як мінімум дві операції читання замість однієї. Очевидно,що одну таблицю легше обробляти, ніж дві, навіть якщо вона недостатньо нормалізована.
Щоразу, коли таблиця розбивається на дві або більше нових таблиць, виникають обмеження цілісності за посиланнями. Якщо витрати на додаткову обробку і забезпечення цілісності перевищують вигоду від усунення аномалій модифікації, нормалізація не проводиться.
Таким чином, наведений приклад нормалізації не раціональний. Краще не створювати додаткову тСтудентиД2.
Ми будемо притримуватися правила, що в БД не повинно бути зв’язків типу 1:1. Виключення можуть становити лише якісь додаткові секретні відомості.
Таблиця тСтудентиДані не перебуває в ДКНФ, оскільки є обмеження, що не є наслідком визначення ключів: ФЗ Індекс→ (Місто, Область) не випливає з ключа Код_ст. Дана таблиця може бути перетворена у дві таблиці:
тНас_пункти (*Індекс, Нас_пункт, Область), де вказується основний поштовий індекс населеного пункту, наприклад 83000;
тСтудДані(*Код_ст, Прізвище,..., Індекс, Поштове_відділення,…), де додатково вказується номер поштового відділення.
Видно, що поштовий індекс для адреси студента визначається по формулі Індекс2=Індекс + Поштове_відділення, наприклад, 83000+1=83000.
Такий етап можна нормалізації можна визнати раціональним.
Розглянемо таблицю тСтудентиДані (*Код_ст, ..., Характеристика, Фотографія). Можна вважати, що вона перебуває в ДКНФ. Відомо, що поля Характеристика та Фотографія – це потенційно великі за обсягом поля. ПД при обробці запитів ці поля майже не використовує. Але їх присутність значно сповільнить обробку БД. Необхідно відкинути ці поля. Можна створювати відповідні запити, а можна з самого початку працювати з двома таблицями тСтудентиДані (*Код_ст, ...) та тСтудентиДані2 (*Код_ст, Характеристика, Фотографія). В цьому разі між тСтудентиДані і тСтудентиДані2 встановлюється зв’язок типу 1:1. В процесі експлуатації може виникнути необхідність зберігати для одного студента кілька характеристик або фотографій. Тому краще створити відповідні таблиці зі зв’язком типу 1:М.
Таким чином, іноді для підвищення продуктивності роботи та оптимізації БД таблиці ФМД навмисно залишають у ненормалізованому виді або нормалізують, а потім проводять операції денормалізації.
62