

os-2015-10-dist
.pdf
Big Data
•Источники?
•Как передавать?
•Как хранить?
•Как обрабатывать?
•Как понять структуру?
•…
•Как использовать?
Почему сейчас?
•Системы хранения
–$600 стоит диск, на которые можно записать всю музыку
–235 TBs данных хранятся в US Library of Congress (апрель 2011)
•Рынок мобильной электроники
–5B мобильных телефонов использовалось 2010
–195M+ отгружено ноутбуков в 2012 (Digitimes Research)
–144,5M планшетов продано в 2012 (IDC)
•Сенсоры и социальные сети генерят огромные объемы
–30B единиц контента распространяется в Facebook ежемесячно
–40% в год рост данных vs. 5% роста расходов на ИТ
•…

Где рождаются данные?
|
|
|
|
|
Приборы |
|
Люди |
|
|
|
Люди |
|
|
|
|
||
|
• |
Поведение (покупки) |
|||
Промышленность |
|
||||
|
|
• |
Общение (социальные сети) |
||
Наука
Data Mining – много определений
•Data Mining — это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для реализации.
•Data Mining — это процесс анализа, выделения и представления детализированных (detailed data) данных неявной конструктивной информации для решения проблем бизнеса (NCR).
•Data mining — это процесс выделения (selecting), исследования и моделирования больших объемов данных для обнаружения неизвестных до этого структур (patterns) с целью достижения преимуществ в бизнесе (SAS Institute).
•Data mining — это процесс, цель которого — обнаружить новые значимые корреляции, образцы и тенденции в результате просеивания большого объема хранимых данных с использованием методик распознавания образцов плюс [применение] статистических и математических методов (Gartner Group).
•Data mining — это процесс автоматического выделения действительной, эффективной, ранее неизвестной и совершенно понятной информации из больших баз данных и использование ее для принятия ключевых бизнесрешений.
•Data mining - это процесс обнаружения в сырых данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. (GTE Labs)
Data Mining - эволюция
Evolutionary Step |
Business |
Enabling Technologies |
Product Providers |
Characteristics |
|
Question |
|
|
|
Data Collection (1960s) |
"What was my total |
Computers, tapes, disks |
IBM, CDC |
Retrospective, |
|
revenue in the last |
|
|
static data |
|
five years?" |
|
|
delivery |
Data Access (1980s) |
"What were unit |
Relational databases |
Oracle, Sybase, |
Retrospective, |
|
sales in New |
(RDBMS), Structured |
Informix, IBM, |
dynamic data |
|
England last |
Query Language (SQL), |
Microsoft |
delivery at |
|
March?" |
ODBC |
|
record |
|
|
|
|
level |
Data Warehousing & |
"What were unit |
On-line analytic |
Pilot, Comshare, |
Retrospective, |
Decision Support |
sales in New |
processing (OLAP), |
Arbor, Cognos, |
dynamic data |
(1990s) |
England last |
multidimensional |
Microstrategy |
delivery at |
|
March? Drill down |
databases, data |
|
multiple levels |
|
to Boston." |
warehouses |
|
|
|
|
|
|
|
Data Mining |
"What’s likely to |
Advanced algorithms, |
Pilot, Lockheed, |
Prospective, |
(Emerging Today) |
happen to Boston |
multiprocessor |
IBM, SGI, |
proactive |
|
unit sales next |
computers, massive |
numerous startups |
information |
|
month? Why?" |
databases |
(nascent industry) |
delivery |
|
|
|
|
|
Google: 141 000 000 for “data mining”
Ref: http://www.thearling.com/text/dmwhite/dmwhite.htm
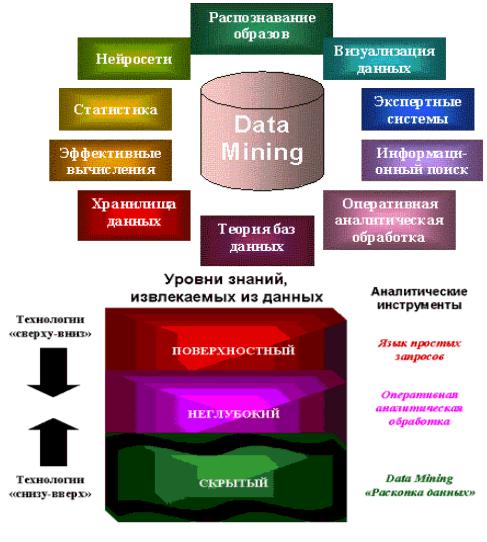
DM использует набор инструментов
Обычно упоминаются технологии:
•Искусственные нейронные сети
•Генетические алгоритмы
•Деревья принятия решений
•Кластеризация (ближайшие соседи)
•…
•Rule induction: Извлечение полезных «Если - то» правил из баз данных

Распределенные файловые системы
При создании распределенных файловых систем обращают внимание на две главные задачи:
сетевая прозрачность, которая заключается в обеспечении тех же возможностей доступа к файлам, как и в централизованных системах
высокая доступность, заключающаяся в том, что ошибки и системные сбои не должны приводить к проблемам доступа к файлам
Файловый сервис — интерфейс с файловой системой, то, что предоставляет файловая система
Файловый сервер — это процесс, который представляет файловый сервис
Пользователь не должен знать, сколько в системе файловых серверов и где они расположены. В системе могут функционировать разные процессы (с разных операционных систем), следовательно, файловый сервис
должен уметь работать со всеми |
38 |
|

Архитектура распределенных файловых систем
Распределенная файловая система обычно имеет два существенно отличающихся компонента:
Файловый сервис. Модели, на которых может основываться файловый сервис, таковы:
модель "загрузки-разгрузки". В этом случае осуществляется пересылка файла клиенту целиком
модель удаленного доступа. Реализуется без пересылки файла клиенту
Сервис каталогов (директорий), обеспечивающий операции создания и удаления каталогов, именования файлов, их переименования и перемещения
Ключевые решения, которые необходимо принять при разработке распределенных файловых систем, определяются ответами на следующие вопросы.
Должны или не должны все процессы видеть иерархию каталогов одинаково?
Должен ли быть единый корневой каталог?
39

Подходы к именованию файлов
Ключевые решения, которые необходимо принять при разработке распределенных файловых систем, определяются ответами на следующие вопросы
Должны или не должны все процессы видеть иерархию каталогов одинаково?
Должен ли быть единый корневой каталог?
Существуют две формы прозрачности именования:
прозрачность расположения, определяющая, как легко мы можем обратиться к файлу
прозрачность миграции, когда изменение расположения файла не требует
изменения имени
Подходы к именованию файлов таковы:
процессы видят файл как имя машины и путь к файлу на ней
монтирование удаленных файловых систем в локальную иерархию файлов
все процессы видят все файлы одинаково (для реализации нужен мощный механизм)
Большинство систем используют ту или иную форму двухуровневого именования:
файлы имеют символическое имя, которое видит пользователь, и
внутреннее двоичное имя, которое используется самой системой
40