

Анализ данных и знаний / 7 лаба / 7
.docx = matrix(data = runif(1500, 0, 21), nrow = 250, ncol = 6)
a = c(2, -1, 1.5, 0.5, -0.2, -2.5)
eps = rnorm(250, 0, 0.3)
y = vector()
for (i in 1:250)
y[i] = sum(a*x[i,]) + eps[i]
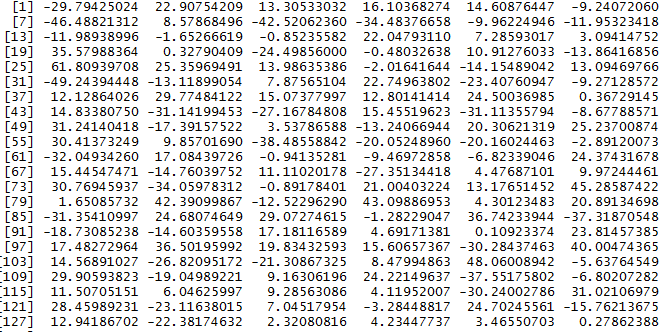
y
mod = lm(y~x)
summary(mod)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-0.75482 -0.20954 -0.00678 0.21588 0.74515
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.116823 0.082713 1.412 0.159
x1 1.995180 0.003023 659.940 <2e-16 ***
x2 -0.999395 0.003140 -318.258 <2e-16 ***
x3 1.499490 0.003030 494.925 <2e-16 ***
x4 0.496806 0.003140 158.206 <2e-16 ***
x5 -0.201876 0.003148 -64.122 <2e-16 ***
x6 -2.502414 0.003075 -813.799 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2927 on 243 degrees of freedom
Multiple R-squared: 0.9998, Adjusted R-squared: 0.9998
F-statistic: 2.482e+05 on 6 and 243 DF, p-value: < 2.2e-16
Бачимо, що вільний член моделі (Intercept – точка перетину з віссю ординат) не є статистично значущим, оскільки p-value для нього є більшим за обраний рівень значущості 0,05. Всі інші коефіцієнти моделі у нашому випадку є значущими і близькими к тим, що ми використовували при побудові вектора y. Коефіцієнт детермінації є близьким до одиниці, а p-value для F- статистики < 2,2·10-16. Це свідчить про адекватність побудованої моделі та значущість регресії.
Оскільки первинна модель містить статистично незначущі компоненти (вільний член) їх треба виключити з моделі і побудувати нову модель. Для побудови моделі без вільного члена можна використовувати команду lm(y~x + 0).
mod1 = lm(y~x+0)
summary(mod1)
Call:
lm(formula = y ~ x + 0)
Residuals:
Min 1Q Median 3Q Max
-0.72701 -0.20372 -0.00474 0.21401 0.73586
Coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 1.996932 0.002763 722.80 <2e-16 ***
x2 -0.997870 0.002955 -337.71 <2e-16 ***
x3 1.501068 0.002822 531.96 <2e-16 ***
x4 0.498439 0.002926 170.36 <2e-16 ***
x5 -0.199956 0.002845 -70.27 <2e-16 ***
x6 -2.500379 0.002722 -918.57 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2933 on 244 degrees of freedom
Multiple R-squared: 0.9998, Adjusted R-squared: 0.9998
F-statistic: 2.504e+05 on 6 and 244 DF, p-value: < 2.2e-16
Бачимо, що значення коефіцієнтів моделі та показники її адекватності практично не змінилися.
confint(mod, level=0.99)
0.5 % 99.5 %
x1 1.9897593 2.0041044
x2 -1.0055413 -0.9901992
x3 1.4937426 1.5083941
x4 0.4908431 0.5060343
x5 -0.2073432 -0.1925690
x6 -2.5074453 -2.4933117
Бачимо, що для вільного члена моделі нуль належить до 99% довірчого інтервалу. Це підтверджує його статистичну незначущість.
fitted(mod)
1 2 3 4 5 6
-29.95800161 22.58062350 13.24485822 15.44714217 14.96908081 -8.96644992
residuals(mod)
1 2 3 4 5 6
0.163751368 0.326918594 0.060472100 0.656540573 -0.360316338 -0.274270676
qqnorm(residuals(mod), col = 2, pch = 16, cex = 2)
qqline(residuals(mod), col = 3, lwd = 3, lty = 2)
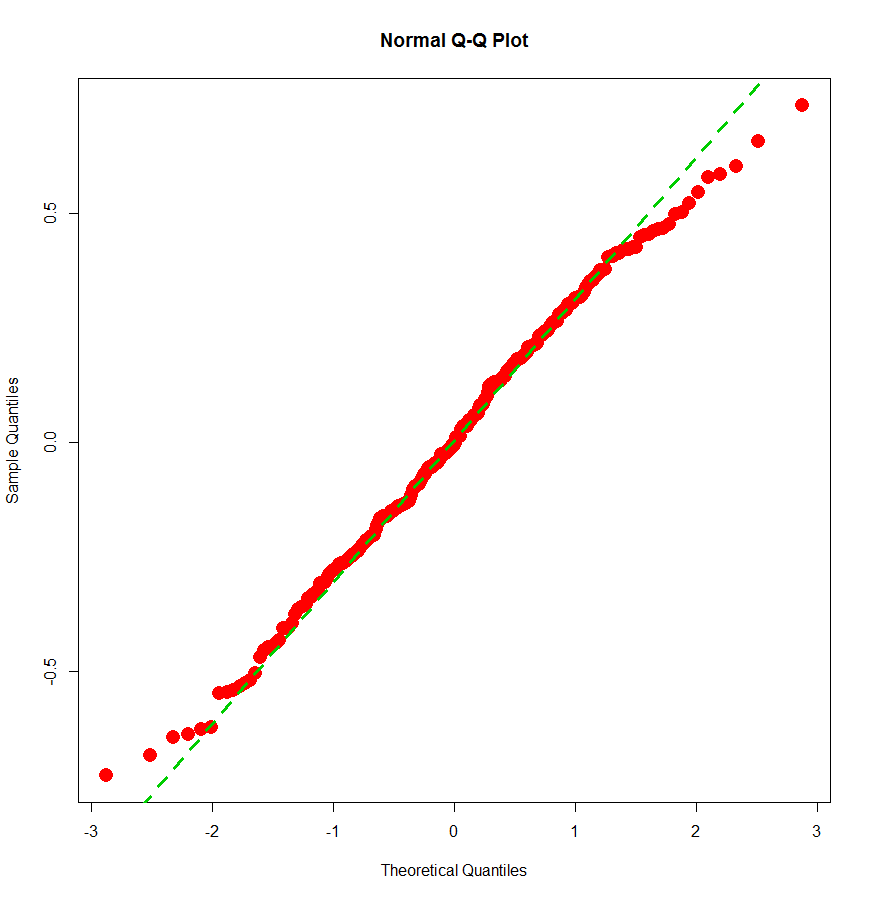
Діаграма свідчить про відсутність істотних відхилень від нормального розподілу.
shapiro.test(residuals(mod))
Shapiro-Wilk normality test
data: residuals(mod)
W = 0.994, p-value = 0.4255
Результати підтверджують відсутність значущих відхилень від нормального розподілу
t.test(residuals(mod))
One Sample t-test
data: residuals(mod)
t = 0.3188, df = 249, p-value = 0.7502
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.03030743 0.04201185
sample estimates:
mean of x
0.005852213
Результати підтверджують відсутність достатніх підстав вважати середнє арифметичне відмінним від нуля.
library("car")
durbinWatsonTest(lm(y~x), max.lag = 5)
lag Autocorrelation D-W Statistic p-value
1 -0.03726709 2.072946 0.588
2 -0.06466077 2.119852 0.286
3 -0.06670409 2.118012 0.244
4 -0.08871946 2.132930 0.238
5 -0.04819618 2.042986 0.548
Alternative hypothesis: rho[lag] != 0
Бачимо, що для перших п’яти лагів коефіцієнти автокореляції для ряду залишків є статистично незначущими. Це підтверджує їх випадковість.
Таким чином всі виконані перевірки підтверджують адекватність отриманої моделі регресії.
s1 = crossprod(x, x)
s2 = solve(s1)
s3 = crossprod(x, y)
alph = s2%*%s3
alph
[,1]
[1,] 1.9969318
[2,] -0.9978702
[3,] 1.5010683
[4,] 0.4984387
[5,] -0.1999561
[6,] -2.5003785
alph-coef(mod1)
[,1]
[1,] -3.330669e-15
[2,] -1.554312e-15
[3,] -6.661338e-15
[4,] -1.110223e-15
[5,] 5.689893e-15
[6,] 3.108624e-15
Отримані результати повністю збігаються з результатами застосування функції lm().