

lab.MIT.06
.pdfЛабораторная работа № 6
Маршрутизация в сетях TCP/IP
Краткие теоретические сведения
1. Понятие о маршрутизации.
Цель введения сетевого уровня – образовать единую транспортную систему, которая смогла бы объединить несколько сетей с различными базовыми технологиями и произвольной структурой связей.
Сетевой уровень должен обеспечить одинаково эффективную работу для всех узлов сетей, входящих в единую составную сеть, независимо от того, какие в этих сетях используются принципы передачи данных.
В протоколах сетевого уровня термин сеть означает совокупность компьютеров, соединенных между собой в соответствии с одной из стандартных типовых топологий и использующих для передачи пакетов общую базовую сетевую технологию.
Совокупность нескольких сетей называется составной сетью (интерсеть – internetwork, internet). Сети, которые входят в составную сеть называются подсетями – subnet, составляющими сетями или просто сетями. При этом такие компоненты составной сети могут быть как локальными, так и глобальными сетями.
Сетевой уровень должен обеспечить передачу пакетов между любыми двумя конечными узлами в составной сети. Другими словами он должен осуществлять выбор наилучшего пути при передаче данных между узлами составной сети, то есть – маршрутизацию. Устройства, которые связывают подсети между собой в единую составную сеть, называются маршрутизаторами.
Маршрут – это последовательность маршрутизаторов, которые должен пройти пакет от отправителя до пункта назначения.
Маршрут выбирается на основании имеющейся у этих устройств информации о текущей конфигурации сети, а также на основании указанного критерия выбора маршрута. Обычно в качестве критерия выступает задержка прохождения маршрута отдельным пакетом или средняя пропускная способность маршрута для последовательности пакетов.
Часто также используется весьма простой критерий, учитывающий только количество пройденных в маршруте промежуточных маршрутизаторов. Количество пройденных маршрутизаторов в маршруте называют хопами.
Чтобы по адресу сети назначения можно было бы выбрать рациональный маршрут дальнейшего следования пакета, каждый конечный узел и маршрутизатор анализируют специальную информационную структуру, которая называется таблицей маршрутизации.
2. Алгоритмы и протоколы маршрутизации.
Протоколы маршрутизации следует отличать от собственно сетевых протоколов. И те, и другие выполняют функции сетевого уровня модели OSI – участвуют в доставке пакетов адресату через разнородную составную сеть. Но если протоколы маршрутизации занимаются сбором и передачей по сети чисто служебной информации, то сетевые протоколы предназначены для передачи пользовательских данных, как это делают протоколы канального уровня.
Протоколы маршрутизации используют сетевые протоколы как транспортное средство. При обмене маршрутной информацией пакеты протокола маршрутизации помещаются в поле данных пакетов сетевого уровня или даже транспортного уровня.
Маршрутизаторы по своей инициативе обмениваются специальными служебными пакетами, с их помощью они сообщают своим соседям об известных им сетях в интерсети, маршрутизаторах и о связях этих сетей с маршрутизаторами. При этом обычно учитывается не только топология связей, но и их пропускная способность и состояние. Это позволяет маршрутизаторам быстрее адаптироваться к изменениям конфигурации сети, а также правильно передавать пакеты в сетях с произвольной топологией, допускающей наличие замкнутых контуров!
С помощью протоколов маршрутизации маршрутизаторы составляют карту связей сети той или иной степени подробности. На основании этой информации для каждого номера сети принимается решение о том, какому следующему маршрутизатору надо передавать пакеты, направляемые в эту сеть, чтобы маршрут оказался рациональным. Результаты этих решений заносятся в таблицу маршрутизации.
При изменении конфигурации сети некоторые записи в таблице становятся недействительными. В таких случаях пакеты, отправленные по ложным маршрутам, могут зацикливаться и теряться. От того, насколько быстро протокол маршрутизации приводит в соответствие содержимое таблицы реальному состоянию сети, зависит качество работы всей сети.
Протоколы маршрутизации могут быть построены на основе разных алгоритмов, отличающихся способами построения таблиц маршрутизации, способами выбора наилучшего маршрута и другими особенностями своей работы.
1
Во всех описанных выше примерах при выборе рационального маршрута определялся только следующий (ближайший) маршрутизатор, а не вся последовательность маршрутизаторов от начального до конечного узла.
В соответствии с этим подходом маршрутизация выполняется по распределенной схеме: каждый маршрутизатор берет на себя ответственность за выбор только одного шага маршрута! а окончательный маршрут складывается в результате работы всех маршрутизаторов, через которые проходит данный пакет. Такие алгоритмы маршрутизации называются одношаговыми.
Существует и прямо противоположный, многошаговый подход – маршрутизация от источника (Source Routing). В соответствии с ним узел, который отправляет пакет в сеть, должен прописать полный маршрут его следования через все промежуточные маршрутизаторы. Понятно, что при использовании многошаговой маршрутизации нет необходимости строить и анализировать таблицы маршрутизации. Это ускоряет прохождение пакета по сети, разгружает маршрутизаторы, но при этом очень большая нагрузка ложится на конечные узлы. Остается только заметить, что та схема в вычислительных сетях применяется сегодня гораздо реже, чем схема распределенной одношаговой маршрутизации.
Одношаговые алгоритмы в зависимости от способа формирования таблиц маршрутизации делятся на три класса:
-алгоритмы статической маршрутизации;
-алгоритмы простой маршрутизации;
-алгоритмы динамической маршрутизации.
2.1. Статическая маршрутизация.
Ее еще называют фиксированная маршрутизация. В алгоритмах статической маршрутизации все записи в таблице маршрутизации являются статическими. Собственно говоря, этот способ маршрутизации предполагает отсутствие какого-либо протокола маршрутизации.
Администратор сети сам решает, на какие маршрутизаторы надо передавать пакеты с теми или иными адресами, и вручную заносит соответствующие записи в таблицу маршрутизации. Таблица, как правило, создается в процессе загрузки, в дальнейшем она используется без изменений до тех пор, пока ее содержимое не будет отредактировано вручную. Такие исправления могут понадобиться, например, если в сети отказывает какой-либо маршрутизатор и его функции возлагаются на другой маршрутизатор.
Различают одномаршрутные таблицы, в которых для каждого адресата задан один путь, и многомаршрутные таблицы, определяющие несколько альтернативных путей для каждого адресата.
В многомаршрутных таблицах должно быть задано правило выбора одного из маршрутов. Чаще всего один путь является основным, а остальные – резервными.
Понятно, что алгоритм фиксированной маршрутизации с его ручным способом формирования таблиц маршрутизации приемлем только в небольших сетях с простой топологией. Однако этот алгоритм может быть эффективно использован и для работы на магистралях крупных сетей, так как сама магистраль может иметь простую структуру с очевидными наилучшими путями следования пакетов в подсети, присоединенные к магистрали.
2.2. Простая маршрутизация.
В алгоритмах простой маршрутизации таблица маршрутизации либо вовсе не используется, либо строится без участия протоколов маршрутизации.
Выделяют три типа простой маршрутизации:
-случайная маршрутизация, когда прибывший пакет посылается в первом попавшем случайном направлении, кроме исходного;
-лавинная маршрутизация, когда пакет широковещательно посылается по всем возможным направлениям, кроме исходного (аналогично обработке мостами кадров с неизвестным адресом);
-маршрутизация по предыдущему опыту, когда выбор маршрута осуществляется по таблице, но таблица строится по принципу моста путем анализа адресных полей пакетов, появляющихся на входных портах.
2.3. Динамическая маршрутизация.
Этот способ маршрутизации (еще называется адаптивный) является самым распространенным.
Алгоритмы динамической маршрутизации обеспечивают автоматическое обновление таблиц маршрутизации после изменения конфигурации сети.
Таким образом, протоколы, построенные на основе адаптивных алгоритмов, позволяют всем маршрутизаторам собирать информацию о топологии связей в сети, оперативно отрабатывая все изменения конфигурации связей.
В таблицах маршрутизации при адаптивной маршрутизации обычно имеется информация об интервале времени, в течение которого данный маршрут будет оставаться действительным. Это время называют временем жизни маршрута
(Time To Live, TTL).
Адаптивные алгоритмы обычно имеют распределенный характер, который выражается в том, что в сети отсутствуют какие-либо выделенные маршрутизаторы, которые собирали бы и обобщали топологическую информацию: эта работа распределена между всеми маршрутизаторами.
Надо отметить, что в последнее время наметилась тенденция использовать так называемые серверы маршрутов. Сервер маршрутов собирает маршрутную информацию, а затем раздает ее по запросам маршрутизаторам, которые освобождаются в этом случае от функции создания таблиц маршрутизации, либо создают только части этих таблиц. Соответственно были разработаны специальные протоколы взаимодействия маршрутизаторов с серверами маршрутов.
К адаптивным алгоритмам маршрутизации предъявляются весьма важные требования:
Во-первых, они должны обеспечивать, если не оптимальность, то хотя бы рациональность маршрута.
2
Во-вторых, алгоритмы должны быть достаточно простыми, чтобы при их реализации не тратилось слишком много сетевых ресурсов, в частности они не должны требовать слишком большого объема вычислений или порождать интенсивный служебный трафик.
И, наконец, алгоритмы маршрутизации должны обладать свойством сходимости, то есть всегда приводить к однозначному результату за приемлемое время.
Адаптивные протоколы обмена маршрутной информацией, применяемые в настоящее время в вычислительных сетях, в свою очередь делятся на две группы, каждая из которых связана с одним из следующих типов алгоритмов:
-дистанционно-векторные алгоритмы (Distance Vector Algorithms, DVA);
-алгоритмы состояния связей (Link State Algorithms, LSA).
2.3.1. Distance Vector Algorithms, DVA.
Валгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор, компонентами которого являются расстояния от данного маршрутизатора до всех известных ему сетей.
Под расстоянием обычно понимается число хопов. Возможна и другая метрика, учитывающая не только число промежуточных маршрутизаторов, но и время прохождения пакетов по сети между соседними маршрутизаторами. При получении вектора от соседа маршрутизатор наращивает расстояния до указанных в векторе сетей на расстояние до данного соседа.
Получив вектор от соседнего маршрутизатора, каждый маршрутизатор добавляет к нему информацию об известных ему других сетях, о которых он узнал непосредственно (если они подключены к его портам) или из аналогичных объявлений других маршрутизаторов, а затем снова рассылает новое значение вектора по сети.
Вконце концов, каждый маршрутизатор узнает информацию обо всех имеющихся в интерсети сетях и о расстоянии до них через соседние маршрутизаторы.
Следует отметить, что, несмотря на свою простоту, дистанционно-векторные алгоритмы хорошо работают только
внебольших сетях. В больших сетях они засоряют линии связи интенсивным широковещательным трафиком, к тому же изменения конфигурации могут отрабатываться по этому алгоритму не всегда корректно, так как маршрутизаторы не имеют точного представления о топологии связей в сети, а располагают только обобщенной информацией – вектором дистанций, к тому же полученной через посредников.
Работа маршрутизатора в соответствии с дистанционно-векторным протоколом напоминает работу моста, так как точной топологической картины сети такой маршрутизатор не имеет.
2.3.2. Link State Algorithms, LSA.
Алгоритмы состояния связей обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации.
«Широковещательная» рассылка (то есть передача пакета всем непосредственным соседям маршрутизатора) используется здесь только при изменениях состояния связей, что происходит в надежных сетях не так часто.
Вершинами графа являются как маршрутизаторы, так и объединяемые ими сети. Распространяемая по сети информация состоит из описания связей различных типов: маршрутизатор – маршрутизатор, маршрутизатор – сеть.
Чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами HELLO со своими ближайшими соседями.
Хотя такой служебный трафик также засоряет сеть, но не в такой степени как, например, пакеты дистанционновекторного протокола, так как пакеты HELLO имеют намного меньший объем.
2.4. Одноуровневые и иерархические алгоритмы.
Некоторые алгоритмы маршрутизации оперируют в плоском пространстве, в то время как другие используют иерархии маршрутизации. В одноуровневой системе маршрутизации все маршрутизаторы равны по отношению друг к другу. В иерархической системе маршрутизации некоторые маршрутизаторы формируют то, что составляет основу (backbone – магистраль) маршрутизации. Пакеты из немагистральных маршрутизаторов перемещаются к магистральным маршрутизаторам и пропускаются через них до тех пор, пока не достигнут общей области пункта назначения. Начиная с этого момента, они перемещаются от последнего магистрального маршрутизатора через один или несколько немагистральных маршрутизаторов до конечного пункта назначения.
Системы маршрутизации часто устанавливают логические группы узлов, называемых доменами, или автономными системами (AS), или областями. В иерархических системах одни маршрутизаторы какого-либо домена могут общаться с маршрутизаторами других доменов, в то время как другие маршрутизаторы этого домена могут поддерживать связь с маршрутизаторами только в пределах своего домена. В очень крупных сетях могут существовать дополнительные иерархические уровни. Маршрутизаторы наивысшего иерархического уровня образуют базу маршрутизации.
Основным преимуществом иерархической маршрутизации является то, что она имитирует организацию большинства компаний и, следовательно, очень хорошо поддерживает их схемы трафика. Большая часть сетевой связи имеет место в пределах групп небольших компаний (доменов). Внутридоменным маршрутизаторам необходимо знать только о других маршрутизаторах в пределах своего домена, поэтому их алгоритмы маршрутизации могут быть упрощенными. Соответственно может быть уменьшен и трафик обновления маршрутизации, зависящий от используемого алгоритма маршрутизации.
2.5. Одномаршрутные или многомаршрутные алгоритмы.
3
Некоторые сложные протоколы маршрутизации обеспечивают множество маршрутов к одному и тому же пункту назначения. Такие многомаршрутные алгоритмы делают возможной мультиплексную передачу трафика по многочисленным линиям; одномаршрутные алгоритмы не могут делать этого. Преимущества многомаршрутных алгоритмов очевидны – они могут обеспечить значительно большую пропускную способность и надежность.
2.6. Показатели алгоритмов (метрики).
Маршрутные таблицы содержат информацию, которую используют программы коммутации для выбора наилучшего маршрута. В алгоритмах маршрутизации используется много различных показателей. Сложные алгоритмы маршрутизации при выборе маршрута могут базироваться на множестве показателей, комбинируя их таким образом, что
врезультате получается один отдельный (гибридный) показатель. Ниже перечислены показатели, которые используются
валгоритмах маршрутизации:
-длина маршрута;
-надежность;
-задержка;
-ширина полосы пропускания;
-нагрузка;
-стоимость связи.
2.6.1. Длина маршрута.
Длина маршрута является наиболее общим показателем маршрутизации. Некоторые протоколы маршрутизации позволяют администраторам сети назначать произвольные цены на каждый канал сети. В этом случае длиной тракта является сумма расходов, связанных с каждым каналом, который был траверсирован. Другие протоколы маршрутизации определяют «количество пересылок», т.е. показатель, характеризующий число проходов, которые пакет должен совершить на пути от источника до пункта назначения через устройства объединения сетей (такие как маршрутизаторы).
2.6.2. Надежность.
Надежность, в контексте алгоритмов маршрутизации, относится к надежности каждого канала сети (обычно описываемой в терминах соотношения бит/ошибка). Некоторые каналы сети могут отказывать чаще, чем другие. Отказы одних каналов сети могут быть устранены легче или быстрее, чем отказы других каналов. При назначении оценок надежности могут быть приняты в расчет любые факторы надежности. Оценки надежности обычно назначаются каналам сети администраторами сети. Как правило, это произвольные цифровые величины.
2.6.3. Задержка.
Под задержкой маршрутизации обычно понимают отрезок времени, необходимый для передвижения пакета от источника до пункта назначения через объединенную сеть. Задержка зависит от многих факторов, включая полосу пропускания промежуточных каналов сети, очереди в порт каждого маршрутизатора на пути передвижения пакета, перегруженность сети на всех промежуточных каналах сети и физическое расстояние, на которое необходимо переместить пакет. Т.к. здесь имеет место конгломерация нескольких важных переменных, задержка является наиболее общим и полезным показателем.
2.6.4. Полоса пропускания.
Полоса пропускания относится к имеющейся мощности трафика какого-либо канала. При прочих равных показателях, канал Ethernet 10 Мбит/с предпочтителен любой арендованной линии с полосой пропускания 64 Кбайт/сек. Хотя полоса пропускания является оценкой максимально достижимой пропускной способности канала, маршруты, проходящие через каналы с большей полосой пропускания, не обязательно будут лучше маршрутов, проходящих через
менее быстродействующие каналы.
3. Протокол RIP.
Протокол RIP является дистанционно-векторным протоколом внутренней маршрутизации. Процесс работы протокола состоит в рассылке, получении и обработке векторов расстояний до IP-сетей, находящихся в области действия протокола, то есть в данной RIP-системе. Результатом работы протокола на конкретном маршрутизаторе является таблица, где для каждой сети данной RIP-системы указано расстояние до этой сети (в хопах) и адрес следующего маршрутизатора. Информация о номере сети и адресе следующего маршрутизатора из этой таблицы вносится в таблицу маршрутов, информация о расстоянии до сети используется при обработке векторов расстояний.
3.1. Алгоритм построения таблицы маршрутов.
Таблицей маршрутов называют таблицу, являющуюся результатом деятельности протокола RIP, т.е. состоящую из строк с полями «Сеть», «Расстояние», «Следующий маршрутизатор». Строка в таблице маршрутов выглядит следующим образом:
А=2Æ e
Это означает, что расстояние от данного маршрутизатора до сети А равно 2, а дейтаграммы, следующие в сеть А, надо пересылать маршрутизатору e.
4

Вектором расстояний называется набор пар («Сеть», «Расстояние до этой сети»), извлеченный из таблицы маршрутов. Каждая такая пара мы называется элементом вектора расстояний. Вектор расстояний записывается в виде (А=2,В=1): это означает, что расстояние от данного маршрутизатора до сети А равно 2, до сети В – 1.
Расстояние до сети, к которой маршрутизатор подключен непосредственно, принимается равным 1.
Каждый маршрутизатор, на котором запущен модуль RIP, периодически широковещательно распространяет свой вектор расстояний. Вектор распространяется через все интерфейсы маршрутизатора, подключенные к сетям, входящим в RIP-систему.
Каждый маршрутизатор также периодически получает векторы расстояний от других маршрутизаторов. Расстояния в этих векторах увеличиваются на 1, после чего сравниваются с данными в таблице маршрутов, и, если расстояние до какой-то из сетей в полученном векторе оказывается меньше расстояния, указанного в таблице, значение из таблицы замещается новым (меньшим) значением, а адрес маршрутизатора, приславшего вектор с этим значением, записывается в поле «Следующий маршрутизатор» в этой строке таблицы. После этого вектор расстояний, рассылаемый данным маршрутизатором, соответственно изменится.
3.1.1. Пример построения таблицы маршрутов. Пример RIP-системы представлен на рисунке 1.
A |
2 |
D |
|
||
1 |
C |
4 |
B |
3 |
E |
|
|
Рисунок 1.
Здесь c , d , e , f – маршрутизаторы, A, B, C, D, E – сети. Узлы в сетях не показаны. В примере рассматривается формирование таблицы маршрутов в узле c.
В начальный момент времени (например, после подачи питания на маршрутизаторы) таблица маршрутов в узле c выглядит следующим образом (т.к. узел c знает только о тех сетях, к которым подключен непосредственно):
A=1Æ c B=1Æ c
Следовательно, узел c рассылает в сети А и В вектор расстояний (А=1,В=1).
Аналогично узел d рассылает в сети A, C, D вектор (A=1,C=1,D=1). Узел c получает этот вектор из сети А, увеличивает расстояния на 1 (A=2,C=2,D=2) и сравнивает с данными в своей таблице маршрутов. Новое расстояние до сети А оказывается больше, чем уже внесенное в таблицу (А=1), следовательно, новое значение игнорируется. Поскольку сети C и D вовсе не фигурируют в его таблице маршрутов, они туда вносятся. В узле c имеем:
A=1Æ c B=1Æ c C=2Æ d D=2Æ d
Узел f в свою очередь рассылает вектор (D=1,E=1) в сети D и E. Узел d получает этот вектор из сети D, увеличивает расстояния на 1, после чего добавляет себе в таблицу данные о сети Е (Е=2Æ f ). Ранее из узла c он получил информацию о сети В и добавил себе в таблицу строку В=2Æ c . Узел d рассылает в сети A, C, D свой обновленный вектор расстояний (A=1,B=2,C=1,D=1,E=2).
Узел c получает этот вектор от d из сети А, увеличивает расстояния на 1: (A=2,B=3,C=2,D=2,E=3) и замечает, что все указанные расстояния, кроме расстояния до сети Е, больше либо равны значениям, имеющимся в его таблице. Сеть Е в таблице узла c отсутствует, следовательно, она туда вносится, и в узле c мы получаем:
A=1Æ c B=1Æ c C=2Æ d D=2Æ d Е=3Æ d
Далее маршрутизатор e , ранее не работавший по каким-либо причинам, рассылает в сети В, С, Е свой вектор (В=1,С=1,Е=1). Узел c получает этот вектор из сети В, увеличивает расстояния на 1 и обнаруживает, что расстояние Е=2 меньше имеющегося в таблице Е=3, следовательно запись о сети Е в таблице заменяется на Е=2Æ e. Остальные элементы полученного от e вектора не вызывают обновления таблицы.
Итоговая таблица маршрутов маршрутизатора c : A=1Æ c
B=1Æ c C=2Æ d D=2Æ d Е=2Æ e
5
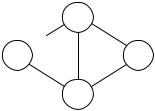
На этом алгоритм сходится, то есть при неизменной топологии системы никакие векторы расстояний, получаемые маршрутизатором c , больше не внесут изменений в таблицу маршрутов. Аналогичным образом алгоритм составления таблицы маршрутов работает и сходится на других маршрутизаторах. Несмотря на то, что таблицы маршрутов построены, векторы расстояний продолжают периодически широковещательно рассылаться каждым маршрутизатором. Это требуется для оперативного реагирования на внезапные изменения топологии системы.
Очевидно, что вид построенной таблицы маршрутов может зависеть от порядка получения маршрутизатором векторов расстояний. Например, если бы узел c получил вектор от узла e раньше, чем от узла d , то дейтаграммы в сеть С посылались бы от c через e.
3.1.2. Изменение состояния RIP-системы.
В случае, когда состояние системы изменяется, например, маршрутизатор c отключается от сети А, рисунок 2.
A |
2 |
D |
|
||
1 |
C |
4 |
B |
3 |
E |
|
|
Рисунок 2.
Узел c обнаруживает свое отсоединение от сети А и меняет таблицу маршрутов, устанавливая бесконечное расстояние до всех сетей, ранее достижимых через маршрутизаторы, подключенные к сети А (то есть d ). В протоколе RIP значение бесконечности равно 16.
A=16Æ c B=1Æ c C=16Æ d D=16Æ d Е=2Æ e
Вектор расстояний, построенный на основании этой таблицы, рассылается в сеть В, чтобы маршрутизаторы, направлявшие свои данные через c в ставшие недоступными сети, если таковые маршрутизаторы существуют, соответственно изменили свои маршрутные таблицы.
Допустим, в узле e имелась следующая таблица маршрутов: A=2Æ d
B=1Æ e C=1Æ e D=2Æ f Е=1Æ e
Узел e периодически и широковещательно рассылает в сети В, С, Е свой вектор расстояний (А=2,В=1,С=1,D=2,E=1). Узел c получает этот вектор, увеличивает расстояния на 1: (А=3,В=2,С=2,D=3,E=2) и замечает, что расстояния А=3, С=2 и D=3 меньше бесконечности следовательно, соответствующие записи таблицы маршрутов модифицируются и она принимает вид:
A=3Æ e B=1Æ c C=2Æ e D=3Æ e Е=2Æ e
Таким образом, узел c построил маршруты в обход поврежденного участка и восстановил достижимость всех
сетей.
3.2. Особые случаи.
К сожалению, поведение дистанционно-векторных протоколов (и в частности, протокола RIP) при изменении топологии системы не всегда корректно и предсказуемо.
В случае, представленном на рисунке 2 предполагалось, что узел e не отправлял дейтаграмм через узел c (и, следовательно, изменение таблицы маршрутов в узле c не повлияло на таблицу узла e ). Если узел e отправлял дейтаграммы в сеть А через c , то есть таблица в узле e имела вид:
A=2Æ c B=1Æ e C=1Æ e D=2Æ f Е=1Æ e
После отсоединения c от сети А узел e получает от c вектор (A=16,B=1,C=16,D=16,E=2). Проанализировав этот вектор, e делает вывод, что все указанные в нем расстояния больше значений, содержащихся в его маршрутной таблице, на основании чего этот вектор узлом e игнорируется.
6
Всвою очередь узел e рассылает в сети В, С, Е вектор (A=2,B=1,C=1,D=2,E=1). Узел c получает этот вектор, увеличивает расстояния на 1: (А=3,В=2,С=2,D=3,E=2) и замечает, что расстояния А=3, С=2 и D=3 меньше бесконечности, следовательно, соответствующие записи таблицы маршрутов в узле c модифицируются и она принимает вид:
A=3Æ e B=1Æ c C=2Æ e D=3Æ e Е=2Æ e
Очевидно, после этого содержимое таблиц узлов c и e стабилизируется. Записи о достижении сети А в таблицах маршрутизаторов c и e имеют вид: в узле c : A=3Æ e;
в узле e : A=2Æ c.
Таким образом, возникло зацикливание: данные, адресованные в сеть А, будут пересылаться между узлами c и e до тех пор, пока не истечет время жизни дейтаграмм и они не будут уничтожены.
Для того, чтобы избежать зацикливания, в алгоритм рассылки векторов расстояний вносятся следующие дополнения.
Если дейтаграммы, адресованные в сеть Х, посылаются через маршрутизатор G, находящийся в сети N, то в векторе расстояний, рассылаемом в сети N, расстояние до сети Х не указывается.
Впримере узел e будет рассылать в сети В вектор (B=1,C=1,D=2,E=1). Элемент А=2 не будет включен в этот вектор, потому что дейтаграммы в сеть А отправляются узлом e через узел c , а узел c находится в сети В. При рассылке узлом e вектора расстояний в другие сети элемент A=1 будет указан (но не будут указаны какие-то другие элементы).
Если маршрутизатор G объявляет новое расстояние до сети Х, то это расстояние вносится в таблицы маршрутов узлов, отправляющих дейтаграммы в сеть X через G, независимо от того, больше оно или меньше уже внесенного в таблицы расстояния.
Впримере это означает, что если в маршрутной таблице узла e записано А=1Æ c и e получает от c вектор с элементом А=16, то несмотря на то, что 1 меньше бесконечности, узел e модифицирует запись в таблице: А=16Æ c .
Очевидно, что при выполнении вышеуказанных условий зацикливания, рассмотренного в примере, не образуется и строятся корректные маршруты. Однако таким образом устраняются далеко не все случаи зацикливания.
Тем не менее и в этом случае особые ситуации все еще остаются.
3.3. Реализация протокола RIP.
Существуют две версии протокола RIP: RIPv1 и RIPv2. Версия 2 имеет некоторые усовершенствования, как то: возможность маршрутизации сетей по модели CIDR (кроме адреса сети передается и маска), поддержка мультикастинга, возможность использования аутентификации RIP-сообщений и др.
3.3.1. Типы и формат сообщений.
В протоколе RIP имеются два типа сообщений, которыми обмениваются маршрутизаторы:
-ответ (response) – рассылка вектора расстояний;
-запрос (request) – маршрутизатор (например, после своей загрузки) запрашивает у соседей их маршрутные таблицы или данные об определенном маршруте.
Обмен сообщениями происходит по порту 520 UDP.
3.3.2. Работа протокола RIP.
Для каждой записи в таблице маршрутов существует время жизни, контролируемое таймером. Если для любой конкретной сети, внесенной в таблицу маршрутов, в течение 180 с не получен вектор расстояний, подтверждающий или устанавливающий новое расстояние до данной сети, то сеть будет отмечена как недостижимая (расстояние равно бесконечности). Через определенное время модуль RIP производит «сборку мусора» - удаляет из таблицы маршрутов все сети, расстояние до которых бесконечно.
При получении сообщения типа «ответ» для каждого содержащегося в нем элемента вектора расстояний модуль RIP выполняет следующие действия:
-проверяет корректность адреса сети и маски, указанных в сообщении;
-проверяет, не превышает ли метрика (расстояние до сети) бесконечности;
-некорректный элемент игнорируется;
-если метрика меньше бесконечности, она увеличивается на 1;
-производится поиск сети, указанной в рассматриваемом элементе вектора расстояний, в таблице маршрутов;
-если запись о такой сети в таблице маршрутов отсутствует и метрика в полученном элементе вектора меньше бесконечности, сеть вносится в таблицу маршрутов с указанной метрикой; в поле «Следующий маршрутизатор» заносится адрес маршрутизатора, приславшего сообщение; запускается таймер для этой записи в таблице;
-если искомая запись присутствует в таблице с метрикой больше, чем объявленная в полученном векторе, в таблицу вносятся новые метрика и, соответственно, адрес следующего маршрутизатора; таймер для этой записи перезапускается;
-если искомая запись присутствует в таблице и отправителем полученного вектора был маршрутизатор, указанный в поле «Следующий маршрутизатор» этой записи, то таймер для этой записи перезапускается; более того, если при
7
этом метрика в таблице отличается от метрики в полученном векторе расстояний, в таблицу вносится значение метрики из полученного вектора; - во всех прочих случаях рассматриваемый элемент вектора расстояний игнорируется.
Сообщения типа «ответ» рассылаются модулем RIP каждые 30 с по широковещательному или мультикастинговому (только RIP-2) адресу; рассылка «ответа» может происходить также вне графика, если маршрутная таблица была изменена (triggered response). Стандарт требует, чтобы triggered response рассылался не немедленно после изменения таблицы маршрутов, а через случайный интервал длительностью от 1 до 5с. Эта мера позволяет несколько снизить нагрузку на сеть.
Протокол RIP описан в RFC-1058 (версия 1) и RFC-1388 (версия 2).
3.3.3. Конфигурирование RIP.
Общий порядок действий при конфигурировании модуля RIP следующий:
-указать, какие сети, подключенные к маршрутизатору, будут включены в RIP-систему;
-указать «nonbroadcast networks», т.е. сети со статической маршрутизацией (например, тупиковые сети, подсоединенные к внешнему миру через единственный шлюз), куда не нужно рассылать векторы расстояний;
-указать «permanent routes» – статические маршруты, например, маршрут по умолчанию за пределы автономной системы.
4. Протокол OSPF.
Протокол OSPF (Open Shortest Path First – выбор кратчайшего пути первым) является реализацией алгоритма состояния связей и обладает многими особенностями, ориентированными на применение в больших гетерогенных сетях.
4.1. Два этапа построения таблицы маршрутизации.
Как и все протоколы маршрутизации, основанные на алгоритме состояния связей, OSPF разбивает процесс построения таблицы маршрутизации на два этапа.
На первом этапе каждый маршрутизатор строит граф связей сети, в котором вершинами графа являются маршрутизаторы и IP-сети, а ребрами – интерфейсы маршрутизаторов. Все маршрутизаторы для этого обмениваются со своими соседями той информацией о графе сети, которой они располагают к данному моменту. Этот процесс похож на процесс распространения векторов расстояний до сетей в протоколе RIP, однако сама информация качественно иная – это информация о топологии сети. Сообщения, с помощью которых распространяется топологическая информация, называются объявлениями о состоянии связей сети (Link State Advertisements, LSA). Кроме того, при передаче топологической информации OSPF маршрутизаторы ее не модифицируют, как это делают RIP-маршрутизаторы, а передают в неизменном виде. В результате все маршрутизаторы сети располагают идентичными сведениями о графе сети, которые хранятся в базе данных о топологии сети.
Второй этап состоит в нахождении оптимальных маршрутов с помощью полученного графа. Задача нахождения оптимального пути на графе является достаточно сложной и трудоемкой. В протоколе OSPF для ее решения используется итеративный алгоритм Дийкстры. Каждый маршрутизатор считает себя центром сети и ищет оптимальный маршрут до каждой известной ему сети. В каждом найденном таким образом маршруте запоминается только один шаг – до следующего маршрутизатора, в соответствии с принципом одношаговой маршрутизации. Данные об этом шаге и попадают в таблицу маршрутизации. Если несколько маршрутов имеют одинаковую метрику до сети назначения, то в таблице маршрутизации запоминаются первые шаги всех этих маршрутов.
4.2. Сообщения HELLO и корректировка таблиц маршрутизации.
Для того чтобы база данных о топологии сети соответствовала текущему состоянию сети, OSPF-маршрутизаторам необходимо постоянно отслеживать изменения состояния сети и вносить при необходимости коррективы в таблицу маршрутизации. Для контроля состояния связей и соседних маршрутизаторов OSPF-маршрутизаторы регулярно передают друг другу сообщения HELLO. Сообщения HELLO отправляются через каждые 10 секунд, чтобы повысить скорость адаптации маршрутизаторов к изменениям, происходящим в сети. Небольшой объем этих сообщений делает возможной такое частое тестирование состояния соседей и связей с ними. На основании принимаемых от непосредственных соседей сообщений HELLO маршрутизатор формирует записи о состоянии связях со своими непосредственными соседями в базе данных о топологии сети.
В том случае, когда сообщения HELLO перестают поступать от какого-либо непосредственного соседа, маршрутизатор делает вывод о том, что состояние связи изменилось с работоспособного на неработоспособное и делает соответствующую отметку в своей базе данных. Одновременно он отсылает всем непосредственным соседям объявление LSA об этом изменении, и те также корректируют свои базы данных и, в свою очередь, рассылают данное объявление LSA своим непосредственным соседям (естественно, кроме того соседа, от которого оно было получено). После корректировки графа сети каждый маршрутизатор заново ищет оптимальные маршруты и корректирует свою таблицу маршрутизации. Конвергенция таблиц маршрутизации к новому стабильному состоянию происходит очень быстро, это время состоит из времени передачи объявления LSA и времени работы алгоритма Дийкстры для нахождения новых маршрутов. Аналогичный процесс происходит и в том случае, когда в сети появляется новый сосед, объявляющий о себе с помощью своих сообщений HELLO, или новая связь.
Если же состояние сети не меняется, то объявления о связях не генерируются и таблицы маршрутизации не корректируются, что экономит пропускную способность сети и вычислительные ресурсы маршрутизаторов. Однако у
8
этого правила есть исключение: каждые 30 минут OSPF-маршрутизаторы обмениваются всеми записями базы данных топологической информации, то есть синхронизируют их для более надежной работы сети. Так как этот период достаточно большой, то данное исключение незначительно сказывается на работе сети.
4.3. Связи и метрики.
Маршрутизаторы соединены как с локальными сетями, так и непосредственно между собой глобальными двухточечными линиями связи, например каналами Т1. Протокол OSPF в своих объявлениях распространяет информацию о связях двух типов: маршрутизатор – маршрутизатор и маршрутизатор – сеть.
Каждая связь характеризуется метрикой. Протокол OSPF по умолчанию использует метрику, учитывающую пропускную способность каналов связи. Кроме того, допускается использование двух других метрик, учитывающих задержки и надежность передачи пакетов каналами связи. Для каждой из метрик протокол OSPF строит отдельную таблицу маршрутизации. Выбор нужной таблицы происходит в зависимости от значений битов TOS в заголовке пришедшего IP-пакета.
Протокол OSPF поддерживает стандартные для многих протоколов (например, для протокола покрывающего дерева) значения расстояний для метрики, отражающей пропускную способность: так, для сети Ethernet она равна 10, для Fast Ethernet – 1, для канала Т1 – 65, для канала 56 Кбит/с – 1785. При использовании высокоскоростных каналов, таких как Gigabit Ethernet или STM-16/64, администратору нужно задать другую шкалу скоростей, назначив единичное расстояние наиболее скоростному каналу.
При выборе оптимального пути на графе с каждым ребром графа связана метрика, которая добавляется к пути, если данное ребро в него входит. Пусть на приведенном примере маршрутизатор R5 связан с маршрутизаторами R6 и R7 каналами Т1, а маршрутизаторы R6 и R7 связаны между собой каналом 56 Кбит/с. Тогда R7 определит оптимальный маршрут до сети 201.106.14.0 как составной, проходящий сначала через R5, а затем через R6, поскольку у этого маршрута метрика будет равна 65 + 65 = 130 единиц. Непосредственный маршрут через R6 не будет оптимальным, так как его метрика равна 1785. При использовании хопов был бы выбран маршрут через R6, что было бы не оптимально.
Протокол OSPF разрешает хранить в таблице маршрутизации несколько маршрутов к одной сети, если они обладают равными метриками. Если такие записи образуются в таблице маршрутизации, то маршрутизатор реализует режим баланса загрузки маршрутов, отправляя пакеты попеременно по каждому из маршрутов.
4.4. Области сети.
К сожалению, вычислительная сложность протокола OSPF быстро растет с увеличением размерности сети. Для преодоления этого недостатка в протоколе OSPF вводится понятие области сети (не нужно путать с автономной системой Интернета). Маршрутизаторы, принадлежащие некоторой области, строят граф связей только для этой области, что сокращает размерность сети. Между областями информация о связях не передается, а пограничные для областей маршрутизаторы обмениваются только информацией об адресах сетей, имеющихся в каждой из областей, и расстоянием от пограничного маршрутизатора до каждой сети. При передаче пакетов между областями выбирается один из пограничных маршрутизаторов области, а именно тот, у которого расстояние до нужной сети меньше.
Маршрутизация в ОС FreeBSD Unix
1. Таблица маршрутизации.
Маршрут во FreeBSD задаётся парой адресов: адресом назначения (destination) и сетевым шлюзом (gateway). Существует три типа адресов назначения: отдельные узлы, подсети и маршрут по умолчанию (default). Маршрут по умолчанию (default route) используется, если не подходит ни один из других маршрутов. Также имеется и три типа сетевых шлюзов: отдельные узлы, интерфейсы (также называемые подключениями (links)) и аппаратные адреса Ethernet (MAC-адреса).
Пример:
% netstat -r Routing tables
Destination |
Gateway |
Flags |
Refs |
Use |
Netif Expire |
Default |
outside-gw |
UGSc |
37 |
418 |
ppp0 |
localhost |
localhost |
UH |
0 |
181 |
lo0 |
test0 |
00:02:b3:36:cf:4f |
UHLW |
5 |
63288 |
fxp0 77 |
10.18.51.255 |
link#1 |
UHLW |
1 |
2421 |
|
example.com |
link#1 |
UC |
0 |
0 |
lo0 |
host1 |
00:02:b3:37:8:1e |
UHLW |
3 |
4601 |
|
host2 |
00:02:b3:37:8:1e |
UHLW |
0 |
5 |
lo0 => |
224 |
link#1 |
UC |
0 |
0 |
|
Интерфейс (колонка Netif), который указан в этой таблице маршрутов для использования с localhost и который назван lo0, имеет также второе название, устройство loopback.
Следующими выделяющимися адресами являются адреса, начинающиеся с 00:02:.... Это аппаратные адреса Ethernet, или MAC-адреса. FreeBSD будет автоматически распознавать любой узел (в примере это test0) в локальной
9

сети Ethernet и добавит маршрут для этого узла, указывающий непосредственно на интерфейс Ethernet, fxp0. С этим типом маршрута также связан параметр таймаута (колонка Expire), используемый в случае неудачной попытки услышать этот узел в течении некоторого периода времени. Если такое происходит, то маршрут до этого узла будет автоматически удалён.
FreeBSD добавит также все маршруты к подсетям для локальных подсетей (10.18.51.255 является широковещательным адресом для подсети 10.18.51, а имя example.com является именем домена, связанным с этой подсетью). Назначение link#1 соответствует первому адаптеру Ethernet в машине.
Строка host1 относится к локальному узлу, который известен по адресу Ethernet. Все пакета, отправляемые этому узлу отправляются на loopback-интерфейс (lo0) вместо того, чтобы осуществлять посылку в интерфейс Ethernet.
Строка host2 являются примером того, что происходит при использовании алиасов в команде ifconfig(8). Символ => после интерфейса lo0 указывает на то, что используется не просто интерфейс loopback (так как это адрес, обозначающий локальный узел), но к тому же это алиас.
Последняя строчка (подсеть назначения 224) имеет отношение к многоадресной рассылке.
Различные атрибуты каждого маршрута перечисляются в колонке Flags. Ниже приводится краткая таблица некоторых из этих флагов и их значений:
U Up: Маршрут актуален.
H Host: Адресом назначения является отдельный узел.
GGateway: Посылать все для этого адреса назначения на указанную удаленную систему, которая будет сама определять дальнейший путь прохождения информации.
S Static: Маршрут был настроен вручную, а не автоматически сгенерирован системой.
CClone: Новый маршрут сгенерирован на основе указанного для машин, к которым подключен данный узел. Такой тип маршрута обычно используется для локальных сетей.
WWasCloned: Указывает на то, что маршрут был автоматически сконфигурирован на основе маршрута в локальной сети (Clone).
L Link: Маршрут включает ссылку на аппаратный адрес Ethernet.
2. Маршруты по умолчанию.
Когда локальному узлу необходимо отправить пакет на другой узел, он обращается к таблице маршрутов. Если узел назначения попадает в подсеть, для которой известен способ ее достижения, то локальный узел определяет интерфейс и передает ему пакет.
Если все известные маршруты не подходят, у узла имеется последняя возможность: маршрут default. Это маршрут с особым типом сетевого шлюза (обычно единственным, присутствующим в системе), и в поле флагов он всегда помечен как c. Для узлов в локальной сети этот сетевой шлюз указывает на машину, имеющую прямое подключение к внешней сети.
Шлюз по умолчанию можно задать в файле /etc/rc.conf. defaultrouter="10.18.51.1"
Это также возможно сделать и непосредственно из командной строки при помощи команды route(8):
# route add default 10.18.51.1
3. Узлы с двумя интерфейсами.
У компьютера есть два адаптера Ethernet, каждый имеет адрес, принадлежащий разным подсетям. Как альтернативу можно рассмотреть вариант с одним Ethernet-адаптером и использованием алиасов. В первом случае используются две физически разделённые сети Ethernet, в последнем имеется один физический сегмент сети, но две логически разделённые подсети.
В любом случае таблицы маршрутизации настраиваются так, что для каждой подсети этот узел был определен как шлюз (входной маршрут) в другую подсеть.
Сетевой маршрутизатор является обычной системой, которая пересылает пакеты с одного интерфейса на другой. Эта функция по умолчанию включена во FreeBSD. Можно включить эту возможность, изменив значение следующей
переменной в YES в файле rc.conf(5): |
# Set to YES if this host will be a gateway |
gateway_enable=YES |
Этот параметр изменит значение sysctl(8) – переменной net.inet.ip.forwarding в 1. Если временно нужно выключить маршрутизацию, можно на время сбросить это значение в 0.
Маршрутизатору нужна информация о маршрутах для того, чтобы знать, куда пересылать пакеты. Если сеть достаточно проста, то можно использовать статические маршруты.
4. Настройка статических маршрутов. Пример сети представлен на рисунке 3.
В этой сети RouterA – это компьютер с FreeBSD, который выступает в качестве маршрутизатора в сеть Internet. Его шлюз по умолчанию 10.0.0.1, что позволяет ему отправлять пакеты во внешнюю сеть. Пусть RouterB уже правильно настроен и знает все необходимые маршруты (для RouterB маршрут по умолчанию 192.168.1.1).
10