

3.5.5. Діаграми потоків даних (dfd)
Така діаграма складається з трьох типів вузлів: вузлів обробки даних, вузлів збереження даних і зовнішніх вузлів, які представляють зовнішні по відношенню до використовуваної діаграми джерела чи користувачі даних. Дуги в діаграмі відповідають потокам даних, які передаються від вузла до вузла. Вони помічені іменами відповідних даних. Описання процесу, функції чи системи обробки даних, які відповідають вузлу діаграми, може бути представлено діаграмою наступного рівня деталізації, якщо процес достатньо складний [1, 53].
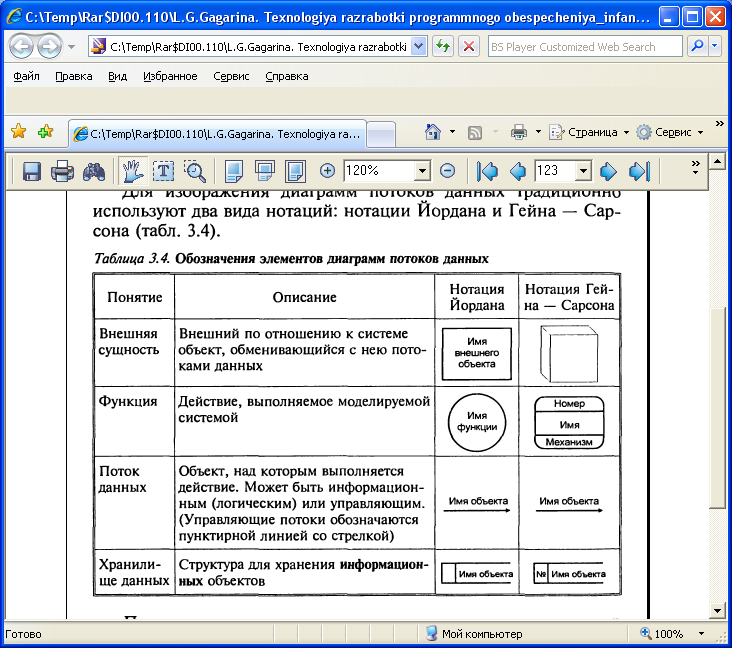
Для зображення діаграм потоків даних традиційно використовують два види нотацій: нотації Йордана і Гейна-Сарсона (табл. 3.4).
Першим кроком при побудові ієрархії діаграм потоків даних є побудова контекстних діаграм, які показують, як система буде взаємодіяти з користувачами та іншими зовнішніми системами. При проектуванні простих систем достатньо однієї контекстної діаграми, яка має зіркову топологію, в центрі якої розміщується основний процес, з’єднаний з джерелами і приймачами інформації.
Для складних систем будується ієрархія контекстних діаграм, яка визначає взаємодію основних функціональних підсистем проектованої системи як між собою, так і з зовнішніми вхідними і вихідними потоками даних і зовнішніми об’єктами. При цьому контекстна діаграма верхнього рівня містить набір підсистем, з’єднаних потоками даних. Контекстну діаграми наступного рівня деталізують вмістиме і структуру підсистем.
Після побудови контекстних діаграм отриману модель слід перевірити на повноту початкових даних і відсутність інформаційних зв’язків з іншими об’єктами.
Для кожної підсистеми, присутньої на контекстних діаграмах, виконується її деталізація з допомогою діаграм потоків даних, при цьому необхідно дотримуватись наступних правил:
правило балансування. Означає, що при деталізації підсистеми можна використовувати тільки ті компоненти (підсистеми, процеси, зовнішні сутності, накопичувачі даних), з якими вона має інформаційний зв’язок на батьківській діаграми;
правило нумерації. Означає, що при деталізації підсистем повинна підтримуватись їх ієрархічна нумерація. Наприклад, підсистеми, які деталізують підсистему з номером 2, отримують номери 2.1, 2.2, 2.3 і т.д.
При побудові ієрархії діаграм потоків даних переходити до деталізації процесів слід тільки після визначення структур даних, які описують вміст всіх потоків і накопичувачів даних. Структури даних можуть містити альтернативи, умовні входження та ітерації. Умовне входження означає, що відповідні компоненти можуть бути відсутніми в структурі. Альтернатива означає, що в структуру може входити один з перерахованих елементів. Ітерація означає, що компонент може повторюватись у структурі деяку кількість разів. Для кожного елемента даних може вказуватись його тип (неперервний чи дискретний). Для неперервних даних може вказуватись одиниця виміру (кг, см і т.д.), діапазон значень, точність представлення і форма фізичного кодування. Для дискретних даних може вказуватись таблиця допустимих значень.
Побудовану модель системи необхідно перевірити на повноту і узгодженість. У повній моделі всі її об’єкти (підсистеми, процеси, потоки даних) повинні бути детально описані і деталізовані. Виявлені недеталізовані об’єкти слід деталізувати, повернувшись на попередні етапи розробки. В узгодженій моделі для всіх потоків даних і накопичувачів даних повинно виконуватись правило збереження інформації: всі дані, які поступають куди-небудь повинні бути зчитані, а всі зчитувані дані повинні бути записані.
У відповідності з вищесказаним процес побудови моделі розбивається на наступні етапи [39]:
Виділення множини вимог в основні функціональні групи – процеси.
Виявлення зовнішніх об’єктів, зв’язаних з розроблюваною системою.
Ідентифікація основних потоків інформації, яка циркулює між системою і зовнішніми об’єктами.
Попередня розробка контекстної діаграми.
Перевірка попередньої контекстної діаграми і внесення в неї змін.
Побудова контекстної діаграми шляхом об’єднання всіх процесів попередньої діаграми в один процес, а також групування потоків.
Перевірка основних вимог контекстної діаграми.
Декомпозиція кожного процесу поточної DFD з допомогою деталізуючої діаграми чи специфікації процесу.
Перевірка основних вимог по DFD відповідного рівня.
Додавання визначень нових потоків у словник даних при кожній появі їх на діаграмі.
Перевірка повноти і наочності моделі після побудови кожних двох-трьох рівнів.
Приклад 3.2. Розробимо ієрархію діаграм потоків даних програми сортування одновимірних масивів.
Для початку побудуємо контекстну діаграму, для чого визначимо зовнішні сутності і потоки даних між програмою і зовнішніми сутностями. Зовнішньою сутністю по відношенню до програми є Користувач. Він вибирає метод сортування і вводить початкові дані, а потім отримує від програми описання вибраного методу і відсортований масив. На рис. 3.29 наведена контекстна діаграма даної програми.
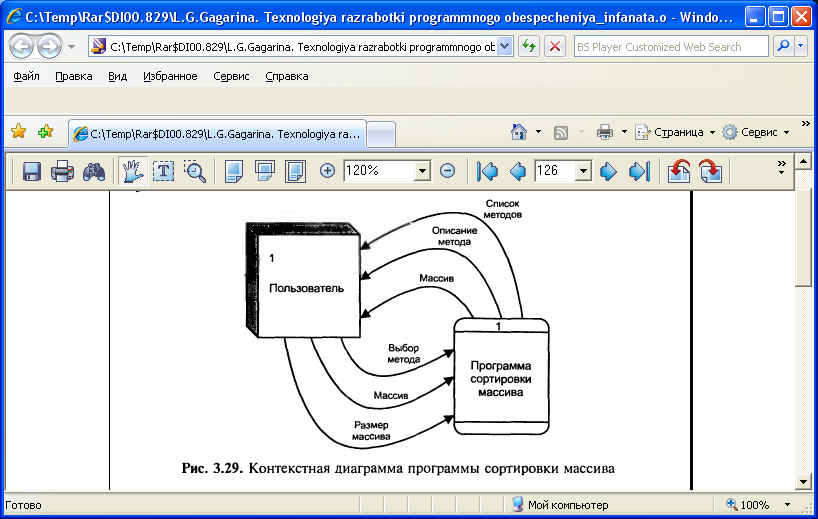
Після деталізації отримались три процеси: Меню, Сортування, Вивід результату. Для збереження описання алгоритмів служить Сховище алгоритмів. Тепер визначимо потоки даних.
Деталізуюча діаграма потоків даних зображена на рис 3.30. Як бачимо, вона дещо відрізняється від функціональної діаграми (див. 3.28), наприклад, на ній показане сховище даних для зберігання описання алгоритмів. Ця відмінність є важливою при проектуванні баз даних.
