

Контрольные вопросы
1. Что означает принцип FIFO?.
2. Что такое очередь в концептуальном и физическом представлении?
3. Как операции осуществляются с элементами очереди? Покажите на схеме.
4. Что такое деревья в концептуальном и физическом представлении?
5. Как операции осуществляются с элементами деревьев? Покажите на схеме.
Лекция № 26 Пользовательские типы данных
Цель лекции
Изучить способы организации и хранения пользовательских типов данных.
План лекции
1. Пользовательские типы данных.
2. Классы.
2. Стандартная библиотека шаблонов.
Ранее мы познакомились с концепцией типов данных и рассмотрели элементарные типы: целые числа, вещественные числа, символы и булевы данные, являющиеся базовыми в большинстве языков программирования. В этом разделе мы обсудим, как программист может самостоятельно определить собственные типы данных, точно отвечающие требованиям отдельного приложения.
1 Пользовательские типы данных
Переменные в программе могут быть не только данными простых типов, но также структурами данных (data structure), то есть данными, упорядоченными каким-либо образом. Например, текст обычно рассматривается как длинная цепочка символов, а учетные записи продаж можно представить в виде таблицы, в которой в строке записываются продажи, сделанные определенным сотрудником, а в столбце — продажи, сделанные в определенный день.
Наиболее распространенной структурой данных является однородный массив (homogeneous array). Однородный массив представляет собой набор значений одного типа, например одномерный список, двумерную таблицу или таблицу с большим количеством измерений. В большинстве языков программирования для того, чтобы описать массив, нужно задать количество измерений, а также число элементов в каждом измерении. Например, структура, описанная выражением в языке С int Scores [2] [9];
означает: «Переменная Scores будет использоваться в программе для обозначения двумерного массива целых чисел, состоящего из двух строк и девяти столбцов» (рис. 1). То же самое выражение на языке FORTRAN будет выглядеть следующим образом:
INTEGER Scores (2.9).
После описания массива к нему можно обращаться по заданному имени. А к отдельным элементам массива можно обращаться с помощью целых чисел, которые называются индексами (indices). Они определяют строку и ряд, в котором находится элемент массива. Однако диапазон индексов меняется от языка к языку. Например, в языке С (и его производных C++, Java и С#) индексы начинаются с 0. То есть элемент, находящийся во второй строке и четвертом столбце массива Scores, можно обозначить с помощью выражения Scores [1] [3], а элемент, расположенный в первой строке и первом столбце, будет обозначаться как Scores [0] [0]. Напротив, в языке FORTRAN индексы начинаются с 1, поэтому элемент, расположенный во второй строке и четвертом столбце, будет обозначаться как Scores (2,4) (см. рис. 1 ).
В отличие от однородного массива, в котором элементы данных относятся к одному типу, неоднородный массив (heterogeneous array) может содержать данные разных типов. Например, совокупность данных о сотруднике компании может состоять из элемента символьного типа Name, элемента целочисленного типа Аgе и элемента вещественного типа SkillRating. В языках Pascal и С (рис. 5.6) такой тип массива называется соответственно записью (record) и структурой (structure).
Описание неоднородного массива в Pascal
var
Employee: record
Name: packed array [1..8] of char;
Age: integer;
SkillRating: real
end
Описание неоднородного массива в С
struct
{ char Name [8];
int Age:
float SkillRating;
} Employee:
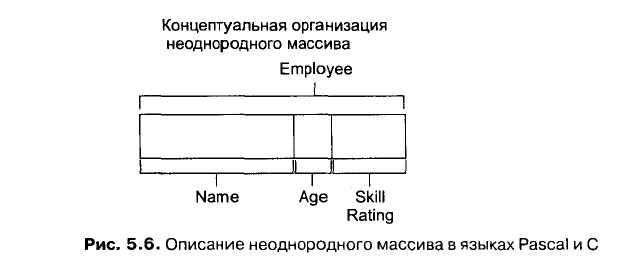
Рисунок 1 – Описание неоднородного массива
К компоненту неоднородного массива обычно обращаются по имени массива, после которого ставится точка и затем указывается имя этого компонента. Например, к компоненту Age массива Employee (см. рис. 1) можно обратиться с помощью выражения Employee.Age.
Данные, которые содержит массив, могут быть разбросаны по оперативной памяти или по запоминающему устройству. Именно поэтому мы рассматриваем структуры данных, как концептуальную форму упорядочивания данных. На самом деле, расположение данных в запоминающем устройстве машины может совершенно отличаться от их абстрактной структуры.
Задача реализации алгоритма часто упрощается, если в языке программирования предусмотрены, кроме примитивных, дополнительные типы данных. Многие современные языки программирования позволяют программистам определять свои типы данных, используя в качестве компоновочных блоков примитивные типы данных и структуры. Эти «самодельные» типы данных называются пользовательскими типами (user-defined types).
В качестве примера предположим, что нам нужно разработать программу, включающую множество переменных одной и той же неоднородной структуры, состоящей из имени, возраста и уровня знаний. Можно заново объявлять состав структуры каждый раз, когда требуется сослаться на такую структуру. Например, чтобы объявить переменную Employee с такой неоднородной структурой, С-программист написал бы:
struct
{char Name[8]:
int Age:
float Ski 11 Rating;
} Employee;
как на рис. 1.
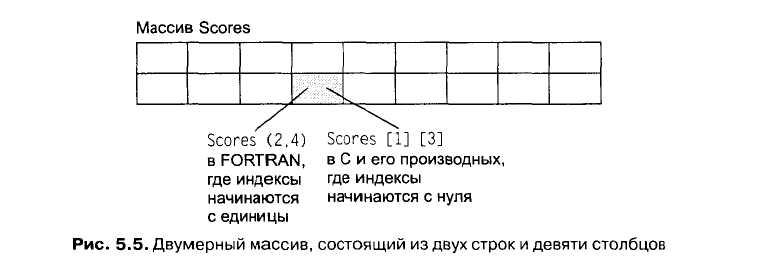
Рисунок 2 – Двумерный массив, состоящий из двух строк и девяти столбцов
Но в этом случае, если такая структура будет часто встречаться в тексте, программа может стать слишком громоздкой и трудной для чтения. Более того, без подробного изучения трудно узнать, что все структуры идентичны. Лучше определить неоднородную структуру как новый (пользовательский) тип данных и использовать этот тип так же, как если бы это был примитив.
Типичный пример такого подхода можно увидеть в языке программирования С, где новые типы определяются при помощи оператора typedef (сокращение от type definition, определение типа). Он состоит из зарезервированного слова typedef, за которым идет описание структуры нового типа, и заканчивается именем нового типа. Так, оператор
typedef struct
{char Name[8]: