

Assembler / P19
.pdf19. Математический сопроцессор 19.1. Плавающие числа
До сих пор мы использовали только целые числа: знаковые и беззнаковые. Можно условиться вставлять в эти числа десятичную точку на фиксированной позиции. Так мы получим числа с фиксированной точкой. Но такой подход нельзя признать удовлетворительным, ведь на практике приходится вести вычисления, в которых одновременно участвуют и очень большие и очень маленькие числа (по абсолютной величине). Для таких вычислений введена система чисел с плавающей точкой (floatingpoint numbers), или просто — плавающих чисел. Прилагательное "плавающий" показывает, что положение десятичной точки не зафиксирована. Для плавающих чисел введен специальный стандарт IEEE 754. Он реализован в изучаемых нами процессорах.
Плавающее число может иметь много эквивалентных представлений. Например,
26.375 2.6375 101 2637.5 10-2 .
Общее представление плавающего числа имеет вид:
|
|
|
d |
1 |
|
d |
2 |
|
d |
t 1 |
|
||
x d |
|
|
|
|
|
|
|
be |
|||||
0 |
|
|
|
|
2 |
|
|
t 1 |
|||||
|
|
b |
|
b |
|
b |
|
||||||
|
|
|
|
|
|
|
|
||||||
Здесь b — основание системы счисления. di — цифры ( 0 di b 1), L e U . Если d0 0 (при x 0 ), то такая плавающая система называется нормализованной. Итак, в
приведенном выше примере из многих представлений только одно ( 2.6375 101 ) является нормализованным. Тогда набор цифр числа f d0 d 1 d t 1 называется мантиссой, e —
порядком (показателем), а t — точностью. Плавающая система определяется четыремя параметрами: b, t, L, U.
Числа, представимые в плавающей системе, расположены на числовой оси неравномерно.
Между 1 и 2 лежит столько же чисел, сколько между |
|
1 |
и |
1 |
, и столько же, сколько |
|
16 |
8 |
|||||
|
|
|
||||
между 16384 и 32768. В процессорах фирмы Intel плавающие числа представлены в трех форматах, носящих условные названия: с одинарной точностью, с двойной точностью, с расширенной точностью. Сначала тщательно изучим формат с одинарной точностью.
Числа с одинарной точностью Представление плавающего числа с одинарной точностью занимает 4 байта, т.е. его длина
составляет 32 бита. Бит 31 отведен для знака числа (0 — положительные, 1 — отрицательные, о представлении плавающего нуля — разговор особый), биты 30:23 — для порядка числа, биты 22:0 — для его мантиссы.
1 |
8 |
23 |
знак |
порядок |
мантисса |
Здесь есть свои особенности.
Основание системы счисления b = 2. Система нормализованная. Поэтому d0 = 1 (если число не является нулем). Но если старшая цифра мантиссы всегда равна 1, зачем ее хранить? За этот счет выигрывается дополнительный разряд мантиссы и увеличивается точность. Старшая цифра двоичного представления носит название "скрытый бит" (hidden bit).
Порядок может быть положительным и отрицательным. Так как на порядок отведены 8 бит, то, как мы уже знаем, e [ 128;127] . В каком формате хранить порядок?
Напрашивается решение: в дополнительном коде. Оказывается, это неудобно, и используется представление со смещением: e e 127 . Это "смещение" по-английски носит название bias (помните, нам ранее встретились два английских термина: offset и displacement, которые переводятся на русский язык словом "смещение"). Тогда –128 переводится в –1 = 11111111, а –127 — в 0 = 00000000. Эти коды будут использованы в
1
особых целях. Поэтому для показателя (порядка) остается диапазон [–126, 127]. Почему выбрано такое странное представление, со смещением? Тогда легко сравнивать плавающие числа на "больше–меньше". Их можно сравнивать, как длинные целые, а это делается очень быстро.
Теперь посмотрим пример представления числа в формате с обычной точностью, но сначала научимся переводить из десятичной в двоичную форму числа от 0 до 1. Для этого
заметим, что если |
x |
d 1 |
|
|
d 2 |
|
d t 1 |
|
, то bx d |
|
|
d 2 |
|
d t 1 |
, то есть d |
|
bx , |
|||||||||||||||
|
|
1 |
|
|
|
|
|
1 |
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
b |
|
b2 |
bt 1 |
|
|
|
|
|
|
|
|
b |
|
|
|
bt 2 |
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
где |
квадратные |
скобки |
|
обозначают |
взятие |
целой |
|
|
части |
|
числа. |
Далее |
|
имеем |
||||||||||||||||||
d 2 |
[b(bx d 1)] и т.д. Так мы по очереди получаем цифры двоичного представления. |
|||||||||||||||||||||||||||||||
|
Пример. –26.375 представить в формате с обычной точностью. |
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
Абсолютная величина числа равна 26.375. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
Двоичное представление целой части: 2610 = 110102, как было показано в примере 1.1. |
|||||||||||||||||||||||||||||||
|
Вычисление двоичного представления дробной части числа, представим в виде схемы: |
|||||||||||||||||||||||||||||||
|
|
|
|
|
0.375 * 2 = 0.75 |
|
|
|
|
|
|
|
|
0 = d–1 |
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
(0.75 – 0) * 2 = 0.75 * 2 = 1.5 |
1 = d–2 |
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
(1.5 – 1) * 2 = 0.5 * 2 = 1 |
|
|
|
|
|
1 = d–3 |
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
Итак, 0.37510 = 0.0112. Проверим: 0.375 |
375 |
|
|
3 |
0 |
|
1 |
1 |
1 |
|
1 |
1 |
. |
|
|
|
|||||||||||||||
|
|
8 |
2 |
4 |
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|||||||||
|
Мы получили, что 26.37510 = 11010.0112. Нормализуем это число. Для этого нужно |
|||||||||||||||||||||||||||||||
переместить десятичную точку влево на четыре |
|
позиции. |
Получим |
1.1010011 24 . |
||||||||||||||||||||||||||||
Вычислим смещенный |
|
порядок: |
e 4 127 131 128 3 100000112. Формируем |
|||||||||||||||||||||||||||||
представление: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
знак = 1, т.к. число отрицательное,
порядок = 1000 0011,
мантисса = 101 0011 0000 0000 0000 0000 (старший бит скрыт!) Окончательно имеем
1100 0001 1101 0011 0000 0000 0000 0000 = C1D30000h.
Проверку правильности вычислений проведем несколькими способами. 1. Программы на языке Си.
Преобразуем указатель на плавающее число к указателю на длинное целое и выведем на экран содержимое.
#include <stdio.h> float p = –26.375; void main()
{printf("%lx\n", *(long*)&p);
}
Воспользуемся конструкцией union.
#include <stdio.h> union {
float p; long f;
} u;
void main()
{u.p = –26.375; printf("%lX\n", u.f);
}
2. Программа на языке Ассемблера. nn.asm
.MODEL small
2

.DATA
DD –26.375 END
Получим листинг этой программы: tasm/l nn.asm
В листинге находим строку C1D30000 DD –26.375. (В файле nn.asm можно было опустить первые две строки, но тогда пришлось бы мириться с сообщением об ошибке)
3. В Turbo Debugger.
В панели данных окна CPU отобразите данные как float, введите –26.375, затем отобразите данные как long.
Задача. Представить вручную число –0.75 в формате с одинарной точностью и проверить правильность перевода описанными выше способами.
19.2. Двойная и расширенная точность.
Формат c одинарной точностью в ряде случаев неприемлем, как мы увидим на примере. Поэтому используются еще два формата: с двойной точностью и с расширенной точностью. Сведем эти форматы в таблицу.
Таблица *.1
Свойство |
Одинарная |
Двойная |
Расширенная |
|
точность |
точность |
точность |
Тип в языке Си |
float |
double |
long double |
Описание в Ассемблере |
DD |
DQ |
DT |
Общее количество бит |
32 |
64 |
80 |
Порядок (количество бит) |
8 |
11 |
15 |
Смещение (bias) |
127 |
1023 |
16383 |
Мантисса (количество бит) |
23 |
52 |
64 |
Скрытый бит (наличие) |
есть |
есть |
нет |
Количество цифр в десятичном представлении |
6 |
15 |
19 |
Диапазон показателя 10 |
–37, 38 |
–307, 308 |
–4931, 4932 |
DQ расшифровывается как Define Quadword — определить учетверенное слово; DT расшифровывается как Define Ten bytes — определить десять байтов.
Представление с расширенной точностью реализовано в сопроцессоре. Для ускорения вычислений скрытый бит в сопроцессоре не используется.
Задание A7.
Осуществить вручную перевод числа в формат обычной, двойной и расширенной точности и проверьте правильность перевода с помощью листинга программы на языке Ассемблера.
Пример выполнения.
Осуществим перевод числа –26.375.
Сначала переведем число в двоичную нормализованную форму. Абсолютная величина числа равна 26.375.
Двоичное представление целой части: 2610 = 110102.
Вычисление двоичного представления дробной части числа, представим в виде схемы:
0.375 * 2 = 0.75 |
0 = d–1 |
(0.75 – 0) * 2 = 0.75 * 2 = 1.5 |
1 = d–2 |
(1.5 – 1) * 2 = 0.5 * 2 = 1 |
1 = d–3 |
Итак, 0.37510 = 0.0112. Проверим: 0.375 1000375 83 0 12 1 14 1 18 .
3
Мы получили, что 26.37510 = 11010.0112. Нормализуем это число. Для этого нужно
переместить десятичную точку влево на четыре позиции. Получим 1.1010011 24 . Последующие вычисления сведем в таблицу
|
|
Обычная точность |
Двойная точность |
Расширенная точность |
знаковый бит |
1 |
1 |
1 |
|
смещенный |
127+4 = 128+3 = |
1023+4 = 1024 + 3 = |
16383+4 = 16384+3 = |
|
порядок |
1000 0011 |
100 0000 0011 |
100 0000 0000 0011 |
|
мантисса |
1010011 |
1010011 |
11010011 |
|
|
|
(есть скрытый бит) |
(есть скрытый бит) |
(нет скрытого бита) |
1) |
Обычная точность: 1 10000011 1010011000… = 1100 0001 1101 0011 0000 … = |
|||
|
C1D30000. (32 /4 = 8 цифр) |
|
|
|
2) |
Двойная точность: 1 10000000011 1010011000… = 1100 0000 0011 1010 0110 0000 … |
|||
=C03A600000000000. (64 /4 = 16 цифр)
3)Расширенная точность: 1 100000000000011 11010011 = 1100 0000 0000 0011 1101 0011 = C003D300000000000000. (80 /4 = 20 цифр)
Текст программы для проверки flonums.asm
.MODEL small
.DATA
DD –26.375
DQ –26.375
DT –26.375 END
Получение листинга: c:\tasm\bin\tasm /l flonums.asm
Задача. Напишите программу на языке Си, которая выведет 16-ричные коды представления чисел с двойной и расширенной точностью.
Теперь изучим, как получить число из его представления в одном из перечисленных форматов. Пусть sgn — значение знакового бита, f1f2… биты в поле мантиссы, e —
значение в поле порядка. Тогда
одинарная точность (–1)sgn(1.f1f2…f23) 2e–127. двойная точность (–1)sgn(1.f1f2…f52) 2e–1023. расширенная точность (–1)sgn(f1.f2…f64) 2e–16383.
Пример. Представление числа с одинарной точностью имеет вид 101111110110…, т.е. 1| 01111110|110… Тогда sgn = 1, e = 126, f1 = 1, f2 = 1, fk = 0 (k > 2). (–1)1(1.11) 2126–127 =
(–1) 1.75 2–1 = – 0.875.
19.3. Сравнение форматов |
|
|
|
Рассмотрим программу для вычисления выражения |
(a b) 2 |
2ab a 2 |
, которое, |
|
b 2 |
||
|
|
|
|
разумеется, равно 1 для любых значений a и b ( b 0 ). |
|
|
|
#include <stdio.h> float a,b,c,t1,t2,t3,d; int main() {
a = 95.0; b = 0.02;
t1 = (a + b) * (a + b);
4
t2 = - 2.0 * a * b - a * a; t3 = b * b;
c = (t1 + t2) / t3;
d = ((a+b)*(a+b)-2.0*a*b-a*a)/(b*b); printf("c = %f d = %f\n",c,d);
return 0;
}
Эта программа вычисляет указанное выражение двумя способами: разбивая его на промежуточные величины t1,t2,t3, помещая результат в c, и сразу вычисляя все выражение, помещая результат в d. Получим:
c = 2.441406 d = 1.000000
Значение c заведомо неверно. Теперь сделаем в программе одно-единственное изменение: заменим тип float на тип double. Тогда
c = 1.000000 d = 1.000000
Дадим объяснение полученным результатам. Как производится сложение плавающих чисел? Сначала надо сделать у них одинаковые порядки. Это можно добиться за счет сдвига мантиссы одного из слагаемых. При равных порядках можно складывать мантиссы. Но при сдвиге мантиссы вправо часть ее разрядов безвозвратно теряется. При работе с короткими мантиссами float это дает существенный эффект. При операциях с длинными мантиссами double эффект потери части младших разрядов становится незаметным.
Почему в первом случае вычисление d дало верный результат? Все вычисления проводились внутри сопроцессора с расширенной точностью, без записи промежуточных результатов вычислений в переменные типа float.
Приведенные результаты получены с использованием компилятора Turbo C. В VC++ вы можете для первого варианта программы получить результат:
c = 1.000000 d = 1.000000
Дело в том, что VC++ проводит оптимизацию кода программы. Он "видит", что переменные t1,t2,t3 более в программе не используются, а значит и выделять для них память нет необходимости. Все промежуточные значения сохраняются в регистрах сопроцессора. Чтобы воспроизвести указанный эффект, надо либо отключить оптимизацию (например, установить для проекта режим Debug, а не Release), либо выводить с помощью printf значения t1,t2,t3.
Вывод. Все расчеты над числами с плавающей точкой надо вести используя тип double, а не float. Окончательные результаты можно сохранять в формате float (например, в файле), если имеются ограничения на размер хранимых данных.
19.4. Специальные численные значения Будем рассматривать эти значения для расширенного формата. К специальным
значениям относятся: |
|
положительный нуль |
0|0…0|00…0 |
отрицательный нуль |
1|0…0|00…0 |
положительная бесконечность |
0|1…1|10…0 |
отрицательная бесконечность |
1|1…1|10…0 |
нечисло (NaN — Not a Number) |
x|1…1|xx…x , кроме x|1…1|10…0 |
Здесь вертикальными линиями отделены поля знака, порядка и мантиссы. Для нечисла есть более тонкая классификация: различают "сигнальные" (signal) и "тихие" (quit) нечисла. Но мы не будем подробно изучать этот вопрос (см. [Григорьев 486, т.2]).
Если число представляется в виде x|0…0|x…x (за исключением x|0…0|00…0), то такие числа считаются ненормализованными и исключаются из рассмотрения.
5
В формате с двойной или одинарной точностью, если поля порядка и мантиссы нулевые, то число — положительный или отрицательный нуль. В других случаях надо учитывать скрытый бит.
Приведем программу, в которой выводятся "бесконечности" (для VC++) #include <stdio.h>
union { float f; int i;
} u;
int main() {
u.i = 0x7F800000; printf("%f\n", u.f); u.i = 0xFF800000; printf("%f\n", u.f); return 0;
}
Программа выводит 1.#INF00 и –1.#INF00. Чтобы переделать ее в программу для Turbo C, замените int i на long i. Тогда программа выведет +INF и –INF.
19.5. Математический сопроцессор.
Математический сопроцессор (FPU — Floating Point Unit), специально предназначенный для вычислений с плавающими числами, появился уже для процессора 8086. Сопроцессор был реализован на отдельной микросхеме 8087. Это продолжалось для последующих моделей: для 80286 сопроцессор 80287, для 80386 сопроцессор 80387. В 486-й модели процессор и сопроцессор были объединены на одном кристалле — это сразу увеличило общее быстродействие. Так же было сделано и в последующих моделях.
19.5.1. Регистры сопроцессора
В FPU имеется восемь 80-разрядных регистров: R0, R1,…,R7. В них хранятся плавающие числа с расширенной точностью. Имеются также три 16-битовых регистра:
регистр управления
регистр состояния
регистр тэгов
Есть еще два регистра, указывающие на команду и операнд при возникновении особых случаев. (Мы не будем разбирать их функции.)
Адресация регистров R0, R1,…, R7 необычна. Программист никогда не обращается к регистрам по их именам. В регистре состояния есть поле ST(13:11). Номер регистра R0, R1,…,R7 вычисляется по формуле:
номер регистра = (номер регистра в команде + ST) mod 8.
Пусть например в поле ST хранится число 6. Тогда ссылки на регистры сопроцессора имеют вид, показанный справа на рис.
|
R0 |
второй от вершины |
ST(2) |
|
R1 |
третий от вершины |
ST(3) |
|
R2 |
четвертый от вершины |
ST(4) |
|
R3 |
пятый от вершины |
ST(5) |
|
R4 |
шестой от вершины |
ST(6) |
ST |
R5 |
седьмой от вершины |
ST(7) |
6 |
R6 |
вершина |
ST(0), или ST |
|
R7 |
первый от вершины |
ST(1) |
Рис.
6
Например, команда сложения плавающих чисел fadd st(1),st берет свои операнды из регистров R7 и R6. Если же в ST записано число 7, то операнды будут взяты из R0 и R7. Итак, набор регистров сопроцессора представляет собой "закольцованный стек". Отсюда и название поля ST — первые две буквы слова stack. Такая организация регистров не случайна. Как мы увидим на примере при вычислении арифметического выражения промежуточные результаты помещается в стек. А элементами этого стека являются регистры сопроцессора.
Регистр тэгов описывает содержимое регистров FPU
тэг7 |
тег6 |
тег5 |
тег4 |
тег3 |
тег2 |
тег1 |
тег0 |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
00 — действительное число, 01 — нуль, 10 — нечисло (бесконечность), 11 — пустой.
19.5.2. Команды Коды команд начинаются с пяти бит 11011. Это информация для ЦП: передать
команду для выполнения в FPU. Ассемблерная мнемоника команд начинается с буквы F (Float).
В системе команд FPU можно выделить несколько групп команд: команды передачи данных, команды сравнения, арифметические команды, команды вычисления трансцендентных функций (логарифма, арктангенса и т.д.). Подробное изучение этих команд не входит в нашу задачу. Арифметические выражения прекрасно транслируют компиляторы языков высокого уровня. Посмотрим работу этих команд на примере
19.5.3. Пример программы для вычисления арифметического выражения.
Программа вычисляет значение квадратного трехчлена 3x 2 7x 2 при x = 2. В обратной польской записи формула принимает вид 3 x * x * 7 x * – 2 +. В процессе вычисления операнды размещаются в стеке регистров сопроцессора.
npol.c float t,x,y; void main()
{x = 2.0;
y = 3*x*x – 7 * x + 2;
}
Обычными командами tcc –v npol.c и td npol.exe мы получаем исполняемый файл с отладочной информацией и загружем его в отладчик. Переменная t введена для удобства отладки.
Закроем окна Module и Watch, откроем окно CPU. Сначала обратимся к панели данных: Alt+F10/ Goto. Вводим адрес 0xA8 (мы узнале его из кода, который будет приведен ниже). Далее Alt+F10/ Display As/ Float. Мы увидим константы, для которых транслятор выделил ячейки памяти
ds:00A8 2 3 ds:00B0 7 0
Уменьшим окно CPU и разместим на экране новое окно: F10/ View/ Numeric Processor.
(описание панелей окна)
С помощью локального меню (Alt+F10) обнулим (Zero) все регистры FPU и сделаем их пустыми (Empty). Вы должны получить
7
Empty ST(0) |
0000 0000 0000 0000 0000 |
Empty ST(1) |
0000 0000 0000 0000 0000 |
Empty ST(2) |
0000 0000 0000 0000 0000 |
Empty ST(3) |
0000 0000 0000 0000 0000 |
Empty ST(4) |
0000 0000 0000 0000 0000 |
Empty ST(5) |
0000 0000 0000 0000 0000 |
Empty ST(6) |
0000 0000 0000 0000 0000 |
Empty ST(7) |
0000 0000 0000 0000 0000 |
Приступим к изучению кода |
|
|
#NPOL#3: { x = 2.0; |
|
|
cs:023C CD3506A800 |
fld |
dword ptr[00A8] |
fld (Float load) считывает операнд, преобразует его в формат с раширенной точностью, осуществляет декркмент ST на 1 по модулю 8ю, операнд помещается в вершину стека. Результат fld
Valid ST(0) 2 |
4000 8000 0000 0000 0000 |
|
Следующая команда |
|
|
cs:0241 CD351E4805 |
fstp |
dword ptr[_x] |
fstp (Float store with pop) считывает содержимое регистра ST(0), после необходимого преобразования результат записывается в операнде, происходит инкремент ST по модулю 8 (это и означает выталкивание — pop).
Empty ST(7) |
4000 8000 0000 0000 0000 |
Число 2 превратилось в "мусор", потому что регистр помечен как пустой. В результате этих двух команд в ячейке x записано число 2.0.
Теперь изучим, как проходит вычисление по формуле. (самостоятельно прослеживайте содержимое стека)
#NPOL#4: |
y = 3 * x * x - 7 * x + 2; |
||
cs:0246 |
CD3506AC00 |
fld |
dword ptr[00AC] |
cs:024B |
CD340E4805 |
fmul |
dword ptr[_x] |
cs:0250 |
CD340E4805 |
fmul |
dword ptr[_x] |
cs:0255 |
CD3506B000 |
fld |
dword ptr[00B0] |
cs:025A |
CD340E4805 |
fmul |
dword ptr[_x] |
cs:025F |
CD3AE9 |
fsubp |
st(1),st |
cs:0262 |
CD3406A800 |
fadd |
dword ptr[00A8] |
cs:0267 |
CD351E4C05 |
fstp |
dword ptr[_y] |
cs:026C |
CD3D |
fwait |
|
#NPOL#5: } |
|
|
|
cs:026E |
5D |
pop |
bp |
cs:026F |
C3 |
ret |
|
Проведите изучение этой программы в VC++ (теперь переменную t можно удалить). В окне Watch выводите содержимое регистров st0, st1, st2. При этом можно использовать спецификатор формата x, чтобы посмотреть 16-ричное содержимое регистра или ячейки памяти.
Задача. Получите в VC++ ассемблерный код этой программы. Превратите его в программу на языке Ассемблера, использующую малую модель памяти, а также секции данных и кода. Изучите работу этой программы в Turbo Debugger.
#include |
<stdio.h> |
|
|
|||
float |
r1 |
= |
1.0, r2 |
= |
0.0, r; |
|
int |
main() |
{ |
|
|
||
r |
= |
1.0 / |
(1.0 / |
r1 + 1.0 / r2); |
||
printf("r |
= %f\n", |
r); |
||||
8
return 0;
}
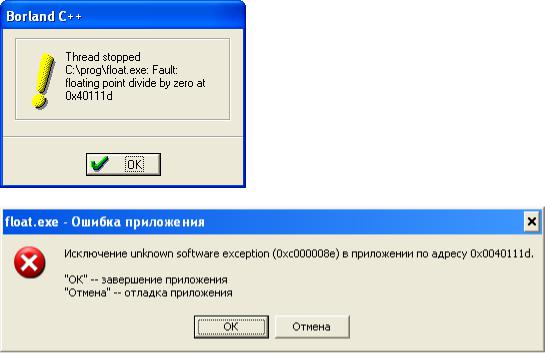
Если делать в 32-разрядной среде, то сообщения
А в 16-разрядной:
Floating point error: Divide by 0. Abnormal program termination
Получим ассемблерный файл bcc –S res.c
и отредактируем его (удалим много лишнего и добавим привычные директивы).
.MODEL small
.286
.STACK 100h
.DATA r1 DD 1.0 r2 DD 0.0
rDD ?
.CODE
start: mov ax, @data mov ds, ax
fld |
dword ptr r1 |
fld1 |
|
fdivr |
|
fld |
dword ptr r2 |
fld1 |
|
fdivr |
|
fadd |
|
fld1 |
|
fdivr |
|
9
fstp dword ptr r mov ax, 4C00h int 21h
END start
В отладчике
#float#start: start: mov ax, @data
cs:0000►B8240B |
mov |
ax,0B24 |
|
#float#10: |
mov ds, ax |
|
|
cs:0003 8ED8 |
mov |
ds,ax |
|
#float#11: |
fld dword ptr r1 |
|
|
cs:0005 D9060000 |
fld |
dword ptr[0000] |
|
#float#12: |
fld1 |
|
|
cs:0009 D9E8 |
fld1 |
|
|
#float#13: |
fdivr |
|
|
cs:000B DEF1 |
fdivrp st(1),st |
||
#float#14: |
fld dword ptr r2 |
|
|
cs:000D D9060400 |
fld |
dword ptr[0004] |
|
#float#15: |
fld1 |
|
|
cs:0011 D9E8 |
fld1 |
|
|
#float#16: |
fdivr |
|
|
cs:0013 DEF1 |
fdivrp |
st(1),st |
|
#float#17: |
fadd |
|
|
cs:0015 DEC1 |
faddp |
st(1),st |
|
#float#18: |
fld1 |
|
|
cs:0017 D9E8 |
fld1 |
|
|
#float#19: |
fdivr |
|
|
cs:0019 DEF1 |
fdivrp st(1),st |
||
#float#20: |
fstp dword ptr r |
|
|
cs:001B D91E0800 |
fstp |
dword ptr[0008] |
|
#float#21: |
mov ax, 4C00h |
|
|
cs:001F B8004C |
mov |
ax,4C00 |
|
#float#22: |
int 21h |
|
|
cs:0022 CD21 |
int |
21 |
|
Проследим выполнение программы по шагам. |
|||
#float#11: |
fld dword ptr r1 |
|
|
cs:0005 D9060000 |
fld |
dword ptr[0000] |
|
Valid ST(0) |
1 |
|
3FFF 8000 0000 0000 0000 |
#float#12: |
fld1 |
|
|
cs:0009 D9E8 |
fld1 |
|
|
Valid ST(0) |
1 |
|
3FFF 8000 0000 0000 0000 |
Valid ST(1) |
1 |
|
3FFF 8000 0000 0000 0000 |
Empty ST(2) |
|
|
0000 0000 0000 0000 0000 |
#float#13: |
fdivr |
|
cs:000B DEF1 |
fdivrp st(1),st |
|
Valid ST(0) |
1 |
3FFF 8000 0000 0000 0000 |
10