

5.2. Нормалізація і стандартизація вихідних значень
Оскільки
значення векторів
![]() у загальному випадку різнотипні, то їх
необхідно привести до єдиної шкали. Це
потрібно для адекватного застосування
математичних методів і комп'ютерних
розрахунків при пов'язаних із великими
і малими абсолютними величинами
обчисленнях, а також для того, аби
встановити відповідність між кількісними
та якісними значеннями.
у загальному випадку різнотипні, то їх
необхідно привести до єдиної шкали. Це
потрібно для адекватного застосування
математичних методів і комп'ютерних
розрахунків при пов'язаних із великими
і малими абсолютними величинами
обчисленнях, а також для того, аби
встановити відповідність між кількісними
та якісними значеннями.
Наприклад, вкрай важко відповісти на питання у стилі: „Що більш природно для людини в 25 років: мати 60 кг ваги або 165 см росту?", оскільки згадані числові показники відносяться не просто до різних вимірів, а ще й вимірюються на різних шкалах. A тим часом відповіді на питання подібного типу і їх комбінації важливі при оцінці схильності людини до певних захворювань.
Важливим кроком, який дає можливість порівняння, є нормування. Основними формулами, що реалізовують нормування і стандартизацію, є такі:
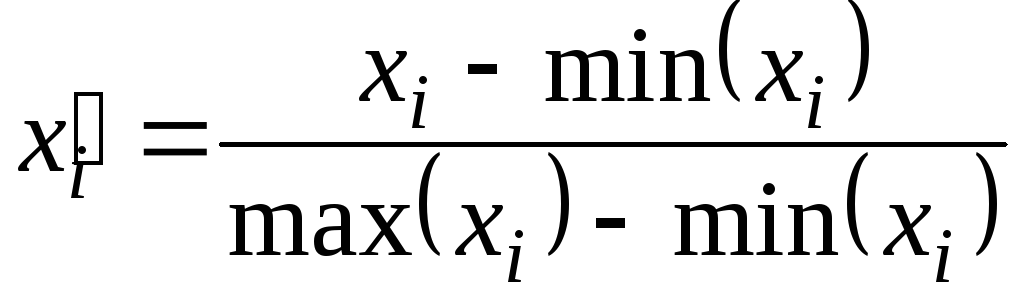 ; (5.3)
; (5.3)
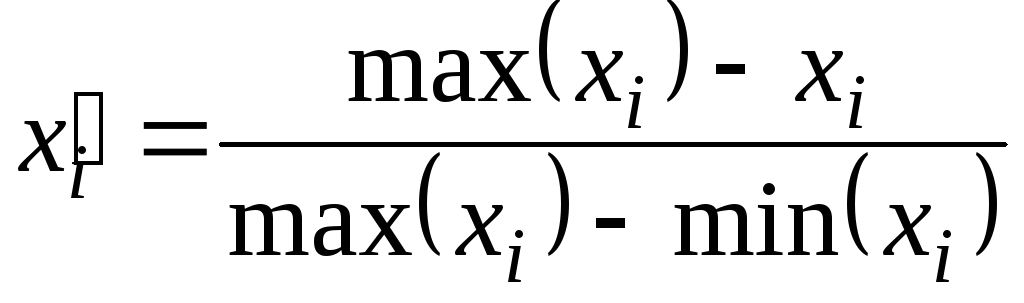 ; (5.4)
; (5.4)
![]() ; (5.5)
; (5.5)
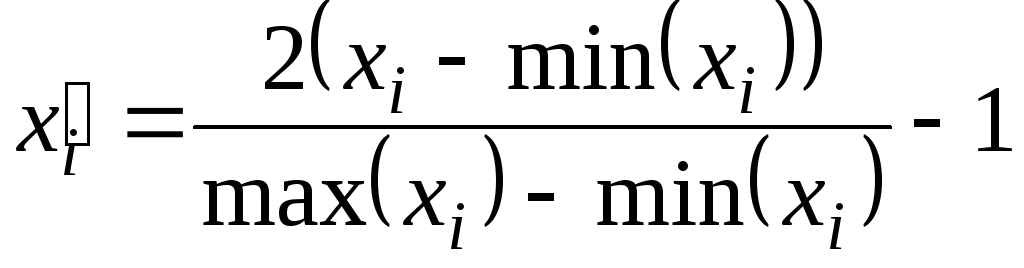 ; (5.6)
; (5.6)
![]() . (5.7)
. (5.7)
Дамо їм коротку характеристику.
Перетворення (5.3). Область значень - [0,1]. Рекомендується використовувати, якщо значення початкових даних рівномірно заповнюють область дослідження. Для деяких методів прогнозування формула неефективна у випадку рівності значень нулю або їх зосередження біля кінців відрізка [0,1].
Перетворення (5.4). Аналогічне першому, але дозволяє зворотно пропорційно розвернути шкалу, що зручно у випадках, коли більшість характеристик мають максимізуватися, а дана характеристика - мінімізуватися. Недоліки ті ж самі.
Перетворення
(5.5). Відрізняється тим, що отримані в
результаті його застосування значення
є безрозмірними, знаходяться з дисперсією
та СКВ, рівними 1, на відрізку
![]() переважно в околі нуля. У перетворенні
використовується
переважно в околі нуля. У перетворенні
використовується![]() - вибіркове середнє значення
- вибіркове середнє значення![]() тої
змінної,
тої
змінної,![]() - її ж вибіркове середньоквадратичне
відхилення. Для використання такого
перетворення, зокрема при навчанні
нейронних мереж, необхідно застосовувати
додаткові перетворення, наприклад
- її ж вибіркове середньоквадратичне
відхилення. Для використання такого
перетворення, зокрема при навчанні
нейронних мереж, необхідно застосовувати
додаткові перетворення, наприклад
 (5.8)
(5.8)
Останнє
перетворення, окрім належності значень
інтервалу
![]() ,
гарантує також більш рівномірний
розподіл значень.
,
гарантує також більш рівномірний
розподіл значень.
Перетворення
(5.6). Область значень
![]() .
Формула зручна для використання при
прогнозуванні із застосуванням нейронних
мереж, в яких активаційною функцією є
гіперболічний тангенс. Має всі ті ж
переваги й недоліки, що і перетворення
(5.3) та (5.4).
.
Формула зручна для використання при
прогнозуванні із застосуванням нейронних
мереж, в яких активаційною функцією є
гіперболічний тангенс. Має всі ті ж
переваги й недоліки, що і перетворення
(5.3) та (5.4).
Перетворення
(5.7). Область значень
![]() .
Використовується рідко, здебільшого
для значного підсилення реакції на
зміни значень в околі нуля. Функція є
допоміжною, вона не позбавляє розмірності
значення факторів.
.
Використовується рідко, здебільшого
для значного підсилення реакції на
зміни значень в околі нуля. Функція є
допоміжною, вона не позбавляє розмірності
значення факторів.
У загальному випадку вважатимемо, що використання функцій нормування веде до відображення вхідних значень в одиничний гіперкуб. Якщо вони будуть нерівномірно розподілені і зосереджені в невеликих гіперколах, то такі дані є малоінформативними і прогнозування буде неточним (приклад - рис. 5.1).
Найбільшу інформативність (у сенсі отримання більш точного прогнозу) мають дані з рівномірним розподілом (відомо, що вони мають найбільшу ентропію) (приклад – рис. 5.2). Таким чином, однією із головних задач після одержання безрозмірних величин і нормалізації буде максимізація ентропії.
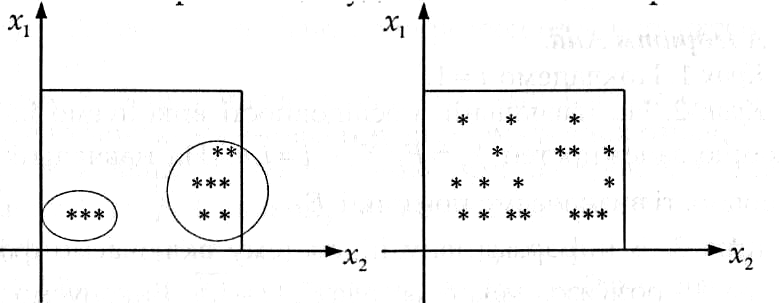
Рис. 5.1 - Неінформативні дані Рис. 5.2 - Інформативні дані