

Глава 7. Мультитредовые микропроцессоры
7.1 Основы мультитредовой архитектуры
Для параллельного выполнения нескольких процессорных инструкций необходимо увеличивать количество исполнительных блоков (Execution Units) внутри процессора. Такая многозадачность реализована в том или ином виде во всех современных процессорах. Отход от последовательного выполнения команд, использование нескольких исполнительных блоков в одном процессоре позволяют одновременно обрабатывать несколько процессорных микрокоманд, то есть организовывать параллелизм на уровне инструкций (Instruction Level Parallelism, ILP), что, естественно, увеличивает общую производительность.
Поясним все вышесказанное на примере. Представьте себе гипотетический процессор, в котором имеются четыре исполнительных блока: два для работы с целыми числами (арифметико-логическое устройство, ALU), один для работы с числами с плавающей точкой (FPU) и один для записи и чтения данных из памяти (Store/Load, S/L). Кроме того, пусть каждая операция осуществляется за один такт процессора.
Д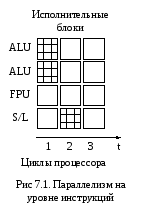 алее
предположим, что выполняется программа,
состоящая из трех инструкций: первые
две – арифметические действия с целыми
числами, а последняя – сохранение
результата (рис. 7.1). В этом случае вся
программа будет выполнена за два такта
процессора: в первом такте задействуются
два блокаALU
процессора, во втором – блок S/L
записи и чтения данных из памяти
(store/load).
алее
предположим, что выполняется программа,
состоящая из трех инструкций: первые
две – арифметические действия с целыми
числами, а последняя – сохранение
результата (рис. 7.1). В этом случае вся
программа будет выполнена за два такта
процессора: в первом такте задействуются
два блокаALU
процессора, во втором – блок S/L
записи и чтения данных из памяти
(store/load).
В современных приложениях в любой момент, как правило, выполняется не одна, а несколько задач или несколько потоков (threads) одной задачи, называемых также нитями. Давайте посмотрим, как будет вести себя наш гипотетический процессор при выполнении двух разных потоков А и В (рис. 7.2).
Если бы оба потока исполнялись изолированно, то для выполнения первого и второго потоков потребовалось бы по пять тактов процессора. При одновременном исполнении обоих потоков на одних и тех же исполнительных блоках (2 ALU, 1 FPU, 1 S/L) процессор будет постоянно переключаться между ними, следовательно, за один такт процессора выполняются только инструкции какого-то одного потока. Поэтому для исполнения обоих потоков потребуется в общей сложности 10 процессорных тактов.
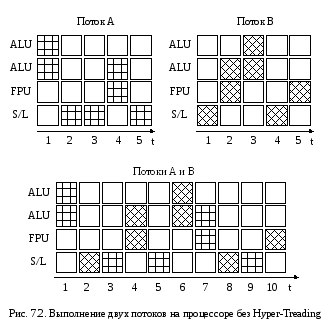
Однако можно повысить скорость выполнения задачи в рассмотренном примере. Как видно на рисунке 7.2, на каждом такте процессора используются далеко не все исполнительные блоки, поэтому имеется возможность частично совместить выполнение инструкций отдельных потоков на каждом такте. В нашем примере выполнение двух арифметических операций с целыми числами потока А можно совместить с загрузкой данных из памяти потока В и выполнить все три операции за один такт процессора. Аналогично на втором такте процессора можно совместить операцию сохранения результатов потока А с двумя операциями потока В и т.д. Следуя такому правилу совмещения операций можно выполнить потоки А и В за пять тактов (рис. 7.3.). Собственно, в таком параллельном выполнении двух потоков и заключается основная идея технологии Hyper-Threading.
И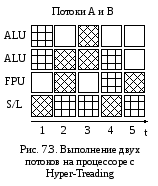 так,
технологияHyper-Threading– это реализация одновременной
многопоточности (SimultaneousMulti-Threading,SMT). Все потоки имеют
собственные: программный счетчик, стек
и регистры. Потоки разделяют: адресное
пространство.Технология
Hyper-Threading
является промежуточной между многопоточной
обработкой, осуществляемой в
мультипроцессорных системах, и
параллелизмом на уровне инструкций,
реализованном в однопроцессорных
системах.
так,
технологияHyper-Threading– это реализация одновременной
многопоточности (SimultaneousMulti-Threading,SMT). Все потоки имеют
собственные: программный счетчик, стек
и регистры. Потоки разделяют: адресное
пространство.Технология
Hyper-Threading
является промежуточной между многопоточной
обработкой, осуществляемой в
мультипроцессорных системах, и
параллелизмом на уровне инструкций,
реализованном в однопроцессорных
системах.
Конечно, ждать двукратного увеличения производительности процессора от использования технологии Hyper-Threading не приходится и на практике выигрыш куда более скромен. Дело в том, что возможность одновременного выполнения на одном такте процессора инструкций от разных потоков ограничивается тем, что эти инструкции могут задействовать одни и те же исполнительные блоки процессора.
Для реализации технологии Hyper-Threading процессор должен иметь как минимум два «входа» для отдельных потоков, как если бы существовало два физических процессора, но при этом всего один конвейер обработки команд, как в реальном физическом процессоре, который использует оба потока. В этом случае один физический процессор представляется операционной системе как два логических.
С конструктивной точки зрения процессор с поддержкой технологии Hyper-Threading состоит из нескольких логических процессоров, каждый из которых имеет свои регистры и контроллер прерываний (Architectural State, AS), то есть две параллельно исполняемые задачи работают со своими собственными независимыми регистрами и прерываниями, но при этом используют одни и те же ресурсы процессора для выполнения задач. Таким образом, от реальной мультипроцессорной конфигурации технология Hyper-Threading отличается только тем, что оба логических процессора используют одни и те же исполняющие ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и одну системную шину.
Суперскалярные микропроцессоры и микропроцессоры с длинным командным словом имеют один счетчик команд и, в силу этого, могут быть названы однотредовыми. В этих микропроцессорах команды, исследуемые на предмет возможности их параллельного совместного исполнения, привязаны к счетчику команд процессора либо окном исполнения как в суперскалярных микропроцессорах, либо длинной командой как в микропроцессорах с длинным командным словом. Для того чтобы более агрессивно выбирать для параллельного исполнения команды одной или нескольких программ, в микропроцессор вводится несколько счетчиков команд и, возможно, другого оборудования. Микропроцессоры с несколькими счётчиками команд получили название мультитредовых.
Мультитредовая архитектура решает проблему борьбы с простоями функциональных устройств процессора, возникающими из-за невозможности выполнения следующей команды, путем переключения на другой регистровый файл, тем самым процессор получает другой контекст для продолжения вычислений, переходя к выполнению другого треда (процесса).
Переключение процессора на другой регистровый файл выполняется либо по наступлению некоторого события, влекущего за собой простой процессора (промах в кэш-память, обращение к оперативной памяти, наступление прерывания), либо принудительно, например, в каждом такте, как в Tera МТА.
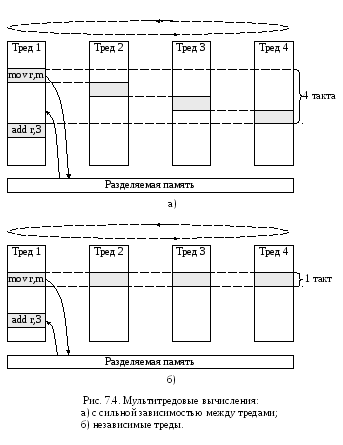
В Tera МТА проблема разрыва между скоростью обработки в процессоре и временем доступа в основную память решается посредством принудительного переключения в каждом такте процессора на работу с очередным множеством регистров. Структура мультитредового процессора представлена на рисунке 7.4. Каждый набор регистров обслуживает один вычислительный процесс, называемый тредом.
Всего в процессоре имеется n наборов регистров. Поэтому запрос, выданный в основную память процессом, может обслуживаться в течение n – 1 тактов, вплоть до момента, когда процессор снова переключится на тот же набор регистров. Тем самым по отношению к одному треду исполнение его команд замедляется в n раз. Значение n выбирается исходя из того, чтобы время доступа в память было меньше, чем время длительности n – 1 такта процессора. Задача формирования n тредов целиком возлагается на компилятор.
При всем различии подходов к созданию мультитредовых микропроцессоров общим в них является введение множества процессорных элементов, содержащих устройство выборки команд, которое организует окно исполнения для одного треда. В рамках одного треда может выполняться предсказание переходов, переименование регистров, динамическая подготовка команд к исполнению. Тем самым, общее количество команд, находящихся в обработке, значительно превышает размер окна исполнения суперскалярного процессора, с одной стороны, и тактовая частота не лимитируется размером окна исполнения, с другой стороны.
Выявление тредов может выполняться компилятором при анализе исходного кода на языке высокого уровня или исполняемого кода программы. Однако компиляторы не всегда могут разрешить проблемы зависимостей при использовании регистров и ячеек памяти между тредами, что требует разрешения этих зависимостей уже в ходе исполнения тредов.
Для этого в микропроцессор вводится специальная аппаратура условного исполнения тредов, предусматривающая возврат с отбрасыванием наработанных результатов в случае обнаружения нарушения зависимостей между тредами. Нарушением зависимости, например, может служить запись по вычисляемому адресу в одном треде в ту же ячейку памяти, из которой выполняется чтение, которое должно следовать за этой записью, в другом треде. В этом случае, если адреса записи и чтения не совпадают, нарушение отсутствует. При совпадении адресов фиксируется нарушение, которое должно вернуть исполнение треда к команде чтения правильного значения.
Интерфейс между аппаратурой мультитредового процессора, поддерживающей протекание каждого отдельного треда, и аппаратурой, общей для исполнения всех тредов, может быть установлен как после устройств выборки команд треда и принадлежащих треду функциональных устройств, так и на уровне доступа к разделяемой памяти. В первом случае каждый тред использует собственные функциональные устройства, например, целочисленное АЛУ и ряд общих для всех тредов функциональных устройств, например, для выполнения операций с плавающей точкой. Тесная связь по ресурсам позволяет эффективно исполнять последовательные программы с сильной зависимостью между тредами. В этом случае имеет место реализация мультискалярного мультитредового процессора (SMT).
Во втором случае для исполнения каждого треда фактически выделяется функционально законченный процессор. В целом, эта структура ориентирована на исполнение независимых и слабо связанных тредов, порождаемых либо одной программой, либо их совокупностью. В этом случае скорее надо говорить не о процессоре, а об однокристальной системе (CMP – chip multiprocessing).
Мультитредовый процессор может исполнять треды, принадлежащие одной или нескольким программам. Если процессор исполняет одну программу, то говорят о его производительности (productivity), если несколько программ – о пропускной способности (capacity).
По оценкам, при обработке транзакций мультитредовый процессор Alpha 21464 будет в 10 раз производительнее, чем современный Alpha 21264. При этом ускорение в 2 раза ожидается за счет именно мультитредовой архитектуры. Еще в 2 раза ускорение прогнозируется за счет увеличения использования параллелизма уровня команд. Остальные 2,5 раза должны быть достигнуты за счет усовершенствования технологии и повышения тактовой частоты.
Мультитредовые микропроцессоры и однокристальные системы вбирают накопленные в ходе эволюции приемы повышения производительности микропроцессоров и используют симбиоз компиляторов и аппаратуры, соответственно для статического и динамического выявления параллелизма из исходных последовательных программ. Ориентация на исполнение совокупности тредов с определенной степенью межтредовых зависимостей обусловливает конкретные решения по совместному использованию тредами функциональных устройств. Суть мультитредовой архитектуры – использование совокупности регистровых файлов в процессоре. То есть транзисторы используются не для образования кэш-памяти, а для формирования совокупностей регистровых файлов, включающих счетчик команд, регистры состояния и рабочие регистры.
Хотя фирма Intel уже ввела мультитредовую архитектуру в своих процессорах, предстоят еще значительные исследования в этом вопросе. Компания Tera объявила о разработке проекта мультитредового микропроцессора Torrent, реализующего процессор МТА. Фирма Level One, образованная Intel, выпустила мультитредовый сетевой микропроцессор IXP1200, содержащий в своем составе 6 четырехтредовых процессоров. IBM анонсировала проект компьютера Blue Gene с производительностью 1015 flops (Floating Point Operations per Second - операций с плавающей точкой двойной точности в секунду). Кристалл микропроцессора Blue Gene включает 32 восьмитредовых процессора. В кристалл встроена DRAM, реализованная как 32 блока. Каждый блок соответствует одному из 32 процессоров и имеет 256-разрядную шину доступа. Так как DRAM имеет высокую пропускную способность и малую задержку, то при восьмитредовой структуре процессора становится возможным отказаться от кэш-памяти, вместо которой между процессором и памятью используется небольшая буферная память. Компании IBM, Sony, Toshiba ведут совместный проект по разработке мультитредового процессора Cell (биологическая клетка, ячейка), само название которого достаточно красноречиво свидетельствует о его предназначении (вторая попытка ввести название нового класса микропроцессоров после неудачи с термином "транспьютер"?).