

Создание упорядоченного списка.
Для получения упорядоченного списка вовсе не обязательно сортировать его после построения, достаточно добавлять новый элемент таким образом, чтобы список все время оставался упорядоченным. Такой метод позволяет иметь упорядоченный список на каждом шаге. Ключом, по которому производиться упорядочивание будем считать значение информационного поля Data. Структура узла списка выглядит следующим образом:
type
PElem = ^Elem;
Elem = record
Data : Integer; {Данные, хранящиеся в узле списка –целое число}
Next : PElem;
end;
При добавлении нового элемента в такой список необходимо предусмотреть следующие варианты:
добавление в пустой список;
добавление в начало списка, когда новый элемент меньше существующего первого;
добавление в середину существующего списка на подходящее место (частный случай этой ситуации – добавление в конец списка).
В третьем случае требуется сначала определить место, куда следует вставить новый элемент. Для этого будем двигаться по списку до тех пор, пола либо не найдется элемент, больший или равный вставляемому, либо не будет достигнут конец списка. Воспользуемся дополнительным указателем на предыдущий элемент – Pre. Все это учтено в процедуреInsert. Параметры процедурыP- указатель на начало списка, e - значение нового элемента.
procedure Insert(var p: PElem; e: Integer);
// p - указатель на список, e - значение нового элемента
var Temp,Pre,This: PElem;
Found: Boolean; // признак того, что место для вставки найдено
begin
if p=nil then
begin // список пуст, создание первого элемента, вариант 1.
new(p);
with p^ do begin
Data:=e;
Next:=Nil;
end;
end
else
begin // вставка элемента в список, варианты 2, 3
if e<=p^.Data then
begin // вставка перед списком, вариант 2
new(This);
with This^ do begin
Data:=e; Next:=p
end;
p:=This; // новое начало списка
end
else
begin // поиск места и вставка, начиная со второго элемента, вариант 3
found:=false; // место не найдено
This:=p^.Next; // текущий элемент равен второму
Pre:=p; // предыдущий равен первому
while not found and (This<>Nil) do // поиск места для вставки
if e<=This^.Data then
found:=true // место найдено
else
begin // двигаемся дальше по списку, запоминая адрес
// предыдущего элемента в переменной Pre
Pre:=This; This:=This^.Next;
end;
// добавляем новый элемент со значение е между Pre и This
new(Temp);
with Temp^ do begin
Data:=e; Next:=This;
end;
Pre^.Next:=Temp;
end
end
end;
Процедура Insert корректно работает в случае, если новый элемент необходимо добавить в конец списка (при поиске подходящего места по условию e<=This^.Data дошли до конца списка). При этом значение This=nil будет записано в поле Next последнего элемента.
Использование упорядоченного связного списка для частотного анализа данных
В качестве примера использования упорядоченного списка рассмотрим построение частотного распределения целых чисел. Эта задача возникает при анализе данных, когда необходимо определить, сколько и какое число встретилось раз, т.е. определить частоту появления каждого числа.
Решение заключается в следующем. Создадим список, который будет содержать числа. Если число встретилось первый раз, то оно заноситься в список. Если такое число уже есть в списке, то увеличивается счетчик появления этого числа. Поэтому внесем некоторые изменения в описание элемента списка Elem, добавив новое целочисленное полеcnt, которое будет являться счетчиком повторений. В основе алгоритма лежит процедураAdd(), всегда вставляющая новый элемент в упорядоченный список. Однако теперь требуется дополнительная проверка на наличие в списке значения. В остальном процедураAdd() аналогична процедуреInsert() описанной выше.
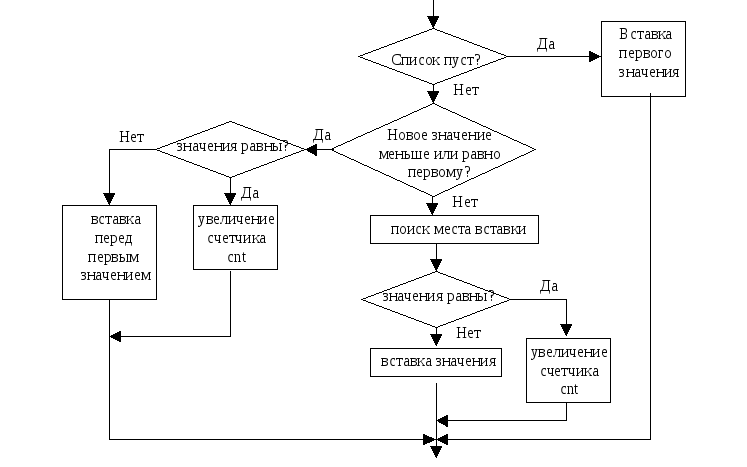
Рис.5 Блок-схема обработки значения при частотном анализе.
Листинг программы частотного анализа целых чисел.
program testsortlist;
{$APPTYPE CONSOLE}
type
PElem=^Elem;
elem=record
Data: integer; // значение
Cnt:integer; // число повторений данного значения
next: pelem;
end; {record}
var top: pelem; // указатель на начало частотного списка
N:integer;
Procedure Lists(p:pelem); // процедура вывода списка на экран, p – указатель на начало
begin
while p<>Nil do
begin writeln(p^.Data,' - ',P^.cnt); p:=p^.next; end;
writeln;
end;
Procedure Del(var p:pelem); // процедура удаления списка, p – указатель на начало
var g:pelem;
begin
while p<>nil do
begin g:=p; p:=p^.next; dispose(g); end;
end;
Procedure add (var Head:pelem; X:integer);// добавление значения Х в список Head
var Pre,This:Pelem;
Found:boolean;
Procedure Insert; { Процедура Insert вставляет новый элемент между Pre и This, учитывая случаи создания первого элемента и добавления в середину или конец существующего}
var P:Pelem;
begin
New(p);
P^.Data:=X;
P^.next:=This;
P^.Cnt:=1;
If pre= nil then
Head:=P //1-й элемент или добавление перед первым
else
Pre^.next:=P; // середина или конец
end;
begin
Pre:=Nil;
This:=Head;
Found:=False;
While (This<>Nil) and not Found Do // Поиск подходящего места вставки
if This.Data >= X then
Found:=True // место найдено
else begin
pre:=This; // место не найдено, переходим к следующему элементу списка
This:=This^.next;
end;
if not found then
Insert // дошли до конца списка или список пуст
else if This^.Data=X then // нашли место
Inc(This^.Cnt) // значения равны – увеличиваем счетчик
else
Insert; // значение больше Х, вставка перед элементом This
end;
begin {Начало программы. Вводим и анализируем числа. Ввод числа 999 – признак окончания ввода значений }
top:=Nil; {инициализациа списка}
Repeat
Write('Input N , (999-Exit) --> ');
Readln(n);
If N <> 999 then Add(top,N); {Добавление числа N в список Top}
until n=999;
Lists(top); { Вывод частотного списка на экран}
Del(top); {Удаление списка}
readln;
end.
Стеки
Еще одной известной и широко используемой структурой данных является стек. Стек представляет собой структуру, которая позволяет выполнять две основных операции: заталкивание для вставки элемента в стек и выталкивание с целью считывания данных из стека. Структура устроена таким образом, что операция выталкивания всегда возвращает элемент, вставленный в стек последним (самый “новый” элемент в стеке). Другими словами, элементы в стеке считываются в порядке, обратном порядку их записи в стек. Благодаря такому устройству стек известен как контейнер магазинного типа.

Рис.6 Операции заталкивания и выталкивания для стека
Написание кода стека не представляет никаких трудностей. Причем существуют два варианта реализации: первый - на основе односвязного списка, второй - на основе массива. Как и в случае со списками, будем считать, что записываться и считываться из стека будут целые числа. Рассмотрим организацию стека на базе связного списка.
В реализации стеков на основе односвязных списков операция заталкивания представляет собой вставку элемента в начало списка, а операция выталкивания - удаление элемента из начала списка и считывание его данных. Обе операции не зависят от количества элементов в списке, следовательно, их можно отнести к классу О(1).
Для работы со стеком необходимы следующие операции:
Инициализация стека, т.е. подготовка структуры.
Включение нового элемента в стек (заталкивание)
Проверка стека на пустоту.
Извлечение элемента из стека (выталкивание).
Реализовать работу стека можно в модуле, объявив в интерфейсной части минимальный набор процедур и функций:
Procedure Push(var Top:PElem; N:integer);
Процедура Push добавляет новый элемент в стек. Параметры процедуры : Top – указатель на начало стека, N – значение нового элемента. Обратите внимание, что параметр Top является параметром-переменной, т.к. при добавлении нового элемента всегда будет меняться и адрес начала стека.
Procedure Pop(var Top:PElem; var N:integer);
Процедура Pop извлекает из стека значение первого элемента через параметр-переменную N, удаляет первый элемент и переставляет указатель Top на следующий элемент. Параметры процедуры: Top – указатель на начало стека, N – передаваемое в программу значение первого элемента.
Function IsEmpty(Top:PElem):Boolean
Функция IsEmpty возвращает значение true, если стек пуст (если указатель на начало стека пустой). Параметр функции: Top – указатель на начало стека.
Перед вызовом процедуры Pop пользователь должен проверить есть ли элементы в стеке с помощью функции IsEmpty. Попытка извлечения элемента из пустого стека вызовет ошибку. Приведем листинг модуля Steck. Инициализацию стека необходимо сделать в программе до использования процедур и функций из модуля.
Листинг модуля Steck
Unit Steck;