

1.8. В-деревья.
Идея использования дополнительной памяти для ускорения доступа к данным особенно важна, если рассматриваемый набор данных содержит очень большое количество записей, которые требуется хранить на диске. Основной метод организации таких наборов данных — индексы, которые предоставляют определенную информацию о размещении записей с указанными значениями ключей. Для наборов данных, состоящих из структурированных записей наиболее важной организацией индексов являются В-деревья (В-tree), разработанные Р. Бойером (R. Bayer) и Э. Мак-Грейтом (Е. McGreight) [12]. Они расширяют идею 2-3-деревьев, разрешая иметь в одном узле дерева поиска много ключей.
В
В-дереве все записи данных (или ключи)
хранятся в листьях, в возрастающем
порядке ключей, а родительские узлы
используются для индексирования. В
частности, каждый родительский узел
содержит n
- 1 упорядоченных ключей
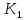 < … <
< … <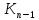 (которые
для простоты полагаем различными). Ключи
разделеныn
указателями на дочерние узлы, так что
все ключи в поддереве
(которые
для простоты полагаем различными). Ключи
разделеныn
указателями на дочерние узлы, так что
все ключи в поддереве
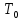 меньше
меньше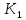 ,
все ключи в поддереве
,
все ключи в поддереве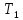 — не меньше
— не меньше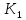 и меньше
и меньше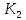 причем
причем
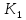 равен
наименьшему ключу в
равен
наименьшему ключу в
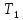 ,
и так далее до последнего поддерева
,
и так далее до последнего поддерева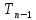 ,
ключи которого не меньше
,
ключи которого не меньше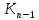 причем
причем
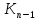 равен наименьшему ключу в
равен наименьшему ключу в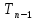 .
.
Кроме того, В-дерево порядка m ≥ 2 должно удовлетворять следующим структурным свойствам:
Корень либо является листом, либо имеет от 2 до m потомков.
Каждый узел, за исключением корня и листьев, имеет от [m/2] до m
потомков (и, следовательно, от [m/2] - 1 до m - 1 ключей).
Дерево (идеально) сбалансировано, т.е. все листья находятся на одном и том же уровне.
Поиск в В-дереве похож на поиск в бинарном дереве поиска, и еще больше — на поиск в 2-3-дереве. Начиная с корня, мы следуем по цепочке указателей к листу, который может содержать искомый ключ. Затем мы ищем ключ среди ключей этого листа. Заметим, что, поскольку ключи хранятся в отсортированном порядке как в родительских узлах, так и в листьях, мы можем воспользоваться бинарным поиском, если количество ключей в узле достаточно велико, чтобы сделать такой поиск оправданным.
Однако при рассмотрении типичного приложения этой структуры данных мы должны в первую очередь рассматривать не количество сравнений ключей. При использовании для хранения больших объемов данных дискового файла узлы В-дерева обычно соответствуют дисковым страницам. Поскольку обычно время, необходимое для обращения к дисковой странице, на несколько порядков превышает время сравнения двух ключей в быстрой основной памяти, основным показателем эффективности для этой и подобных структур данных является количество обращений к диску.
Таким образом поиск в В-дереве является операцией, принадлежащей классу эффективности O(logn).
Часть 2. Экспериментальный анализ алгоритмов.
2.1. Суть эксперимента.
Мы рассмотрели несколько алгоритмов, провели оценку их временной. Однако, как уже говорилось, данные критерии оценки не позволяют нам наверняка сказать, какой из алгоритмов будет быстрее работать. Поэтому, для дополнительной оценки проведем их экспериментальный анализ, т.е. измерим время, за которое алгоритм выполняет конкретно поставленную задачу.
Проведем поиск заданного слова в словаре для некоторых алгоритмов и измерим время работы программы. При этом будем учитывать следующее:
Строки предварительно загружаем в оперативную память (в виде массива), причем время считывания в массив не учитывается. Предобработка (создание таблиц перехода) входит в общее время.
Каждый алгоритм запускается 5 раз, время выбирается наименьшее.
Понятно, что такой замер времени даст нам весьма расплывчатые результаты, так как напрямую зависит от характеристик и загрузки процессора. Поэтому во время проведения эксперимента, отключались все сторонние и фоновые приложения, которые не влияют на работу программы. При запуске одной и той же задачи мы можем получить разное время, поэтому совершается несколько запусков, из которых выбирается наилучший результат.