

Анализ данных и знаний / 4 лаба / 4
.doc#1
x11=data[1:45,2]
x11
[1] 189.5 184.5 170.0 178.5 180.0 170.0 148.5 167.0 161.0 199.0 162.0 165.5
[13] 152.0 140.0 154.5 155.5 146.0 149.5 147.0 147.5 143.5 139.0 130.5 149.0
[25] 163.5 181.0 178.0 180.5 185.0 172.0 171.0 179.0 177.0 176.0 166.0 157.0
[37] 178.0 164.5 156.0 164.5 171.5 164.0 162.5 163.0 169.0
x12=data[46:84,2]
x12
[1] 179.0 151.0 151.0 160.5 167.0 165.5 155.0 167.0 176.0 156.0 167.0 172.0
[13] 166.5 165.5 150.5 157.0 164.5 167.0 168.0 153.5 158.5 152.5 156.0 148.5
[25] 152.5 151.0 145.5 157.0 161.0 153.5 146.0 139.5 153.5 140.5 144.5 143.5
[37] 142.0 141.0 149.0
x21=data[1:45,3]
x21
[1] 189.0 166.5 180.0 156.0 172.0 162.5 153.0 161.0 165.5 150.0 149.5 161.5
[13] 157.0 160.5 151.0 154.5 146.5 139.0 150.0 138.0 161.0 124.5 138.0 124.5
[25] 154.0 184.0 171.5 167.0 176.0 172.0 169.0 161.5 164.5 173.0 175.0 182.0
[37] 178.0 162.0 177.5 146.0 168.5 146.0 164.0 169.0 162.0
x22=data[46:84,3]
x22
[1] 161.0 162.5 160.5 174.5 170.0 160.5 172.0 153.5 153.5 173.0 156.5 167.0
[13] 172.5 160.5 158.5 164.0 153.0 156.0 146.0 151.0 149.5 167.5 146.0 162.0
[25] 156.0 149.5 156.0 158.5 146.0 162.0 152.5 174.5 130.5 152.5 136.0 140.0
[37] 140.0 149.0 130.5
x31=data[1:45,4]
x31
[1] 187.5 167.0 175.0 175.5 164.0 147.5 173.0 165.5 160.5 170.0 156.0 149.5
[13] 141.0 151.0 146.0 141.5 163.0 152.5 143.0 151.0 130.5 152.5 149.0 150.5
[25] 140.0 182.0 178.0 189.5 160.0 184.5 185.0 169.5 173.0 169.5 166.5 173.0
[37] 157.0 168.5 175.0 175.0 158.5 170.0 179.0 171.5 164.0
x32=data[46:84,4]
x32
[1] 156.5 158.5 164.5 156.0 156.0 161.5 170.5 170.0 164.0 165.5 164.5 151.0
[13] 141.0 153.5 153.0 158.5 149.0 146.5 140.0 156.0 162.5 147.5 159.5 156.0
[25] 153.0 138.0 158.5 141.0 151.0 131.0 156.0 126.5 152.5 134.5 149.5 130.5
[37] 134.5 125.5 131.5
#2
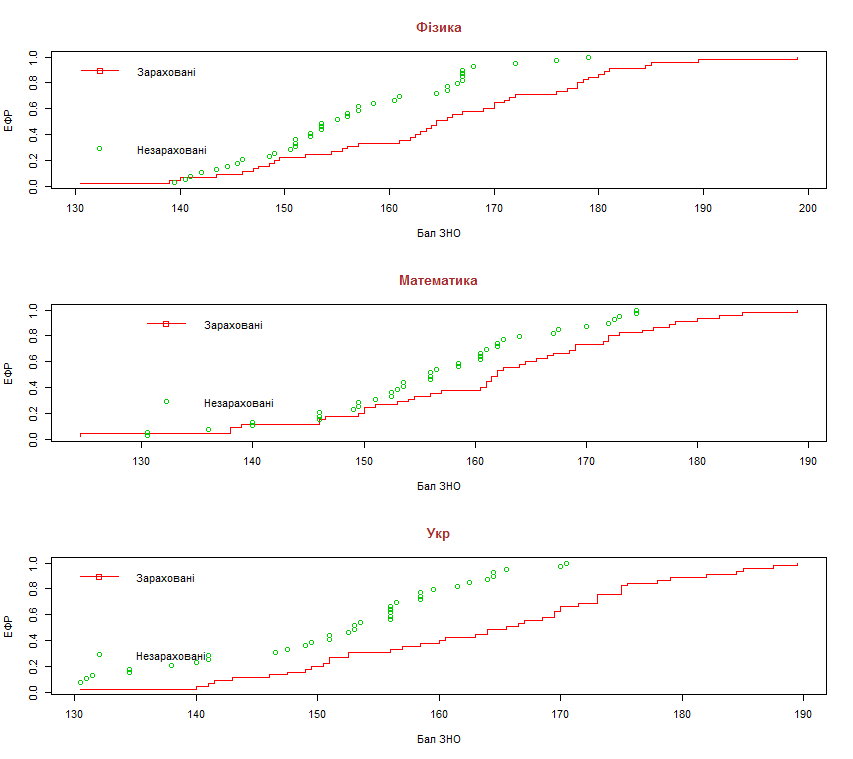
erf1 = seq(1/45, 1, len = 45)
erf2 = seq(1/39, 1, len = 39)
x11s = sort(x11); x12s = sort(x12)
x21s = sort(x21); x22s = sort(x22)
x31s = sort(x31); x32s = sort(x32)
old.par=par(mfrow=c(3,1))
plot(x11s, erf1, xlab = "Бал ЗНО", ylab = "ЕФР", main = "Фізика", type =
"s", col = 2, col.main = "brown", cex.main = 1.2)
points(x12s, erf2, col = 3)
legend(130, 1.5, c("Зараховані","Незараховані"), col=c(2,3), pch=c(0, 1),
bty = "n", lty=c(1, 0))
plot(x21s, erf1, xlab = "Бал ЗНО", ylab = "ЕФР", main = "Математика",
type = "s", col = 2, col.main = "brown", cex.main = 1.2)
points(x22s, erf2, col = 3)
legend(130, 1.5, c("Зараховані","Незараховані"), col=c(2,3), pch=c(0, 1),
bty = "n", lty=c(1, 0))
plot(x31s, erf1, xlab = "Бал ЗНО", ylab = "ЕФР", main = "Укр", type = "s", col = 2, col.main = "brown", cex.main = 1.2)
points(x32s, erf2, col = 3)
legend(130, 1.5, c("Зараховані","Незараховані"), col=c(2,3), pch=c(0, 1), bty
= "n", lty=c(1, 0))
par(old.par)
#3
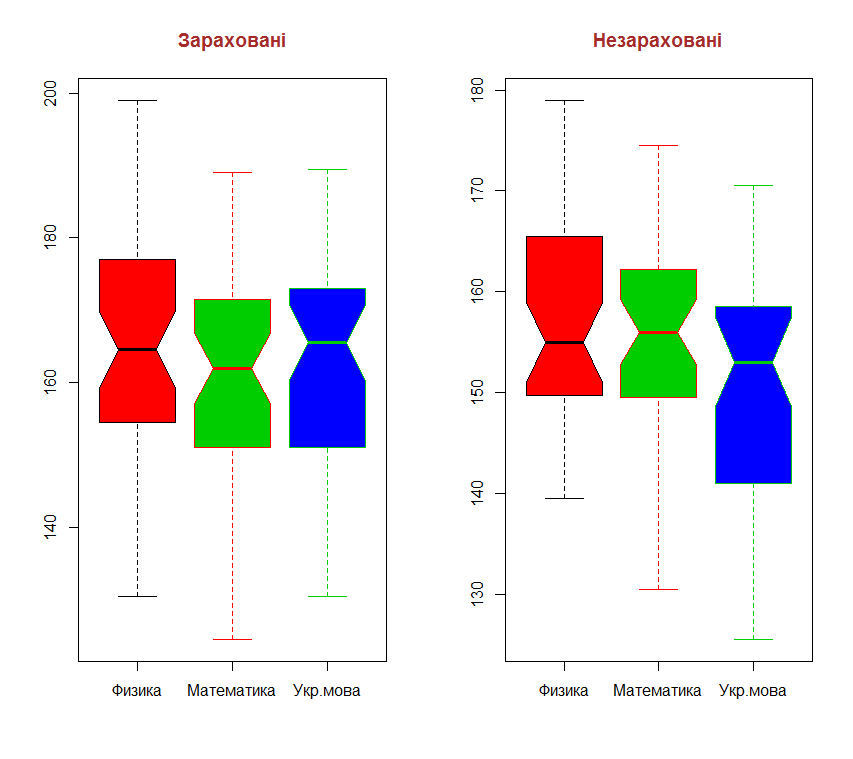
old.par=par(mfrow=c(1,2))
boxplot(x11, x21, x31, col = c(2:4), border = c(9:11), notch = TRUE, main = "Зараховані", names = c("Физика", "Математика", "Укр.мова"), col.main = "brown", cex.main = 1.2)
boxplot(x12, x22, x32, col = c(2:4), border = c(9:11), notch = TRUE, main = "Незараховані", names = c("Физика", "Математика", "Укр.мова"), col.main = "brown", cex.main = 1.2)
par(old.par)
#4
quantile(x11)
0% 25% 50% 75% 100%
130.5 154.5 164.5 177.0 199.0
quantile(x12)
0% 25% 50% 75% 100%
139.50 149.75 155.00 165.50 179.00
quantile(x21)
0% 25% 50% 75% 100%
124.5 151.0 162.0 171.5 189.0
quantile(x22)
0% 25% 50% 75% 100%
130.50 149.50 156.00 162.25 174.50
quantile(x31)
0% 25% 50% 75% 100%
130.5 151.0 165.5 173.0 189.5
quantile(x32)
0% 25% 50% 75% 100%
125.5 141.0 153.0 158.5 170.5
|
|
Мін |
25% |
50% |
75% |
Макс |
|
Физика, зарах |
130,5 |
154,5 |
164,5 |
177.0 |
199.0 |
|
Физика, незарах |
139,5 |
149,75 |
155,0 |
165,5 |
179,0 |
|
Математика, зарах |
124,5 |
151,0 |
162,0 |
171,5 |
189,0 |
|
Математика, незарах |
130,5 |
149,5 |
156,0 |
162,25 |
175,5 |
|
Укр. мова, зарах |
126.5 |
151,0 |
165,5 |
173,0 |
189,5 |
|
Укр. мова, незарах |
125.5 |
141,0 |
153,0 |
158,5 |
170,5 |
Минимальные результаты квантилей показывают, что результаты не зачисленных абитуриентов весьма низкие. Но можно заметить, что часть не зачисленных абитуриентов имеет достаточно высокие показатели.
#5
old.par=par(mfrow=c(3,2))
qqnorm(x11, main = "Фізика, зараховані", col = 2, col.main = "brown",
cex.main = 1.2)
qqline(x11, col = 4)
qqnorm(x12, main = "Фізика, незараховані", col = 3, col.main = "brown",
cex.main = 1.2)
qqline(x12, col = 4)
qqnorm(x21, main = "Математика, зараховані", col = 2, col.main =
"brown", cex.main = 1.2)
qqline(x21, col = 4)
qqnorm(x22, main = "Математика, незараховані", col = 3, col.main =
"brown", cex.main = 1.2)
qqline(x22, col = 4)
qqnorm(x31, main = "УМЛ, зараховані", col = 2, col.main = "brown",
cex.main = 1.2)
qqline(x31, col = 4)
qqnorm(x32, main = "УМЛ, незараховані", col = 3, col.main = "brown",
cex.main = 1.2)
qqline(x32, col = 4)
par(old.par)
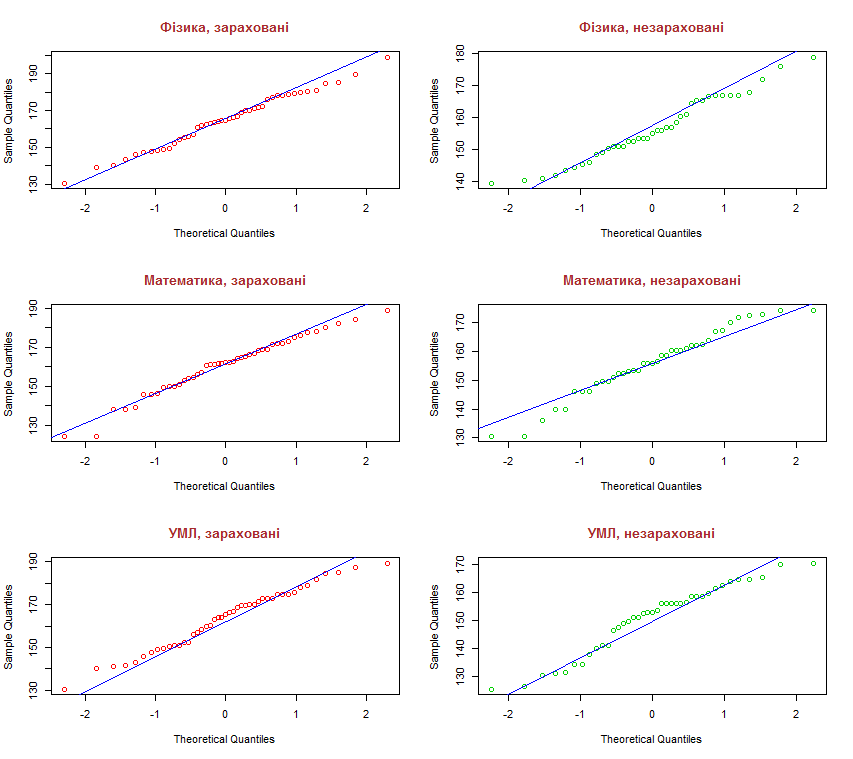
На диаграммах видно, что практически во всех случаях есть большие или маленькие отклонения от нормального распределения.
#6
sw1 = shapiro.test(x11)
install.packages("nortest")
library(nortest)
shapiro.test(x11)
ad.test(x11)
lillie.test(x11)
shapiro.test(x12)
ad.test(x12)
lillie.test(x12)
shapiro.test(x21)
ad.test(x21)
lillie.test(x21)
shapiro.test(x22)
ad.test(x22)
lillie.test(x22)
shapiro.test(x31)
ad.test(x31)
lillie.test(x31)
shapiro.test(x32)
ad.test(x32)
lillie.test(x32)
Shapiro-Wilk normality test
data: x11
W = 0.9887, p-value = 0.9354
> ad.test(x11)
Anderson-Darling normality test
data: x11
A = 0.2433, p-value = 0.7523
> lillie.test(x11)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x11
D = 0.0741, p-value = 0.7756
> shapiro.test(x12)
Shapiro-Wilk normality test
data: x12
W = 0.9678, p-value = 0.3213
> ad.test(x12)
Anderson-Darling normality test
data: x12
A = 0.4129, p-value = 0.3227
> lillie.test(x12)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x12
D = 0.1002, p-value = 0.4159
> shapiro.test(x21)
Shapiro-Wilk normality test
data: x21
W = 0.9748, p-value = 0.4261
> ad.test(x21)
Anderson-Darling normality test
data: x21
A = 0.3151, p-value = 0.5314
> lillie.test(x21)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x21
D = 0.1156, p-value = 0.138
> shapiro.test(x22)
Shapiro-Wilk normality test
data: x22
W = 0.9675, p-value = 0.3147
> ad.test(x22)
Anderson-Darling normality test
data: x22
A = 0.2932, p-value = 0.5847
> lillie.test(x22)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x22
D = 0.0714, p-value = 0.8852
> shapiro.test(x31)
Shapiro-Wilk normality test
data: x31
W = 0.9779, p-value = 0.5356
> ad.test(x31)
Anderson-Darling normality test
data: x31
A = 0.3606, p-value = 0.4323
> lillie.test(x31)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x31
D = 0.0889, p-value = 0.4986
> shapiro.test(x32)
Shapiro-Wilk normality test
data: x32
W = 0.9448, p-value = 0.05509
> ad.test(x32)
Anderson-Darling normality test
data: x32
A = 0.797, p-value = 0.03549
> lillie.test(x32)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x32
D = 0.1313, p-value = 0.08816
|
Выборка |
Критерии |
|||||
|
Шапиро-Уилка |
Андерсона-Дарлинга |
Колмогоров-Смирнов |
||||
|
W |
p-value |
A |
p-value |
D |
p-value |
|
|
Физика, зарах |
0,9887 |
0,9354 |
0,2433 |
0,7523 |
0,0741 |
0,7756 |
|
Физика, незарах |
0.9687 |
0,3213 |
0,4129 |
0,3227 |
0,1002 |
0,4159 |
|
Математика, зарах |
0,9748 |
0,4261 |
0,3151 |
0,5314
|
0,1156 |
0,138
|
|
Математика, незарах |
0,9675 |
0,3147 |
0,2932 |
0,5847 |
0,0714 |
0,8852 |
|
Укр. мова, зарах |
0,9779 |
0,5356 |
0,3606 |
0,4323 |
0,0889 |
0,4986 |
|
Укр. мова, незарах |
0,9448
|
0,05509 |
0,797 |
0,03549
|
0,1313 |
0,08816
|
В приведённых в таблице результатах, принятие “нулевой гипотезы про соответсвие данных нормальному распределению” возможно во всех случаях кроме последнего.
#7
t.test(x11, x31) #тест Уелча
var.test(x11, x31) #тест Фишера
t.test(x11, x21)
var.test(x11, x21)
ks.test(x22, x32) # тест Колмогорова – Смирнова;
wilcox.test(x22, x32) # тест Уїлкоксона
ansari.test(x22, x32) # тест Ансарі – Бредлі
t.test(x11, x31) #тест Уелча
Welch Two Sample t-test
data: x11 and x31
t = 0.4131, df = 87.846, p-value = 0.6805
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4.827200 7.360533
sample estimates:
mean of x mean of y
164.6333 163.3667
var.test(x11, x31) #тест Фишера
F test to compare two variances
data: x11 and x31
F = 1.0874, num df = 44, denom df = 44, p-value = 0.7823
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.5975691 1.9787506
sample estimates:
ratio of variances
1.087401
t.test(x11, x21)
Welch Two Sample t-test
data: x11 and x21
t = 1.2514, df = 87.982, p-value = 0.2141
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.287121 10.064899
sample estimates:
mean of x mean of y
164.6333 160.7444
var.test(x11, x21)
F test to compare two variances
data: x11 and x21
F = 1.029, num df = 44, denom df = 44, p-value = 0.9249
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.5654797 1.8724919
sample estimates:
ratio of variances
1.029007
ks.test(x22, x32) # тест Колмогорова – Смирнова;
Two-sample Kolmogorov-Smirnov test
data: x22 and x32
D = 0.2051, p-value = 0.3847
alternative hypothesis: two-sided
wilcox.test(x22, x32) # тест Уїлкоксона
Wilcoxon rank sum test with continuity correction
data: x22 and x32
W = 930, p-value = 0.09094
alternative hypothesis: true location shift is not equal to 0
ansari.test(x22, x32) # тест Ансарі – Бредлі
Ansari-Bradley test
data: x22 and x32
AB = 765, p-value = 0.7643
alternative hypothesis: true ratio of scales is not equal to 1
|
Вибірка |
Критерії |
|||
|
Уелч |
Фішер |
|||
|
t |
p-value |
F |
p-value |
|
|
x11, x31 |
0.4131 |
0.6805 |
1.0874 |
0.7823 |
|
x11, x21 |
1.2514 |
0.2141 |
1.029 |
0.9249 |
|
Выборка |
Критерии |
|||||
|
x22, x32 |
Колмогорова-Смирнова |
Уїлкоксона |
Ансарі – Бредлі |
|||
|
D |
p-value |
W |
p-value |
AB |
p-value |
|
|
0.2051
|
0.3847
|
930
|
0.09094
|
765
|
0.7643
|
|
Из анализа этих данных можно сделать вывод про отсутствие считать, разным распределение показателей абитуриентов, зачисленных на направление «Технологии производства авиационных двигателей и энергетических установок». А вот для пары x22, x32 (не зачисленные физика и математика) есть значимая разница между распределением, которая определяется разницей центров распределения.