

programmig [1 term] / кодирование_информации / кодирование информации[23-40] / Unicode, UCS-2, UCS-4, BMP - основная многоязыковая плоскость
..docxUNICODE
В январе 1991 года возник консорциум UNICODE (Unicode Consortium), целью которого является продвижение, развитие и реализация стандарта Unicode как международной системы кодирования для обмена информацией, а также поддержание качества этого стандарта в будущих версиях.
Стандарт UNICODE 4.0 представляет собой новую систему кодирования символов, выводимых на экран монитора или на принтер, позволяющую закодировать 1 114 112 символов (в стандарте из принято называть code points). Большинство символов, используемых в основных языках мира занимают 65 536 code points, образуя Basic Multilingual Plane (BMP) (Основной Многоязычный Уровень - мой перевод). Оставшиеся (более миллиона) code points вполне достаточно для кодирования всех известных символов, включая малораспространенные языки и исторические знаки. Стандарт UNICODE поддерживается тремя формами, 32-битной (UTF-32), 16-битной (UTF-16) и 8-битной (UTF-8). Восьмибитная форма UTF-8 была разработана для удобной совместимости с ASCII-ориентироваными системами кодирования. Стандарт UNICODE совместим с Международным стандартом International Standard ISO/IEC 10646.
Наиболее просто устроена форма UTF-32. В ней каждый символ закодирован при помощи 32-битного блока. Благодаря этому каждый символ UTF-32 обладает однозначным соответствием между декодированным символом и блоком кода. Это форма имеет фиксированную длину знакоместа. Она покрывает все кодовое пространство UNICODE - 0...10FFFF16. Это гарантирует полную совместимость с UTF-16 и UTF-8. Форма UTF-32 является наиболее предпочитаемой для большинства UNIX платформ.
Стандарт UNICODE содержит 96 382 символа, взятых их мировых шрифтов. Этих символов более чем достатонно для общения на всех известных языках мира, а также для написания классических (исторических ) шрифтов многих языков. UNICODE всключает в себя шрифты европейских алфавитов, средне-азиатское письмо, направленное справа на лево, шрифты Азии, и многие другие. Подмножество символов (code points) HUN включает 70 207 идеографических символов определяемых по национальным и промышленным стандартам Китая, Японии, Кореи, Тайвани, Вьетнама и Сингапура. Более того, UNICODE содержит знаки пунктуации, математические символы, технические символы, герметрические фотмы и графические метки (dingbats), фонетические знаки.
Ниже приведена сравнительная таблица кодов ASCII и UNICODE, взятая из Фрагмента спецификации UNICODE 4.0 (Unicode Standard, Version 4.0), размещенного на сайте Unicode Consortium.
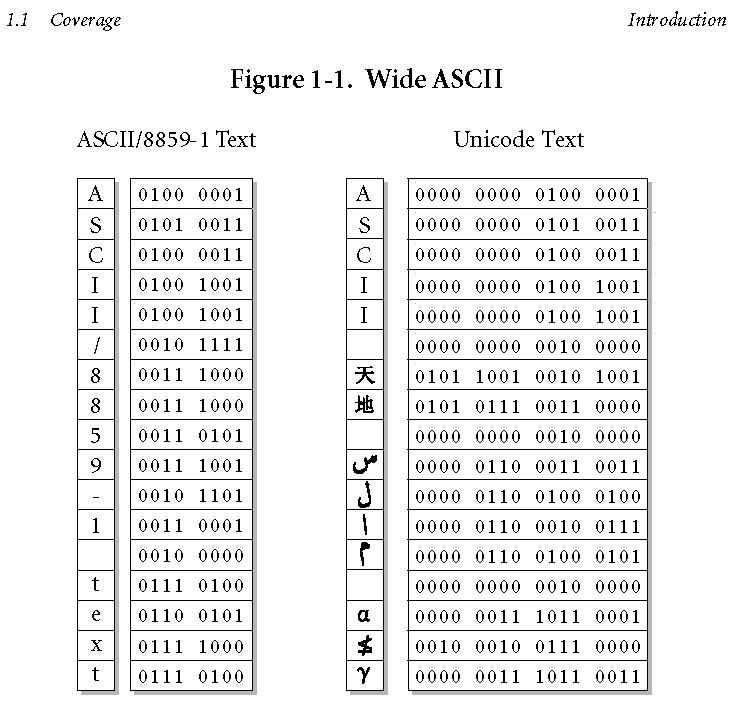
Кодовая таблица для кириллицы приведена на следующем рисунке (взято из Фрагмента спецификации UNICODE 4.0 (Unicode Standard, Version 4.0), размещенного на сайте Unicode Consortium.

Предпосылки создания и развитие Юникода[править | править исходный текст]
К концу 1980-х годов стандартом стали 8-битные символы, при этом существовало множество разных 8-битных кодировок, и постоянно появлялись всё новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример — появлениеальтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилось несколько проблем:
-
Проблема «кракозябр» (отображения документов в неправильной кодировке):[6] её можно было решить либо последовательным внедрением методов указания используемой кодировки, либо внедрением единой для всех кодировки.
-
Проблема ограниченности набора символов:[6] её можно было решить либо переключением шрифтов внутри документа, либо внедрением «широкой» кодировки. Переключение шрифтов издавна практиковалось в текстовых процессорах, причём часто использовались шрифты с нестандартной кодировкой, т. н. «dingbat fonts» — в итоге при попытке перенести документ в другую систему все нестандартные символы превращались в кракозябры.
-
Проблема преобразования одной кодировки в другую: её можно было решить либо составлением таблиц перекодировки для каждой пары кодировок, либо использованием промежуточного преобразования в третью кодировку, включающую все символы всех кодировок.[9]
-
Проблема дублирования шрифтов: особенно для каждой кодировки делался свой шрифт, даже если эти кодировки частично (или полностью) совпадали по набору символов: эту проблему можно было решить, делая «большие» шрифты, из которых потом выбираются нужные для данной кодировки символы — однако это требует создания единого реестра символов, чтобы определять, чему что соответствует.
Было признано необходимым создание единой «широкой» кодировки. Кодировки с переменной длиной символа, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать символы фиксированной ширины. Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
Таким образом, первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 216 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+04F0). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе. Редко используемые символы должны были размещаться в «области пользовательских символов» (private use area), которая первоначально занимала коды U+D800…U+F8FF. Чтобы использовать Юникод также и в качестве промежуточного звена при преобразовании разных кодировок друг в друга, в него включили все символы, представленные во всех наиболее известных кодировках.