

Распределенные базы данных (Дейт «Введение в системы баз данных» 8-е издание)
Введение
Предварительные сведения
Двенадцать основных целей
Проблемы распределенных систем
Системы "клиент/сервер"
Независимость от СУБД
Средства SQL
Резюме Упражнения Списо* литературы
21.1. Введение
В конце главы 2 уже затрагивалась тема распределенных баз данных. При этом было указано: "Полная поддержка распределенных баз данных означает, что отдельное приложение может «прозрачно» обрабатывать данные, распределенные между множеством различных баз данных, управление которыми осуществляют разные СУБД, работающие на соединенных коммуникационными сетями компьютерах разных типов с различными операционными системами. Здесь понятие «прозрачно» означает, что приложение выполняет обработку данных с логической точки зрения так, как будто управление данными полностью осуществляется одной СУБД, работающей на единственном компьютере". В этой главе мы поговорим о распределенных базах данных подробнее, а именно — более точно определим, что такое распределенная база данных, почему такие базы данных играют все более важную роль (достаточно лишь подумать о современных масштабах развития World Wide Web — см. главу 27) и какие технические проблемы существуют в области распределенных баз данных.
Кроме того, в главе 2 обсуждались системы "клиент/сервер", которые можно рассматривать как простой частный случай распределенных систем вообще. Системы "клиент/ сервер" будут рассмотрены в разделе 21.5.
Общий план данной главы приведен в конце следующего раздела.
21.2. Предварительные сведения
Начнем с рабочих определений, приведенных ниже, которые на этом этапе неизбежно будут не совсем точны.
• Система распределенных баз данных состоит из набора узлов (site), связанных коммуникационной сетью, в которой:
а) каждый узел — это полноценная СУБД сама по себе, но
б) узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находят ся на его собственном узле.
Из этого определения следует, что так называемая распределенная база донных в действительности представляет собой виртуальную базу данных, компоненты которой физически хранятся в нескольких различных реальных, базах данных на нескольких различных узлах (в сущности, являясь логическим объединением этих реальных баз данных). Пример подобной структуры показан на рис. 21.1.
Еше раз отметим, что каждый узея сам по себе является системой баз данных. Иначе говоря, на каждом узле есть собственные локальные реальные базы данных, собственные локальные пользователи, собственные локальные СУБД и программное обеспечение управления транзакциями (включая собственное программное обеспечение блокировки, ведений журналов, восстановления и т.д.) и собственный локальный диспетчер передачи данных. В частности, любой пользователь может выполнять операции над данными на своем локальном узле точно так же, как если бы этот узел вовсе не входил в распределенную систему (по крайней мере, так должно быть)^Всю распределенную систему баз данных можно рассматривать как некоторое партнерство между отдельными локальными СУБД на отдельных локальных узлах. Новый программный компонент на каждом узле — логическое расширение локальной СУБД— предоставляет необходимые функциональные возможности для организации подобного партнерства. Именно этот компонент вместе с существующими СУБД составляет то, что обычно называется распределенной системой управления базами данных (РСУБД).
Чаше всего предполагается, что узлы разделены физически (а возможно, и территориально, как показано на рис. 21.1), хотя в действительности достаточно того, чтобы они были разделены логически. Два узла могут даже сосуществовать на одном и том же физическом компьютере (в особенности на начальном этапе тестирования). Главная цель создания распределенных систем со временем изменялась. В ранних исследованиях в основном предполагалась территориальная распределенность, но в большинстве первых коммерческих реализаций предполагалось локальное распределение, когда несколько узлов размешалось в одном здании и соединялось с помощью локальной сети (ЛВС). Однако позже стремительное распространение глобальных сетей (ГВС) снова пробудило интерес к использованию территориального распределения. В любом случае это не имеет большого значения с точки зрения системы баз данных — решать в основном требуется одни и те же технические (связанные с базами данных) проблемы. Поэтому в настоящей главе мы можем обоснованно рассматривать представленную на рис 21.1 систему в качестве типичного представителя распределенных систем.
Примечание. Для упрощения дальнейшего изложения будем предполагать, что система однородна, если нет иного соответствующего явного указания. Система однородна в том смысле, что на каждом узле работает некоторая копия одной и той же СУБД. Будем
называть это предположением о строгой однородности. Возможности и особенности неоднородных систем будут проанализированы в разделе21.6.
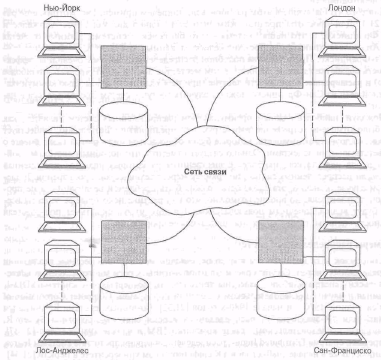
Рис. 21.1. Пример типичной системы распределенной базы данных
Преимущества
Зачем нужны распределенные базы данных? Основная причина заключается в том, что сами предприятия обычно уже распределены, по крайней мере, логически, т.е. разбиты на подразделения , отделы, рабочие группы и т.д. Очень часто они распределены и физи-
зически, т.е. разделены на отдельно расположенные заводы, фабрики, лаборатории и т.д. Из этого следует, что данные также обычно распределены, поскольку каждая организационная единица на предприятии создает и обрабатывает собственные данные, относящиеся к ее деятельности. Таким образом, информация предприятия разбивается на отдельные автономные части, которые иногда называют островами информации. А распределенная система обеспечивает мосты для их соединения в единое целое. Иначе говоря, распределенная система позволяет структуре базы данных отображать структуру
предприятия — локальные данные могут храниться локально, в соответствии с логической принадлежностью, тогда как к удаленным данным доступ может осуществляться по мере необходимости.
Для того чтобы лучше в этом разобраться, приведем пример, Рассмотрим еше раз рис. 21.1. Для простоты предположим, что есть только два узла, Лос-Анджелес и Сан-Франциско, и что наша система— это банковская система. Данные о счетах Лос-Анджелеса хранятся в Лос-Анджелесе, а данные о счетах Сан-Франциско — в Сан-Франциско. Преимущества подобной распределенной системы очевидны: эффективность обработки (данные хранятся в том месте, где доступ к ним требуется наиболее часто) и расширенные возможности доступа (при необходимости с помошью коммуникационной сети из Сан-Франциско можно получить доступ к счетам Лос-Анджелеса и наоборот).
Пожалуй, наиболее важным преимуществом распределенных систем является, как уже было отмечено, отражение ими структуры предприятия. Безусловно, существует множество других преимуществ, которые будут обсуждаться ниже в этой главе вместе с соответствующими аспектами. Однако следует отметить, что подобным системам свойствен и ряд недостатков, наиболее существенным из которых является повышенная сложность распределенных систем, по крайней мере, с технической точки зрения. В идеальном случае, конечно, эта сложность должна быть проблемой реализации, а не проблемой пользователя, но вполне возможно, что на практике некоторые ее аспекты все-таки будут видны конечным пользователям. Для того чтобы скрыть от пользователя сложность системы, требуется весьма тщательная ее проработка.
Примеры распределенных систем
Для ссылок в дальнейшем мы кратко перечислим некоторые известные реализации распределенных систем. Сначала рассмотрим прототипы. Среди многочисленных исследовательских систем наиболее известны три системы. Во-первых, это система SDD-I, созданная в научно-исследовательском отделении корпорации Computer Corporation of America в конце 1970-х и начале 1980-х годов [21.32]. Во-вторых, система R* (читается "R-star" или "R-звездочка")1, распределенная версия системы-прототипа System R, созданная в исследовательском отделе компании IBM в начале 1980-х годов [21.37]. И в-третьих, система Distributed Ingres, распределенная версия прототипа системы Ingres, созданная также в начале 1980-х годов в Калифорнийском университете в Беркли [21.34].
Что касается коммерческих реализаций, то большинство современных продуктов SQL включает определенную поддержку распределенных баз данных, но, безусловно, с разными уровнями функциональных возможностей. Наиболее известные среди них следующие:
1 В данном обозначении звездочка — это так называемый "оператор Клина" (Kleene), а конструкция !R*" означает "от нуля или больше экземпляров СУБД | System] R".
Ingres/Star (распределенный компонент базы данных СУБД Ingres), версия для распределенных баз данных СУБД Oracle и средства распределения данных для СУБД DB2.
Примечание. Разработчики программных продуктов часто выпускают новые версии своих продуктов под другими названиями, поэтому автор не может гарантировать, что перечисленные выше названия (а в некоторых случаях даже продукты) в настоящее время все еще продолжают использоваться. Кроме того, этот список продуктов и прототипов
ни в коем случае не следует считать исчерпывающим; автор просто хотел упомянуть системы, которые по тем или иным причинам оказывали или оказывают определенное влияние на развитие данной области либо представляют интерес благодаря своей внутренней структуре. Но, по крайней мере, следует указать, что все перечисленные здесь системы, как прототипы, так и продукты, относятся к категории реляционных систем (в частности, во всех них поддерживается язык SQL). В действительности, существует несколько конкретных причин, по которым для успешной реализации распределенная система должна быть реляционной. Реляционная технология — это необходимое условие для эффективной реализации распределенной технологии (15.6). Некоторые причины
Фундаментальный принцип
Теперь сформулируем утверждение, которое может рассматриваться как фундаментальный принцип создания распределенных баз данных [21. В].
• Для пользователя распределенная система должна выглядеть так же, как нерйспре-
Другими словами, пользователи распределенной системы должны иметь возможность ных систем относятся или должны относиться к внутренним проблемам (или проблемам
Примечание. Понятие пользователи в предыдущем абзаце относится к таким пользователям (конечным пользователям или прикладным программистам), которые выполняют операции обработки^данных. Все операции манипулирования данными должны оставаться логически неизменными. Но для операций определения данных, напротив, в распреде-
чтобы пользователь (возможно, администратор базы данных) на узлех имел возмож-
менты, которые будут храниться на узлах Y и Z (см. обсуждение фрагментации в следующем разделе).
Сформулированный выше фундаментальный принцип имеет следствием определен-
будет рассмотрена в следующем разделе. Для последующих ссылок перечислим эти шли.
Локальная независимость.
Отсутствие зависимости от центрального узла.
Непрерывное функционирование.
Независимость от расположения.
Независимость от фрагментации.
Независимость от репликации.
Обработка распределенных запросов.
Управление распределенными транзакциями.
2 "Правила" — это термин, используемый встатье, в которой эти правила впервые были представлены [21.13]. Указанный "фундаментальный принцип" был назван "Правилом ноль". Однако на самом деле здесь более уместен термин "цел»" — слово "правила" звучит слишком категорично. В этой главе будет использоваться более умеренное название — "цели".
9. Аппаратная независимость.
Независимость от операционной системы.
Независимость от сети.
Независимость от типа СУБД.
Обратите внимание на то, что не все эти цели независимы одна от другой. Кроме того, они не исчерпывающие и не все одинаково важны (разные пользователи могут придавать различное значение разным целям в различных средах, и, кроме того, некоторые из этих целей могут быть вообще неприменимы в некоторых ситуациях). Но данные цели полезны как основа для понимания самой распределенной технологии и как общая схема описания функциональных возможностей конкретных распределенных систем. Поэтому мы будем использовать список этих целей как организационный принцип для большей части данной главы. В разделе 21.3 кратко обсуждается каждая из целей. В разделе 21.4 некоторые конкретные вопросы рассматриваются более подробно, а в разделе 21.5, как уже отмечалось, приводится обсуждение систем "клиент/сервер". В разделе 21.6 мы детально обсудим некоторые конкретные проблемы, связанные с достижением независимости от СУБД. Наконец, раздел 21.7 посвящен поддержке языка SQL, а в разделе 21.8 содержится резюме и представлено несколько заключительных замечаний.
Рассмотрим последний дополнительный вопрос в этом разделе. Важно отличать истинные обобщенные системы распределенных баз данных от систем, которые предоставляют просто удаленный доступ к данным (кстати, это все, что на самом деле предоставляет пользователям система "клиент/сервер"). В системах удаленного доступа к данным конечный пользователь может оперировать данными на удаленном узле или даже данными на нескольких удаленных узлах одновременно, но е-^у будут видны все "швы". Пользователю, несомненно, в той или иной мере будет известно, что данные расположены не локально, и поэтому он должен действовать с учетом этого. В истинной системе распределенных баз данных, напротив, все швы скрыты. (Большая часть этой главы посвящена выяснению вопроса, что же означает выражение "все швы скрыты".) Далее термин распределенная система будет означать именно истинную обобщенную систему распределенной базы данных (в противоположность обычной системе удаленного доступа к данным), если только явно не будет указано иное.