

1.2. Основы современных сетевых технологий.
1.2.1. Схема взаимодействия с Web-сервером Обобщенное описание. В настоящее время наиболее перспективной является архитектура "клиент-сервер", основанная на Web-технологии.
Обмен информацией по Web-технологии не отличается от информационного обмена, реализуемого по принципу "клиент-сервер", когда программа-сервер осуществляет обработку запросов, поступающих от программы-клиента.
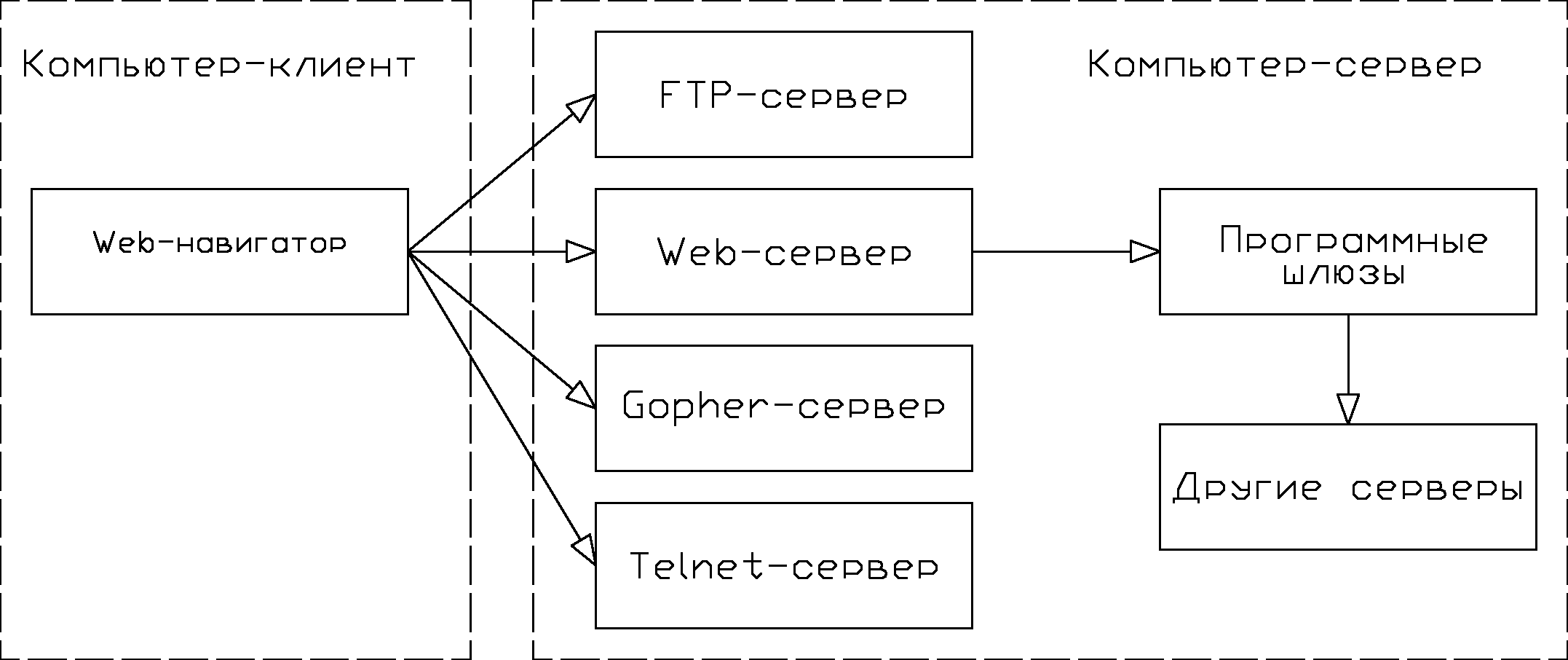
Рис. 1.9. Обобщенная схема взаимодействия Web-навигатора с сервером
В качестве программ-клиентов выступают программы Web-навигации, располагаемые на рабочих станциях сети, или служебные Web-приложения. Web-навигаторы используются для непосредственной визуализации и интерпретации Web-документов, хранящихся на сервере, а также для доступа к другим отдельным сервисам (рис. 1.9):
- сервису копирования файлов с сервера (FTP-сервису);
- сервису управления сервером (Telnet-сервису);
- сервису многоуровневых меню по доступу к компьютерным ресурсам (Gopher-сервису).
Доступ к другим отдельным сервисам возможен в связи с тем, что с самого начала программы навигации разрабатывались как мультипротокольные программы, обеспечивающие интерфейс доступа ко многим ресурсам сети.
К Web-навигаторам относятся такие известные продукты, как Netscape Navigator компании Netscape или Internet Explorer от Microsoft.
Служебные Web-приложения используются чаще всего для получения некоторых статистических данных о Web-сервере или индексирования содержащейся там информации с целью пополнения базы данных поисковых систем.
При использовании Web-технологии в качестве основной программы-сервера выступает Web-сервер, который запускается на компьютере-сервере и осуществляет обработку запросов, приходящих от Web-клиентов. Взаимодействие между Web-клиентом и Web-сервером осуществляется в соответствии с протоколом HTTP (HyperText Transfer Protocol — протокол передачи гипертекста). Будучи запущенным, Web-сервер контролирует логический порт, номер которого по умолчанию равен 80, и полагает, что любые сообщения, присланные к этому порту, предназначены для Web-сервера.
При получении запроса от Web-клиента Web-сервер устанавливает связь по протоколу TCP/IP и обменивается информацией в соответствии с протоколом HTTP. В случае запроса защищенной информации Web-сервер может потребовать от пользователя введения идентификатора и пароля. Защищенные Web-документы предоставляются только при наличии у пользователей соответствующих прав доступа.
Web-документы, получаемые навигатором от Web-сервера, представляют собой текстовые файлы, написанные на специальном языке, называемом языком HTML (HyperText Markup Language — гипертекстовый язык меток). Этот язык состоит из набора соглашений, в соответствии с которыми в текстовый файл помимо требуемого текста на любом языке мира вставляются метки, определяющие форматирование этого текста и его внешний вид в окне Web-навигатора, а также ссылки на любые объекты и отображаемые графические файлы. Кроме меток в Web-документ могут быть вставлены программы на языках JavaScript (Java Scripting) и VBScript (Visual Basic Scripting), интерпретируемые Web-навигатором при загрузке и просмотре Web-документа.
Для доступа к той информации, которая не может обрабатываться Web-сервером непосредственно, например для доступа к базам данных, используется система программных шлюзов. Программный шлюз, получив запрос от Web-сервера, обрабатывает его сам или выступает в качестве посредника между сервером Web и каким-либо другим сервером, например, сервером СУБД (рис. 1.9). Программные шлюзы разрабатываются в соответствии с определенными стандартами, определяющими способы вызова Web-сервером прикладных программ или функций динамических библиотек, а также способы обмена информацией с этими программными объектами. Одним из наиболее распространенных стандартов данного типа является интерфейс CGI (Common Gateway Interface — общий интерфейс шлюзов).
1.2.1.1. Обработка запроса от Web-клиента. Рассмотрим полную последовательность шагов, реализуемую Web-сервером при обработке запроса, поступившего от Web-клиента.
1. Web-навигатор или другой Web-клиент посылает Web-серверу запрос на получение от него какого-либо информационного ресурса. Запрос передается в формате HTTP, а адрес ресурса указывается в формате URL.
2. После получения запроса Web-сервер определяет наличие запрашиваемого ресурса среди локальных ресурсов, т. е. среди ресурсов, которыми данный сервер управляет.
3. Если запрашиваемый ресурс имеется в наличии, то Web-сервер проверяет права доступа к этому ресурсу и, если права не нарушены, то возвращает содержимое ресурса Web-клиенту.
4. Если запрос Web-клиента нарушает права доступа к ресурсу, то Web-сервер отклоняет запрос и возвращает соответствующее предупреждение клиенту.
5. В случае, если запрашиваемый ресурс не относится к локальным ресурсам Web-сервера, сервер определяет наличие в его файлах настройки информации о перемещении ресурса в сети. Если ресурс был размещен на сервере, но в данный момент перемещен в другое место, то сервер сообщает об этом клиенту (рис. 1.10).
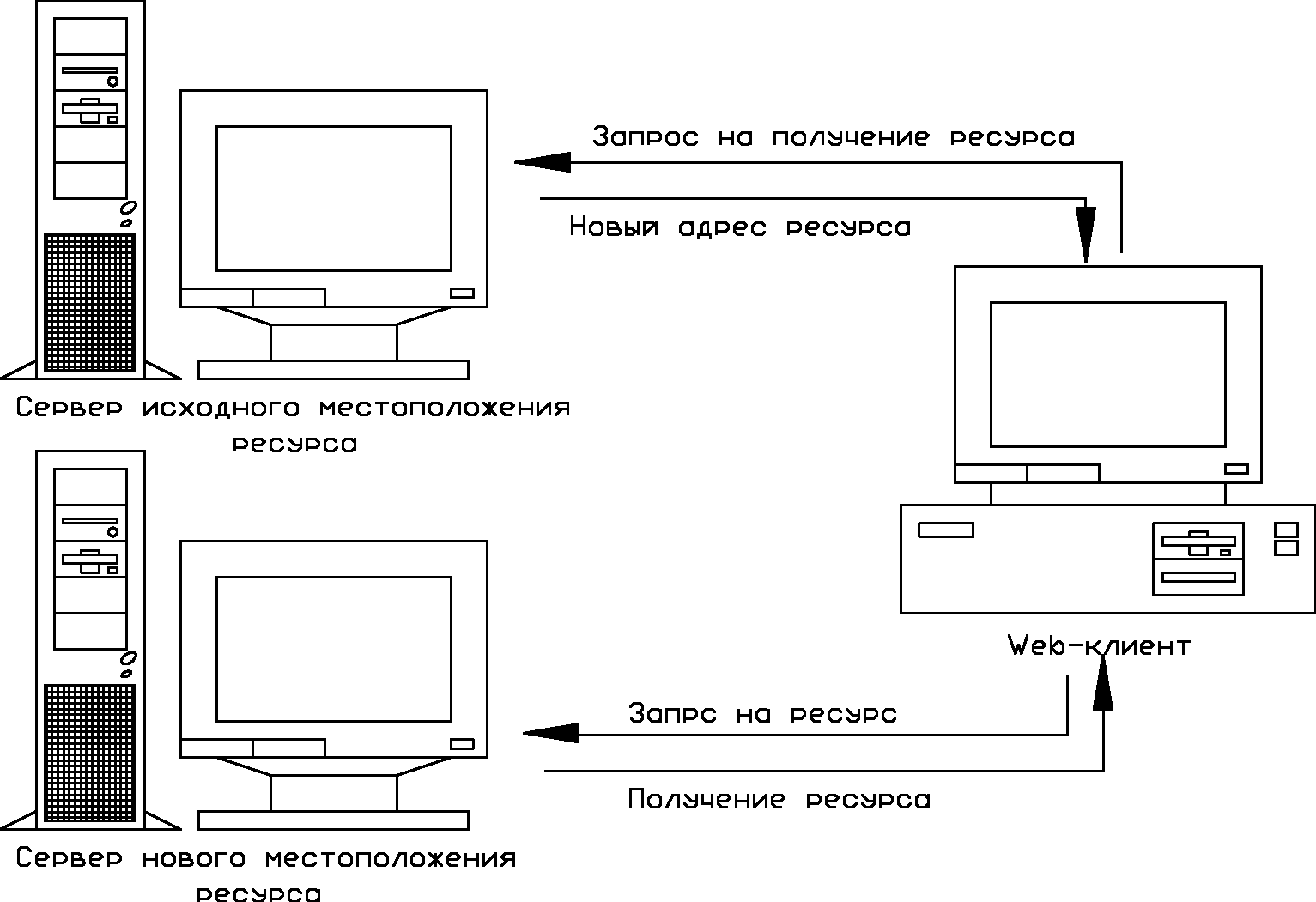
Рис. 1.10. Схема перенаправления запроса
6. Если Web-сервер поддерживает виртуальное дерево другого Web-сервера, то запрос будет перенаправлен на нужный ресурс по аналогии с предыдущим шагом (рис. 1.10).
7. Если Web-сервер используется в качестве сервера-посредника (proxy-сервера), то он выступает, с одной стороны, в качестве Web-сервера для клиента, пославшего запрос, а с другой стороны — в качестве Web-клиента, который посылает запрос к другому Web-серверу (рис. 1.11).
8. После возвращения информации клиенту сервер разрывает соединение с ним.

Рис. 1.11. Использование Web-сервера в качестве сервера-посредника
Web-сервер может использоваться для решения широкого круга задач. Наиболее типичными для современных серверов являются следующие функции:
- ведение иерархической базы данных документов, обработка запросов и контроль за доступом к информации со стороны программ-клиентов;
- предварительная обработка данных перед ответом на запрос;
- взаимодействие с внешними программами и другими серверами, например, с информационно-поисковыми системами.
Большинство современных Web-серверов, таких как Enterprise Server от корпорации Netscape и Internet Information Server от Microsoft, реализуют криптографический протокол SSL (Secure Sockets Layer), обеспечивающий поддержание конфиденциальности, целостности и подлинности передаваемых по сети данных. Этот протокол реализован и в современных Web-навигаторах — Netscape Navigator и Internet Explorer. Данная особенность позволяет безопасно использовать Web-технологию в компьютерных сетях.
1.2.2. Распределенная обработка информации на основе мигрирующих программ. Одной из главных особенностей intranet-архитектуры является распределенная обработка информации на основе мигрирующих программ. Программа навигации, выполняемая на рабочей станции, может не только визуализировать Web-старницы и выполнять переходы к другим ресурсам, но и активизировать программы на сервере, а также интерпретировать и запускать на выполнение программы, относящиеся к Web-документу, которые передаются вместе с этим документом с сервера. Такой вид распределенной обработки информации позволяет сконцентрировать всю прикладную систему непосредственно на сервере.
Существует три основных вида программ, которые могут быть связаны с Web-документом и передаваться на рабочую станцию для выполнения:
- Java-аплеты, подготовленные и используемые по технологии Java;
- программы, написанные на языке сценариев JavaScript, VBScript (Visual Basic Scripting) или VRML;
- программные компоненты ActiveX Controls, соответствующие технологии ActiveX.
Наличие нескольких разновидностей мигрирующих программ объясняется их различными возможностями, а также конкуренцией между ведущими корпорациями в области программных и сетевых технологий — корпорациями Sun Microsystems, Netscape, Microsoft и другими.
1.2.2.1. Java-технология. Технология Java была разработана компанией Sun Microsystems в начале 90-х годов в связи с возникновением острой необходимости в компьютерных программах, ориентированных на использование в сетевой среде и интеграцию с Web-сервисом. К таким программам изначально были предъявлены требования по мобильности, предполагающие независимость от аппаратных и операционных платформ, а также безопасность и надежность обработки информации.
В результате были разработаны язык программирования Java, а также целостная технология создания и использования мобильных программ, получившая название Java-технологии.
Язык Java является простым объектно-ориентированным языком программирования, построенным на основе языка C++, из которого убрали все лишнее и добавили новые возможности для обеспечения безопасности и надежности распределенных вычислений. Много полезных идей было заимствовано из языков Objective С и SmallTalk.
Для снижения сложности программирования и количества допускаемых ошибок в язык Java были внесены жесткая объектная ориентация описаний и строгая типизация данных. В этом языке нет данных, не входящих в объекты, и нет функций, не являющихся методами какого-либо объекта. Строгая типизация информационных элементов позволяет на стадии компиляции выявлять ошибки, связанные с несовместимостью типов данных.
Реализованный в языке модульный принцип построения программ и простота языка дают возможность не только быстро разрабатывать новые программы, но и применять элементы уже написанных и проверенных программ, а также эффективно модернизировать старые. Кроме того, в стандарт языка входит множество полезных библиотек, на основе которых можно строить вычислительные системы любой сложности. Этот стандартный набор постоянно пополняется новыми важными функциями.
Независимость от аппаратно-операционных платформ, а также безопасность и надежность обработки информации были достигнуты разработкой виртуального Java-процессора, предназначенного для выполнения Java-программ путем их интерпретации. Определены его архитектура, представление элементов данных и система команд.
Виртуальный Java-процессор обеспечивает среду для исполнения Java-программ. При этом любая Java-программа должна соответствовать спецификации этого абстрактного процессора, которая полностью определяет его машинно-независимую систему команд, типы обрабатываемых данных, а также регистры. Поэтому для возможности исполнения Java-программы виртуальным Java-процессором ее исходные тексты должны быть оттранслированы в высокоуровневые машинно-независимые коды этого абстрактного процессора, называемые байт-кодами.
Оттранслированные Java-программы, предназначенные для выполнения на рабочей станции в среде Web-навигатора, называют Java-аплетами или просто аплетами. По своей структуре каждый аплет представляет собой небольшую программку, в которой должно быть определено несколько обязательных функций. Аплет загружается по сети с сервера и выполняется в среде Web-навигатора (рис. 1.12). Ссылки на аплеты располагаются в Web-документах, но непосредственно в состав Web-документов аплеты не входят. Они хранятся в отдельных файлах на сервере.
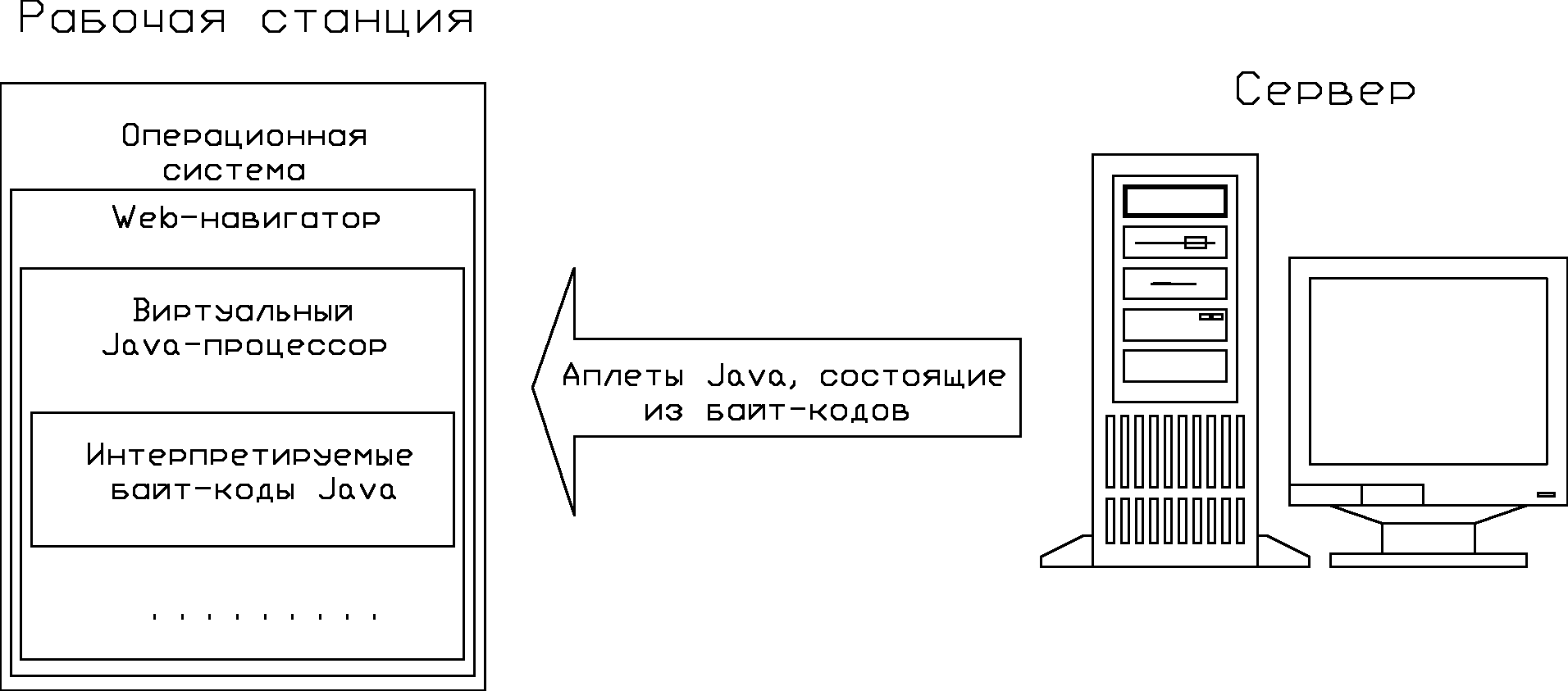
Рис. 1.12. Схема передачи и выполнения машинно-независимых
Java-программ
Независимость байт-кодов Java от аппаратно-операционных платформ достигается программной реализацией для каждой из этих платформ только виртуального Java-процессора, который и предназначен для интерпретации аплетов.
Байт-коды Java-программ обладают следующими особенностями:
- они могут не только легко интерпретироваться, но и эффективно компилироваться "на лету" непосредственно в машинные коды для любой современной аппаратной платформы;
- средняя длина команды в байт-кодах сокращена до минимума, что снизило сложность и объем Java-аплетов по сравнению с обычными исполняемыми программами;
- байт-коды каждой программы содержат избыточную информацию, которая позволяет проверить их на безопасность выполнения.
Под компиляцией "на лету" или, как ее еще называют, динамической компиляцией понимается компиляция аплетов в машинные коды рабочей станции, выполняемая сразу же после получения аплетов на этой рабочей станции с целью их выполнения как обычных исполняемых программ. Вместо виртуального процессора при динамической компиляции предполагается использование специализированного компилятора. Динамическая компиляция байт-кодов и их дальнейшее выполнение повышает быстродействие Java-аплетов, которое при их интерпретации ниже скорости выполнения обычных исполняемых программ. Однако без принятия дополнительных мер при использовании динамической компиляции может быть снижена безопасность обработки информации. Поэтому динамическая компиляция Java-аплетов в Web-навигаторах пока не используется.
Байт-коды разрабатывались так, чтобы максимально сократить среднюю длину команды. Java-процессор имеет минимум регистров, стековую архитектуру и часто использует косвенную адресацию. Поэтому большинство из команд занимает всего один байт, к которому добавляется при необходимости номер операнда. Кроме того, для обработки каждого типа данных Java-процессор имеет свой набор команд. В результате средняя длина Java-команды составляет всего 1,8 байта. Средняя длина команды для классических RISC-процессоров равна примерно 4 байтам.
Для высокой надежности и безопасности выполнения Java-аплетов предусмотрены две важные функции:
- проверка байт-кодов перед их выполнением на целостность и правильность инструкций;
- контроль и блокирование опасных действий в процессе интерпретации байт-кодов.
Первую функцию реализует загрузчик и верификатор байт-кодов, а вторую - диспетчер безопасности виртуального Java-процессора. Диспетчер безопасности запрещает аплетам осуществлять доступ к файлам и периферийным устройствам, а также выполнять системные функции, такие как распределение памяти.
Виртуальный Java-процессор обеспечивает выполнение и других функций, влияющих на надежность обработки информации, например, "сбор мусора", т. е. освобождение неиспользуемой оперативной памяти. Кроме того, язык Java содержит необходимые средства для корректной работы со всеми объектами и ресурсами в случае возникновения исключительных ситуаций.
Технологический цикл подготовки Java-аплетов тот же, что и для программ на других языках программирования. Отличием является лишь то, что при редактировании внешних связей требуемые компоненты могут доставляться по сети. Процесс выполнения аплетов существенно отличается от аналогичного процесса для обычных программ (рис. 1.13).
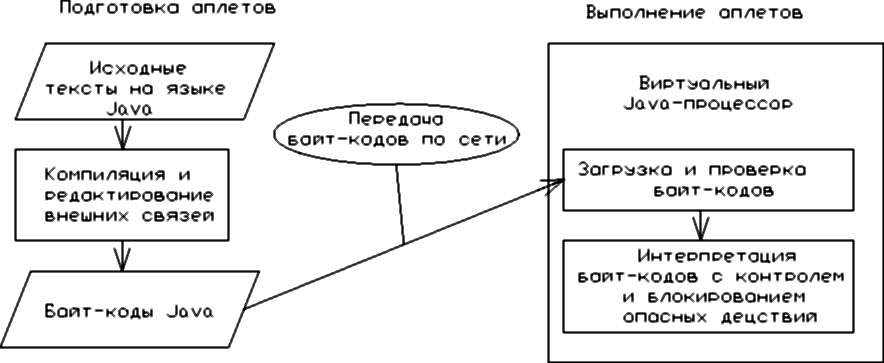
Рис. 1.13. Схема подготовки и выполнения Java-аплетов
Поскольку аплеты и другие части прикладной системы хранятся на сервере, то за счет централизации облегчается сопровождение и администрирование системы. Это в свою очередь гарантирует, что пользователь всегда будет использовать самые последние версии программ.
Следует отметить, что на языке Java могут создаваться не только аплеты, являющиеся мигрирующими программами, но и стационарные программные приложения. Однако для высокого быстродействия исходный текст таких программ следует компилировать не в байт-коды, а в машинно-зависимые коды, обеспечивающие высокую скорость исполнения.
В настоящее время существует достаточное количество инструментальных средств для разработки как Java-аплетов, так и Java-приложений. Среди них - Microsoft Visual J++, Symantec Cafe, Borland Jbuilder, Sun Microsystems Java Workshop и ряд других.
1.2.2.2. Технологии, основанные на использовании языков сценариев. Параллельно с мощной Java-технологией появились технологии создания и применения мигрирующих программ, основанные на использовании языков сценариев. Наиболее важным отличием таких технологий от Java-технологии является покомандная интерпретация исходных текстов программ, исключающая необходимость их компиляции перед выполнением. Вспомним, что в Java-технологии мобильная Java-программа для возможности выполнения должна быть откомпилирована в байт-коды. Функция интерпретации мобильных программ, написанных на языке сценариев, возложена на Web-навигатор.
Языки сценариев часто называют еще языками скриптов (script — сценарий) или макроязыками. Их интерпретируемая природа упрощает отладку и создание составленных на них программ. К основным представителям языков сценариев, предназначенных для написания мигрирующих программ, относятся:
- язык JavaScript, разработанный совместно компаниями Netscape и Sun Microsystems, а также подобный ему язык VBScript (Visual Basic Scripting) от Microsoft;
- язык VRML (Virtual Reality Modeling Language — язык моделирования виртуальной реальности), разработанный компанией Silicon Graphics.
Язык сценариев JavaScript впервые появился в Web-навигаторе Netscape Navigator 2.0 под названием LiveScript. Впоследствии Netscape отказалась от такого названия, начав работать вместе с Sun Microsystems и попав под влияние Java. JavaScript вовсе не представляет собой производную от Java. Хотя эти языки имеют некоторые общие атрибуты, но их можно назвать не более чем дальними родственниками.
JavaScript является упрощенным интерпретируемым языком с базовыми объектно-ориентированными функциями. Свойство простоты объясняется отсутствием жесткой архитектуры типов и семантики. Объектно-ориентированная ориентация проявляется в возможностях работы с окнами, строкой состояния и другими элементами интерфейса Web-навигатора и сетевого окружения как с объектами в иерархии, к которым можно обращаться по имени.
JavaScript беднее языка Java, но гораздо удобнее и эффективнее для ряда задач, связанных с обработкой Web-документов и взаимодействием с пользователем при его просмотре. Он имеет большое число встроенных функций и команд. Программы, написанные с помощью JavaScript, могут выводить на экран диалоговые окна, производить математические вычисления, проигрывать различные аудио- и видеофайлы, получать новые документы, обрабатывать нажатие на кнопки в формах и многое другое. С помощью JavaScript можно также устанавливать атрибуты и свойства бинарных библиотек Java, a также программных модулей (plug-ins), подключенных к Web-навигатору.
Команды JavaScript встраиваются непосредственно в Web-страницу и выполняются Web-навигатором во время загрузки этой страницы или во время определенных действий, производимых пользователем при работе с ней, например, при щелчке мышью на одном из объектов страницы, при позиционировании указателя в место расположения ссылки или при вводе информации в поля HTML-формы.
Как и для любой другой технологии или языка, используемых в компьютерной сети, обеспечение безопасности обработки информации является первоочередной задачей. JavaScript, хотя его и нельзя назвать языком с самым высоким уровнем защиты, тем не менее, адекватен большинству требований. В нем не реализованы некоторые возможности, поскольку они косвенно делают защиту более уязвимой. Программе на JaveScript, как и программе на языке Java, запрещено выполнять операции с локальными файлами. Поэтому программа не в состоянии изменять или получать доступ к пользовательским данным. Кроме того, язык JavaScript не поддерживает сетевые функции. Он не может, например, напрямую открыть порт TCP/IP, а способен только обеспечить загрузку объекта по заданному адресу и формирование данных, передаваемых Web-серверам. Современные Web-навигаторы позволяют устанавливать уровни безопасности и управлять ими так, что программа на JavaScript может обратиться только к ограниченному кругу информации.
Быстрота создания программ, небольшие размеры программных модулей, удобный доступ ко всем внутренним функциям Web-навигатора, а также безопасность JavaScript-технологии привели к высокой популярности языка JavaScript, не уступающей популярности языка Java.
К недостаткам технологии JavaScript следует отнести невысокое быстродействие JavaScript-программ, являющееся неотъемлемым атрибутом всех интерпретируемых языков программирования.
Нужно отметить, что реализации языка JavaScript компаний Netscape и Microsoft различаются. Эти несоответствия могут привести к несовместимости при использовании Web-навигаторов Netscape Navigator и Internet Explorer. Поэтому при создании приложений на JavaScript необходима проверка их работоспособности в среде различных программ навигации.
Язык сценариев VBScript (Visual Basic Scripting) от Microsoft во многом подобен JavaScript. Он является подмножеством языка Visual Basic и также предназначен для программирования страниц Web. С его помощью можно заставить взаимодействовать разные объекты на Web-странице, включая программные компоненты другого типа, например, аплеты Java и программные компоненты ActiveX Controls.
В отличие от макроязыков JavaScript и VBScript язык VRML разработан корпорацией Silicon Graphics специально для создания интерпретируемых программ, моделирующих трехмерные виртуальные миры. Интерпретаторы VRML подключаются к Web-навигаторам чаще всего в виде отдельных программных модулей (plug-ins). Исходные тексты программ на языке VRML оформляются в виде отдельного VRML-файла и вызываются по ссылке с Web-документа при его просмотре Web-навигатором. Щелчок мышью по такой ссылке приводит к открытию отдельного окна, позволяющего пройтись по расположенному в нем фрагменту трехмерной реальности.
1.2.2.3. Технологии ActiveX. Под ActiveX понимается набор технологий от Microsoft, направленных на дополнение, интеграцию и унификацию существующих методов представления и обработки информации в компьютерных сетях, построенных по Web-архитектуре. Основная идея ActiveX-технологий заключается в использовании одинакового способа доступа ко всем информационным ресурсам сети (рис. 1.14). В качестве основы такого унифицированного способа доступа выбрана Web-технология.
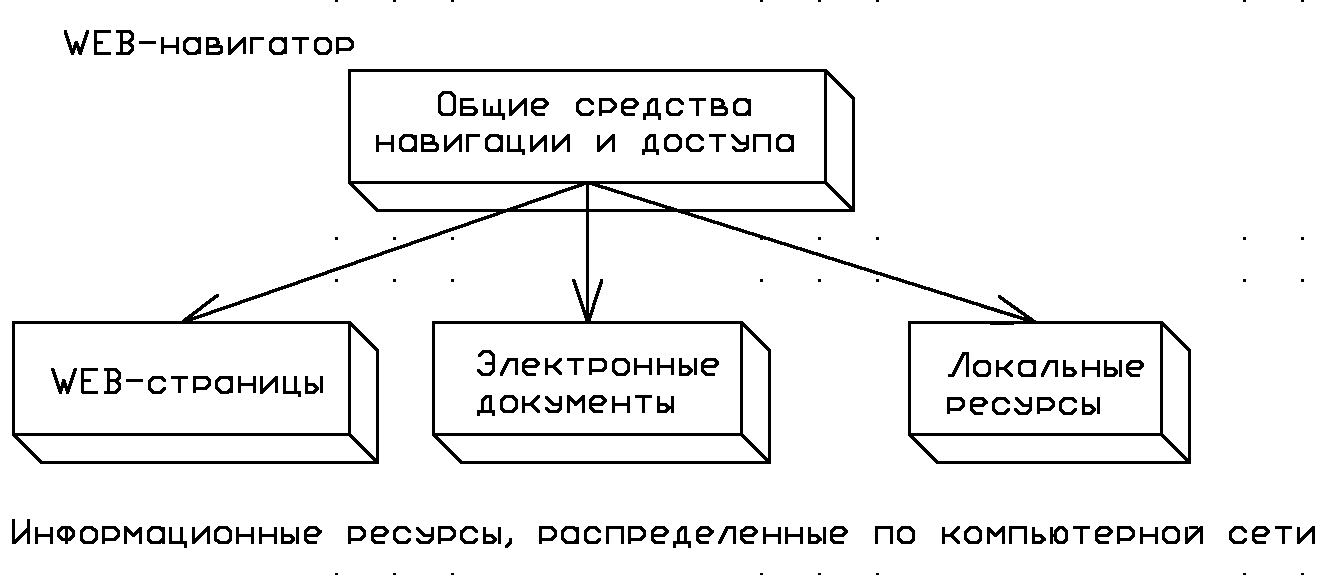
Рис. 1.14. Схема единообразного доступа к информационным ресурсам сети
В соответствии с ActiveX Web-навигатор должен стать частью операционной системы. Более того, методы доступа к любой информации на собственном компьютере, на сервере локальной сети или в Internet должны быть совершенно одинаковы и прозрачны для пользователя. Данная концепция частично уже реализована в Web-навигаторе Microsoft Internet Explorer 4.0.
С точки зрения разработки мобильных программ набор технологий ActiveX с одной стороны выступает как альтернатива, а с другой — как существенное дополнение технологий Java и JavaScript. ActiveX обеспечивает не только разработку и выполнение мобильных программ, но и реализацию ряда дополнительных возможностей, например, вызов из среды Web-навигатора функций по просмотру и редактированию документов Word, Excel и PowerPoint. В распоряжение программистов и авторов Web-документов ActiveX предоставляет набор функций API (Application Program Interface), реализованный как для клиента, так и для сервера.
ActiveX поддерживает следующие типы мобильных программ, которые могут быть связаны с Web-документом и передаваться на рабочую станцию для выполнения (рис. 1.15):
- программные компоненты ActiveX Controls;
- аплеты Java;
- программы, написанные на языках сценариев JavaScript, VBScript (Visual Basic Scripting) и VRML.
Технологии по созданию и использованию программных компонентов ActiveX Controls, а также программ, написанных на макроязыке VBScript, являются собственными разработками Microsoft.
Рис. 1.15. Миграция программ в технологии ActiveX
На сервере для действенности технологий ActiveX должны функционировать общесистемные программные средства от Microsoft: операционная система Windows NT Server и Web-сервер US (Internet Information Server). Взаимодействие Web-сервера US с другими приложениями, например с системой управления базами данных (СУБД), обеспечивается за счет реализованных в нем интерфейсов ISAPI (Internet Server API) и CGI (Common Gateway Interface).
Программные компоненты ActiveX Controls представляют собой обычные исполняемые программы, которые могут загружаться с сервера для исполнения на рабочей станции. Как и при использовании Java-аплетов ссылки на эти программы располагаются в Web-документах. Непосредственно в состав Web-документов программные компоненты ActiveX Controls не входят. Они хранятся в отдельных файлах на сервере.
Компоненты ActiveX Controls отличаются от Java-аплетов следующими особенностями:
- программы ActiveX Controls включают исполняемый код, зависящий от аппаратно-операционной платформы: байт-коды же Java-аплетов являются машинно-независимыми;
- загруженные элементы ActiveX Controls остаются в клиентской системе, тогда как аплеты Java необходимо каждый раз загружать заново;
- поскольку программы ActiveX Controls не работают подобно Java-аплетам под контролем диспетчера безопасности, они могут получать доступ к дискам и выполнять другие функции, характерные для традиционных приложений.
Учитывая, что программы ActiveX Controls по сути являются обычными программными приложениями, то их разработка может осуществляться с помощью любого языка программирования. Могут быть использованы такие инструментальные системы, как Visual C++, Visual Basic, Delphi, Visual J++ и ряд других. Разработан и комплексный инструментальный пакет Microsoft ActiveX Development Kit (MADK).
Программные компоненты ActiveX Controls, а также программы, написанные на макроязыках JavaScript и VBScript, могут включать вызовы функций API ActiveX по предоставлению ряда сервисов, таких как:
- создание высококачественных мультимедийных эффектов;
- открытие и редактирование электронных документов путем обращения к приложениям, поддерживающим стандарт OLE (Object Linking and Embedding — связывание и встраивание объектов), например, к приложениям Microsoft Office;
- обращения к операционной системе для оптимальной настройки параметров выполнения полученных с сервера программ.
Программы, написанные на макроязыках JavaScript и VBScript, могут автоматизировать взаимодействие между множеством объектов, включая аплеты Java, программные компоненты ActiveX Controls и другие программы на клиентском компьютере, позволяя им работать вместе как часть интегрированного активного пространства Web. Можно написать свой макроязык и добавить его интерпретатор в Web-навигатор Internet Explorer с помощью динамически загружаемой библиотеки DLL.
В сравнении с технологией Java технология ActiveX Controls имеет как недостатки, так и преимущества.
Недостатки связаны прежде всего с более низким уровнем безопасности распределенной обработки информации. Программные компоненты ActiveX Controls, загруженные на клиентскую систему, могут обращаться к любой ее части подобно обычному приложению. Microsoft реализовала в рамках ActiveX доверительную защиту на основе цифровых сертификатов, которые обеспечивают подтверждение подлинности загруженных с сети программных компонентов. Однако подтверждение подлинности еще не означает подтверждение безопасности. Кроме того, схема доверительной защиты ActiveX может оказаться недейственной, когда пользователи загружают программные компоненты ActiveX Controls из Internet, особенно из неизвестных или сомнительных источников.
Вместе с тем программные компоненты ActiveX Controls, в отличие от Java-аплетов, позволяют реализовать функции, свойственные полномасштабным программным приложениям. Эта особенность для корпоративной сети является существенным преимуществом при условии принятия соответствующих мер безопасности, например, при разрешении загрузки программ ActiveX Controls только с серверов корпорации.
Что же касается производительности, то поскольку Java является интерпретируемым языком, аплеты Java выполняются на виртуальной машине клиентской системы с меньшей скоростью, чем скомпилированные элементы ActiveX Controls. Но с другой стороны, аплеты Java очень компактны, поэтому загружаются быстро. Для загрузки же программ ActiveX Controls требуется большее время. Следует также учесть, что загруженные программы ActiveX Controls остаются в клиентской системе, тогда как все аплеты Java необходимо каждый раз загружать заново. Эта особенность с точки зрения безопасности является недостатком, так как нарушается централизация прикладной системы. Но с точки зрения производительности достигается преимущество перед Java-аплетами.
По независимости от аппаратных и операционных платформ ActiveX уступает Java-технологии. Несмотря на заявление компании Microsoft, что ActiveX обеспечивает открытую многоплатформенную поддержку операционных систем Macintosh, Windows и UNIX, технологии ActiveX лучше работают на платформах Microsoft Windows, поскольку разработаны преимущественно для использования функций, встроенных в эти операционные системы. Соответственно в полной мере ActiveX может использоваться в сетях, работающих под управлением операционных систем Microsoft Windows.
1.2.3. Доступ к реляционным базам данных. В архитектуре "клиент-сервер", основанной на Web-технологии, Web-сервер выступает в качестве информационного концентратора, который доставляет информацию из разных источников, а потом однородным образом с помощью Web-навигатора предоставляет ее пользователю. Непосредственная интеграция разнородной информации выполняется при визуализации и интерпретации Web-документов, которую реализует Web-навигатор при взаимодействии с Web-сервером, а также другими серверами по предоставлению информационных ресурсов.
Взаимодействие Web-навигатора с сервером системы управления базами данных (сервером СУБД) может осуществляться двумя основными способами:
- доступ к серверу СУБД через Web-сервер;
- доступ к серверу СУБД напрямую.
Доступ к серверу СУБД через Web-сервер
Для доступа Web-навигатора к серверу СУБД через Web-сервер используется система программных шлюзов (см. рис. 1.9). Программный шлюз, получив запрос от Web-сервера, выступает в качестве посредника между сервером Web и сервером СУБД. Программные шлюзы разрабатываются в соответствии с определенными стандартами, определяющими способы вызова Web-сервером прикладных программ или функций динамических библиотек, а также способы обмена информацией с этими программными объектами. Одними из наиболее распространенных стандартов данного типа являются интерфейс CGI (Common Gateway Interface — общий интерфейс шлюзов), а также его усовершенствованная спецификация, названная как FastCGI (ускоренный CGI).

Рис. 1.16. Схема доступа к СУБД через CGI-программу
1.2.3.1. Интерфейс CGI. Для доступа Web-навигатора к серверу СУБД через Web-сервер по стандарту CGI необходима соответствующая CGI-программа, выполняющая роль программного шлюза между Web-сервером и сервером СУБД (рис. 1.16).
CGI-приложения работают независимо от Web-сервера, а их запуск осуществляется по вызову с Web-документа при его обработке Web-навигатором. CGI-программа взаимодействует с Web-сервером посредством двустороннего обмена переменными среды через стандартные каналы ввода/вывода данного приложения.
Поскольку CGI-программы работают независимо от Web-сервера и имеют простой общий интерфейс, разработчики Web-документов имеют возможность создавать свои CGI-программы на любом языке, поддерживающем стандартные файловые операции ввода/вывода. Кроме того, при независимой разработке можно создавать такие приложения, которые легко переносятся с одного на другой Web-сервер. Существуют и стандартные CGI-программы, специально разработанные для взаимодействия Web-серверов с различными СУБД, например, программа WebDBC.
В качестве интерфейса между Web-навигатором и сервером СУБД в составе Web-документов применяют HTML-формы, которые позволяют формулировать запросы к базе данных. CGI-программа получает информацию от Web-сервера либо через переменные окружения, либо через стандартный ввод. Все зависит от метода доступа, который используется при обмене данными между Web-навигатором и Web-сервером. Далее CGI-программа через драйвер ODBC (Open DataBase Connectivity) обращается к серверу СУБД и возвращает Web-серверу ответ на запрос через стандартный вывод.
Драйвер ODBC обеспечивает унифицированный способ доступа к различным СУБД посредством стандартного языка запросов SQL. Благодаря стандарту ODBC прикладные программы могут использовать единственный диалект SQL и взаимодействовать с разными СУБД. Можно обойтись и без драйвера ODBC, но в этом случае CGI-программа должна быть написана с ориентацией на конкретную СУБД, функционирующую на сервере.
Таким образом, разработчику CGI-приложения не надо ничего знать о том, как устроен Web-сервер. Более того, ему вовсе не обязательно использовать сложные языки типа C++. CGI-программа может быть написана и на командном языке, например Peri. Главное выдержать все соглашения, накладываемые стандартом CGI. Такой подход существенно облегчает разработку прикладного программного обеспечения для Web вообще и для сопряжения баз данных с Web-сервером в частности.
Стандарт CGI обладает и недостатком — снижение скорости обработки запросов при увеличении интенсивности их поступления. При каждом вызове CGI-программы ее приходится загружать с диска (т. е. запускать новый процесс). По завершении работы программы требуется освободить использовавшиеся ею ресурсы. Такие операции создают заметную дополнительную нагрузку на сервер, что сказывается на его производительности. К тому же запуск нового процесса при каждом запросе снижает эффективность постоянных процессов и доступность данных. Информацию, которая сгенерирована в ходе обработки одного запроса, невозможно использовать при обработке другого.
1.2.3.2. Интерфейсы API и FastCGI. Для того чтобы обойти проблемы, связанные с быстродействием CGI, многие поставщики Web-серверов, включая Microsoft и Netscape, разработали соответствующие интерфейсы прикладного программирования (API). Корпорацией Microsoft был разработан интерфейс ISAPI (Internet Server API), a корпорацией Netscape — интерфейс NSAPI (Netscape Server API).
Эти интерфейсы тесно интегрированы с Web-сервером, позволяя сохранять доступность постоянно используемых процессов и данных. Программы с интерфейсом ISAPI компилируются в файлы динамически подключаемых библиотек DLL. Они загружаются в память во время первого обращения к ним и поэтому для повторного вызова этих программ не нужно порождать новый процесс. Функции интерфейса NSAPI загружаются в серверное пространство процессов. Соответственно при вызове этих функций также не порождаются дополнительные процессы. Благодаря API-интерфейсу использующая его программа может оставлять соединение с СУБД открытым, так что следующему запросу к базе данных не придется тратить время на открытие и закрытие соединения.
Однако API-интерфейсы Web-серверов — хоть и неплохое, но нестандартное решение. Большинство приложений нельзя переносить с одного API на другой, и очень редко удается переносить приложения на другие платформы. Кроме того, большинство приложений для Web-серверов все еще создаются для интерфейса CGI, поэтому переход к приложениям на базе API не представляется экономически оправданным.
Поэтому стали появляться способы построения некоторого промежуточного варианта, который, с одной стороны, удовлетворял бы требованиям мобильности, независимости и простоты программирования, а с другой стороны — был бы достаточно эффективным. Одним из таких решений является спецификация FastCGI. Идея этой спецификации в том, что прикладная программа использует способ передачи параметров и данных, который применяется в CGI, но при этом не удаляется из памяти, а остается резидентной, обрабатывая поступающие запросы.
Таким образом, приложения на базе FastCGI, подобно CGI-программам, работают независимо от Web-сервера и запускаются через стандартные ссылки в Web-документах. Но, как и программы на базе API, программы для FastCGI являются постоянно действующими. Когда программа заканчивает обработку очередного запроса, ее процесс остается открытым в ожидании нового запроса.
При доступе Web-навигатора к реляционной базе данных через интерфейс FastCGI получается схема, в которой фактически используются три сервера:
Web-сервер, FastCGI-программа и сервер базы данных. Web-сервер принимает запрос Web-навигатора и передает его FastCGI-программе, которая в свою очередь обращается к серверу баз данных. Результат возвращается по обратной цепочке.
1.2.3.3. Доступ к серверу СУБД напрямую. Для доступа Web-навигатора к серверу СУБД напрямую могут использоваться как Java-аплеты (рис. 1.17) и программные компоненты ActiveX Controls (рис. 1.18), так и подключаемые к навигатору специализированные программные модули (plug-ins).
Для использования Java-аплетов по доступу к различным серверам СУБД разработан стандартный интерфейс JDBC (Java DataBase Connectivity) (рис. 1.17). Данный интерфейс ориентирован на обеспечение взаимодействия с сервером СУБД не только Java-аплетов, выполняющихся на клиентских станциях, но и Java-программ, запускаемых на сервере.
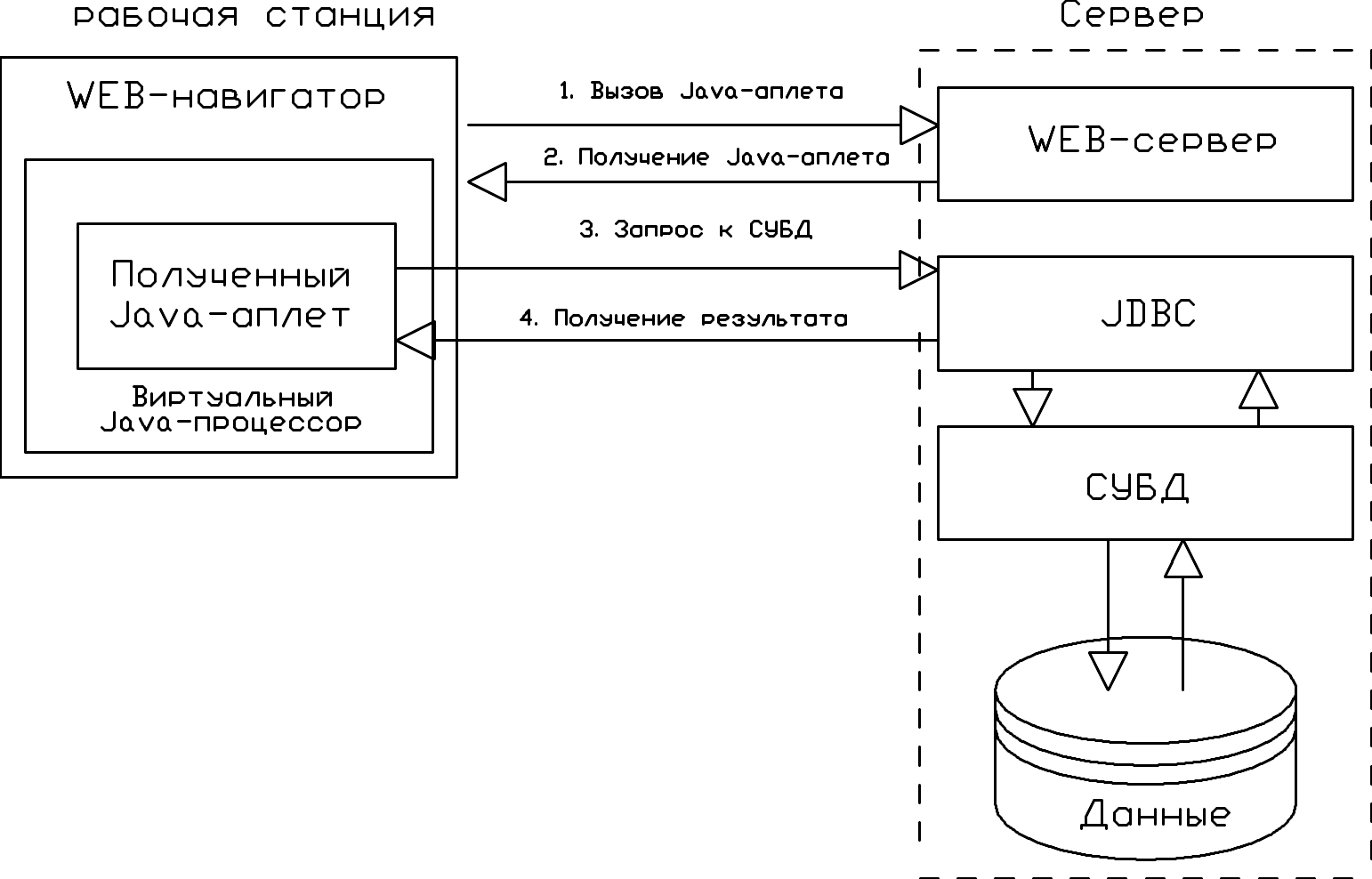
Рис. 1.17. Схема доступа к СУБД с помощью Java-аплета
Доступ Web-навигатора к серверу СУБД с помощью программных компонентов ActiveX Controls (рис. 1.18) предполагает, как и в случае Java-аплетов, запрос и передачу соответствующей программы на рабочую станцию, а также ее дальнейшее выполнение на рабочей станции. В этом случае взаимодействие с сервером СУБД должно выполняться через интерфейс ODBC. Если учесть, что Java исполняется Web-навигатором в режиме интерпретации мобильного кода, то требования к аппаратуре рабочей станции по производительности и объему оперативной памяти существенно возрастают.
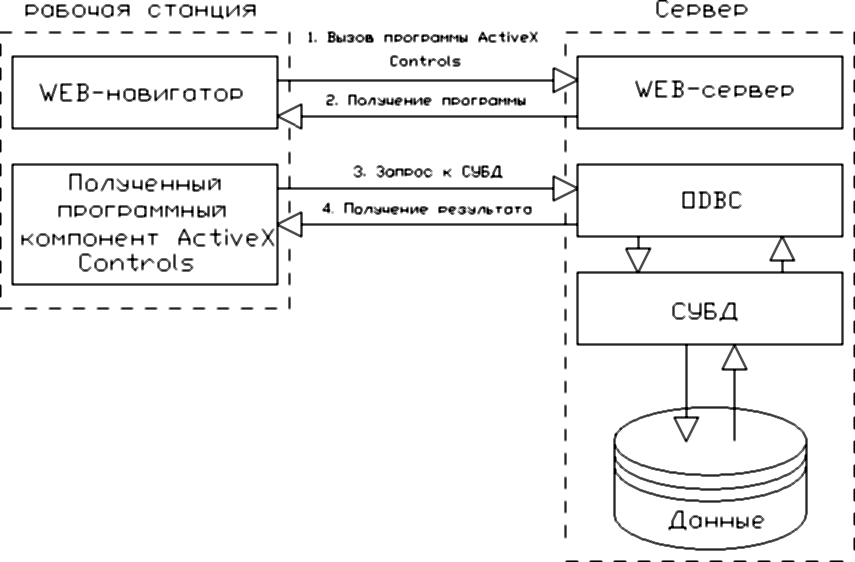
Рис. 1.18. Схема доступа к СУБД с помощью программного компонента ActiveX Controls
Использование для доступа Web-навигатора к серверу СУБД подключаемых к навигатору специализированных программных модулей (plug-ins) требует предварительной установки соответствующего программного дополнения на рабочей станции. После этого взаимодействие с сервером СУБД будет осуществлять установленное программное средство, получающее управление от Web-навигатора при обработке соответствующего вызова в Web-документе.
Для избежания несовместимости взаимодействие подключенных программных модулей с сервером СУБД, как и в случае программных компонентов ActiveX Controls, должно выполняться через интерфейс ODBC.
1.2.4. Управление информацией о ресурсах и пользователях сети. Масштабность и неоднородность современных компьютерных сетей не только усложняют администрирование и защиту компьютерных ресурсов, но и снижают удобство использования распределенных сетевых сервисов конечными пользователями. В этих условиях требуемый уровень управляемости, безопасности и удобства использования компьютерной сети может быть обеспечен только при наличии эффективного управления информацией о ее ресурсах и пользователях. В противном случае администратор не сможет осуществлять должный контроль компьютерных ресурсов, а пользователи не будут иметь возможности прозрачного доступа к любому сервису сети вне зависимости от его местонахождения.
Эффективное управление информацией о ресурсах и пользователях сети предполагает динамическое накопление и обновление этой информации, а также выдачу необходимых сведений по запросам пользователей и программ в соответствии с их полномочиями. Различают два вида управляемой информации о ресурсах и пользователях сети;
- административная информация, включающая сведения о пользователях и сетевых ресурсах, которые не детализируют описания информационных ресурсов на уровне отдельных файлов, например, файлов документов (Web-документов, обычных текстовых документов, документов Word, Excel и др.);
- детальные сведения об информационных ресурсах сети на уровне отдельных файлов, отражающие их содержимое и адреса.
Способы управления административной информацией о сети и детальными сведениями об информационных сетевых ресурсах были разработаны до появления Web-технологии. Однако при переходе на Web-архитектуру, благодаря которой повысились доступность и популярность, а соответственно и масштабность компьютерных сетей, эти способы получили новое развитие.
Для управления административной информацией о сети в состав современных сетевых операционных систем входит подсистема, названная службой каталогов (directory service). Данная служба поддерживает имена, описания и адреса ресурсов и пользователей сети, что существенно упрощает установление связей и управление работой сети. Благодаря службе каталогов создается единое унифицированное сетевое пространство для всех пользователей и сетевых сервисов за счет выделения единых точек доступа и единообразного управления ресурсами и пользователями сети.
1.2.4.1. Задачи службы каталогов. Служба каталогов обеспечивает решение следующих важных задач:
- автоматический поиск сетевых ресурсов и зарегистрированных пользователей, а также прозрачный доступ к ресурсам сети;
- административный контроль и учет компьютерных ресурсов и пользователей;
- поддержка удобной системы именования сетевых ресурсов и пользователей;
- однократная регистрация пользователей и ресурсов сети.
Поиск сетевых ресурсов и зарегистрированных пользователей реализуется с помощью службы каталогов прозрачным образом. Здесь уместна аналогия с "желтыми страницами", позволяющими определять местоположение нужной службы по имени в известном окружении, например, в каком-либо городе, или производить поиск по определенным категориям, например, по музеям. Служба каталогов выполняет функции поиска аналогичным образом, но в качестве окружения использует компьютерную сеть и в отличие от "желтых страниц" процесс поиска выполняется автоматически. Это обеспечивает возможность прямого доступа к любому сервису в сети вне зависимости от его местонахождения.
Служба каталогов позволяет охватить централизованным административным контролем все ресурсы и всех пользователей компьютерной сети любого масштаба, покончив с допотопным способом управления каждым сервером в отдельности. Эта служба помогает администраторам собирать и просматривать информацию о ресурсах, распределенных по узлам сети, и обеспечивает единообразное представление этой информации.
Одной из важнейших функций службы каталогов является установление соответствия между сетевыми именами пользователей и ресурсов и сетевыми адресами или, иными словами, перевод одних в другие. Данная функция, называемая службой имен, позволяет работать с удобопонятными псевдонимами, а также переводить эти имена в машинные адреса и выполнять обратный перевод. Современные службы каталогов поддерживают все стандартные системы именований, что дает возможность единым образом управлять различными пространствами имен в неоднородных компьютерных сетях.
Благодаря службе каталогов пользователи и ресурсы регистрируются в сети лишь один раз, и все серверы могут параллельно осуществлять доступ в одни и те же каталоги. Когда общесетевая служба каталогов отсутствовала, каждым сервером сети приходилось управлять в индивидуальном порядке. Пользователь, нуждавшийся в каких-либо ресурсах сервера, должен был иметь на нем свою учетную запись. Это приводило к тому, что многие конечные пользователи регистрировались на нескольких серверах сети масштаба предприятия, и им все время приходилось помнить, где и какие ресурсы размещены.
Множество учетных записей сказывалось весьма болезненно как на пользователях, так и на администраторах. Но, что более важно, подвергало риску систему безопасности. Из-за необходимости помнить множество имен и паролей пользователи либо записывали их на бумагу, либо хранили в незащищенных местах, либо использовали несколько легко идентифицируемых паролей или, что еще хуже, задавали один и тот же пароль для всех учетных записей.
При использовании службы каталогов наличие одного идентификатора и пароля для доступа в сеть позволяет свести к минимуму риск для системы безопасности и, кроме того, администраторы получают больший контроль над доступом пользователей к конкретным сетевым ресурсам. В случае однократной регистрации аутентификация конкретного пользователя осуществляется на основе одного пароля или аппаратного ключа. При этом пользователь получает доступ к любому сетевому ресурсу, на который администратор дал ему права.
1.2.4.2. Принципы построения службы каталогов. Служба каталогов обеспечивает единое согласованное представление сети и унифицированный доступ к административной информации о сетевых ресурсах и пользователях. В услугах данной службы нуждаются все пользователи и сервисы сети. Доступ любого пользователя или сервиса к службе каталогов реализуется в соответствии с его полномочиями.
Схема использования и организационная структура службы каталогов представлена на рис. 1.19. Доступ к любым административным сведениям о сети выполняется специализированной СУБД через интерфейсную подсистему, которая обеспечивает единый способ представления этих сведений. СУБД службы каталогов в процессе обработки запросов взаимодействует с подсистемой идентификации, предназначенной для установления соответствия между сетевыми именами пользователей и ресурсов и их реальными адресами в сети.
База данных службы каталогов организована в виде иерархий каталогов аналогично структуре каталогов файловой системы. Иерархии каталогов обеспечивают систематизацию хранящихся в них объектов путем их распределения по каталогам в соответствии с какими-либо признаками.
В базе данных службы каталогов объектами являются порции информации, характеризующие ресурсы и пользователей сети. Объекты объединяются в поименованные каталоги по определенному признаку, например, по принадлежности к подразделениям организации. Каждый каталог может содержать другие каталоги и объекты (рис. 1.20). Каталог, который не входит ни в какие другие каталоги, является корневым.
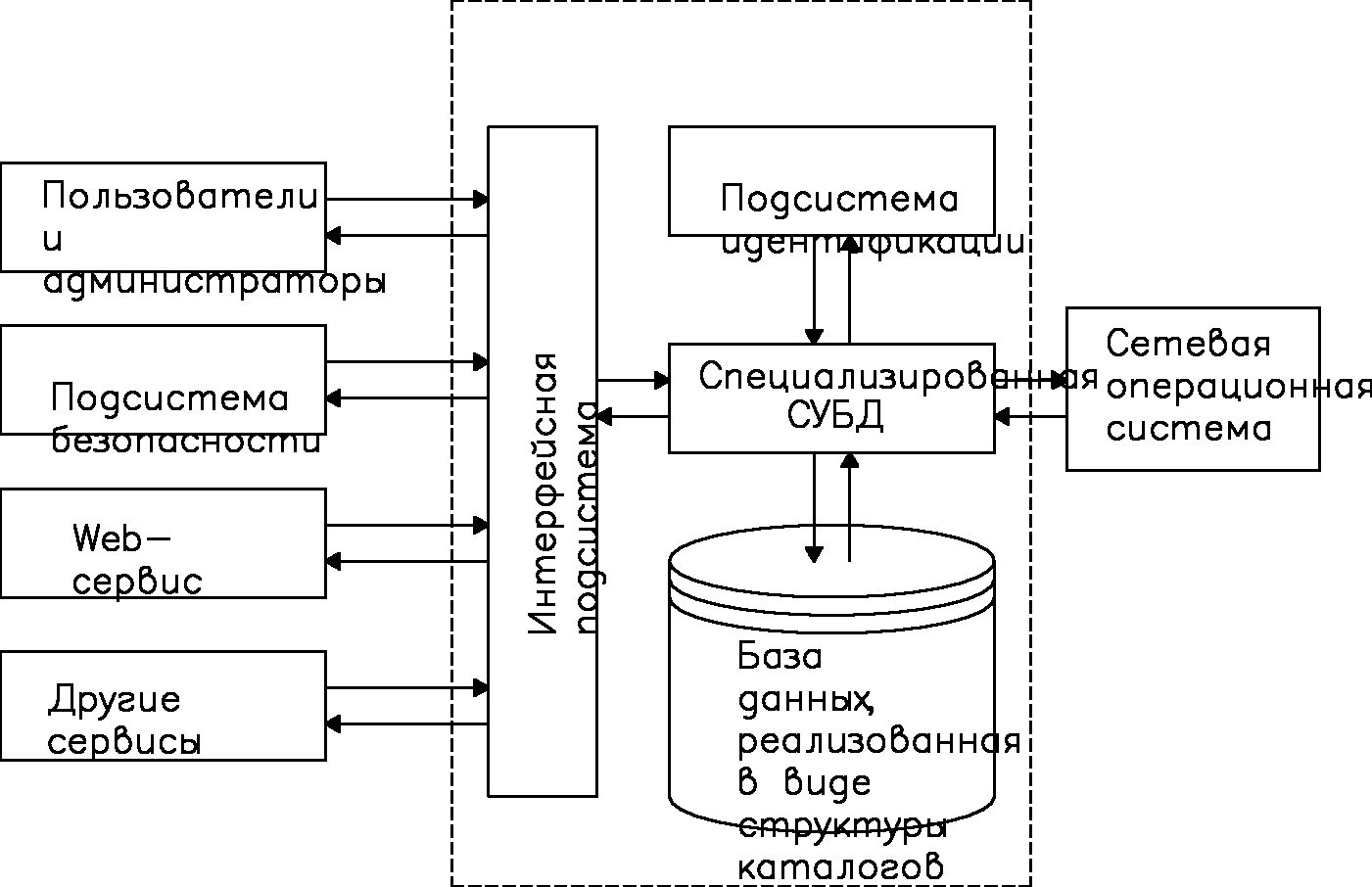
Рис. 1.19. Схема использования и организационная структура службы каталогов
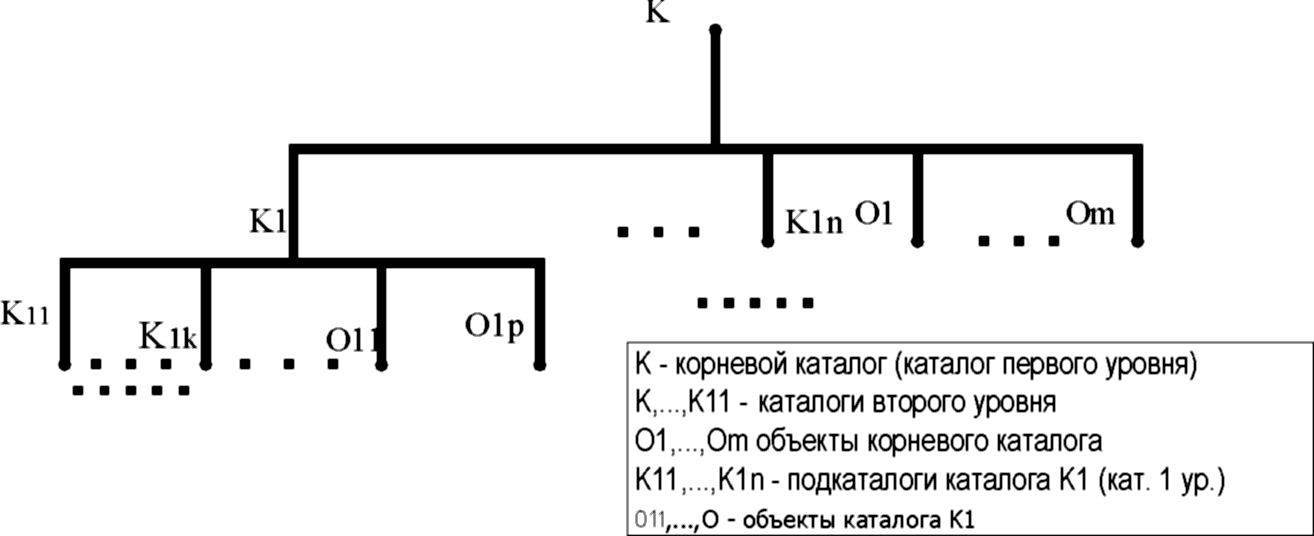
Рис. 1.20. Древовидная структура корневого каталога базы данных службы каталогов
Таким образом, в древовидной структуре любого корневого каталога нелистовыми вершинами (имеющими выходные дуги) являются каталоги, а листовыми (не имеющими выходных дуг) - объекты. Для отдельных операционных систем, например, для Windows NT, база данных службы каталогов может включать несколько корневых каталогов, объединенных определенными типами отношений. В этом случае полное дерево корневого каталога называют доменом.
Объект в каталоге базы данных представляет собой ее запись, соответствующую реальному объекту или субъекту сети, например, принтеру или пользователю. Каждый объект каталога содержит информацию в виде набора свойств (атрибутов) и их значений. Например, сетевой принтер характеризуется в базе данных объектом Printer, для которого определены такие свойства, как имя, описание, местоположение и сетевой адрес. Одни и те же типы объектов обладают одинаковыми свойствами, в то время как у разных типов объектов свойства могут отличаться. Для каждого типа объектов определяются обязательные свойства, без указания значений которых объект данного типа не сможет быть создан. Например, обязательным свойством объектов всех типов является имя.
Различают следующие типы объектов базы данных службы каталогов:
- объект рабочая станция, содержащий описание рабочей станции сети;
- объект сервер, описывающий сервер сети;
- объект тома, характеризующий логический том на дисковом носителе информации;
- объект принтер, содержащий описание принтера;
- объект очередь, описывающий очередь заданий на печать;
- объект пользователь, содержащий учетную запись пользователя (идентификатор, фамилия и имя, пароль, полномочия, адрес электронной почты, сценарий регистрации и др.);
- объект группа, описывающий группу пользователей;
- объект профиль, описывающий задаваемые для пользователей параметры конфигурации;
- объект схема каталога, характеризующий каталог;
- другие объекты, зависящие от конкретной службы каталогов.
Объединение с помощью иерархий каталогов описаний реальных сетевых объектов и субъектов существенно упрощает администрирование сети, а также поиск ее ресурсов и пользователей.
Заполнение базы данных службы каталогов выполняют как соответствующие компоненты сетевой операционной системы и сетевые сервисы, так и администраторы сети.
Для высокой надежности функционирования компьютерной сети современные службы каталогов поддерживают функции тиражирования и синхронизации своих баз данных. Тиражирование предполагает формирование нескольких копий базы данных, распределенных по различным серверам. Синхронизация обеспечивает своевременное обновление распределенных копий базы данных для их поддержания в актуальном состоянии.
Современные службы каталогов соответствуют стандартам Х.500 и LDAP (Lightweight Directory Access Protocol — облегченный протокол доступа к каталогам). Наиболее распространенным является стандарт LDAP, который представляет собой подмножество протокола Directory Access Protocol (DAP), используемого для построения каталогов Х.500. Однако DAP работает только в стеках протоколов модели OSI (Open System Interconnection) и требует серьезных вычислительных мощностей. Протокол LDAP, как и DAP, предназначен для извлечения информации из иерархических каталогов, но в отличие от него, имеет ограничение по числу ответов на запрос к каталогу Х.500, что снижает загрузку сети. Преимуществом LDAP является также его программный интерфейс, более дружественный и легкий для использования, чем интерфейс Х.500 или DAP. Кроме того, LDAP проще реализуется, чем вышеупомянутые протоколы, поскольку в нем используются для кодирования обычные текстовые строки без дополнительного форматирования.
В сетевых операционных системах Novell NetWare используется служба каталогов Novell Directory Services (NDS). Microsoft Windows NT Server 4.0 включает службу каталогов Windows NT Directory Service (NTDS). Для пятой версии данной операционной системы разработана новая служба каталогов Active Directory (AD). Службы каталогов NDS и AD соответствуют протоколу LDAP.
1.2.4.3. Управление детальными сведениями об информационных ресурсах. Для управления детальными сведениями об информационных ресурсах сети на уровне отдельных файлов используются специализированные информационно-поисковые системы. Эти системы ориентированы на выполнение следующих функций:
- периодического сканирования файлов, хранящихся в узлах компьютерной сети с целью определения их содержимого;
- систематизации полученной при сканировании информации и занесение ее в базу данных об информационных ресурсах сети;
- поиска и выдачи необходимых сведений по запросам пользователей и программ в соответствии с их полномочиями.
Функцию поиска и выдачи необходимых сведений по запросам пользователей и профамм реализует специализированная СУБД на основе сведений об информационных ресурсах сети, хранящихся в базе данных информационно-поисковой системы (рис. 1.21 и 1.22). Результатом поиска является список указателей на удовлетворяющие запросу файлы вместе с их описаниями.
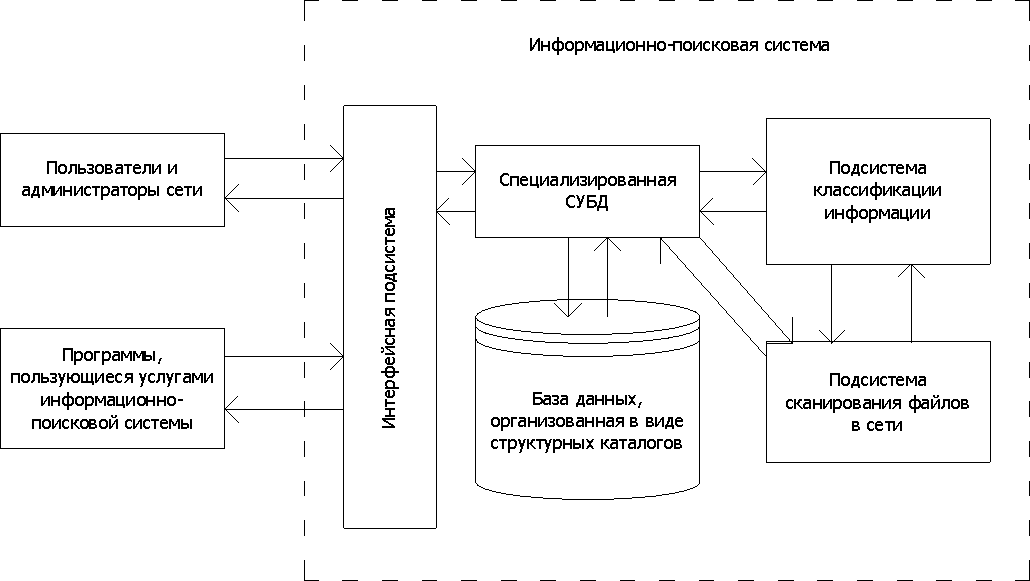
Рис. 1.21. Схема использования и организационная структура информационно-поисковой системы, основанной на построении каталогов
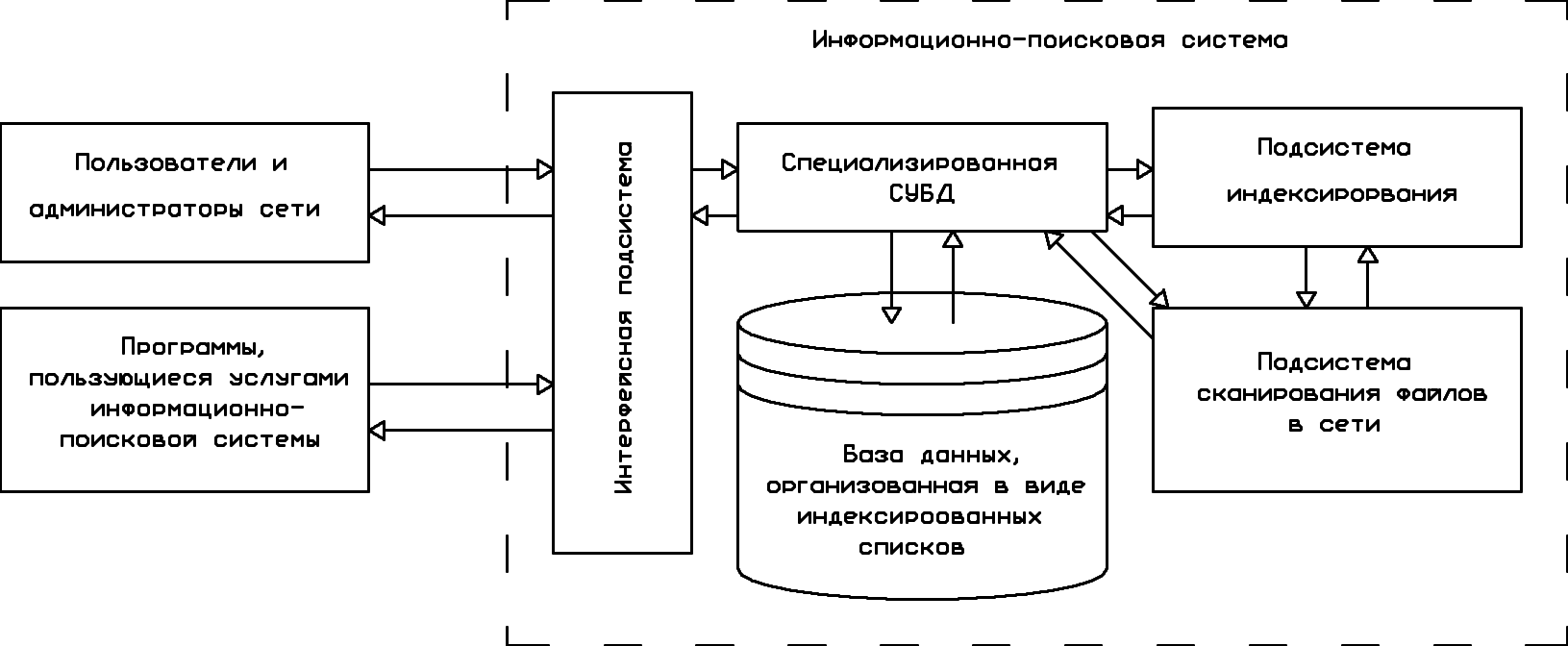
Рис. 1.22. Схема использования и организационная структура информационно-поисковой системы, основанной на построении индексов
В зависимости от автоматизации способа накопления сведений в базе данных об информационных ресурсах, а также ее структуры различают два типа информационно-поисковых систем:
- системы, основанные на построении каталогов, которые обеспечивают как поиск путем навигации по тематическим каталогам, так и поиск по ключевым словам;
- системы, основанные на построении индексов, которые обеспечивают только поиск по ключевым словам.
Существуют также комбинированные информационно-поисковые системы.
Общей особенностью перечисленных типов поисковых систем является используемый способ сканирования файлов, хранящихся в узлах компьютерной сети с целью определения их содержимого.
Сканирование файлов в сети для построения тематических каталогов и индексов выполняется автоматически. Основная задача сканирования файлов - формирование их описаний. Описание файла называют его поисковым образом, так как оно заменяет собой этот файл, и используется при поиске вместо реального файла.
Наиболее популярной моделью поискового образа файла является векторная модель, в которой каждому файлу приписывается список терминов, адекватно отражающих его описание. Если быть более точным, то файлу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в поисковом образе. В более сложных моделях термины взвешиваются — элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной.
Процесс формирования поисковых образов файлов осуществляется включением в поисковый образ каждого файла относящихся к нему ключевых слов. Эту процедуру часто называют индексированием, что не совсем правильно, так как под индексированием понимается составление инвертированного списка, в котором каждому термину ставится в соответствие указатель (индекс) на список поисковых образов файлов, к которым этот термин имеет отношение.
Для сканирования файлов в сети и формирования их поисковых образов используются специальные сканирующие программы, которые часто называют роботами. Программа-робот запускается на компьютере, подключенном к сети, и автоматически скачивает для анализа файлы с сетевых узлов. Разработка таких сканирующих программ является довольно нетривиальной задачей. Ведь файловое содержимое компьютеров сети представлено в виде различных, никак не согласованных друг с другом форматов данных: различные типы электронных документов, текст в разных кодировках (ASCII, ANSI, UNICODE), графика, аудио-, видеоинформация, программы. Робот должен уметь извлекать информацию об этих файлах и формировать их поисковые образы приписыванием соответствующих ключевых слов.
Источниками информации об анализируемых документах являются заголовки, аннотации, списки ключевых слов, гипертекстовые ссылки и полные тексты документов. Для формирования поисковых образов файлов с нетекстовой информацией используются главным образом ссылки на эту информацию (URL), а также сообщения пользователей и администраторов, располагаемые в специализированных файлах. Описание новостей Usenet и почтовых списков реализуется на основе полей Subject и Keywords.
Следует иметь в виду, что при сканировании файлов не все термины из анализируемых источников информации попадают в поисковые образы. Приписывание поискового образа файлу или документу выполняется на основе словаря, из которого выбираются помещаемые в поисковый образ ключевые слова. Различают системы с контролируемым словарем и системы со свободным словарем.
Контролируемый словарь предполагает ведение некоторой лексической базы данных, добавление терминов в которую производится администратором системы. В этом случае поисковые образы могут быть составлены только из терминов лексической базы данных.
Свободный же словарь пополняется автоматически по мере появления новых терминов. Соответственно поисковые образы могут быть составлены из новых терминов, которые автоматически заносятся в лексическую базу данных. В этом случае применяются списки запрещенных слов, которые не могут быть употреблены для формирования новых терминов и построения поисковых образов, например, предлоги, союзы и т. п. Для того чтобы не раздувать используемые словари, применяется и такое понятие, как вес термина. Словарь пополняется только в том случае, если дополняемое слово встречается не менее заданного количества раз, например, 30.
Поисковые системы, основанные на построении тематических каталогов
В данных информационно-поисковых системах база данных организована в виде структуры каталогов. Помимо интерфейсной подсистемы, обеспечивающей единый способ представления иерархий каталогов, самой базы данных и СУБД в эту поисковую систему входит подсистема сканирования файлов в сети, а также подсистема классификации информации (см. рис. 1.21).
Подсистема классификации ориентирована на систематизацию полученных в результате сканирования сведений. Процесс классификации информации и формирования каталогов выполняется чаще всего вручную подразделением поддержки тематических каталогов.
Результатом ручной классификации сведений об информационных ресурсах сети являются постоянно обновляющиеся иерархические каталоги, на верхнем уровне которых собраны самые общие информационные категории, например, категории, соответствующие направлениям деятельности отдельных подразделений организации. Объекты каталогов, являющиеся нелистовыми вершинами иерархического дерева, представляют собой ссылки на файлы, например, файлы электронных документов (Web, Word, Excel и др.), вместе с кратким описанием их содержимого.
Преимущество тематических каталогов в осмысленности отбора информации, что пока не под силу никакому компьютеру. Но в связи с тем, что темагические каталоги заполняются вручную, нет гарантий относительно их полноты. Кроме того, ручные процессы классификации информации требуют существенных затрат человеческого труда, что может себе позволить не каждая организация.
В Internet большой поп. лярностью пользуются такие международные тематические каталоги, как Yahoo (http://www.yahoo.com) и Infoseek (http://www.infoseek.com). Наиболее популярными в Internet русскоязычными поисковыми системами, включающими тематические каталоги, являются системы Ау (http://www.au.ru) и Rambler (http://www.rambler.ru).
1.2.4.4. Поисковые системы, основанные на построении индексов. Недостатки, присущие службам тематических каталогов, устраняются в информационно-поисковых системах, основанных на построении индексов. В этих поисковых системах вместо подсистемы классификации применяется подсистема индексирования (см. рис. 1.22), а база данных организована в виде списков, ставящих в соответствие ключевым словам указатели на относящиеся к ним описания файлов. Данные указатели, обеспечивающие быстрый поиск сведений по запросам пользователей и программ, называют индексами.
После сканирования файлов в сети и формирования их поисковых образов систематизация полученных сведений выполняется автоматически путем их индексирования. При индексировании составляется список, в котором каждому ключевому слову ставится в соответствие указатель (индекс) на список поисковых образов файлов, к которым это ключевое слово имеет отношение. Отсутствие индексирования привело бы к слишком длительному поиску образов (описаний) документов по заданным ключевым словам.
Структура и состав индексированных списков различных систем могут отличаться друг от друга и зависят от многих факторов: размера массива поисковых образов, информационно-поискового языка, размещения различных компонентов системы и т. п. Рассмотрим структуру индексированного списка на примере системы, для которой можно реализовывать не только примитивный булевый, но и контекстный, а также взвешенный поиск Web-страниц, и ряд других возможностей.
Индексированный список такой системы должен включать таблицу идентификаторов Web-страниц (page-ID), таблицу ключевых слов (Keyword-ID), таблицу модификации Web-страниц, таблицу заголовков, таблицу гипертекстовых связей, инвертированного (IL) и прямого списков (FL).
Page-ID отображает идентификаторы Web-страниц в их адрес (URL), Keyword-ID — каждое ключевое слово в уникальный идентификатор этого слова, таблица заголовков — идентификатор Web-страницы в ее заголовок, таблица гипертекстовых ссылок — идентификатор Web-страницы в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову документа список пар — идентификатор Web-страницы, позиция слова в странице. Прямой список — это массив поисковых образов Web-страниц.
Все эти файлы, так или иначе, используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле — это объединение и/или пересечение списков идентификаторов Web-страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным — хэширование.
Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу" с помощью таблицы модификации страниц. Суть подобного решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса — его перезагрузка. Эффективность поиска в каждой конкретной поисковой системе определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и ее гордостью.
Так как сканирование файлов в сети и индексирование полученной при сканировании информации выполняются автоматически, то информационно-поисковые системы, основанные на построении индексов, функционируют в полностью автоматическом режиме, что делает их доступными для компьютерных сетей любых организаций.
Основным способом поиска информации для пользователя поисковой системы, базируемой на построении индексов, является поиск по ключевым словам, который намного мощнее аналогичного способа поиска по отношению к системам, основанным на построении каталогов. Информационно-поисковый язык позволяет сформулировать запрос в простой и наглядной форме. При обработке запроса его содержимое разбивается на лексемы, из которых удаляются запрещенные и общие слова. Иногда производится нормализация лексики, а затем все слова связываются указанными пользователем либо действующими по умолчанию логическими операциями.
Кроме обычного набора логических операций AND, OR, NOT наиболее развитые поисковые системы позволяет использовать еще и операцию NEAR, обеспечивающую контекстный поиск. В запросе можно указать также части документа для поиска: ссылка, заглавие, аннотация и т. п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
В ряде поисковых систем используется коррекция запросов по релевантности. Релевантность — это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Первую вычисляет система, и на основании чего ранжируется выборка найденных документов. Вторая — это оценка самим пользователем найденных документов. Некоторые системы имеют для этого специальное поле, где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, а результат снова ранжируется. Так происходит до тех пор, пока не наступит стабилизация, означающая, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
В Internet большой популярностью пользуются такие международные поисковые системы, основанные на построении индексов, как AltaVista (http://altavista.digital.com) и Lycos (http://www.lycos.com). Популярными русскоязычными поисковыми системами данного типа являются:
- Rambler (http://www.rambler.ru);
- Ау (http://www.au.ru);
- Русская машина поиска (http://search.interrussia.com);
- Russian Internet Search (http://www.search.ru).
Поисковые системы Lycos, Ay и Rambler являются комбинированными, объединяющими индексированные списки и тематические каталоги.
В настоящее время появился ряд информационно-поисковых систем для корпоративных компьютерных сетей. В рамках Web-сервера Enterprise Server компании Netscape реализована поисковая система, основанная на построении индексов. Корпорация Netscape выпустила и отдельный поисковый сервер Catalog Server, объединяющий функции построения индексированных списков и каталогов. В состав операционной системы Microsoft Windows NT Server, начиная с четвертой версии, включена поисковая система Index Server, основанная на построении индексов.
1.2.5. Электронная почта и системы новостей. Помимо Web-сервиса одними из наиболее популярных сетевых сервисов являются электронная почта (E-mail) и система новостей (Network News), часто называемая еще системой телеконференций. Эти службы сети функционируют на прикладном уровне модели OSI и предназначены для обработки и доставки электронных сообщений в распределенной сетевой среде. Однако если при отправке сообщения электронной почты конкретизируется адрес получателя, то при отправке сообщения системы новостей адрес получателя не указывается, а задается лишь тема сообщения.
Сообщение электронной почты доставляется получателю, адрес которого указан в заголовке сообщения. Сообщение же системы новостей, называемое еще статьей, могут получить все, кто подписался по теме, также указанной в заголовке сообщения. Соответственно аналогом сообщений электронной почты являются обычные письма, а аналогом статей системы новостей — газеты и журналы, доставляемые по подписке.
Современные программы электронной почты и систем новостей позволяют не только создавать сообщения в формате HTML, используемом в Web-документах, но и добавлять к отправляемым сообщениям любые файлы, например, файлы с аудио- или видеоинформацией.
1.2.5.1. Обмен электронными сообщениями Рекомендации стандарта Х.400. Использование электронной почты для оперативного обмена информацией между людьми как внутри отдельно взятой организации, так и за ее пределами существенно повышает эффективность совместного труда.
Структура и принципы функционирования любой современной почтовой системы в общем случае соответствуют рекомендациям стандарта Х.400, являющимся результатом деятельности международного комитета по средствам телекоммуникаций (CITT во французской транскрипции или ITU в английской). Рекомендации Х.400 охватывают все аспекты построения среды управления сообщениями: компоненты и схемы их взаимодействия, протоколы управления и передачи, форматы сообщений и правила их преобразования.
Система обмена электронными сообщениями в рамках большой компьютерной сети представляет собой совокупность почтовых отделений, объединенных между собой сетевой средой (рис. 1.23). Локальная сеть может содержать лишь одно почтовое отделение, обслуживающее всех пользователей.

Рис. 1.23. Схема построения системы обмена сообщениями
Схема функционирования каждого почтового отделения реализуется в соответствии с технологией "клиент-сервер", когда почтовый сервер осуществляет обработку запросов, поступающих от почтовых клиентов. В качестве почтовых клиентов выступают программы электронной почты, установленные на компьютерах пользователей. Программы, исполняющие роль почтовых серверов, чаще всего устанавливаются на серверах сети.
Основными компонентами почтового сервера являются:
- подсистема передачи сообщений, выполняющая их пересылку;
- хранилище сообщений, предназначенное для промежуточного хранения сообщений перед их пересылкой получателю или передачей почтовым клиентам.
В зависимости от масштабности сети пересылка сообщений подсистемой передачи может выполняться либо напрямую почтовому серверу получателя, либо через промежуточные почтовые серверы в соответствии с правилами маршрутизации, определяемыми используемым протоколом обмена электронными сообщениями.
Хранилище сообщений каждого почтового сервера состоит из почтовых ящиков пользователей этого сервера, а также перевалочных почтовых ящиков, используемых для промежуточного хранения транзитных сообщений. Хранилище позволяет осуществлять отправку сообщений в наиболее удобное для почтового сервера время. Кроме того, хранилище не требует постоянного подключения к почтовому серверу компьютеров пользователей, что актуально для Internet. В этом случае почтовые клиенты могут извлекать предназначенные для пользователей сообщения при подключении к серверу.
Таким образом, основными способами отправки почтовых сообщений являются следующие:
- отправка сообщения почтовым клиентом через хранилище, когда пользователь, используя свою программу электронной почты, помещает отправляемое сообщение непосредственно в хранилище сообщений; оттуда оно выбирается и отправляется подсистемой передачи;
- отправка сообщения почтовым клиентом через подсистему передачи, когда сообщение передается напрямую данной подсистеме и далее доставляется ее средствами.
- основным способам получения сообщений относятся:
- получение сообщения почтовым клиентом из хранилища; в этом случае подсистема передачи осуществляет доставку сообщения в почтовый ящик получателя для его дальнейшей обработки программой электронной почты пользователя;
- получение сообщения почтовым клиентом от подсистемы передачи, когда данная подсистема непосредственно отправляет сообщение программе электронной почты получателя.
Первые из перечисленных способов отправки и получения электронных сообщений используют в случае отсутствия постоянного подключения компьютеров пользователей к почтовому серверу, вторые — при постоянном подключении пользовательских компьютеров к сети.
В качестве дополнительного, но очень важного компонента почтового сервера выступает служба каталогов, поддерживающая имена, описания и адреса пользователей сети. В состав почтового клиента должна входить адресная книга, также предназначенная для хранения имен, описаний и адресов пользователей сети. Но в отличие от службы каталогов, хранящей всю справочную информацию, адресная книга заполняется пользователем. Адресная книга, по сути, является службой каталогов, поддерживаемой пользователем, и должна обеспечивать взаимодействие с общей службой каталогов сети.
Адресная книга и служба каталогов сети должны иметь возможность создания, сохранения и выборки списков рассылки. Список рассылки представляет собой группу электронных адресов, по которым можно одновременно отправить одно сообщение. Будучи отправлено на адрес списка рассылки, сообщение будет доставлено по всем входящим в него адресам.
Для описания формата сообщения электронной почты в рекомендациях Х.400 была принята привычная парадигма конверта и его содержимого, используемая в традиционных почтовых системах (рис. 1.24).
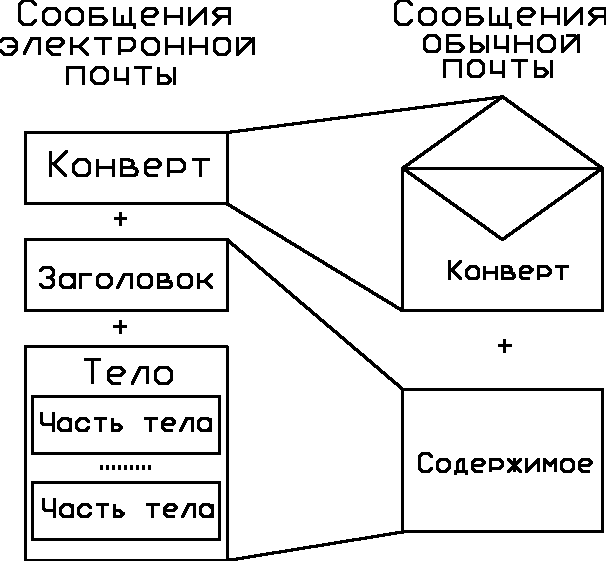
Рис. 1.24. Структура электронного сообщения
Как и положено, конверт содержит исчерпывающую информацию о том, куда и кому должно быть доставлено письмо, обратный адрес отправителя и пометку о срочности доставки. При этом системе нет необходимости знать, что бы то ни было о содержимом письма. На основе информации, указанной на конверте, среда доставки выполняет необходимую маршрутизацию и передачу с возможным промежуточным хранением. Роль перевалочных пунктов и средств транспортировки выполняют транзитные почтовые серверы.
Конверт может иметь специальную пометку о необходимости установки на нем электронного "штампа" каждым почтовым сервером, через который проходит сообщение на пути к адресату. Это, в частности, позволяет системе автоматически отслеживать возникновение маршрутных петель.
Содержимое конверта состоит из заголовка и тела. Заголовок обычно включает в себя копию информации, указанной на конверте, и дополнительные поля, определяющие расширенные свойства сообщения. Тело в свою очередь может быть составным и включать различные типы информации, такие как текст, графика, документы различных форматов, вложенные файлы и т. д.
Рекомендации Х.400 предусматривают также возможность автоматического уведомления отправителя о факте доставки и/или прочтения посланного им сообщения.
1.2.5.2. Протокол SMTP. Несмотря на мощную теоретическую базу и практически безупречный архитектурный дизайн, стандарт Х.400 не получил широкого распространения за пределами государственных и банковских учреждений. Недостатками этого стандарта явились чрезмерная сложность реализации и значительная стоимость внедрения и эксплуатации систем на его основе. Однако вытекающие из этого стандарта общие принципы управления сообщениями стали основой современных почтовых служб.
Наиболее распространенным протоколом электронной почты является протокол SMTP (Simple Mail Transfer Protocol — простой протокол передачи почты), ставший стандартом обмена сообщениями в Internet и intranet. Популярность этого протокола объясняется сравнительной простотой реализации и широкими возможностями расширяемости без ущерба ддя обратной совместимости с существующими версиями почтовых систем. Немаловажным фактором является также широкая доступность спецификаций и отсутствие необходимости отчислять средства за их использование.
Протокол SMTP в качестве транспортного протокола использует TCP и применяется для реализации двух функций (рис. 1.25):
- пересылки отправляемых сообщений от почтовых клиентов к почтовым серверам этих клиентов;
- передачи сообщений между почтовыми серверами.
Начальная версия протокола SMTP поддерживала ограниченный набор команд и сервисов для приема и передачи сообщений. В последнее время был разработан его расширенный вариант (Extended SMTP или ESMTP), обеспечивающий стандартную возможность дальнейшего расширения и поддержку таких функций, как подтверждение доставки (Delivery Notification Request или DNR), согласование максимального допустимого размера сообщений, передаваемых между серверами, и принудительная инициация передачи накопленной почты.

Рис. 1.25. Схема обмена сообщениями на базе протокола SMTP
Однако протокол SMTP при автономном применении все еще обладает рядом недостатков:
- отсутствие возможности аутентификации входящих соединений;
- ориентация на передачу только текстовой информации;
- отсутствие возможности шифрования передаваемых сообщений.
Для устранения этих недостатков SMTP используется совместно с дополняющими его протоколами и стандартами.
Отсутствие средств аутентификации входящих соединений не позволило использовать SMTP для обслуживания клиентского доступа. Классическая почтовая SMTP-система требует наличия файлового доступа клиента к своему почтовому ящику для получения и работы с сообщениями. Для реализации работы в режиме клиент-сервер был создан протокол обслуживания почтового офиса (Post Office Protocol или POP). Наиболее удачной оказалась версия РОРЗ, широко используемая в современных SMTP-системах. Протокол РОРЗ позволяет пользователю с помощью программы электронной почты, выполняющей роль клиента, забрать из своего почтового ящика, расположенного на почтовом сервере, поступившие сообщения.
Наиболее продвинутые реализации РОРЗ поддерживают аутентификацию с шифрованием имени и пароля, а также шифрование трафика по протоколу Secure Socket Layer (SSL). Однако при использовании протокола РОРЗ отсутствует возможность просмотра характеристик сообщения без предварительной загрузки его на станцию клиента. Для решения проблемы просмотpa и манипуляции свойствами почтового сообщения непосредственно на сервере, а также преодоления ряда других функциональных ограничений был разработан протокол IMAP4. В отличие от РОРЗ протокол IMAP4 предоставляет следующие возможности:
- просмотр заголовков сообщений, чтобы определить, какие из них следует читать (загружать с почтового сервера на рабочую станцию);
- избирательную загрузку с сервера частей сообщений в формате MIME;
- поиск сообщений на сервере;
- создание как стандартных, так и определенных пользователем атрибутов сообщений, например, для идентификации рабочих групп, проектов и т. д.;
- организацию на сервере иерархии папок вне входного почтового ящика;
- распределение по созданным на сервере папкам почтовых сообщений, их обновление и долговременное централизованное хранение;
- централизованное резервирование и восстановление почтовых сообщений, хранящихся на сервере.
Современные программы электронной почты, например Microsoft Outlook Express, поддерживают в качестве клиентского почтового протокола как РОРЗ, так и IMAP4.
Следует заметить, что если для получения сообщений почтовым клиентом с сервера используется протокол РОРЗ или IMAP4, то отправка сообщений от почтового клиента на сервер все равно реализуется в соответствии с протоколом SMTP (рис. 1.25).
Изначально SMTP-системы рассчитывались на передачу информации исключительно в текстовом виде и не были ориентированы на передачу символов национальных алфавитов, т. е. использовали 7-битный набор символов.
Для решения проблемы передачи двоичных файлов был разработан стандарт UUENCODE, позволяющий внедрять предварительно преобразованные из бинарного в текстовый вид произвольные данные непосредственно в текст сообщения. Однако универсальным данный подход назвать было трудно, так как в общем случае никакой информации о типе передаваемых данных и породившем их приложении принимающая сторона не имела.
По мере расширения сети Internet, усложнения программного обеспечения и активного внедрения мультимедиа назрела необходимость создания универсального формата типизации и представления двоичных данных и текста, содержащего национальные символы. Таким универсальным форматом стали многофункциональные расширения почты Internet (Multipurpose Internet Mail Extensions или MIME). Формат MIME оказался чрезвычайно удачным, поскольку в него были заложены возможности неограниченного расширения как поддерживаемых типов данных, так и национальных кодировок.
Использование MIME позволяет включить в электронное письмо аудиоинформацию, двоичные данные или оцифрованный видеосигнал, а также подсоединять к передаваемому сообщению любые файлы. С помощью MIME можно создавать и читать электронные письма, содержащие информацию в RTF- и HTML-формате, в частности различные текстовые шрифты, сканированные изображения и электронные таблицы.
Немаловажной проблемой при передаче данных через SMTP-системы является обеспечение конфиденциальности. Для решения проблем с защитой информации был создан стандарт на шифрование тела сообщения, называемый засекреченные многофункциональные расширения почты (Secure MIME или S/MIME). Однако этот протокол не в состоянии защитить от перехвата заголовков сообщений.
Сообщение SMTP в соответствии с рекомендациями стандарта Х.400 состоит из конверта и содержимого. Содержимое в свою очередь имеет заголовок и тело. Функциональное назначение их полностью идентично. Состав полей в заголовке определяется форматом тела сообщения (UUENCODE или MIME). Ни одно поле не является обязательным, но, как правило, указываются такие поля, как кому (То:), от кого (From:) и тема (Subject:). В случае использования формата MIME в заголовке обязательно должно присутствовать поле MIME-Version:, в котором указывается номер версии стандарта MIME.
1.2.5.3. Адресация и маршрутизация. Для отсутствия противоречий в процессе обмена сообщениями каждый пользователь почтовой системы должен иметь в ней уникальный почтовый адрес. Этот адрес должен идентифицировать именно пользователя, а не используемый этим пользователем компьютер. Схему назначения уникальных адресов пользователям в той или иной почтовой системе называют адресацией.
При наличии в сети избыточных связей доставка сообщения получателю должна осуществляться по оптимальному маршруту от почтового сервера отправителя к почтовому серверу получателя. Процесс выбора очередного пункта на пути следования сообщения к почтовому серверу-получателю, называемый маршрутизацией, осуществляется на основе специальных таблиц. Маршрутизация почтовых сообщений реализуется поверх маршрутизации пакетов сетевого уровня. После выбора очередного транзитного почтового сервера в соответствии с правилами маршрутизации почтовых сообщений осуществляется маршрутизация на сетевом уровне модели OSI для оптимальной доставки выбранному транзитному серверу.
Схемы адресации и маршрутизации в конкретной системе электронной почты определяются применяемым протоколом обмена почтовыми сообщениями. Администратору, в чьи задачи входит обеспечение взаимодействия между несколькими разнородными системами передачи сообщений, необходимо знать методы адресации и маршрутизации, используемые в каждой из них. Рассмотрим схемы адресации и маршрутизации на примере протокола SMTP.
1.2.5.4. Адресация в SMTP. В системах на базе SMTP используется интуитивно понятная, простая и одновременно очень мощная иерархическая схема адресации, аналогичная той, что принята в службе имен Internet (Domain Name Services или DNS). Данная схема может обеспечить уникальность адреса практически неограниченному числу пользователей. Почтовый адрес SMTP записывается в следующем виде:
mailbox@domain
где mailbox — символическое имя почтового ящика пользователя (длиной до 63 символов), a domain — уникальное имя почтового домена, в котором зарегистрирован упомянутый пользователь (длиной до 255 символов). Сочетание имен почтового ящика и почтового домена образует уникальный идентификатор пользователя.
Почтовый домен хранит полную информацию о положении системы в иерархии почтового пространства организации (рис. 1.26). В имени домена имя каждого следующего уровня иерархии отделяется от предыдущего точкой. Разбор имени домена выполняется справа налево. Самый верхний уровень, называемый корневым доменом, соответствует либо типу организации (например, corn — коммерческая, gov — государственная, org — общественная), либо географическому региону (например, ru — Россия, a fr — Франция). Следующими в иерархии идут домены первого уровня, как правило, представляющие имя организации.

Рис. 1.26. Пример иерархической схемы адресации в SMTP
Регистрацией имен доменов первого уровня занимается международный центр Internet (Internet Network Information Center или InterNIC). За назначение имен доменов более низкого уровня чаще всего отвечают сами компании. Поскольку организациям не запрещается регистрировать для собственных нужд несколько параллельных доменов (например, spektr.spb.ru и spektr. corn), пользователь может иметь более одного SMTP-адреса. Кроме того, современные SMTP-системы зачастую позволяют назначать псевдонимы для самого почтового ящика.
В приведенном примере spektr.spb.ru является субдоменом spb.ru, который в свою очередь является субдоменом ru. Компания SPEKTR имеет два зарегистрированных имени, и каждый пользователь может иметь два почтовых адреса.
1.2.5.5. Маршрутизация в SMTP. Для того чтобы SMPT-сервер доставил почту на имя адресата ivanov@spektr.com, ему предварительно нужно узнать IP-адрес почтового сервера, обслуживающего домен spektr. corn, обратившись с соответствующим запросом к серверу DNS. В службе имен DNS предусмотрен специальный тип ресурсной записи для обслуживания такого рода запросов — MX или Mail Exchanger. Данная запись имеет следующий формат:
domain MX [cost] hostname
где domain — это имя почтового домена, к которому принадлежит адресат;
hostname — символическое имя почтового сервера, располагающего знаниями о том, как осуществлять дальнейшую доставку сообщения; cost — относительная стоимость доставки через этот компьютер. Для получения IP-адреса компьютера с именем hostname выполняется поиск адресной ресурсной записи в DNS. При наличии нескольких МХ-записей для одного и того же домена сначала будет выполнена попытка установить соединение с тем почтовым сервером, у которого стоимость доставки ниже. Если такой компьютер окажется недоступным или перегруженным, будут использоваться компьютеры с большими значениями стоимости.
Таким образом, чтобы доставить сообщение на имя адресата ivanov@spektr.com, сначала будет выполнен запрос к серверу DNS на получение списка ресурсных записей с типом MX. Если список не пуст, по имени компьютера с наименьшим значением стоимости доставки будет получен его адрес (опять же через DNS), после чего будет установлено соединение и отправлена почта. Если для домена spektr. corn нет МХ-записи, домен будет трактоваться как имя компьютера. Будет выполнена попытка получить его IP-адрес и доставить сообщение напрямую.
В связи с тем, что служба имен DNS полагается источником статической информации, схема маршрутизации сообщений SMTP является статической. В соответствии с протоколом SMTP в сетях, не имеющих прямого выхода в Internet и не использующих возможности МХ-записей DNS, могут использоваться отдельные статические таблицы маршрутизации почтовых сообщений.
В зависимости от возможностей маршрутизации SMTP-сервер может выступать в одной или нескольких из следующих ролей:
- mail exchanger — компьютер, непосредственно подключенный к Internet и выполняющий доставку сообщений напрямую адресатам внутри организации, к которой он принадлежит; в организации может быть несколько таких компьютеров с различными или одинаковыми значениями показателя стоимости доставки;
- relay — компьютер, выполняющий прием почтового трафика от лица других доменов, не имеющих непосредственного и/или постоянного подключения к Internet и, как правило, не принадлежащий к организациям, чьи домены он обслуживает; для каждого отдельного домена может быть определено не более одного relay-сервера;
- smart host — компьютер, который способен осуществлять пересылку сообщений на основе собственной статической таблицы маршрутизации;
- одной из функций smart host является переписывание на конверте адреса получателя и/или отправителя перед осуществлением дальнейшей передачи сообщения.
Большинство современных реализации SMTP-серверов позволяют сочетать все перечисленные функции на одном компьютере.
Передача новостей
В компьютерных сетях актуальной является не только задача оперативного обмена данными, но и тиражирования электронных сообщений для совместного использования информации различной тематики. Системы новостей, предназначенные для решения этой задачи, обеспечивают распространение посланных по каждой теме электронных статей всем подписавшимся на эту тему пользователям сети.
В системах новостей используются два основных метода тиражирования:
- отправка статей по спискам рассылки;
- использование распределенной базы новостей, статьи из которой пользователи получают сами.
В первом случае серверы тиражирования хранят у себя списки адресов подписчиков на статьи по различным темам. При необходимости тиражирования какой-либо статьи по определенной тематике пользователь отправляет данную статью в виде сообщения электронной почты по адресу соответствующего сервера. Тот, в свою очередь, рассылает копии данной статьи непосредственно по электронным адресам пользователей, подписавшихся на указанную в статье тему. Тиражирование статей на основе списков рассылки становится неэффективным при росте количества подписчиков. Это связано, прежде всего, со сложностью поддержания списков рассылки в актуальном состоянии, а также дополнительными требованиями по надежности функционирования серверов, осуществляющих рассылку.
Указанный недостаток устраняется при тиражировании путем использования распределенной базы новостей, статьи из которой пользователи получают сами. Данный способ тиражирования положен в основу службы USENET, являющейся наиболее популярной в сети Internet и ставшей общепризнанным стандартом для систем новостей.
Служба USENET изначально ориентирована на работу в архитектуре "клиент-сервер" и позволяет поддерживать базы новостей, распределенные между несколькими серверами с возможностью автоматической репликации вновь поступающих сообщений. Для взаимодействия серверов новостей друг с другом, а также клиентов с серверами был разработан протокол NNTP (Network News Transport Protocol — протокол передачи сетевых новостей).
В USENET используется формат и способ адресации сообщений, совпадающий с принятыми в SMTP-системах. Информация, специфическая для службы новостей, указывается в расширенных полях заголовка сообщения. Это позволяет разрабатывать клиентские программы для чтения почты и новостей на основе единого кода, а также использовать существующие сети SMTP для получения новостей в тех местах, где непосредственный доступ к серверу новостей по каким-либо причинам невозможен. Кроме того, применяются служебные сообщения, предназначенные для обмена управляющей информацией между серверами новостей. Благодаря служебным сообщениям упрощается процесс автоматического создания и удаления тематических групп новостей, а также ликвидации устаревших статей.
Вся информация, хранимая в USENET, представляется единым иерархическим деревом, организованным по тематическому признаку. В этом смысле USENET выступает в роли тематического каталога, содержащего мнения людей на ту или иную тему. Статьи, объединенные общей тематикой, помещаются в тематические группы, называемые группами новостей. Группы новостей, в свою очередь, могут содержаться внутри других групп, образовывая тематические иерархии. Каждый уровень иерархии называется категорией. В рамках категории группа имеет уникальное имя. Полное характерное имя группы получается последовательным добавлением слева направо имен категорий при движении вниз от корня по дереву иерархии. Имена категорий разделяются точкой. Например, имя relcom.comp.security соответствует группе новостей по компьютерной безопасности (comp.security) русскоязычной сети Relcom.
Иерархии или их отдельные ветви реплицируются между серверами новостей, образующими пространство USENET. В качестве единицы репликации выступает отдельная статья. При репликации используется схема издатель-подписчик. Каждый сервер USENET может быть подписан на некоторое подмножество групп, предоставляемых другими серверами. Одновременно он может публиковать некоторое подмножество групп, расположенных непосредственно на нем, в том числе группы, получаемые по подписке.
В терминах USENET репликация именуется заполнением (feed). В зависимости от того, какой сервер выступает инициатором этого процесса, различают два типа заполнения:
- вытягивание (pull feed), когда сервер, ожидающий поступления новых статей, сам обращается к своему издателю;
- проталкивание (push feed), когда сервер, имеющий у себя новые статьи, производит попытку передать их подписчику.
Еще одним немаловажным моментом службы USENET является возможность создания модерированных групп новостей. В модерируемой группе каж-дое новое сообщение автоматически перенаправляется лицу, выполняющему роль цензора или модератора. Если сообщение не противоречит уставу конференции и одобрено модератором, оно становится публично доступным для прочтения. В противном случае — просто удаляется.
Поскольку служба новостей изначально создавалась как средство ведения хранилища публично доступной информации, в ней не были предусмотрены функции назначения и проверки прав доступа на отдельные ветви каталога. Большинство существующих служб новостей способны выполнить лишь однократную проверку имени и пароля пользователя при установлении соединения с сервером, после удачного завершения которой все статьи становятся доступны клиенту. Кроме того, не предусмотрена возможность авторизации серверов и служебных сообщений. Как следствие этого, массовое применение USENET оправдано только для организации публичных групп новостей с анонимным режимом доступа.
Возможностями надежной проверки подлинности пользователей и разграничения их доступа к статьям по темам обладают системы электронной почты и новостей, специально разработанные для корпоративных сетей, например, система Microsoft Exchange, которая совместима со службой новостей USENET.