

Konspekt_lektsiy_BD_amp_amp_SD
.pdfМ. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
1 |
Конспект лекцій |
|
з дисципліни “Технологія проектування баз даних та сховищ даних” |
|
Зміст |
|
Типи і структури даних..................................................................................................................... |
3 |
Поняття даних. Обробка даних. Інформаційна система............................................................ |
3 |
Структури даних............................................................................................................................ |
4 |
Спискові структури даних............................................................................................................ |
6 |
Лінійні списки............................................................................................................................ |
6 |
Деревоподібні структури.......................................................................................................... |
7 |
Графи (графові структури) ....................................................................................................... |
7 |
Елементи і параметри графів................................................................................................ |
8 |
Збереження топології графу................................................................................................. |
8 |
Системи баз даних........................................................................................................................... |
12 |
Архітектура системи БД ............................................................................................................. |
12 |
Моделювання предметної області.............................................................................................. |
14 |
Моделі даних................................................................................................................................ |
18 |
Мережева модель даних.......................................................................................................... |
19 |
Ієрархічна модель даних......................................................................................................... |
20 |
Реляційна модель даних.......................................................................................................... |
21 |
Реляційна алгебра................................................................................................................ |
23 |
Проектування БД......................................................................................................................... |
29 |
Нормалізація відношень.......................................................................................................... |
30 |
Друга нормальна форма...................................................................................................... |
31 |
Третя нормальна форма ...................................................................................................... |
33 |
Нормальна форма Бойса-Кодда.......................................................................................... |
33 |
Формалізація зв’язків між відношеннями................................................................................. |
36 |
Демонстраційний приклад.................................................................................................. |
41 |
SQL.................................................................................................................................................... |
44 |
Засоби розробки....................................................................................................................... |
44 |
Мова визначення даних (МВД, DDL) SQL. Частина 1 ............................................................ |
46 |
Типи даних............................................................................................................................... |
46 |
Домени...................................................................................................................................... |
46 |
Підтримка користувальницьких типів даних в СУБД PostgreSQL..................................... |
47 |
Створення нових типів........................................................................................................ |
47 |
Складені типи даних............................................................................................................ |
48 |
Додаткові структурні елементи.......................................................................................... |
50 |
Таблиці...................................................................................................................................... |
53 |
Логічні оператори................................................................................................................ |
55 |
Регулярні вирази. ................................................................................................................. |
56 |
Потенційні ключі................................................................................................................. |
60 |
Первинний ключ.................................................................................................................. |
61 |
Зовнішні ключі..................................................................................................................... |
61 |
Створення об’єктно-реляційних зв'язків в PostgreSQL........................................................ |
64 |
Індекси...................................................................................................................................... |
64 |
Представлення.......................................................................................................................... |
65 |
Демонстраційний приклад.................................................................................................. |
67 |
Мова маніпулювання даними (ММД, DML) SQL.................................................................... |
69 |
Основні команди ММД SQL .................................................................................................. |
69 |
Агрегатні функції..................................................................................................................... |
71 |
Аналітичні функції.................................................................................................................. |
75 |
Реалізація операцій з’єднання................................................................................................ |
80 |
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

2 |
М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
|
|
Демонстраційний приклад................................................................................................... |
88 |
Підзапити.................................................................................................................................. |
91 |
Об’єднання................................................................................................................................ |
98 |
Ієрархічні (рекурсивні) запити PostgreSQL ........................................................................... |
99 |
Підтримка механізму об’єктно-реляційних зв’язків в PostgreSQL ................................... |
101 |
Демонстраційний приклад................................................................................................. |
101 |
МВД (DDL) SQL. Частина 2...................................................................................................... |
103 |
Представлення, які модифікуються...................................................................................... |
103 |
Збережені процедури (ЗП)..................................................................................................... |
103 |
Особливості побудови збережених процедур в СУБД PostgreSQL .................................. |
107 |
Мова програмування PLpg/SQL СУБД PostgreSQL ....................................................... |
107 |
Структура підпрограм PLpg/SQL ..................................................................................... |
107 |
Змінні в PLpg/SQL.............................................................................................................. |
108 |
Атрибути............................................................................................................................. |
108 |
Управляючі структури....................................................................................................... |
109 |
Обробка помилок ............................................................................................................... |
111 |
Курсори................................................................................................................................... |
111 |
Тригери.................................................................................................................................... |
113 |
Підтримка сховищ даних засобами PLpg/SQL.................................................................... |
117 |
Демонстраційний приклад................................................................................................. |
118 |
Сценарії....................................................................................................................................... |
121 |
Мова управління даними SQL (МУД, DCL)............................................................................ |
122 |
Управління доступом............................................................................................................. |
122 |
Особливості управління доступом у СУБД PostgreSQL .................................................... |
123 |
Ролі та управління ролями ................................................................................................ |
123 |
Управління схемами даних ............................................................................................... |
125 |
Управління представленнями........................................................................................... |
127 |
Блокування.............................................................................................................................. |
129 |
Додаток А Схема системи баз даних до розділу „SQL“............................................................. |
131 |
Додаток Б Приклад сценарію для побудови таблиць до розділу „SQL“ .................................. |
134 |
Додаток В Приклади таблиць до розділу „SQL“......................................................................... |
137 |
Список літератури.......................................................................................................................... |
140 |
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
3 |
|
|
Типи і структури даних
Поняття даних. Обробка даних. Інформаційна система
У визначенні інформаційної системи використовуються два поняття: дані та предметна область (підобласть).
Дані — цифрові і графічні відомості про об’єкти навколишнього світу.
Під терміном обробка даних ми будемо розуміти послідовність дій, необхідних для виконання деякого завдання. Розрізняють числову і нечислову обробки.
Для числової обробки характерний великий обсяг обчислень, що складаються з ряду ітерацій (наприклад, розв’язання різних нелінійних рівнянь, операцій з матрицями і векторами тощо) з обов’язковим збереженням високої точності результатів.
При нечисловій обробці не потрібна висока точність і великий обсяг обчислень. Однак є дуже великий обсяг даних, що оброблюються і, крім того, при нечисловій обробці потрібно виконання таких специфічних операцій, як пошук конкретних даних, їхнє сортування.
У поняття „дані“ як об’єкти при числовій і нечисловій обробках вкладається різний зміст.
Так при числовій обробці ми маніпулюємо змінними, векторами, матрицями, константами та ін. При цьому нас не цікавить їхній вміст. Наприклад, при виконанні якої-небудь арифметичної операції чи операції введення/виведення необхідно знати адреси змінних (їхні імена), і не важливо, що знаходиться в цих змінних.
При нечисловій обробці об’єктами є файли, записи, поля, сітки, відношення та ін. У цьому випадку нас більше цікавить інформація, що міститься в конкретному запису, ніж місце розташування цього запису в файлі чи оперативній пам’яті.
Термін база даних (БД) позначає сукупність даних, призначених для спільного використання.
Оперуючи якою-небудь інформацією, можна розглядати дані, що відносяться до однієї або загальні для множини організацій чи сфер діяльності людини.
Реальний світ, що має бути відображений у БД, називають предметною областю
(ПрО).
Будь-яка частина реального світу є продуктом взаємодії певної частини фізичного світу та інтелектуального світу, що виник у виділеній частині фізичного світу.
Фізичним світом будемо називати Всесвіт. Частина фізичного світу — це деяка його k- вимірна область D, задана у вигляді множини k-вимірних точок в m-мірному просторі, що описує наш Всесвіт. Область D задається системою k-вимірних відношень. Тобто ця множина всіх k-вимірних точок відповідного простору, які задовольняють заданій системі математичних співвідношень.
Інтелектуальним світом будемо називати біологічну систему, що досягла такого рівня розвитку в деякій фізичній частині світу, при якому вона в змозі змінити частину фізичного світу, у якому вона існує і продовжує розвиватися, впливаючи на закони його еволюції.
Крім того, у процесі розвитку інтелектуального світу на деякому етапі виникла систематична потреба у все більш досконалих формах аналізу, обробки та організації інформації і знань, не пов’язаних безпосередньо з розумовими процесами, але які дозволяють під управлінням людини приймати бажані для нього форми цих процесів.
Частина інформаційного простору, яка має необхідний ступінь незалежності, самостійності і здатності до трансформації в необхідні форми та передачі їх відповідно до людських законів, але, в той же час, незалежно від людини, будемо називати віртуальним світом.
Для уточнення поняття віртуальний світ або віртуальна реальність, або віртуальність (від лат. virtus — потенційний, можливий, доблесть, енергія, сила, а також мнимий, уявний; лат. realis — речовинний, дійсний, існуючий) відзначимо два визначення.
„Віртуальна реальність у посткласичній науці — поняття, за допомогою якого позначається сукупність об’єктів наступного (стосовно нижчележачої, породжуючої їх реальності)
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

4 |
М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
|
|
рівня. Ці об’єкти онтологічно рівноправні з породжуючою їх „константною“ реальністю і автономні; при цьому їхнє існування повністю обумовлене перманентним процесом їхнього відтворення породжуючою реальністю...
Віртуальна реальність — технічно конструюєме за допомогою комп’ютерних засобів інтерактивне середовище породження і оперування об’єктами, подібними реальним або уявним, на основі їх тривимірного графічного представлення, симуляції їхніх фізичних властивостей (об’єм, рух тощо), симуляції їхньої здатності впливу та самостійної присутності в просторі“.
Фактично, віртуальний світ — це уявний світ, для якого визначені певні фізичні та математичні закони і який, при відповідних умовах, може бути за допомогою технічних засобів зроблений доступним для сприйняття органами почуттів людини. Тобто віртуальним світом є „фізичний“ світ, створений в межах інтелектуального світу.
В кожному зі світів: фізичному, інтелектуальному, віртуальному, у свою чергу, можна виділити предметну область. Предметна область реального світу є продуктом взаємодії відповідних предметних областей кожного зі світів.
Предметна область або домен (від англ. domain — область) — чітко обкреслений реальний, гіпотетичний або абстрактний світ, населений взаємозалежним набором об’єктів, які поводяться відповідно до характерних для предметної області правил та напрямів поведінки.
Побудова будь-якої інформаційної системи починається зі створення математичної, інформаційної, онтологічної і т.п. моделі ПрО, яка може бути реалізована у вигляді баз і сховищ даних.
Тому для того, щоб деяку предметну область представити в БД, потрібно виділити істотні поняття, необхідні користувачу, і зв’язки між ними. (Наприклад, книги у бібліотеці: читачу потрібні автор і назва, а не число малюнків чи якість паперу).
Класифікацію понять предметної області, конкретне наповнення яких буде виконане в БД, називають логічним проектуванням даних чи баз даних. З математичної точки зору мож-
на сказати, що логічне проектування — це абстрагування інформації про предметну область.
У зв’язку з цим необхідно визначити таке:
фізичні дані — дані, що зберігаються в пам’яті комп’ютера (дисковій чи оперативній).
логічне представлення даних відповідає користувальницькому уявленню фізичних даних. Наприклад: у файлі БД зберігаються 2 множини символьних рядків — це фізичні дані.
Логічне представлення: автори і назви книг.
Структури даних
При використанні комп’ютера для збереження й обробки даних необхідно добре знати тип і структуру даних, і визначити спосіб їхнього представлення.
Програму, призначену для досягнення деякої мети, можна розглядати як результат об’єднання структур даних і алгоритму.
Найчастіше існують різні алгоритми розв’язання однієї і тієї ж задачі, що залежать від способу представлення і упорядкованості даних. Реалізувати структуру даних необхідно так, щоб забезпечити ефективність їхньої обробки великим числом алгоритмів.
Як правило, структурування даних вимагає точного визначення типу кожного елемента, що входить у структуру.
Математичні принципи концепції типу, що покладені в основу мов програмування високого рівня такі:
1.Будь-який тип даних визначає множину значень, до яких може відноситися деяка константа, що може приймати будь-яка змінна або вираз і яке може формуватися операцією чи функцією.
2.Тип будь-якої величини, що позначається константою, змінною чи виразом, може бути виведений з її виду або з її опису (без необхідності будь-яких обчислень).
3.Кожна операція чи функція вимагає аргументів певного типу і дасть результат також фік-
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
5 |
|
|
сованого типу.
В обчислювальній техніці існує ряд так званих найпростіших стандартних типів даних: цілий, логічний, символьний тощо.
Крім того, існує можливість визначення нових типів шляхом переліку множини їхніх значень. Тому ці типи ще звуть перелічуванними. Вони також є найпростішими, проте, звісно, не стандартними. Наприклад:
колір {синій, червоний, зелений}
Структури даних інакше називають складеними типами, тому що вони являють собою сукупності компонентів, що відносяться до визначених раніше типів.
Якщо всі компоненти відносяться до одного типу, то такий тип називають базовим. Дані, крім типу, що визначає їхню структуру, мають специфічні властивості.
При розгляді структур даних ми будемо оперувати таким поняттям як множина, яка є сукупністю даних певного типу, що володіють деякою властивістю. При цьому повинні бути встановлені область визначення даних і правила визначення належності даних до множини.
Імовірно, що найбільше широко відома структура даних — одновимірний чи багатовимірний масив. Ця структура являє собою відображення деякої кінцевої множини даних на множину даних іншого типу. Тут областю визначення є множина даних типу індекс, а областю значень — множина елементів масиву. Масив складається з елементів одного базового типу, тому структура масиву однорідна.
Найбільш загальний метод одержання складених типів полягає в об’єднанні елементів різних типів. Причому самі елементи можуть бути складеними.
Нехай у нас є такі елементи:
ai A1 , a j A2 .
Якщо розглянути множину виду:
{(ai , aj ) ai A1 , aj A2 },
то ми дістанемо складений тип, що зветься прямим (декартовим) добутком. Кожен елемент такої структури зветься кортежем.
Назва „добуток“ пояснюється тим, що множина значень, визначена таким типом, складається з усіляких комбінацій наборів ai ,a j . Відповідно, число таких комбінацій дорівнює
добутку числа елементів у кожній зі складових множин. Приклад: |
||||||
1 |
{ |
} |
2 |
= |
{ |
} |
A |
= 1,3,8,9 |
, A |
|
2,3 |
||
1 |
2 |
{ |
|
|
|
} |
A |
× A = |
(1, 2), (3, 2), (8, 2), (9, 2), (1, 3), (3, 3), (8, 3), (9, 3) . |
||||
При обробці даних такі складені типи, що описують людей або об’єкти, є найбільш застосовними у файлах і базах даних. Тому до даних такої природи стали використовувати назву запис і розглядати його як ще один (третій) тип даних.
Четвертим типом структурованих даних є послідовності. Типові приклади послідовного типу даних — файл і стік. Всі елементи послідовності мають той самий тип. Структура послідовності дуже схожа на структуру масиву. Істотна відмінність полягає в тому, що в масиві число елементів фіксується в його опису, а число елементів послідовності (довжина) скінченне, але не фіксовано.
Послідовним файлом називається послідовність, для якої визначені такі операції:
1.Формування порожньої послідовності.
2.Вибірка початкового елемента послідовності.
3.Додавання елемента в кінець послідовності.
Стік — послідовність, над якою можливе виконання таких операцій:
1.Створення порожньої послідовності.
2.Одержання першого елемента послідовності.
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет
6 |
М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
|
|
3. Додавання елемента в початок послідовності.
Спискові структури даних
Лінійні списки
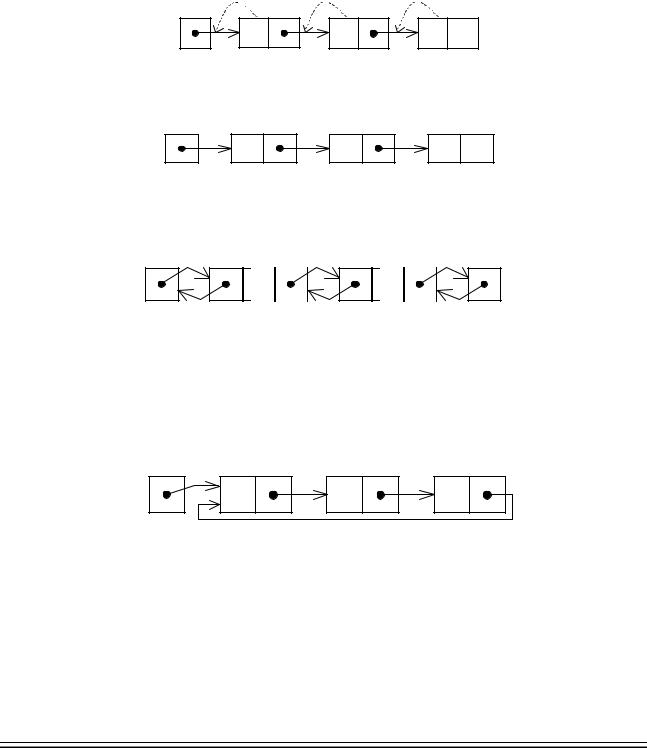
Припустимо, що дані записані не в послідовні адреси пам’яті (як у випадку масивів), а в довільні місця. У цьому випадку найбільш простий спосіб об’єднати чи зв’язати деяку множину елементів — це витягнути їх у лінію. І для того, щоб задати „зв’язок“ між даними, необхідно кожному елементу поставити у відповідність посилання або покажчик на наступний елемент структури (рис. 1), починаючи з порожнього.
Формування списку може виконуватися 2-ма способами: 1. Додаванням елементів у кінець списку (рис. 1).
P |
A |
B |
C |
M |
|
3 |
5 |
7 |
|
|
1 |
2 |
4 |
6 |
Рис. 1. Формування списку „з кінця“
2. Додаванням елементів у початок списку (рис. 2).
P |
A |
B |
C |
M |
|
4 |
3 |
2 |
1 |
Рис. 2. Формування списку „з початку“
Додавання і виключення елементів може виконуватися просто зміною покажчика.
Двозв’язний список виглядає так (рис. 3):
P |
A |
B |
L |
Рис. 3. Двозв’язний список
Таке представлення зручне з погляду обробки структур як з початку, так і з кінця списку. Недолік: додатковий покажчик. Якщо необхідно виконати обробку, як у прямому, так і в зворотному напрямку, то адреси повернення зручно зберігати в стеку: так організовані команди виклику/повернення з процедури.
Для забезпечення багаторазової обробки структури може використовуватися її представлення у вигляді циклічного списку (рис. 4):
P |
A |
B |
C |
Рис. 4. Циклічний список
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
7 |
|
|
Деревоподібні структури
|
|
|
Р |
|
Припустимо, що в списковій структурі кожен елемент може містити |
||||
|
|
|
|
або мітку кінця списку, або покажчик на не менше ніж 1 елемент. Дістане- |
|||||
|
|
|
|
|
|||||
|
|
|
|
|
мо так званий рекурсивний тип даних (рис. 5). Подібні структури назива- |
||||
|
A |
|
|
B |
ються деревами (вершини — вузли, зв’язки — гілки). |
|
|
||
|
|
|
До речі, лінійний список є виродженим деревом. У дереві можна ви- |
||||||
|
|
|
|
|
|||||
|
|
|
|
|
ділити деякі рівні та вузли, що відносяться до них. Вузол y, що знаходить- |
||||
C |
D |
E |
F |
G |
ся на i+1 рівні, називають нащадком вузла х i-го рівня, х — предок у. Ву- |
||||
зол, що не має предків, називають коренем. Вузол, що не має нащадків — |
|||||||||
|
|
|
|
|
термінальним вузлом чи листом. Нетермінальну вершину називають вну- |
||||
H |
I |
J |
K |
L |
трішньою. |
|
|
|
|
Рис. 5. Дерево |
Число безпосередніх нащадків вузла (фактично, число гілок, що ви- |
||||||||
ходять з нього) називають ступенем вершини (вузла). Максимальний сту- |
|||||||||
|
|
|
|
|
пінь, що мають усі вершини дерева — ступінь дерева. |
|
|
||
|
|
Найбільш важливими в обчислювальній техніці є дерева ступеня 2, так звані двійкові |
|||||||
(бінарні) дерева. |
|
|
|
|
|||||
|
|
Дерева ступеня > 2 називають багатогілковими. Зберігати їх незручно через велике чи- |
|||||||
сло посилань. Тому їх перетворюють у бінарні дерева одним зі способів: |
|
|
|||||||
|
|
|
|
|
|
A |
A1 |
A2 |
|
1. |
Розподілом вершини (рис. 6): |
|
|
|
|||||
2. |
Використанням двох типів покажчиків: покажчика на по- |
B C D |
B C |
D |
|||||
Рис. 6. Перетворення дерева |
|||||||||
|
дібний вузол і покажчика на породжений вузол (рис. 7): |
||||||||
|
|
|
|
|
|
до бінарного |
|
||
А
В |
С |
D |
М |
М |
М |
Рис. 7. Перетворення дерева до бінарного („комп’ютерний“ варіант)
Графи (графові структури)
Багато інформаційних задач зводяться до розгляду об’єктів, істотні властивості яких описуються зв’язками між ними. Наприклад, при розгляді електричних ланцюгів може цікавити наявність з’єднань між тими або іншими елементами, на карті авіаліній необхідно знати наявність зв’язку між містами. Інтерес можуть становити різні зв’язки і відносини між людьми, подіями, станами й ін. У подібних випадках зручно об’єкти представляти у вигляді ве-
ршин, а зв’язки між ними - лініями, називаними ребрами. |
|
х2 |
a24 |
х4 |
|
||
Множина вершин X, зв’язки між якими визначені мно- |
|
|
a23 |
|
a45 |
||
жиною ребер А, зветься графом (рис. 8): |
|
a12 |
a34 |
||||
{aij |
|
aij (xi , x j ), aij A, xi X , x j X } |
|
|
|
|
|
|
|
|
|
|
|||
|
х1 |
a13 |
х3 |
a35 |
х5 |
||
Перша робота з графів була розглянута Ейлером для |
|||||||
розв’язання задачі з топології. У середині минулого століття |
|
Рис. 8. Граф |
|
||||
Кірхгоф застосував графи для аналізу електричних кіл. |
|
|
|
|
|
||
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

8 |
М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
|
|
До речі, розглянутий нами тип даних дерево — окремий випадок графу.
Часто зв’язки між об’єктами характеризуються певною орієнтацією. Наприклад, напрямок струму в електричних з’єднаннях, перехід деякої системи з одного стану в інший.
Для зазначення напрямку зв’язку ребро відзначається стріл- |
|
кою (рис. 9). Орієнтоване таким чином ребро називається дугою, а |
|
граф з орієнтованими ребрами — орієнтованим графом чи оргра- |
|
фом. |
Рис. 9. Орграф |
Якщо вузли з’єднуються більш ніж двома дугами, то ці дуги |
|
називаються рівнобіжними. Якщо вони мають один напрямок — |
|
строго рівнобіжними, якщо різний — нестрого рівнобіжними. Дві нестрого рівнобіжні дуги в графі можна замінити ребром, діставши тоді змішаний граф. Змінивши напрямки дуг орграфу на протилежні, дістанемо орграф, зворотний початковому.
Подальший розгляд графів складається в приписуванні ребрам і дугам деяких кількісних значень або характерних властивостей, називаних вагами. Вага може означати довжину шляху, пропускну здатність ліній зв’язку, величину струму в електричному колі тощо. Граф у цьому випадку називається зваженим. Особливе значення для моделювання фізичних систем мають зважені орграфи, названі графами потоків, сигнальними графами чи сітками.
Елементи і параметри графів
Кожне ребро, відповідно до визначення, з’єднує пару вершин (xi , xj ), іменованих гра-
ничними вузлами. Для дуги розрізняють початковий вузол, з якого дуга виходить, і кінцевий, в який вона входить.
Якщо граничні (чи початковий і кінцевий) вузли збігаються, ребро чи дуга називається
петлею.
Поняття ступеня вузла аналогічно тому, що ми розглядали в деревах. В орграфі розрізняють позитивний (щодо вихідних з вузла дуг) і негативний (щодо вхідних) ступені. Граф, ступені усіх вузлів якого однакові і дорівнюють r, називається однорідним чи регулярним графом r-го ступеня.
Маршрут з вершини хi до xj дорівнює сумі ваг послідовних гілок (ребер), що з’єднують ці вузли. Замкнутий маршрут приводить у ту ж вершину, з якої почався, і називається циклом. Для орграфу маршрут визначається так, що початковий вузол наступної гілки повинен збігатися з кінцевим вузлом попередньої. Маршрут, що не містить повторюваних дуг, зветься
шляхом.
Збереження топології графу
1. Матриця суміжності
Два вузли хi, xj називають суміжними, якщо вони є граничними вузлами однієї гілки. Рядки і стовпці матриці суміжності відповідають вузлам графу, а її ij-й елемент дорівнює числу ребер, що зв’язують вузли хi і xj чи дуг, що виходять з хi у xj. Для сітки значення елемента може відповідати вазі гілки. Приклад (рис. 10).
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

|
|
М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
9 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x1 |
x2 |
x3 |
x4 |
x5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x1 |
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
х2 |
a24 |
х4 |
|
x2 |
|
|
1 |
1 |
|
|
|
|
a12 |
a23 |
a45 |
|
x3 |
|
|
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
a34 |
|
x4 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
х1 |
a13 |
х3 |
a35 |
х5 |
|
|
|
|
|
|
|
|
x5 |
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 10. Орієнтований граф і його матриця суміжності |
|
||||||||
2. |
Матриця інцидентності |
|
|
|
|
|
|
|
|
|
||
|
Якщо вузол хi — граничний для гілки аij, то вони інцидентні. Для орграфу розрізняють |
|||||||||||
позитивну (для початкових вузлів) і негативну (для кінцевих) інцидентність.
Рядки матриці інцидентності відповідають вузлам, а стовпці — ребрам. mn-й елемент дорівнює 1, якщо m-а вершина і n-е ребро інцидентні. Приклад (рис. 11).
|
a12 |
a13 |
a23 |
a24 |
a34 |
a35 |
a45 |
|
|
|
|
|
|
|
|
x1 |
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
x2 |
1 |
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
x3 |
|
1 |
1 |
|
1 |
1 |
|
|
|
|
|
|
|
|
|
x4 |
|
|
|
1 |
1 |
|
1 |
|
|
|
|
|
|
|
|
x5 |
|
|
|
|
|
1 |
1 |
|
|
|
|
|
|
|
|
Рис. 11. Матриця інцидентності графу з рис. 10
Для орграфу елементи дорівнюють 1 та –1 для початкових і кінцевих вузлів відповідно. 3. За допомогою множини списків
Для зберігання такої множини в пам’яті ЕОМ чи в БД створюються дві групи по три масиви (чи таблиці) (рис. 14):
1) номерів (в базах даних ми будемо використовувати поняття |
|
ідентифікатору) початкових вузлів (ПВ), номерів перших гі- |
|
лок, що виходять з початкових вузлів (ПГП), номерів реш- |
Рис. 12. Приклад графу. |
ти гілок, що виходять з цих вузлів (ГП); |
2)номерів кінцевих вузлів (КВ), номерів перших гілок, що входять до кінцевих вузлів (ПГК), номерів решти гілок, що входять до цих вузлів (ГК).
Структура масивів (таблиць) в цих групах попарно ідентична (рис. 14):
—індексами масиву ПВ (КВ) є номери гілок, а елементами — номери вузлів, з яких вони виходять (до яких входять);
—в масиві ПГП (ПГК) навпаки — індексами є номери вузлів, а елементами — номери гілок, для яких ці вузли є початковими (кінцевими);
—в масиві ГП (ГК) і індексами, і елементами є номери гілок, що входять до (виходять з) цих вузлів.
Формування списків здійснюється таким чином.
1. З графу береться будь-яка гілка і за індексом, що співпадає з її номером, до масиву ПВ
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет

10 |
М. Г. Глава. Технологія проектування і адміністрування баз даних та сховищ даних |
|
|
заноситься її початковий вузол (рис. 13а).
2.До масиву ПГП заноситься номер тієї гілки за індексом, що дорівнює номеру її початкового вузла (з масиву ПВ). Далі з масиву ПГП береться елемент (номер тієї ж гілки) і за індексом, що співпадає з ним, до масиву ГП заноситься позначка кінця списку М.
|
ПВ |
|
ПГП |
|
ГП |
|
ПВ |
|
ПГП |
|
ГП |
1 |
1 |
1 |
1 |
1 |
М |
1 |
1 |
1 |
1 2 |
1 |
М |
2 |
|
2 |
|
2 |
|
2 |
1 |
2 |
|
2 |
1 |
3 |
|
3 |
|
3 |
|
3 |
|
3 |
|
3 |
|
|
|
|
а |
|
|
|
|
|
б |
|
|
Рис. 13. Формування списку гілок, що виходять, графу з рис. 12.
3.Далі повторюються пункти 1-2 для будь-якої наступної гілки графу, доки весь граф не буде введений.
Але тут можлива ситуація, коли на другому кроці з’ясовується, що комірка масиву ПГП
вже зайнята. Це буде якщо наступна гілка має той же початковий вузол, що й гілка, яку вже введено. Тому загальний вигляд пункту 2 наведеного алгоритму формування масивів (таблиць) дещо зміниться:
2.До масиву ПГП заноситься номер тієї гілки за індексом, що дорівнює номеру її початкового вузла (з масиву ПВ).
Якщо відповідна комірка масиву ПГП вільна, то за індексом, що співпадає з новим
елементом масиву ПГП (номер гілки, яка обробляється), до масиву ГП заноситься позначка кінця списку М.
Якщо у комірці масиву ПГП було якесь значення, то воно видаляється і переноситься до масиву ГП за індексом, що співпадає з новим елементом масиву ПГП (рис. 13б).
Легко побачити, що в масивах ПГП та ГП зберігаються лінійні списки номерів гілок, що виходять з певних вузлів. Відтепер, взявши будь-який вузол графу, можна дістати перелік всіх гілок, що виходять з нього. Наприклад (рис. 14а), з вузла 2 виходять: (див. комірку 2 ма-
сиву ПГП) гілка 4, (див. комірку 4 масиву ГП) гілка 3 та (див. комірку 3 масиву ГП) … більше нічого (у цій комірці позначка кінця списку).
Цілком аналогічно формується друга група масивів (таблиць), яка містить номери кінцевих вузлів, та гілок, що входять в них (рис. 14б).
Таке представлення дозволяє зберігати топологію графу у зручному для оперативного аналізу вигляді. Наприклад, для автоматизованого вирішення задачі мережевого планування на підприємстві.
І нарешті, існує ще один варіант представлення даних: таблиці. Зокрема, більшість сучасних баз даних можуть бути представлені у вигляді множини таблиць, що дозволяє досить легко вводити, шукати і виводити дані.
Кафедра економічної кібернетики та інформаційних технологій. Одеський національний політехнічний університет