

7.3 Последовательные файлы
Последовательный файл характеризуется последовательным размещением его физических записей, или блоков, в порядке их поступления в файл и доступом к блокам файла в порядке их физического расположения на соответствующем носители данных. Типичным устройством внешней памяти, на котором организуются последовательные файлы, является НМЛ, для которого наиболее естественен последовательный способ обработки (записи, чтения и поиска) данных. Однако последовательные файлы можно создавать и обрабатывать и на запоминающих устройствах прямого доступа, а также на устройствах последовательного действия, которые существенно отличаются от НМЛ устройствах чтения перфокарт и перфолент, устройствах перфорации карт и лент, печатающих устройствах и т.п.
Логическая структура последовательного файла представлена на рис. 7.2. Для каждой записи файла, кроме последней, имеется единственная следующая запись, которая на типичном последовательном носители данных (таком, как МЛ) расположена физически вслед за предшествующей ей записью. В рассматриваемом типе файла, например, в общем случае обращение к записи i становится возможным лишь после обращения к записи i-1. Значит, если целью обращения к файлу является запись i, то при i>1 предварительно необходимо пропустить i-1 предыдущих записей файла.

Операции над последовательными файлами имеют особенности в зависимости от типа внешних устройств, на которых создаются последовательные файлы. Основные операции доступа к последовательному файлу приведены в таблице 7.1.
Таблица 7.1
|
Операции при доступе к файлу |
Тип устройства | ||||
|
НМЛ |
ЗУПД |
Чтения ПК |
Перфорации |
Печати | |
|
Чтение блока |
Да |
Да |
Да |
Нет |
Нет |
|
Чтение блока в обратном направлении |
Да |
Нет |
Нет |
Нет |
Нет |
|
Запись блока |
Да |
Да |
Нет |
Да |
Да |
|
Пропуск блока |
Да |
Да |
* |
* |
* |
|
Возврат на один блок |
Да |
Да |
Нет |
Нет |
Нет |
|
Пропуск файла |
Да |
Да |
* |
* |
* |
|
Возврат на один файл |
Да |
Да |
Нет |
Нет |
Нет |
|
Изменение блока на месте |
Нет |
Да |
Нет |
Нет |
Нет |
|
Определение текущей позиции файла |
Да |
Да |
Нет |
Нет |
Нет |
|
Установка в заданную позицию |
Да |
Да |
Нет |
Нет |
Нет |
7.4 Библиотечные файлы
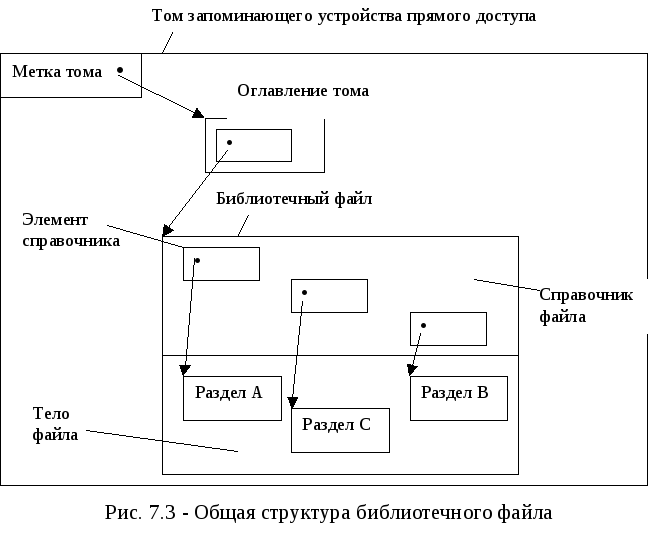
Библиотечный, или расчлененный, файл представляет собой совокупность последовательных подфайлов, расположенных в произвольном порядке в той области ЗУПД, которая выделена для файла при его создании. Каждый подфайл библиотечного файла называется разделом. Для доступа к разделам библиотечный файл содержит справочник, который располагается в самом файле (как правило, в начале файла). В справочнике имеется по одному элементу для каждого из разделов файла. Общая структура библиотечного файла приведена на рис. 7.3., из которого видно, что разделы могут быть отделены друг от друга незанятыми участками памяти.
7.5 Файлы прямого доступа
Файл прямого доступа может создаваться только на ЗУПД. Такой файл обычно не нуждается в справочнике. Создав файл прямого доступа и выделив необходимую для него область памяти на ЗУПД, можно записывать блоки в любые места файла. Порядок чтения блоков также может быть произвольным. Например, можно прочитать любой пустой блок, т.е. блок, в который еще ничего не записывалось после создания файла. Вследствие произвольности выбора мест для записи и чтения блоков файлы прямого доступа нередко называют также файлами с произвольным доступомили файлами с произвольной организацией.
При обработке файла прямого доступа важно правильно выбрать способ адресации блоков при записи и чтении данных. В системах обработки данных чаще всего применяются следующие способы адресации блоков: прямая адресация; табличная адресация; рандомизация или косвенная адресация.
В случае прямой адресациипрограмма обработки файла записывает или читает содержимое блока, используя физический адрес блока на ЗУПД. Физический адрес блока может задаваться в абсолютной или относительной формах. Абсолютная форма означает указание номеров цилиндра, дорожки и блока. Относительная форма соответствует указанию адреса в виде номера блока. Предполагается, что все блоки области ЗУПД, выделенной для файла, пронумерованы с самого начала в порядке их физического расположения на ЗУПД. По заданному номеру блока, зная местоположение файла на ЗУПД, операционная система автоматически вычисляет абсолютный физический адрес блока.
Форма абсолютного физического адреса менее удобна, чем относительная форма, так как для этого программист должен знать точное местоположение файла на ЗУПД и особенности формирования физических адресов для конкретного ЗУПД. Изменение местоположения файла на ЗУПД требует соответствующего изменения программы обработки файла, что не всегда приемлемо.
В способе табличной адресациипри первоначальной загрузке файла прямого доступа в основной памяти формируетсяиндексная таблица, в которой имеется по одному элементу для каждого записанного блока файла. Элемент индексной таблицы содержит значение ключа и физический адрес блока, соответствующего данному элементу. При каждом последующем обращении к блоку с целью его чтения или модификации сначала просматривается индексная таблица для нахождения в ней элемента, который содержит значение ключа обрабатываемого блока. Как только такой элемент находится, из его второго поля извлекается физический адрес блока и используется программой для обращения к заданному блоку в файле. Существенные недостатки табличной адресации – необходимость дополнительных расходов памяти для индексной таблицы, которые могут стать непомерно большими, а также увеличение времени доступа к файлу на величину, равную длительности поиска в индексной таблице. В конце сеанса работы с файлом может возникнуть необходимость сохранить индексную таблицу во внешней памяти, чтобы учесть возникшие в ней изменения.
Наиболее общий способ обращения к блокам файла прямого доступа – способ обращения с использованием рандомизации, или косвенной адресации. Основная идея рандомизации состоит в установлении определенной связи между значением ключа блока и местоположением, или адресом, этого блока в файле. В отличие от табличного способа, при рандомизации зависимость между ключом и адресом блока должна устанавливаться алгоритмическим, или процедурным, путем и не должна требовать никакой таблицы соответствия. Для дальнейшего изучения способа рандомизации нам потребуются такие понятия, как "адресное пространство файла", "пространство ключей" и "коэффициент загрузки файла".
Адресное пространство файла– множество адресов его блоков. Мощность такого множества равна числу блоков в файле, считая и "пустые" блоки, т.е. блоки, в которые ни разу не были записаны данные после создания файла.
Пространство ключей– множество возможных значений ключей. Множество же значений, которые в действительности принимают ключи, обычно является подмножеством пространства ключей. Это подмножество будем называть в дальнейшем множеством фактических значений ключей. В реальных задачах мощность множества фактических значений ключей, как правило, существенно меньше мощности множества возможных значений ключей.
Коэффициент загрузки файла– отношение числа занятых блоков к общему числу блоков в файле. В процессе использования файла коэффициент загрузки не остается постоянным. Вначале, когда в файл не записан ни один блок данных, этот коэффициент равен нулю, а с течением времени, по мере добавления в файл все новых и новых блоков, он может приблизиться к единице.
Приступая к разъяснению способа рандомизации, представим себе ситуацию, когда ключи имеют последовательные значения без пропусков, длина и формат каждого ключа блока совпадают с длиной и форматом адреса блока в файле, а число значений ключей не превышает числа блоков в файле. При выполнении перечисленных условий значения ключей могут быть непосредственно использованы для адресации блоков в файле. Этот случай соответствует методу самоиндексированияпри адресации блоков в файле прямого доступа и по существу является разновидностью способа прямой адресации. Метод самоиндексирования весьма прост, но, к сожалению, использовать его можно далеко не всегда, так как в практических задачах первые два условия его применимости выполняются весьма редко.
Типичная ситуация, когда значения ключей распределены нерегулярно, с большими пропусками, в некотором диапазоне, причем длина и формат ключа не соответствуют длине и формату адреса блока, в каком бы виде (абсолютном или относительном) этот адрес не задавался. В такой ситуации можно попытаться создать файл с таким числом блоков в нем, чтобы было по одному блоку на каждое значение ключа в заданном диапазоне значений. Но так как число фактических значений ключей в этом диапазоне, как правило, гораздо меньше числа возможных значений, то большое количество блоков файла не будет никогда использовано, т.е. коэффициент загрузки файла всегда будет мал. Более того, диапазон возможных значений ключей может быть настолько широк, что реализация файла с учетом каждого возможного значения ключа может оказаться практически затруднительной или даже невозможной.
В способе рандомизации этот недостаток устраняется следующим путем. На основе информации о множестве фактических значений ключей создается файл прямого доступа с таким числом блоков, которое немного большемощности множества фактических значений ключей. Затем выбирается подходящая функция, которая преобразует значение ключа каждого записываемого или читаемого блока в адрес этого блока в файле. Эта функция называетсярандомизирующей функциейилифункцией хеширования. Выбор функции хеширования – довольно трудная задача и должен выполняться программистом с учетом следующих требований.
1. Функция хеширования должна отображать значения ключей в адреса блоков таким образом, чтобы обеспечивался достаточно равномерный разброс значений ключей по адресам блоков.
2. Функция хеширования должна как можно реже приводить к ситуациям переполнения блока, когда два или более значений ключей отображаются в один и тот же адрес блока в файле.
3. Функция хеширования не должна сохранять какую-либо связь между значениями ключей.
4. Функция хеширования должна быть простой, чтобы не требовалось длительного времени на вычисление адреса блока по заданному значению ключа.
Наиболее популярны такие функции, или алгоритмы, хеширования, как деление с использованием остатка, вычисление среднего квадрата, поразрядный анализ, переход к другой системе счисления, свертывание и др. Во всех этих алгоритмах преобразуемое, или хешируемое, значение ключа предварительно приводится к цифровому виду (например, к двоичному представлению), над которым и выполняются необходимые преобразования. В качестве примера поясним один из простейших алгоритмов хеширования – алгоритм деления с использованием остатка. В соответствии с этим алгоритмом значение ключа, представленное в цифровом виде, делится на число, близкое к числу блоков в файле. Для уменьшения синонимов (синонимы- это ключи, значения которых отображаются в один и тот же адрес блока) рекомендуется, чтобы делитель был простым числом, т.е. таким числом, которое делится без остатка только на само себя и на единицу. В результате деления значения ключа на выбранное простое число получается тот или иной целый остаток, который и считается относительным адресом блока в файле.
Рассмотрим некоторые способы для решения проблемы переполнения в файле прямого доступа. Один из таких способов состоит в том, что для каждого блока файла отводится столько места на ЗУПД, чтобы в блоке можно было поместить несколько различных логических записей. Такой блок применительно к файлу прямого доступа нередко называют секциейилипакетом. Размер пакета может соответствовать, например, целой дорожке. Как и всякий блок, при записи и чтении пакет передается между основной памятью и ЗУПД целиком. В пакет помещаются те логические записи, ключи которых при хешировании отображаются в адрес данного пакета. Если пакет имеет места дляМлогических записей, тоситуация переполнения пакетане возникает до тех пор, пока в пакет не будет записаноМзаписей с различными значениями ключа. Однако рано или поздно ситуация переполнения пакета все же может возникнуть.
Второй способ, который применяется наиболее часто, в дополнение к использованию пакетов предполагает выделение в файле одной или нескольких областей переполнения, в которых запоминаются записи, послужившие причиной возникновения ситуаций переполнения пакетов. Области переполнения могут быть на каждой дорожке или на каждом цилиндре, в этом случае для обращения к ним не требуется перемещения головок чтения-записи ЗУПД. Проще всего реализовать способ, в соответствии с которым в файле имеется единственная область переполнения, расположенная, например, в конце файла. При этом, однако, обращение к области переполнения может требовать дополнительных затрат времени на перемещение головок чтения-записи, в результате чего среднее время чтения или записи блоков увеличивается. Для связывания записей, попавших в область переполнения, с соответствующими пакетами обычно применяются указатели, для которых надо отводить место в каждой записи. Если в области переполнения имеются несколько записей, соответствующих одному пакету, то они связываются друг с другом в список.
Схема организации файла прямого доступа с использованием пакетов и области переполнения иллюстрируется на рис.7.4.
В основной области файла представлены три пакета M,NиJ, каждый из которых может хранить до трех логических записей. В рассматриваемый момент времени пакетMсодержит две логические записи А и В. ПакетNсодержит три записиP,RиS. ЗаписиSA,SB,SCиSD, которые привели к ситуациям переполнения пакетов, размещены в области переполнения в пакетахN1 иN2. ПакетыN,N1 иN2 связаны друг с другом с помощью указателей. И, наконец, пакетJхранит записиT,U,Vи связан с пакетомJ1, в котором содержатся записи переполненияVAиVB. Кружками, соединенными пунктирными линиями с пакетами, показано соответствие между ключом записи и соответствующим пакетом.

Иногда при обработке переполнения используется способ, не требующий особой области переполнения. В этом способе запись переполнения помещается в первый очередной пакет, в котором есть свободное место. При всей своей простоте такой метод обработки переполнения приводит к удлинению времени доступа из-за необходимости поиска первого свободного пакета, а также к явлению скручивания записей в отдельных местах файла.
Какой бы ни был способ обработки переполнения пакетов, с увеличением числа записей, помещаемых в файл, рано или поздно окажется, что для них нет места ни в основной области, ни в области переполнения. Говорят, что в этом случае возникает ситуация переполнения файла. Для ее устранения необходимо заново создать (реорганизовать) файл, выделив для него объем памяти ЗУПД в соответствии с возросшими требованиями.
Важнейшие операции над файлом прямого доступа – запись нового блока, чтение, модификация и удаление блока. В ряде операционных систем файлы прямого доступа можно обрабатывать последовательно, в порядке физического расположения блоков, или пакетов, в файле. Эта возможность бывает особенно полезна на этапе первоначальной загрузки файла, а также, например, при сплошной распечатке содержимого файла. В случае последовательной обработки после выполнения каждой операции чтения (или записи) блока автоматически формируется адрес следующего блока, который можно прочитать (или записать) при повторном выполнении операции чтения (записи), не формируя его адрес.