

Интервал
Иногда исходных частных первичных данных, которые подлежат статистической обработке, бывает довольно много, и они требуют проведения огромного количества элементарных арифметических операций. Для того чтобы сократить их число и вместе с тем сохранить нужную точность расчетов, иногда прибегают к замене исходной выборки частных эмпирических данных на интервалы.
Интервалом называется группа упорядоченных по величине значений признака, заменяемая в процессе расчетов средним значением.
Пример. Представим следующий ряд частных признаков: 0, 1, 1, 2, 2, 3, 3, 3, 4, 4, 5, 5, 5, 5, 6, 6, 6, 7, 7, 8, 8, 8, 9, 9, 9, 10, 10, 11, 11, 11. Этот ряд включает в себя 30 значений.
Разобьем представленный ряд на шесть подгрупп по пять признаков в каждом.
Первая подгруппа включит в себя первые пять цифр,
вторая — следующие пять и т.д.
Вычислим средние значения для каждой из пяти образованных подгрупп чисел. Они соответственно будут равны 1,2; 3,4; 5,2; 6,8; 8,6; 10,6.
Таким образом, нам удалось свести исходный ряд, включающий тридцать значений, к ряду, содержащему всего шесть значений и представленному средними величинами. Это и будет интервальный ряд, а проведенная процедура — разделением исходного ряда на интервалы.
Теперь все статистические расчеты мы можем производить не с исходным рядом признаков, а с полученным интервальным рядом, и результаты в равной степени будут относиться к исходному ряду. Однако число производимых в ходе расчетов элементарных арифметических операций будет гораздо меньше, чем количество тех операций, которые с этой же целью пришлось бы проделать в отношении исходного ряда признаков.
На практике, составляя интервальный ряд, рекомендуется руководствоваться следующим правилом: если в исходном ряду признаков больше чем тридцать, то этот ряд целесообразно разделить на пять-шесть интервалов и в дальнейшем работать только с ними.
Для проверки сказанного проведем пробное вычисление среднего значения по приведенному выше ряду, составляющему тридцать чисел, и по ряду, включающему только интервальные средние значения. Полученные цифры с точностью до двух знаков после запятой будут соответственно равны 5,97 и 5,97, т.е. являются одинаковыми.
Тема 4. Основные понятия, используемые в математической обработке психологических данных
1. Распределение признака. Параметры распределения
Распределением признака называется закономерность встречаемости разных его значений
В психологических исследованиях чаще всего ссылаются на нормальное распределение.
Нормальное распределение характеризуется тем, что крайние значения признака в нем встречаются достаточно редко, а значения, близкие к средней величине - достаточно часто. Нормальным такое распределение называется потому, что оно очень часто встречалось в естественно-научных исследованиях и казалось "нормой" всякого массового случайного проявления признаков. Это распределение следует закону, открытому тремя учеными в разное время: Муавром в 1733 г. в Англии, Гауссом в 1809 г. в Германии и Лапласом в 1812 г. во Франции. График нормального распределения представляет собой привычную глазу психолога-исследователя так называемую колоколообразную кривую (см, напр., Рис.1).
Параметры распределения - это его числовые характеристики, указывающие, где "в среднем" располагаются значения признака, насколько эти значения изменчивы и наблюдается ли преимущественное появление определенных значений признака. Наиболее практически важными параметрами являются математическое ожидание, дисперсия, показатели асимметрии и эксцесса.
В реальных психологических исследованиях мы оперируем не параметрами, а их приближенными значениями, так называемыми оценками параметров. Это объясняется ограниченностью обследованных выборок. Чем больше выборка, тем ближе может быть оценка параметра к его истинному значению. В дальнейшем, говоря о параметрах, мы будем иметь в виду юс оценки.
Среднее арифметическое (оценка математического ожидания) вычисляется по формуле:
![]()

где x i - каждое наблюдаемое значение признака;
i - индекс, указывающий на порядковый номер данного значения признака;
n - количество наблюдений;
∑ - знак суммирования.
Оценка дисперсии определяется по формуле:

где Xi - каждое наблюдаемое значение признака;
x - среднее арифметическое значение признака;
п - количество наблюдений.
Величина, представляющая собой квадратный корень из несмещенной оценки дисперсии (S), называется стандартным отклонением или средним квадратническим отклонением. Для большинства исследователей привычно обозначать эту величину греческой буквой δ (сигма), а не S. На самом деле, δ - это стандартное отклонение в генеральной совокупности, a S - несмещенная оценка этого параметра в исследованной выборке. Но, поскольку S - лучшая оценка δ (Fisher R.A., 1938), эту оценку стали часто обозначать уже не как S, а как δ:
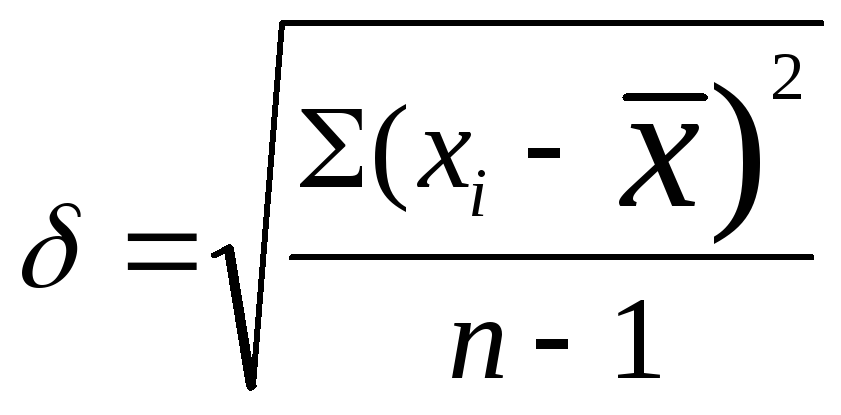
В тех случаях, когда какие-нибудь причины благоприятствуют более частому появлению значений, которые выше или, наоборот, ниже среднего, образуются асимметричные распределения. При левосторонней, или положительной, асимметрии в распределении чаще встречаются более низкие значения признака, а при правосторонней, или отрицательной - более высокие (см. Рис. 2).
Показатель асимметрии (А) вычисляется по формуле:

Для симметричных распределений А=0.

В тех случаях, когда какие-либо причины способствуют преимущественному появлению средних или близких к средним значений, образуется распределение с положительным эксцессом. Если же в распределении преобладают крайние значения, причем одновременно и более низкие, и более высокие, то такое распределение характеризуется отрицательным эксцессом и в центре распределения может образоваться впадина, превращающая его в двухвершинное (см. Рис. 3).
Показатель эксцесса (Е) определяется по формуле:


Рис. 3. Эксцесс: а) положительный; б) отрицательный.
В распределениях с нормальной выпуклостью Е=0.
Параметры
распределения оказывается возможным
определить только
по отношению к данным, представленным
по крайней мере в интервальной
шкале. Как мы убедились ранее, физические
шкалы длин, времени,
углов являются интервальными шкалами,
и поэтому к ним применимы
способы расчета оценок параметров, по
крайней мере, с формальной
точки зрения. Параметры распределения
не учитывают  истинной
психологической неравномерности
секунд, миллиметров и других физических
единиц измерения.
истинной
психологической неравномерности
секунд, миллиметров и других физических
единиц измерения.
На Рис. 4. Приведен график нормального распределения с параметрами μ и σ.

Рис. 4. График нормального распределения с параметрами μ и σ.
Из графика видно «правило 3σ».
Действительно в интервал (-3σ, +3σ) попадает 99,7 % выборки. Иными словами, то, что выходит за пределы указанного интервала нами может не рассматриваться.
На практике психолог-исследователь может рассчитывать параметры любого распределения, если единицы, которые он использовал при измерении, признаются разумными в научном сообществе.