

Проектування РБД
.pdfтСтудентиРоботи (Код_ст, Код_роб) тРоботи (Група, Код_роб)
Вважають, що 5НФ – це остання НФ, яку можна отримати шляхом декомпозиції.
4НФ є частковим випадком 5НФ, коли повна декомпозиція повинна бути з'єднанням рівно двох проекцій. Дуже непросто підібрати реальну таблицю, що знаходилася б у 4НФ, але не була б у 5НФ.
Загалом умови 5НФ досить нетривіальні, поки що не існує ефективного та формалізованого алгоритму перевірки на існування або відсутність БЗ. Тому на практиці 5НФ майже не використовують. Часто з великою гарантією вважають, що якщо таблиці перебувають в БКНФ, то вони перебувають в 4НФ та в 5НФ.
Сформулюємо загальний алгоритм, заснований на практиці. Необхідно провести детальний аналіз ПО та визначити ті характеристики, які можуть змінюватися в часі. Це може допомогти визначити БЗ.
Наприклад, у задачі обліку студентів необхідно враховувати, що кожна людина може бути студентом кількох спеціальностей як одночасно так і протягом часу. Таким чином, між сутностями Люди та Спеціальності існує БЗ.
Одна людина може навчатися на 0, 1 або кількох спеціальностях, а на кожній із спеціальностей може навчатися 0,1 або кілька людей. Видно, що між тЛюди та тСпеціальності існує зв’язок типу N:M.
Уточнимо, що студент навчається у групі, яка відноситься до спеціальності. Таким чином, якщо студент може навчатися на декількох спеціальностях, то він може навчатися в декількох групах. Таким чином, у БД має бути реалізовано зв’язок типу N:M між тГрупи та тЛюди. Зв’язок такого типу у РБД на використовується. Тому дві таблиці зі зв’язком типу N:M замінюються на три таблиці зі зв’язками 1:М.
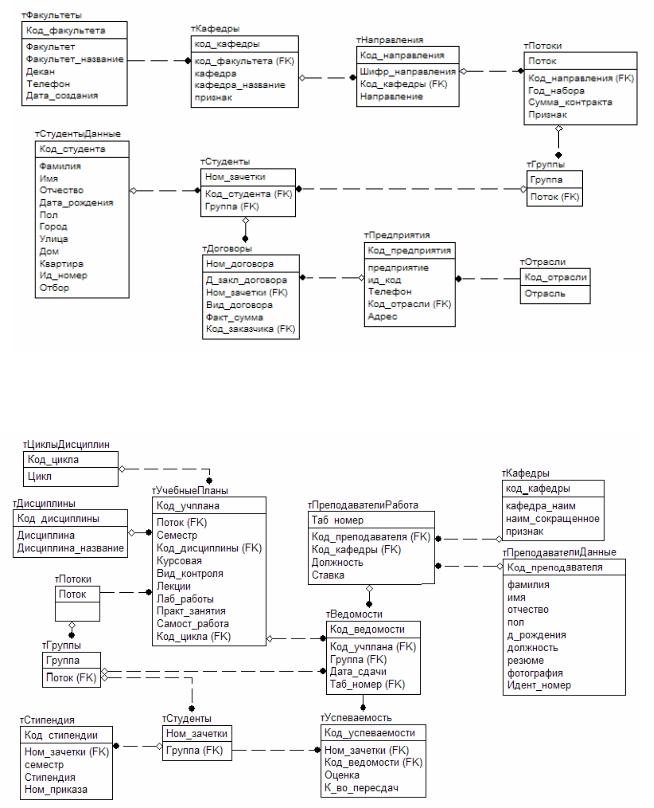
На рис. 6.7 наведені частка діаграми БД для задачі обліку студентів
тГрупи |
|
|
тСтуденти |
|
|
тСтудентиДані |
|
1 |
|
|
|
1 |
|
*Група |
|
*Код_ст |
M |
*Ін_ст |
||
|
|
|
||||
|
|
|
Прізвище |
|||
Код_спец |
|
M |
Ін_ст |
|
||
|
|
|
||||
|
|
|
Ім'я |
|||
|
|
|
Група |
|
|
|
|
|
|
|
|
По-батькові |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Стать |
|
|
|
|
|
|
Д_народження |
|
|
|
|
|
|
|
Рисунок 6.7 – Діаграма БД (варіант 3)
На рис. 6.8 наведено приклад діаграми, який наочно ілюструє розв’язання БЗ у загальному виді.
тТ1 |
1 |
тТ3 |
|
тТ2 |
|
*Код_т1 |
*Код_т3 |
1 |
*Код_т2 |
||
M |
|||||
Т1 |
Т3 |
|
Т2 |
||
|
Код_т1 |
M |
|||
|
|
|
|||
|
|
Код_т2 |
|
|
|
|
|
|
|
||
|
|
|
|
|
Рисунок 6.8 – Зв’язки між трьома таблицями
55
Всі НФ були виділені дослідниками, які виявили аномалії в деяких таблицях, які перебували в НФ більш низького порядку. Хоча 5НФ вирішує проблеми, знайдені в попередніх НФ, ніхто не може гарантувати, що не буде виявлено ще яких-небудь аномалій.
6.11 Домено-ключова нормальна форма
Була зроблена спроба розробити НФ, що буде вільною від аномалій будьякого типу.
Р.Фагін у 1981 р. визначив домено-ключову нормальну форму (ДКНФ). Він показав, що таблиця в ДКНФ не має аномалій модифікації, а будь-яка таблиця, що не має аномалій модифікації, повинна перебувати в цій НФ.
Визначення ДКНФ стосується тільки поняття ключів та доменів, які безпосередньо можуть підтримуватися існуючими СУБД. Доказ стосується обох частин доменів. Але у контексті ДКНФ під доменом мають на увазі тільки фізичний опис.
Розглянемо термін обмеження. Обмеження – це будь-яке правило, що регулює можливі статичні значення полів і досить точне для того, щоб можна було встановити, виконується воно чи ні. Прикладами таких обмежень можуть бути правила редагування, обмеження взаємин і структури таблиць, ФЗ і БЗ. Звідси виключаються обмеження, що ставляться до змін значень даних, або обмеження, що залежать від часу.
Таблиця перебуває в ДКНФ, якщо кожне обмеження, що накладається на цю таблицю, є логічним наслідком визначення доменів і ключів.
Говорячи неформально, таблиця перебуває в ДКНФ, якщо виконання обмежень на домени та ключі приводить до виконання всіх обмежень. Більш того, оскільки відносини в ДКНФ не можуть мати аномалій модифікації, СУБД може запобігти виникненню цих аномалій при реалізації обмежень на домени й ключі.
Якщо ми зможемо вводити таблиці таким чином, що всі обмеження, що накладаються на них, будуть логічними наслідками доменів і ключів, то в таких відносинах не буде аномалій модифікації. У багатьох випадках цей критерій може бути дотриманий. Якщо ж виконати критерій не уявляється можливим, необхідні обмеження повинні бути вбудовані в логіку прикладних програм, які обробляють БД.
Розглянемо приклад, що ілюструє ДКНФ.
Треба вести облік інформації про викладачів, про дисципліни, які вони ведуть, та студентів, якими вони керують під час НДРС та дипломування. Кожен викладач може вести кілька дисциплін та бути керівником у кількох студентів. Але кожним студентом може керувати тільки один викладач. Можна створити таблицю тВикладачі (*Код_викл, Ін_викл, ПІБ_викл…., *Код_дисц, Назва_дисц,
Годин,…, *Код_ст, Ін_ст, ПІБ_ст,…). В цій таблиці існують залежності:
56
Код_викл → Ін_викл Ін_викл → Код_викл
Код_викл →→ Код_дисц | Код_ст Ін_викл →→ Код_дисц | Код_ст Код_ст → Код_викл
При цьому мають виконуватися додаткові обмеження:
–Код_викл повинен належати до домену табельних номерів співробітників;
–Код_ст повинен належати до домену номерів залікових книжок студентів;
–Код_дисц повинен належати до домену кодів дисциплін усіх учбових
планів.
На жаль, відсутні чіткі алгоритми перетворення таблиці до ДКНФ. Корисно розглянути ДКНФ у більш інтуїтивному світлі. Неформально основна суть нормалізації полягає в тім, що кожна таблиця повинна мати тільки одну тему.
Якщо розглянути тВикладачі з погляду цієї точки зору, то може бути виявлена присутність чотирьох тем:
−інформація про викладачів;
−інформація про дисципліни;
−інформація про дисципліни, які веде викладач;
−інформація про студентів.
При цьому до атрибутів студента можна віднести і відомості про його керівника.
Використаємо підхід, що полягає в розбивці таблиці з декількома темами на кілька таблиць, кожна з яких містить одну тему. Представимо таблиці, що відбивають ці теми.
Визначення доменів
Код_викл |
ЦЦЦЦ, де Ц – десятична цифра |
Ін_викл |
Ц…Ц (12 ) |
ПІБ_викл |
ТТ…Т (до 50) |
Код_ст |
ЦЦЦЦЦЦ, де перші 2 цифри - це дві останні цифри року |
вступу |
|
Ін_ст |
Ц…Ц (12) |
ПІБ_ст |
ТТ…Т (до 50) |
Код_дисц |
ЦЦЦЦ |
Визначення таблиць та ключів тВикладачі (*Код_викл, Ін_викл, ПІБ_викл….)
тДисципліни (*Код_дисц, Назва_дисц, Годин,…,) тВикладання (*Код_викл, *Код_дисц) тСтуденти (*Код_ст, Ін_ст, ПІБ_ст,…,Код_викл)
Таблиця тВикладачі виражає еквівалентність полів Код_викл і Ін_викл. Поле Код_викл – це ключ, а поле Ін_викл – це альтернативний ключ, що означає, що обидва поля унікальні для цієї таблиці. Оскільки обидва вони є ключовими, ФЗ Код_викл → Ін_викл та Ін_викл → Код_викл являють собою
57
логічні наслідки ключів.
Таблиця тВикладання відбиває відповідність між викладачами та дисциплінами. В ній зазначені дисципліни, які може викладати кожен із викладачів. Комбінація обох полів становить ключ. Обидва поля є необхідними для ключа, тому що один викладач може вести кілька предметів, а той самий предмет може вестися декількома викладачами. Розділення тем усуває БЗ.
Отримані таблиці БД виражають всі задані обмеження у вигляді логічних наслідків визначень доменів і ключів. Тому дані таблиці перебувають у ДКНФ.
На сучасному етапі проектування БД вважається, що таблиці у ДКНФ точно не будуть мати ніяких аномалій.
Таким чином, введення ДКНФ поклало кінець розробці інших НФ більш високого порядку. ДКНФ наближує ЛМД до ФМД.
6.12 Процедура проектування реляційних баз даних
Процес проектування БД проводиться за таким алгоритмом:
Опис постановки задачі àРозробка КМД à Розробка ЛМД àРозробка ФМДàРеєстрація проектних рішень.
Розглянемо цей процес поетапно.
Процес проектування БД може починатися з ідентифікації сутностей та побудови ІМД за допомогою МІМ або у вигляді діаграми типу “Сутностізв’язки”.
Далі треба перейти до проектування даталогічної реляційної МД та представити ІМД у вигляді діаграми типу “Таблиці – зв’язки”.
Для переходу від ER-діаграми типу “Сутності-зв’язки” до діаграми типу “Таблиці-зв’язки” необхідно виконати наступні кроки:
1.Представити кожен стрижень базовою таблицею (БТ) і специфікувати її первинний ключ.
2.Представити кожну асоціацію як БТ. Визначити в цій таблиці зовнішні ключі для ідентифікації учасників асоціації і специфікувати обмеження, зв'язані
зкожним з цих зовнішніх ключів.
3.Представити кожну характеристику як БТ з зовнішнім ключем, що ідентифікує сутність, яку описує ця характеристика. Специфікувати обмеження на зовнішній ключ цієї таблиці, її первинний ключ та властивості, що гарантує унікальність у рамках сутності, що описується.
4.Представити кожне позначення, що не розглядалося в попередньому пункті, як БТ з зовнішнім ключем, який ідентифікує сутність, що позначається. Специфікувати обмеження, зв'язані з кожним таким зовнішнім ключем.
5.Представити кожну властивість як поле в БТ, що представляє сутність, яку безпосередньо описує ця властивість.
Таким чином, для переходу від ER-діаграми “Сутності-зв’язки” до діаграми типу “Таблиці-зв’язки” необхідно сутності всіх типів замінити таблицями. Тому на практиці АБД об’єднує два підходи (ІМД у вигляді діаграм двох типів “Сутності-зв’язки” і “Таблиці – зв’язки”) і при проектуванні РБД використовує в основному діаграми типу “Таблиці – зв’язки”.
58
Зазвичай початковий набір таблиць без використання формальних методик за принципом “Один факт зберігається в одному місці”. На основі аналізу ПО АБД виділяє об’єкти, ставить їм у відповідність таблиці, а потім розміщує властивості об’єктів як поля по різних таблицях.
Далі для кожного об’єкта (таблиці) необхідно визначити або створити простий ключ. Таким чином ми переведемо всі таблиці в 2НФ і позбавимося часткових залежностей неключових полів від ключа.
Після формування такого початкового набору таблиць БД треба виконати процедуру подальшої нормалізації.
Нормалізація – це процес послідовної заміни таблиці її повними декомпозиціями доти, поки всі вони не будуть повністю нормалізовані та перебувати в 5НФ або ДКНФ.
Процес нормалізації методом НФ вимагає послідовне вилучення наступних залежностей між полями:
–часткових залежностей неключових полів від ключа (2НФ);
–транзитивних залежностей неключових полів від ключа (3НФ);
–залежностей ключів (полів складового ключа) від неключових полів
(БКНФ).
При аналізі ФЗ між полями та переході до 3НФ треба або проводити декомпозицію, або зовсім вилучати залежні поля з таблиць та ставити завдання на подальшу розробку відповідних запитів.
Далі аналізуються зв’язки між таблицями та проектується перший варіант схеми БД у вигляді діаграми “Таблиці – Зв’язки ”.
Далі визначаються БЗ, які вилучаються за допомогою подальшої декомпозиції.
Таким чином формується ЛМД майбутньої РБД. Для наочності на всіх етапах нормалізації створюються діаграми (схеми).
Якщо на початку моделювання була створена ІМД, а в процесі нормалізації був зроблений поділ яких-небудь таблиць, то варто модифікувати ІМД для збереження відповідності між ІМЛ та ЛМД.
Після розробки нормалізованої ЛМД треба вказати для неї обмеження цілісності. Таким чином, ми переведемо таблиці в ДКНФ.
Вернемося до попереднього приклада.
В тСтуденти залишилась БЗ: керівник у студента може змінитись. Крім того, не можна вважати, що викладач – це властивість студента. Тому поле Код_викл в тСтуденти можна вважати надлишковим. Краще це поле вилучити, керівництво НДРС, практикою, дипломним проектом розглядати як звичайну дисципліну. В такому випадку інформацію можна зберігати в тВикладання.
В тУспішність визначається, в якому семестрі була отримана оцінка. Але якщо навчальним планом визначено, що екзамен по ОБДЗ здається в 4-ому семестрі, то і оцінка має бути проставлена за цей семестр, навіть якщо езамен буде здано лише в кінці 5-ого семестру.
Таким чином, необхідно продовжувати нормалізацію таблиць і вилучати
БЗ.
На рис. 6.9 наведені дві частини логічної моделі БД ”ВНЗ”.
59
а) облік студентів
б) облік успішності Рисунок 6.9 – Логічна модель БД “ВНЗ”
На рис. 6.9а наведена та частина діаграми БД, яка може бути використана для обліку студентів ВНЗ, контрактів на навчання та угод про працевлаштування. В БД враховано, що студенти можуть навчатися на різних
60
спеціальностях.
Для обліку успішності студентів ВНЗ можна використати БД, діаграма якої наведена на рис. 6.9б. В моделі враховано, що перелік дисциплін, що вивчаються, встановлюється навчальними планами. В цій моделі вилучені БЗ між викладачами та кафедрами, між оцінками та дисциплінами. Крім того, зберігається інформація про заліково-екзаменаційні відомості, а також про стипендії, які призначалися студентам.
Процедура логічного проектування закінчується реєстрацією прийнятих проектних рішень за допомогою мови опису даних. При опису використовують речення, в яких наводиться структура таблиць, обмеження на значення, характеристики зв’язків. При визначенні полів іноді вказують тип даних, що будуть зберігатися, їх розмір, інші властивості. Це дозволяє дати зручний і повний опис будь-якої таблиці і всієї БД.
Структура речень, які використовуються при опису МД, може бути легко трансформована на мову створення фізичних реалізацій БД. Але мова опису даних на рівні ЛМД не має програмної реалізації. Тому на практиці етап опису ЛМД не виконується.
На основі ЛМД розробляється ФМД з врахуванням можливостей конкретної СУБД. Для кожного поля визначається тип та розмір даних, інші властивості, встановлюються правила підтримки цілісності даних. ФМД оформлюється у виді діаграм типу “Таблиці – зв’язки ”. На них показують таблиці, поля та зв’язки. Для кожного поля вказується тип та розмір даних у позначеннях СУБД, відповідними знаками помічаються первинні та альтернативні ключі.
ФМД – це основа для реєстрації кінцевих проектних рішень. Ці рішення зазвичай оформлюються у виді програми генерації БД і її об’єктів. В даний час основним стандартом для визначення об’єктів БД вважається структурована мова запитів SQL (Structured Query Language). До складу цієї мови входять команди визначення даних (Data Definition Commands), які служать для створення структур таблиць, їх редагування, а також для визначення схеми БД.
6.13 Оптимізація БД
Як було зазначено вище, ЛМД і ФМД зв’язані: результати логічного проектування використовують при побудові ФМД, а зміни у ФМД можуть бути показані у ЛМД. Разом з тим даталогічну ЛМД можна розглядати як статичну модель, а ФМД – як динамічну модель. На практиці проводять оптимізацію ФМД, виходячи з міркувань ефективної роботи, насамперед мінімізації часу обробки запитів до БД та обсягу БД.
Однією з переваг нормалізованих БД є те, що в них мінімізується дублювання даних. Але з метою підвищення продуктивності іноді доречним є навмисне дублювання даних.
Розглянемо таблицю тСтудентиДані (*Ін_ст, Прізвище,..., Індекс, Область, Нас_пункт, Вулиця, Будинок, Квартира), де зберігається інформація про студентів та адреси постійної реєстрації.
61
При подачі документів до ВНЗ ми можемо не мати інформацію про Ін_ст. Тому це поле не може бути ключем. Введемо штучний ключ Код_ст. Отримаємо тСтудентиДані (Код_ст, Ін_ст, Прізвище,...).
Нормалізація вимагає рознести цю інформацію у різні таблиці тСтудентиД1 (Код_ст, Прізвище,...).
тСтудентиД2 (Код_ст, Ін_ст).
Ці дві таблиці мають більш високу ступінь нормалізації, ніж початкова таблиця. Але це приведе до появи у БД додаткової таблиці та зв’язку типу 1:1. І у випадках, коли необхідно комбінувати дані із двох таблиць, СУБД або ПД мають виконувати додаткову роботу. У більшості випадків для цього потрібно як мінімум дві операції читання замість однієї. Очевидно,що одну таблицю легше обробляти, ніж дві, навіть якщо вона недостатньо нормалізована.
Щоразу, коли таблиця розбивається на дві або більше нових таблиць, виникають обмеження цілісності за посиланнями. Якщо витрати на додаткову обробку і забезпечення цілісності перевищують вигоду від усунення аномалій модифікації, нормалізація не проводиться.
Таким чином, наведений приклад нормалізації не раціональний. Краще не створювати додаткову тСтудентиД2.
Ми будемо притримуватися правила, що в БД не повинно бути зв’язків типу 1:1. Виключення можуть становити лише якісь додаткові секретні відомості.
Таблиця тСтудентиДані не перебуває в ДКНФ, оскільки є обмеження, що не є наслідком визначення ключів: ФЗ Індекс→ (Місто, Область) не випливає з ключа Код_ст. Дана таблиця може бути перетворена у дві таблиці:
тНас_пункти (*Індекс, Нас_пункт, Область), де вказується основний поштовий індекс населеного пункту, наприклад 83000;
тСтудДані(*Код_ст, Прізвище,..., Індекс, Поштове_відділення,…), де додатково вказується номер поштового відділення.
Видно, що поштовий індекс для адреси студента визначається по формулі Індекс2=Індекс + Поштове_відділення, наприклад, 83000+1=83000.
Такий етап можна нормалізації можна визнати раціональним.
Розглянемо таблицю тСтудентиДані (*Код_ст, ..., Характеристика, Фотографія). Можна вважати, що вона перебуває в ДКНФ. Відомо, що поля Характеристика та Фотографія – це потенційно великі за обсягом поля. ПД при обробці запитів ці поля майже не використовує. Але їх присутність значно сповільнить обробку БД. Необхідно відкинути ці поля. Можна створювати відповідні запити, а можна з самого початку працювати з двома таблицями тСтудентиДані (*Код_ст, ...) та тСтудентиДані2 (*Код_ст, Характеристика, Фотографія). В цьому разі між тСтудентиДані і тСтудентиДані2 встановлюється зв’язок типу 1:1. В процесі експлуатації може виникнути необхідність зберігати для одного студента кілька характеристик або фотографій. Тому краще створити відповідні таблиці зі зв’язком типу 1:М.
Таким чином, іноді для підвищення продуктивності роботи та оптимізації БД таблиці ФМД навмисно залишають у ненормалізованому виді або нормалізують, а потім проводять операції денормалізації.
62
7 ПРИКЛАДИ РОЗРОБКИ МОДЕЛЕЙ ДАНИХ
7.1 Модель даних для закладу харчування
Розглянемо кілька прикладів розробки ІЛМ для різних ПО.
МД “Пансіон” [5] може бути використана в ІС закладу суспільного харчування.
Удодатку А на рис. А.1а наведена ІЛМ “Пансіон” у вигляді ER-діаграми “Сутності - звязки” на мові оригіналу.
Умоделі застосовані атрибути Блюдо, Продукт і Постачальник як найменування, а БЛ, ПР і ПОС – як цифрові коди блюд, продуктів і організаційпостачальників.
На рис. А.1б наведена ІЛМ “Пансіон” у вигляді діаграми “Таблиці - звязки” на мові оригіналу.
На рис. А.1в наведено опис ІЛМ “Пансіон” на МІМ.
Для прикладу реєстрації проектних рішень у додатку А наведено частину опису таблиць для МД “Пансіон”.
Уприкладі наведені вимоги на відсутність значень Null для полів. Зауважимо, що треба розрізняти два типи порожніх значень: значення Null (невизначеність) та пусті рядки.
7.2 Модель даних для бібліотеки
МД “Бібліотека” [5] може бути використана для ІС обліку видань, що зберігаються в бібліотеці, та відомостей про читачів.
Удодатку В на рис. В.1 наведена ІЛМ “Бібліотека” у вигляді ER-діаграми “Таблиці - звязки” на мові оригіналу.
Це дуже повна модель. В ній відображені навіть вид і характер видання, редактори, художники, перекладачі.
Удодатку Б також наведені частина ІЛМ на МІМ та опис частини проектних рішень для МД.
7.3 Модель даних для обліку заробітної плати
Розглянемо більш детально процедуру розробки РБД на прикладі. Постановка задачі передбачає розробку БД для обліку щомісячної
заробітної плати (зарплати) працівників підприємства. БД повинна містити наступні дані: ПІБ працівника, його ідентифікаційний код, дати прийняття та звільнення, стаж роботи на підприємстві, оклад, ставка, відсоток премії, сума нарахованої зарплати по кожному робочому місцю, загальна сума нарахованої зарплати за звітний місяць.
В основному ця задача вирішується для відділу кадрів та бухгалтерії.
У відділі кадрів ведеться облік працівників із зазначенням основних анкетних даних: прізвище, ім’я, по-батькові працівника, його ідентифікаційний код, стать, дата народження, вік, адреса, фотографія, резюме, дати прийняття та звільнення, стаж роботи на підприємстві, список призначень працівника на
63
робочі місця за весь термін роботи з зазначенням дати призначення, підрозділу, посади, окладу, ставки, номеру та дати наказу.
У відділі кадрів ведеться табельний облік використання робочого часу. Типові форми первинних документів для обліку кадрів і табельного
обліку встановлюються державними органами. До них відносяться особисті картки працівників, накази про прийом на роботу, звільнення, накази про надання відпустки, табелі обліку використання робочого часу і розрахунку заробітної плати
У бухгалтерії підприємства щомісячно ведеться розрахунок зарплати по кожному працівнику, формуються відомість такого розрахунку по підприємству та табуляграми для кожного працівника. Бухгалерія також готує статистичний звіт про фонд оплати праці за різні звітні періоди (місяць, квартал, півріччя, рік). Форми вихідних документів встановлюються державними органами. Ці звіти використовуються для нарахування єдиного соціального податку та аналізу фінансової діяльності підприємства.
Будемо вважати, що на підприємстві прийнята погодинно-преміальна системи оплати праці: працівнику за роботу на визначеному робочому місці щомісячно нараховується зарплата, яка складається з окладу та премії. Розмір премії залежить від результатів роботи конкретного працівника і підприємства в цілому. Будемо вважати, що премія може бути в межах від 0 до 100% від нарахованої суми за окладом.
Для спрощення при вирішенні задачі будемо розглядати тільки розрахунок сум, що нараховані. Відрахування з зарплати (прибутковий податок, внески до Пенсійного фонду, збори на соціальне страхування, тощо) не будемо розглядати.
Таким чином, відомості про зарплату включають наступні дані: оклад, ставка, % премії, розмір премії, сума, що нарахована.
Розглянемо процес ІЛМ для задачі.
За основу при проектуванні БД можна взяти основний вихідний документ
– відомість розрахунку зарплати за місяць. Її загальний вид наведено в табл. 7.1.
Для наочності до відомості внесені умовні значення реквізитів. При цьому враховано, що на підприємстві кожному працівнику дається табельний номер. Якщо працівник працює за основним місцем роботи та за сумісництвом на іншому робочому місці, то він має два різних табельних номери.
Зауважимо, що робоче місце на підприємстві визначається трьома полями: підрозділ, посада, оклад.
Для спрощення будемо спочатку вважати, що зарплата не залежить від кількості годин, які відпрацювала людина. Будемо умовно вважати, що ця кількість врахована при призначенні премії.
На базі відомості створимо УТ. Ії вид наведено в табл. 7.2.
Проведемо нормалізацію УТ. Для наочності цього процесу розвернемо поля УТ вертикально. При цьому крім полів, що вказані в відомості, включимо до УТ ті поля, які мають зберігатися в БД у відповідності з постановкою задачі. Результат показано на рис. 7.3.
64