

Garbage / Информатика / 2.1.2.2 - Коды Хаффмана
.pdfКоды Хаффмана
Рассмотрение кодов Хаффмана начнем с кодирования в двоичном алфавите. Термин символ источника применяется здесь для обозначения входов si, а
кодовый алфавит — для обозначения алфавита, в который происходит кодирование.
Доказательство свойств кодирования, а также метод кодирования основаны на том, что на каждом шаге происходит сведение кода к более укороченному. Объединим два наименее вероятных символа алфавита источника в один символ, вероятность которого равна сумме соответствующих вероятностей. Таким образом, нужно построить код для источника, у которого число символов уменьшилось на 1. Повторяя этот процесс несколько раз, приходим к более простой задаче кодирования источника, алфавит которого состоит из символов 0 и 1. Возвращаясь на один шаг назад, имеем, что один из символов нужно разбить на два символа; это можно сделать, добавив к соответствующему кодовому слову символ 0 для одного из символов и символ 1 - для другого. Возвращаясь еще на один шаг назад, нужно таким же образом разбить один из трех имеющихся симво-
Рис. 2.1. Схема посимвольного кодирования по Р. Фано
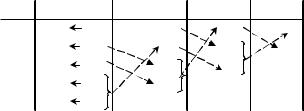
лов на два символа, и так далее. На рис. 2.2 показан процесс редукции для одного частного случая, а на рис. 2.3 - соответствующий процесс разбиения (расширения). На основании этого рассмотрения общий случай становится очевидным.
Почему этот процесс порождает эффективный код? Предположим, что существует более короткий код, т. е. такой, у которого средняя длина L' удовлетворяет условию L' < L. Сравним два дерева декодирования. В эффективном двоичном коде все концевые вершины должны быть заняты и не должно быть мертвых ребер. (Наличие мертвого ребра позволяет уменьшить длину кода, удаляя соответствующий двоичный символ из всех концевых вершин, путь к которым проходит через эту бесполезную точку.)
Если в дереве есть только два слова максимальной длины, они должны иметь общую последнюю вершину ветвления и соответствовать двум наименее
вероятным |
символам. |
|
До редукции дерева эти два символа дают вклад |
||||||||||||||||||||||
lq ( pq + pq−1) , |
а |
после |
редукции, (lq −1)( pq + pq−1) , |
так |
что |
средняя |
длина |
кода |
|||||||||||||||||
уменьшается до ( pq + pq−1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
S i |
|
P i |
|
|
|
|
|
|
|
S i |
|
P i |
|
|
|
|
|
|
0 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
S 1 |
|
0,4 |
|
|
0,4 |
|
0,4 |
0,6 |
|
S 1 |
|
1 |
|
|
|
|
0,4 |
1 |
0,4 |
1 |
0,4 |
1 |
0,6 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
S 2 |
|
0,2 |
|
|
0,2 |
|
0,4 |
0,4 |
|
S 2 |
|
01 |
|
|
0,2 |
01 |
0,2 |
01 |
0,4 |
00 |
0,4 |
1 |
||
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
S 3 |
|
0,2 |
|
|
0,2 |
|
0,2 |
|
|
S 3 |
|
000 |
|
|
0,2 |
000 |
0,2 |
000 |
0,2 |
01 |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
S 4 |
|
0,1 |
|
|
0,2 |
|
|
|
|
S 4 |
|
0010 |
|
|
0,1 |
0010 |
0,2 |
001 |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
S 5 |
|
0,1 |
|
|
|
|
|
|
|
S 5 |
|
0011 |
|
|
0,1 |
0011 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
Первона- |
Первая |
|
Вторая |
Третья |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
чальный |
редукция |
|
редукция |
редукция |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
источник |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
Рис. 2.2. |
Процесс редукции |
|
|
|
Рис. 2.3. Процесс разделения |
|
|
|||||||||||||||
Если число слов максимальной длины больше двух, то можно использовать следующее предположение: кодовые слова одинаковой длины можно переставлять, не уменьшая средней длины кода. На основе этого предположения можно считать, что два наименее вероятных символа имеют одну и ту же вершину последнего ветвления. Таким образом, после редукции средняя длина кода уменьшилась на ( pq + pq−1) .
Итак, в любом случае можно укоротить код и уменьшить среднюю длину кода на одну и ту же величину.
Применим эту процедуру к двум сравниваемым деревьям декодирования. Поскольку обе средние длины уменьшились на одну и ту же величину, неравенство между средними длинами сохранится. Повторное применение этой процедуры сводит оба дерева к двум символам. Для кода Хаффмана средняя длина равна 1, для другого кода она должна быть меньше 1, что невозможно.
Таким образом, код Хаффмана является самым коротким из возможных кодов. Процесс кодирования неоднозначен в нескольких отношениях, Во-первых, сопоставление символов 0 и 1 двум символам источника на каждом этапе
разбиения является произвольным, что, однако, приводит лишь к тривиальным различиям. Во-вторых, в случае, когда вероятности двух символов равны, неважно, какой из символов поставить в таблице выше другого. Полученные коды могут иметь различные длины кодовых слов, однако средние длины кодовых слов для двух кодов совпадают.
Для двух различных кодов Хаффмана рассмотрим вероятности p1 = 0,4; р2 =
0,2; р3 = 0,2; р4 = 0,1; р5 = 0,1.
Если помещать склеенные состояния как можно ниже, то получаем длины
(1,2,3,4,4) и средняя длина равна L = 0,4 (l) + 0.2 (2) + 0,2 (3) + 0,l (4) + 0,l (4) = 2,2.
Если, с другой стороны, ставить склеенные состояния как можно выше (рис. 2.4), то получим длины (2, 2, 2, 3, 3) и средняя длина равна
L = 0,4 (2) + 0,2 (2) + 0,2 (2) + 0,1 (3) + 0,1 (3) = 2,2.
Оба кода имеют одинаковую эффективность (среднюю длину), но разные наборы длин кодовых слов.
S i |
|
P i |
|
|
|
|
|
|
|
S 1 |
00 |
0,4 |
00 |
0,4 |
00 |
0,4 |
1 |
0,6 |
0 |
S 2 |
10 |
0,2 |
10 |
0,2 |
01 |
0,4 |
00 |
0,4 |
1 |
S 3 |
11 |
0,2 |
11 |
0,2 |
10 |
0,2 |
01 |
|
|
S 4 |
010 |
0,1 |
010 |
0,2 |
11 |
|
|
|
|
S 5 |
011 |
0,1 |
011 |
|
|
|
|
|
|
Рис. 2.4.
Какой из этих двух кодов следует выбрать? Более разумным выбором является тот, при котором длина меньше меняется по ансамблю сообщений. Поэтому следует вычислить дисперсию длины. Другой метод кодирования для каждого из этих двух случаев:
Var(I) = 0,4 (1 - 2,2) 2 + 0,2 (2 - 2,2) 2 + 0,2 (3 - 2,2) 2 + 0,1 (4 - 2,2) 2 + 0,1 (4 - 2,2) 2 = 1,36;
Var (II) = 0,4 (2 - 2,2) 2 + 0,2 (2 - 2,2) 2 + 0,2 (2 - 2,2) 2 + 0,1 (3 - 2,2) 2+0,1 (3 - 2,2) 2 = 0,16.
Таким образом, при использовании для кодирования сообщений конечной длины второй код имеет существенно меньшую дисперсию длины и поэтому, возможно, является более предпочтительным. Весьма вероятно, что, помещая склеенное состояние возможно выше, получим код с наименьшей дисперсией.