

2 Деревья
Последняя структура данных, с которой мы познакомимся, — это деревья (tree), которыми являются организационные диаграммы типичных компаний (рис. 4). Здесь президент находится на вершине, от которой отходят линии к вице-президентам, за которыми следуют региональные менеджеры и т. д. Чтобы дать интуитивное определение дерева, мы наложим дополнительное ограничение, состоящее в том (в терминах организационной диаграммы), что ни один сотрудник компании не подчиняется двум разным начальникам. То есть разные ветви организации не сливаются на нижнем уровне.

Рисунок 4 – Пример организационной диаграммы
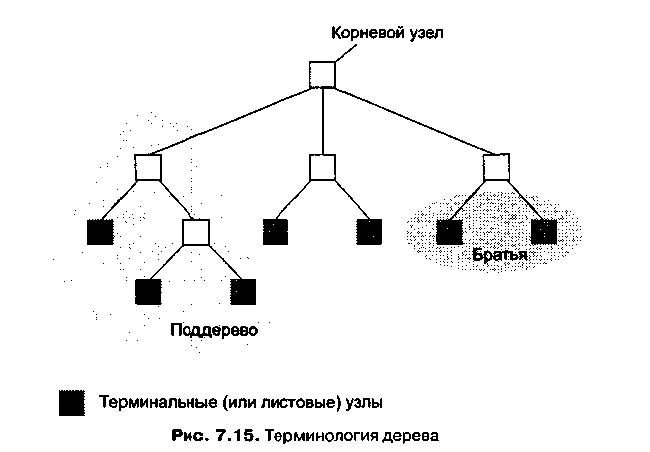
Рисунок 5 – Терминология дерева
Каждый элемент дерева называется узлом (node) (рис. 5). Узел, находящийся наверху, называется корневым (root node). Если перевернуть рисунок вверх ногами, этот узел будет находиться на месте основания или корня дерева. Узлы на противоположном конце дерева называются терминальными (terminal node) (или листовыми). Если мы выберем любой нетерминальный узел дерева, то обнаружим, что он вместе с узлами, находящимися ниже, также образует дерево. Эти меньшие структуры называются поддеревьями (subtrees). Иногда мы рассматриваем структуру деревьев так, как если бы каждый узел порождал узлы, находящиеся сразу же под ним. Так определяются предки и потомки. Потомки узла называются дочерними узлами (children), а его предок — родителем (parent). Узлы, имеющие одного и того же родителя, называются братьями (siblings). И, наконец, можно определить глубину дерева (depth) как количество узлов в наиболее длинном пути от корня до листа. Другими словами, глубина дерева — это количество горизонтальных уровней в нем.
На следующих занятиях мы часто будем встречаться с деревьями, поэтому сейчас нет необходимости работать над приложениями. Далее в этом теме и во время обсуждения организации индексов в следующей теме мы увидим, что данные, в которых требуется проводить быстрый поиск данных, часто организованы в виде дерева, а позже мы узнаем, как можно проанализировать игру в терминах деревьев.
Для обсуждения способов хранения деревьев мы ограничимся бинарными деревьями (binary tree), то есть деревьями, где у каждого узла может быть максимум два потомка. Подобные деревья обычно хранятся в памяти при помощи связной структуры, похожей на связные списки. Но в этом случае каждая запись (или узел) бинарного дерева состоит не из двух компонентов (данные и указатель на следующую запись), а из трех: (1) данные, (2) указатель на первого потомка узла и (3) указатель на второго потомка узла. Хотя в компьютере не различаются лево и право, полезно считать первый указатель указателем на левого потомка, а второй — указателем на правого потомка, отображая таким образом способ рисования дерева на бумаге. Каждый узел дерева представлен небольшим непрерывным блоком ячеек памяти, формат которых показан на рис. 6.

Рисунок 6 – Структура узла в бинарном дереве
Хранение дерева в памяти включает поиск свободных блоков ячеек памяти для записи узлов и связывание этих узлов согласно желаемой структуре дерева. Это означает, что в каждый указатель должен быть записан адрес левого или правого потомка соответствующего узла, или ему должно быть назначено значение NIL, если в этом направлении дерева более нет узлов. Таким образом, терминальный узел отличается тем, что значения обоих его указателей равны NIL. Наконец, перейдем к специальному месту в памяти, называемому корневым указателем (root pointer), где хранится адрес корневого узла. При помощи корневого указателя осуществляется первоначальный доступ к дереву.
Концептуальная схема структуры бинарного дерева существенно отличается от возможной схемы фактической организации дерева в компьютерной памяти (рис. 7). Обратите внимание, что в действительности узлы в оперативной памяти компьютера расположены не так, как на абстрактной схеме дерева. Блоки памяти, представляющие отдельные узлы, могут быть разбросаны по достаточно большой области памяти. Однако, следуя корневому указателю, мы всегда можем найти корневой узел и от него проследить любой путь вниз по дереву, проходя по соответствующим указателям от узла к узлу.

Рисунок 7 – Концептуальная и фактическая организация бинарного дерева при помощи связной системы хранения

Рисунок 8 – Хранение дерева без указателей
Альтернативой связной системе хранения бинарных деревьев является способ выделения непрерывного блока ячеек памяти, запись корневого узла в первые ячейки (для простоты предполагаем, что для хранения каждого узла дерева требуется одна ячейка памяти), запись левого потомка корневого узла во вторую ячейку, правого потомка — в третью и т. д. Общая концепция этого метода — левый и правый потомки узла, находящегося в ячейке п, записываются в ячейки 2п и 2п + 1 соответственно. Ячейки блока, в которых не хранятся узлы текущей структуры дерева, помечены определенным набором битов, указывающим отсутствие данных. На рис. 8 показано, как будет храниться дерево
с использованием этого способа. Обратите внимание, что узлы, находящиеся на одном уровне, записываются друг за другом одним блоком. Таким образом, первой записью в блоке является корневой узел, за ним — потомки корневого узла, затем — внуки корневого узла и т. д.
С добавлением и удалением данных в динамические структуры занимается и освобождается пространство для хранения. Процесс восстановления незадействованного пространства для будущего использования называется сбором мусора. Сбор мусора требуется в различных условиях. Диспетчер памяти в операционной системе должен производить сбор мусора по мере выделения и восстановления пространства в памяти. Диспетчер файлов проводит сбор мусора во время записи и удаления файлов с носителей компьютера. Более того, любому процессу, выполняющемуся под управлением диспетчера, может понадобиться произвести сбор мусора в пределах выделенного ему пространства в памяти.
В процессе сбора мусора есть несколько коварных проблем. В случае связных структур при каждом изменении значения указателя на элемент данных сборщик мусора должен решать, нужно ли восстанавливать область памяти, на которую ранее указывал этот указатель. Проблема усложняется в переплетенных структурах данных, включающих множество путей указателей. Неправильная работа сборщика мусора может привести к потере данных или к неэффективному использованию пространства хранения. В частности, если сборщик не будет восстанавливать пространство, доступное место в памяти будет постепенно сокращаться; этот процесс называется утечкой памяти (memory leak).
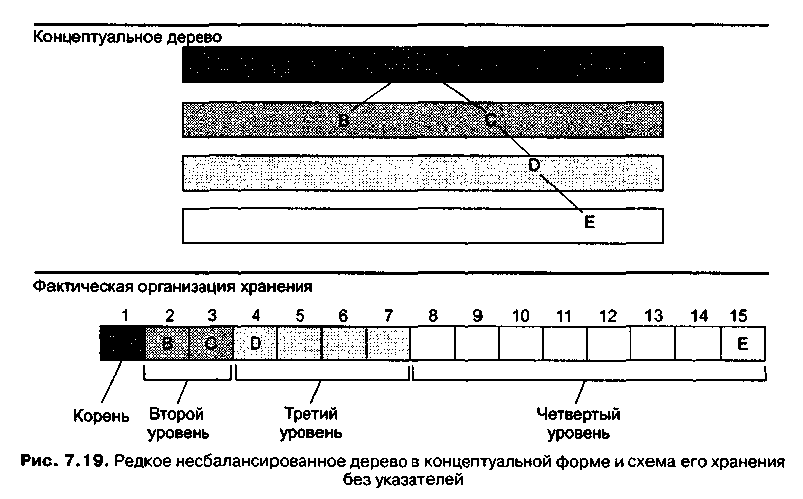
Рисунок 9 – Редкое несбалансированное дерево в концептуальной форме и схема его хранения без указателей
В отличие от описанной ранее связной системы, эта альтернативная система хранения обеспечивает удобный способ поиска родителей или братьев каждого узла. (Конечно, это можно сделать и в связной структуре, задействовав дополнительные указатели.) Положение родителя узла определяется путем деления адреса этого узла на 2 без учета остатка (родитель узла по адресу 7 — это узел по адресу 3). Если узел находится на четном месте, для поиска его брата нужно добавить 1 к адресу этого узла, а если на нечетном — отнять единицу (брат узла на 4 позиции — это узел на 5 позиции; брат узла на 3 позиции — это узел на 2 позиции). Помимо этого такая система хранения предполагает эффективное использование пространства, если бинарные деревья практически сбалансированы (то есть оба поддерева, находящиеся ниже корневого узла, имеют одинаковую глубину) и полные (в деревьях нет длинных тонких ветвей). Если же деревья не отвечают этим характеристикам, такая система станет довольно неэффективной (рис. 9).
Как и для других структур, которые мы уже изучали, полезно отделить технические детали реализации деревьев от прочих составляющих приложения. Поэтому программист обычно выделяет действия, которые будут производиться с деревом, и пишет для их выполнения процедуры, которые затем используются для доступа к дереву из других частей программы. Эти процедуры вместе с областью хранения составляют пакет, применяемый как абстрактный инструмент.
Чтобы продемонстрировать такой пакет, вернемся к вопросу хранения списка имен в алфавитном порядке. Мы предполагаем, что с этим списком можно выполнять следующие действия:
♦ искать, существует ли определенная запись;
♦ печатать список в алфавитном порядке;
♦ вставлять новую запись.
Наша цель — разработать систему хранения и набор процедур для выполнения этих операций.
Начнем с обсуждения вариантов процедур поиска в списке. Если список создан на основе модели связного списка, поиск в нем придется осуществлять последовательно, а этот процесс, как мы узнали ранее, крайне неэффективен в длинных списках. Таким образом, надо найти способ реализации, позволяющий использовать алгоритм бинарного поиска. Для применения этого алгоритма в системе хранения должен быть возможен поиск центральных записей в последовательно уменьшающихся блоках списка. Это несложно сделать в непрерывном списке, так как адрес центральной записи можно вычислить, так же как местоположение записей в массиве. Но при использовании непрерывных списков возникают проблемы с добавлением элементов, рассмотренные ранее.
Эту проблему можно решить хранением списка в связном бинарном дереве вместо какой-либо традиционной системы хранения списков. Центральная запись списка становится корневым узлом, центральная запись первой половины списка — левым потомком корня, а центральная запись второй половины — правым потомком. Центральные записи оставшихся четвертей списка становятся потомками детей корня и т. д. Например, бинарное дерево на рис. 20 представляет список букв А, В, С, D, E, F, G, H, I, J, К, L и М. (Если часть списка состоит из четного количества записей, центральной мы будем считать запись с большим значением.)

Рисунок 10 – Буквы от А до М, организованные в упорядоченное дерево
Для осуществления поиска в списке, хранящемся таким образом, мы сравниваем значение, которое требуется найти, со значением в корневом узле. Если они равны, поиск успешно завершен. Если они не равны, то, в зависимости от того, меньше или больше искомое значение корневого, мы переходим, соответственно, к левому или правому потомку — который становится корневым узлом поддерева, в котором будет продолжаться поиск. Процесс сравнения и перехода к потомку продолжается до тех пор, пока искомое значение не будет найдено (то есть поиск завершится успешно) или пока мы не достигнем пустого указателя, не найдя искомое значение (то есть поиск завершится неудачей).
Листинг 1 показывает, как может быть реализован такой процесс поиска в связном бинарном дереве. Обратите внимание, что приведенная процедура является усовершенствованием обсуждавшейся ранее процедуры — исходного варианта реализации бинарного поиска. Различия между ними чисто внешние. В первой процедуре поиск осуществлялся в последовательно уменьшающихся частях списка, а в последней (листинг 1) — в последовательно уменьшающихся поддеревьях (рис. 11).
Листинг 1. Бинарный поиск в списке, реализованном в виде связного бинарного дерева
procedure SearchCTree. TargetValue)
if (корневой указатель дерева Tree = NIL)
then (Объявление неудачного завершения поиска)
else (Выполнение одного из блоков операций, приведенных ниже, в соответствии с подходящим вариантом)
case I: TargetValue = значение корневого узла
(Поиск завершен успешно)
case 2: TargetValue < значения корневого узла
(Вызов процедуры Search для поиска TargetValue в поддереве, определенном указателем на левого потомок корня, и получения отчета о результатах поиска)
case 3: TargetValue > значения корневого узла
(Вызов процедуры Search для поиска TargetValue в поддереве, определенном указателем на правого потомка корня, и получения отчета о результатах поиска)
) end if
Поскольку естественное последовательное расположение элементов списка было изменено в целях упрощения поиска, вы можете подумать, что процесс печати списка в алфавитном порядке теперь усложнится. Выясняется, однако, что это предположение неверно. Для выполнения этой операции нам необходимо просто напечатать в алфавитном порядке левое поддерево, затем корневой узел, а после этого — правое поддерево (рис. 22). Мы знаем, что элементы в левом поддереве меньше элемента в корневом узле, а записи в правом поддереве, наоборот, больше. Так выглядит набросок процедуры печати:
if (дерево не пусто)
then (печать левого поддерева в алфавитном порядке:
печать корневого узла;
печать правого поддерева в алфавитном порядке)

Рисунок 11 – Последовательно уменьшающиеся поддеревья, в которых производится поиск буквы J согласно процедуре (листинг 1)
Вы можете возразить, что эта схема не приближает нас к разработке полной процедуры печати, так как включает задачи печати левого и правого поддеревьев в алфавитном порядке, в точности повторяющие нашу исходную задачу. Однако печать поддерева — это меньшая по размерам задача по сравнению с печатью целого дерева. Таким образом, в решение проблемы печати дерева входят решения меньших задач печати поддеревьев, что приводит к идее рекурсивного подхода.
Следуя этой идее, мы можем расширить наш набросок до полной процедуры печати дерева, написанной на псевдокоде (листинг 2). Мы назначили процедуре имя PrintTree и вызываем PrintTree для печати левого и правого поддеревьев. Обратите внимание, что условие завершения рекурсивного процесса (получение

Рисунок 12 – Печать дерева поиска в алфавитном порядке
пустого поддерева) будет гарантированно достигнуто, так как при каждом новом вызове процедура работает с поддеревом, меньшим по размеру, чем предыдущее.
Листинг 2. Процедура печати данных бинарного дерева
procedure PrintTree (Tree)
if (дерево Tree не пусто)
then
(Применение процедуры PrintTree к дереву на левом узле дерева Tree;
Печать корневого узла дерева Tree;
Применение процедуры PrintTree к дереву на правом узле дерева Tree)
Задача добавления новой записи в дерево также проще, чем может показаться на первый взгляд. Можно решить, что для получения необходимого для добавления определенных элементов пространства может потребоваться разрезать дерево, но в действительности любой добавляемый узел может быть присоединен к дереву как новый лист, независимо от его значения. Чтобы найти подходящее место для новой записи, мы следуем вниз по дереву по тому же пути, по которому шли бы для поиска этой записи. Так как такого значения в дереве нет, в конце концов, мы придем к пустому указателю. Это и будет подходящим местом для нового узла (рис. 23). Действительно, мы нашли место, к которому нас приведет поиск нового значения.
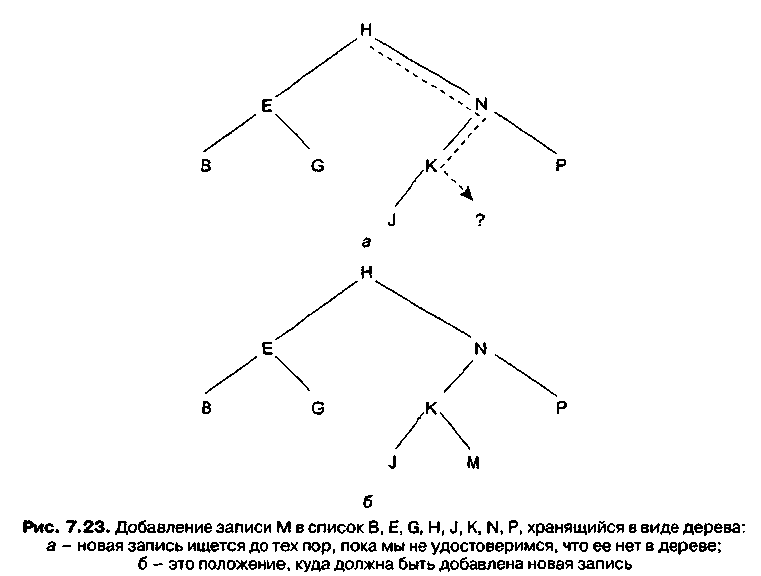
Рисунок 13 – Добавление записи М в список, хранящийся в виде дерева: а – новая запись ищется до тех пор, пока мы не удостоверимся. Что ее нет в дереве; б – это положение, куда должна быть добавлена новая запись
Процедуру, реализующую этот процесс в случае связного дерева, содержит листинг 3. Сначала в дереве проводится поиск вставляемого значения (оно называется NewValue), затем на место пустого указателя помещается указатель на новый листовой узел, содержащий NewValue. Если же значение, которое мы хотим вставить в дерево, найдено при поиске, оно повторно не добавляется.
Листинг 3. Процедура для добавления новой записи в список, хранящийся в виде бинарного дерева
procedure Insertdree, NewValue)
if (Корневой указатель дерева Tree = NIL)
then (Корневой указатель переопределяется и указывает на новый лист,
содержащий NewValue)
else (Выполнение одного из блоков операций ниже в соответствии с подходящим вариантом)
case I: NewValue - значение корневого указателя
(Ничего не делать)
case 2: NewValue < значения корневого указателя
(if (указатель на левого потомка корневого узла = NIL)
then (Этот указатель переопределяется и указывает на новый лист, содержащий NewValue)
else (Применение процедуры Insert для добавления NewValue в поддерево, определяемое указателем на левого потомка)
case 3: NewValue > значения корневого указателя
(if (указатель на правого потомка корневого узла = NIL)
then (Этот указатель переопределяется и указывает на новый лист, содержащий NewValue)
else (Применение процедура Insert для добавления NewValue в поддерево, определяемое указателем на правого потомка) )
) end if
Резюмируем, что программный пакет, состоящий из структуры связного дерева и процедур для поиска, печати и добавления записей, является полным и может использоваться как абстрактный инструмент нашим гипотетическим приложением.