


|
|
результат. Эта команда очень удобна для формирования услов- |
|
|
ных ветвлений в программах. |
|
|
|
PSADBV |
|
Packed Sum of Absolute Differences |
|
|
Вычисляет сумму абсолютных значений разностей значений без- |
|
|
знаковых байтов источника и приемника. Источником могут высту- |
|
|
пать ММХ-регистр или 64-разрядная ячейка памяти, а приемником |
—один из ММХ-регистров.
3.8.6.XMM расширение с плавающей точкой
Синтаксис XMM команд:
Мнемоника приемник, источник
Мнемоника приемник, источник, маска
Мнемоника приемник
Приемник – всегда регистр XMM, источник - регистр XMM или ячейка памяти,
Типы данных. XMM-расширение реализовано в виде аппаратно-программного модуля SSE, который включает дополнительные восемь регистров разрядностью в 128 бит, имеющих обозначение ХММО - ХММ7,
и 32-разрядный регистр управления/состояния MXCSR.
Программная часть XMM-расширения включает в себя набор команд для работы с данными в формате плавающей точки. Содержимое ХММ-регистра представляет собой четыре 32-разрядных операнда с плавающей точкой в коротком формате (Single Precision Floating Point, SPFP). Представление данных SSE-
202
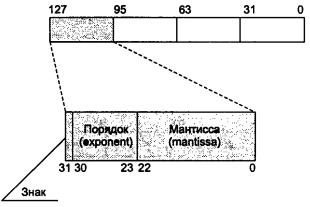
расширения соответствует стандарту IEEE-754, а сам формат данных показан на рисунке.
Здесь мантисса (mantissa) и порядок (exponent) формируют число в формате SPFP в соответствии с формулой
мантисса * 2порядок.
Этот формат данных несопоставим с тем, который принят для математического сопроцессора (число в 80-разрядном расширенном формате), поэтому в некоторых случаях при разных границах выравнивания результаты вычислений с использованием форматов FPU и SSE могут различаться.
Поскольку аппаратно модуль SSE-расширения реализован независимо от других модулей, то это позволяет выполнять XMM-комапды параллельно с командами математического сопроцессора и ММХ-командами. При этом для синхронизации вычислений инструкции наподобие EMSS не требуются.
Структура полей регистра управления/состояния (MXCSR) во многом напоминает ту, что реализована в регистрах состояния (swr) и управления (cwr) математического сопроцессора. Состоянием вычислений можно управлять путем установки определенных значений в поля этого регистра.
Набор инструкций XMM-расширения включает 70 команд.
Значительная часть команд может выполняться в двух контекстах: скалярном и параллельном. Это относится к арифметическим командам, а также к командам сравнения. Команды обрабатывают:
203
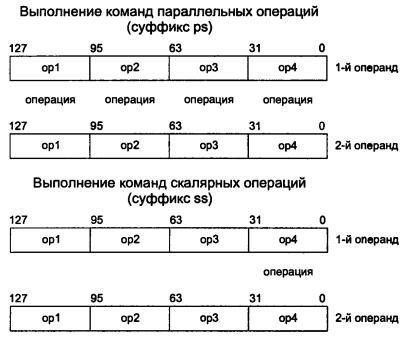
В параллельном контексте одновременно 4 двойных слова и имеют в своей мнемонике суффикс ps.
В скалярном контексте только младшие 32-разрядные двойные слова упакованных операндов, не затрагивая при этом три старших двойных слова. Исключение составляют некоторые команды скалярной пересылки данных. Мнемоническое обозначение этих команд включает суффикс ss.
В процессе обработки данных команды XMM-расширения могут возбуждать исключительные ситуации, которые возникают, если происходит одно из следующих событий:
некорректная операция (invalid operation);
денормализованный операнд (denormalized operand);
деление на 0 (divide-by-zero);
арифметическое переполнение (numeric overflow);
потеря значащих разрядов (numeric underflow);
204
потеря точности (inexact result).
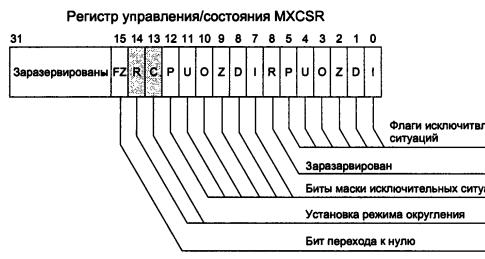
При возникновении исключительных ситуаций устанавливаются биты 0-5 в регистре управления/состояния (MXCSR). Каждая исключительная ситуация может быть замаскирована путем установки в 1 битов 7-12 регистра MXCSR. Если какое-либо исключение замаскировано, то оно обрабатывается процессором по стандартному алгоритму, после чего продолжается выполнение программного кода. Формат полей регистра MXCSR и их назначение показаны на рис. 13.5.
Биты 13-14 регистра MXCSR поля RC (или гс, что одно и то же) задают режим округления. По умолчанию устанавливается режим округления к ближайшему значению числа с плавающей точкой в коротком формате. Эти биты можно установить программно, причем возможны следующие комбинации:
00 — округление к ближайшему числу;
01 — округление к меньшему числу;
10 — округление к большему числу;
11 — округление с отбрасыванием дробной части.
Бит 15 используется, если результат операции близок к нулю. При этом процессор выполняет следующие действия:
возвращает значение 0 и знак результата;
205
устанавливает флаги Р (бит 5) и U (бит 4);
маскирует биты исключений.
Программная реализация SSE-расширения включает несколько десятков команд. Все их условно можно разделить на несколько групп:
команды передачи данных;
арифметические команды;
команды сравнения;
команды преобразования;
логические команды;
дополнительные команды.
Классификация команд
После обзора команды будут рассмотрены подробно.
Категория |
Подкатегория |
Команды |
Передача данных |
|
|
Арифметика |
Скалярные |
|
|
Параллельные |
|
Сравнение |
|
|
|
|
|
Преобразования |
|
|
Логика |
|
|
Дополнительные |
Вычисления |
|
|
Извлечения |
|
|
Извлечения знака |
|
Передача данных. Данные передаются между:
регистрами MMX,
регистром MMX и регистром основного процессора,
регистром MMX и памятью.
Если размер приемника меньше размера источника, то лишние разряды обнуляются.
|
|
|
Мнемоник |
|
Описание |
а |
|
|
|
|
|
MOVAPS |
|
MOVe Aligned four Packed Single precision float point |
|
|
|
206
|
|
Пересылка выровненных по 16-байтовой границе 128-разрядных |
|
|
операндов. В качестве входного операнда могут выступать ХММ- |
|
|
регистр или 128-разрядная ячейка памяти, выходным операндом |
|
|
может служить один из ХММ-регистров. Если адрес ячейки памяти |
|
|
не будет выровнен по 16-байтовой границе, то произойдет исключе- |
|
|
ние общей защиты. |
|
|
|
MOVUPS |
|
MOVe Unaligned four Packed Single precision float point |
|
|
Пересылка невыровненных данных; в качестве входного операнда |
|
|
могут выступать ХММ-регистр или 128-разрядная ячейка памяти, |
|
|
выходным операндом может служить один из ХММ-регистров. Ко- |
|
|
манда не требует выравнивания по 16-байтовой границе.. |
|
|
|
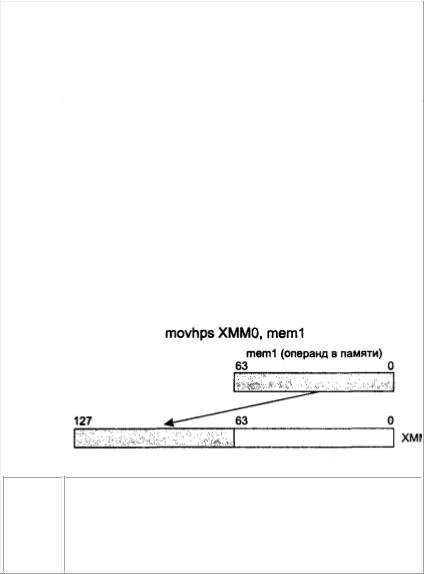
MOVHPS |
|
MOVe unaligned High Packed Single precision float point |
|
|
Пересылка невыровненных 64 бит из входного операнда в выход- |
|
|
ной. Один из операндов обязательно должен быть ХММ-регистром, |
|
|
в качестве второго может выступать 64-разрядная ячейка памяти. |
|
|
Пересылаются только старшие 64 бит входных операндов. Млад- |
|
|
шие 64 бит обоих операндов не изменяются. Если данные переда- |
|
|
ются из ХММ-регистра, то пересылке подлежат только старшие 64 |
|
|
бит. Команда не требует выравнивания по 16-байтовой границе |
|
|
адреса ячейки памяти. Пример: |
|
|
|
MOVLHPS MOVe Low to High Packed Single precision float point
Пересылка невыровненных 64 бит из входного операнда в выходной. Оба операнда должны находиться в ХММ-регистрах. Пересылаются только старшие 64 бит входных операндов. В результате выполнения этой команды изменяются младшие 64 бит приемника. Пример:
207
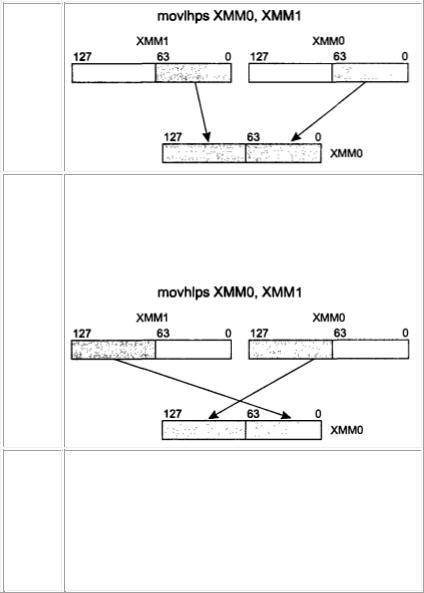
MOVHLPS MOVe High to Low Packed Single precision float point
Пересылка невыровненных 64 бит из входного операнда в выходной. Оба операнда должны находиться в ХММ-регистрах. Пересылаются только старшие 64 бит входных операндов. В результате выполнения этой команды изменяются младшие 64 бит регистраприемника. Пример:
MOVLPS MOVe unaligned Low Packed Single precision float point
пересылка невыровненных 64 бит из входного операнда в выходной. Один из операндов обязательно должен быть ХММ-регистром, в качестве второго может выступать 64-разрядная ячейка памяти. Пересылаются только младшие 64 бит входных операндов. Старшие 64 бит обоих операндов не изменяются. Если данные передаются из ХММ-регистра, то пересылке подлежат только младшие 64 бит. Команда не требует выравнивания по 16-байтовой границе адреса ячейки памяти. Пример:
208

MOVMSK |
|
MOVe sign MaSK Packed Single precision float point to integer |
PS |
|
Пересылка знакового бита каждого из четырех упакованных чисел |
|
|
входного операнда в младшие четыре бита выходного операнда. В |
|
|
качестве входного операнда может выступать только ХММ-регистр, |
|
|
а в качестве выходного операнда — 32-разрядный регистр общего |
|
|
назначения. Эта команда используется для организации условных |
|
|
переходов. Пример: |
|
|
|
|
MOVSS |
|
MOVe Scalar Single precision float point |
|
|
|
|
Пересылка 32 младших битов из источника в приемник, при этом как |
|
|
|
|
минимум один из операндов должен быть ХММ-регистром. Второй |
|
|
|
|
операнд должен быть 32-разрядной ячейкой памяти. При выполне- |
|
|
|
|
|
|
|
|
209 |
|
|

нии операции пересылки из операнда в памяти младшие 32 бит
помещаются в младшие 32 бит ХММ-регистра. Если выполняется пересылка из ХММ-регистра, то выбираются младшие 32 разряда регистра, остальные разряды не изменяются.
Арифметика. В мнемонике суффикс:
SS – скалярный контекст.
PS – параллельный контекст.
|
|
|
Мнемоника |
|
Описание |
|
|
|
|
|
Сложение |
ADDSS |
|
ADDition Scalar Single precision float point |
ADDPS |
|
ADDition Packed Single precision float point |
|
|
|
|
|
Вычитание |
SUBSS |
|
SUBtracition Scalar Single precision float point |
SUBPS |
|
SUBtraction Packed Single precision float point |
|
|
|
|
|
Умножение |
MULSS |
|
MULtiply Scalar Single precision float point |
MULPS |
|
MULtiply Packed Single precision float point |
|
|
|
|
|
Деление |
DIVSS |
|
DIVide Scalar Single precision float point |
DIVPS |
|
DIVide Packed Single precision float point |
|
|
|
|
|
Извлечение квадратного корня |
SQRTSS |
|
Square RooT Scalar Single precision float point |
SQRTPS |
|
Square RooT Packed Single precision float point |
|
|
|
|
|
Максимальное значение |
MAXSS |
|
MAXimum Scalar Single precision float point |
MAXPS |
|
MAXimum Packed Single precision float point |
|
|
|
|
|
Минимальное значение |
MINSS |
|
MINimum Scalar Single precision float point |
MINPS |
|
MINimum Packed Single precision float point - |
|
|
|
|
|
Обратное значение |
RCPSS |
|
ReCiProcal Scalar Single precision float point |
RCPPS |
|
ReCiProcal Packed Single precision float point |
|
|
|
|
|
Обратное значение квадратного корня |
|
|
|
210
|
|
|
RSQRTSS |
|
Reiprocal SQuare RooT Scalar Single precision float point |
RSQRTPS |
|
Reiprocal SQuare RooT Packed Single precision float point |
|
|
|
Сравнения. В мнемонике суффикс:
SS – скалярный контекст.
PS – параллельный контекст.
Мнемоника |
|
Описание |
|
|
|
|
|
Равенство (equal) |
CMPEQS |
|
CoMPare EQual Scalar Single precision float point |
CMPEQPS |
|
CoMPare EQual Packed Single precision float point |
|
|
|
|
|
Неравенство (not equal) |
CMPNEQS |
|
CoMPare Not EQual Scalar Single precision float point |
CMPNEQPS |
|
CoMPare Not EQual Packed Single precision float point - |
|
|
|
|
|
Меньше чем (less-than) |
CMPLTS |
|
CoMPare Less-Then Scalar Single precision float point |
CMPLTPS |
|
CoMPare Less-Than Packed Single precision float point |
|
|
|
|
|
Не меньше чем (not-less-than) |
CMPNLTS п |
|
CoMPare Not Less-Then Scalar Single precision float point |
CMPNLTPS |
|
CoMPare Not Less-Than Packed Single precision float point |
|
|
|
|
|
Меньше или равно (less-than-or-equal) |
CMPLES |
|
CoMPare Less-then-or-Equal Scalar Single precision float point |
CMPLEPS |
|
CoMPare Less-than-or-Equal Packed Single precision float point |
|
|
|
|
|
Не меньше или равно (not less-than-or-equal) |
CMPNLES |
|
CoMPare Not Less-then-or-Equal Scalar Single precision float point |
CMPNLEPS |
|
CoMPare Not Less-than-or-Equal Packed Single precision float |
|
|
point |
|
|
|
|
|
Упорядоченность (order) |
CMPORDS |
|
CoMPare ORDer Scalar Single precision float point |
CMPORDPS |
|
CoMPare ORDer Packed Single precision float point |
|
|
|
Неупорядоченность (unorder)
CMPUNORDS CoMPare UNORDer Scalar Single precision float point CMPUNORDPS CoMPare UNORDer Packed Single precision float point
Преобразования. В мнемонике суффикс:
211

SI – скалярный контекст.
PI – параллельный контекст.
|
|
|
Мнемоника |
|
Описание |
|
|
|
|
|
Преобразование 32-разрядного числа с плавающей точкой в ко- |
CVTSS2SI |
|
ротком формате в 32-разрядное целое число |
CVTPS2PI |
|
ConVerT Scalar Single precision float point to Scalar signed Int32 |
|
|
ConVersion Two Packed Single precision float point to Packed signed |
|
|
Int32 |
|
|
|
|
|
Преобразование 32-разрядного числа с плавающей точкой в ко- |
|
|
ротком формате в 32-разрядное целое число путем отсечения |
CVTTSS2SI |
|
дробной части |
CVTTPS2PI |
|
ConVerT Trancate Scalar Single precision float point to Scalar signed |
|
|
Int32 |
|
|
ConVersion Trancate Two Packed Single precision float point to |
|
|
Packed signed Int32 |
|
|
|
|
|
Преобразование 32-разрядного числа в целочисленном формате |
|
|
в 32-разрядное число с плавающей точкой в коротком формате. |
CVTSI2SS |
|
ConVerT Scalar signed Int32 to Scalar Single precision float point |
CVTTPS2PI |
|
ConVersion Two Packed signed Int32 to Packed Single precision float |
|
|
point |
|
|
|
Логика. Логические ММХ-команды выполняют поразрядные логические операции над всеми 64 битами своих операндов. Они реализуют логические операции И, ИЛИ, И-НЕ, исключающего ИЛИ:
Мнемоника |
|
Описание |
|
|
|
ANDPS |
|
bit-wise logical AND for Packed Single precision float point |
|
|
Параллельная операция логического И над парами би- |
|
|
тов упакованных чисел с плавающей точкой операнда- |
|
|
источника и операнда-приемника. |
ANDNPS
bit-wise logical AND-Not for Packed Single precision float point
Параллельная операция логического И-НЕ над парами битов упакованных чисел с плавающей точкой операн- да-источника и операнда-приемника
ORPS |
|
bit-wise logical OR for Packed Single precision float point |
212

XORPS
Параллельная операция логического ИЛИ над парами
битов упакованных чисел с плавающей точкой операн- да-источника и операнда-приемника
bit-wise logical eXclusive OR for Packed Single precision float point
Параллельная операция логического Исключающкго ИЛИ над парами битов упакованных чисел с плавающей точкой операнда-источника и операнда-приемника.
Управление состоянием. К этой группе относятся команды, выполняющие загрузку/сохранение регистров состояния и управления:
|
|
|
Мнемоника |
|
Описание |
|
|
|
LDMXCSR ис- |
|
LoaD MXCSR |
точник |
|
Загрузка регистра управления/состояния (MXCSR) содержи- |
|
|
мым 32-разрядной ячейки памяти, которая и является единст- |
|
|
венным операндом. |
|
|
|
STMXCSR при- |
|
STore MXCSR |
емник |
|
Сохранение регистра управления/состояния (MXCSR) в 32- |
|
|
разрядной ячейки памяти, которая и является единственным |
|
|
операндом. |
|
|
|
FXRSTOR ис- |
|
Fp and mmX ReSTORe |
точник |
|
Загрузка предварительно сохраненного состояния сопроцес- |
|
|
сора, ММХ- и SEE-расширения из области памяти размером |
|
|
512 байт. В качестве операнда выступает адрес области па- |
|
|
мяти, который должен быть выровнен по 16-байтовой границе. |
|
|
|
FXSAVE прием- |
|
Fp and mmX SAVE |
ник |
|
Сохранение состояния сопроцессора, ММХ- и SSE- |
|
|
расширения в область памяти размером в 512 байт. В качест- |
|
|
ве операнда выступает адрес области памяти. |
|
|
|
Распаковка данных. XMM-команды распаковки попарно объединяют элементы данных из обоих операндов в более длинные элементы выходного операнда. Этими командами можно пользоваться для увеличения числа значащих разрядов при вычислениях.

 Мнемони-
Мнемони- 
 Описание
Описание
213
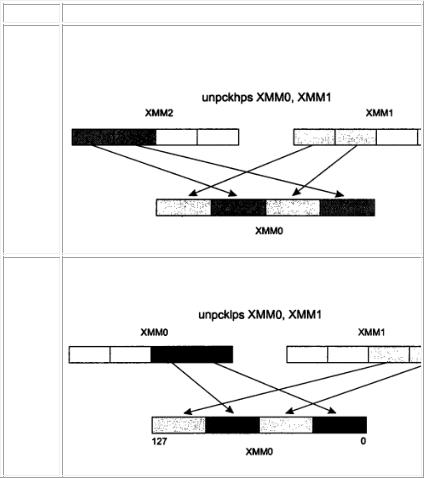
ка
UNPCKH
PS
UNPaCK High Packed Single precision float point data
Параллельное перемещение старших двойных слов из операндаисточника и операнда-приемника в операнд-приемник.Пример:
UNPCKLP UNPaCK Low Packed Single precision float point data
SПараллельное перемещение младших двойных слов из операндаисточника и операнда-приемника в операнд-приемник. Пример:
214
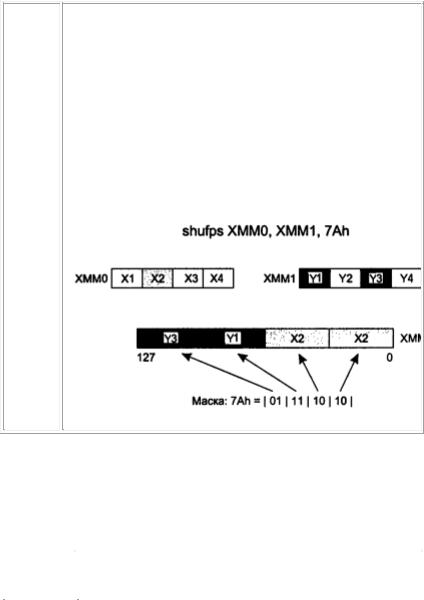
SHUFPS UNPaCK Low Packed Single precision float point data
Параллельная перестановка 32-разрядных упакованных операндов в соответствии с заданной маской. Команда имеет три операнда: входной, выходной и операнд-маску.
Маска представляет собой непосредственное 8-разрядное значение, задающее порядок перестановки операндов. Каждая пара битов маски определяет номер упакованного 32-разрядного операнда в приемнике или источнике, который должен помещаться в операндприемник. При этом порядок размещения 32-разрядных операндов таков: младшие 4 бита маски указывают номера двух упакованных чисел приемника, которые становятся младшими упакованными значениями результата, а старшие 4 бита — номера упакованных чисел источника, которые становятся старшими упакованными значениями результата. Пример:
Управление кэшированием. Необходимость управления кэшированием вызвана тем, что большинство мультимедийных приложений оперируют большими объемами данных, при этом может случиться, что данные, загруженные в кэш, никогда не понадобятся. Чтобы оптимизировать работу кэша, в систему команд SSE-расширения и были включены команды управления кэшем.
|
|
|
Мнемоника |
|
Описание |
|
|
|
MASKMOVQ |
|
MASK MOVe Quadword |
mm1, mm2 |
|
Выборочная запись байтов в память из источника (ММХ-регистр |
|
|
mm1) по маске. Маска – это знаковые биты 8 байтов MMX- |
|
|
|
|
215 |
|
MOVNTQ
MOVNTDQ
MOVNTPD
MOVNTPS
регистра mm2. Последовательно проверяются знаковые биты
всех 8 байтов, и если какой-то из этих битов равен 1, то соответствующий байт источника копируется в область памяти, начальный адрес которой содержится в регистрах DS:DI/EDI. Если знаковый бит равен нулю, то соответствующий байт в приемнике будет нулевым.
MOVe using Non-Temporal of Quadword
Сохранение учетверенного слова из ХММ-регистра в памяти без использования кэша.
MOVe using Non-Temporal of Double Quadword
Сохранение двойного учетверенного слова из ХММ-регистра в памяти без использования кэша.
MOVe Non Temporal aligned Packed Double precision float point data
Запись в память, минуя кэш, упакованных чисел с плавающей точкой c удвоенной точностью. Операндом-источником здесь выступает ХММ-регистр, а операндом-приемником — 128разрядная ячейка памяти, адрес которой должен быть выровнен по 16-байтовой границе.
MOVe Non-Temporal Packed Single precision float point
Запись в память, минуя кэш, упакованных чисел с плавающей точкой в коротком формате. Операндом-источником здесь выступает ХММ-регистр, а операндом-приемником — 128-разрядная ячейка памяти, адрес которой должен быть выровнен по 16байтовой границе.
Дополнительные команды. Сейчас мы рассмотрим еще одну группу команд, которые трудно отнести к какому-либо определенному типу, но которые являются весьма полезными при разработке программ.
Перераспределение.
|
|
|
Мнемоника |
|
Описание |
|
|
|
SHUFPS приемник, ис- |
|
Packed AveraGe Bytes |
точник |
|
Попарно вычисляет средние значения упакованных |
|
|
чисел, представленных байтами. Значения операн- |
|
|
дов интерпретируются как беззнаковые целые числа. |
|
|
В качестве источника могут выступать ММХ-регистр |
|
|
|
216
UNPCKHPS приемник,
источник
UNPCKLPS приемник,
источник
или 64-разрядная ячейка памяти, приемником служит
один из ММХ-регистров.
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Перераспределение.
Команда |
|
Описание |
SHUFPS приемник, ис-
точник
UNPCKHPS приемник,
источник
UNPCKLPS приемник,
источник
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операн-
217
дов интерпретируются как беззнаковые целые числа.
В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Управление состоянием.
Команда |
|
Описание |
IDMXCSR приемник,
источник
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
STMXCSR приемник,
источник
FXSTOR приемник, ис-
точник
FXSAFE приемник, ис-
точник
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
Packed AveraGe Bytes
Попарно вычисляет средние значения упакованных чисел, представленных байтами. Значения операндов интерпретируются как беззнаковые целые числа. В качестве источника могут выступать ММХ-регистр или 64-разрядная ячейка памяти, приемником служит один из ММХ-регистров.
218