

arx011010_ch1
.pdfзащиты. Однако для создания защищенных подсистем в рамках одной задачи, для того, чтобы изменять возможности доступа, когда точка выполнения переходит через различные программы, управляющие ее решением, необходимо связать с каждой задачей множество доменов защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств.
3.7.Структурные методы повышения быстродействия памяти
1. Пакетная обработка множества доступов к памяти.
При выборке команд, исключая переходы и ветвления, команды считываются последовательно из соседних ячеек памяти. Если реализовать одновременный доступ к содержимому определенного числа соседних ячеек памяти, реализовать выбор кванта соседних ячеек - гиперслова в регистры, то затем данные можно брать из регистра.
2. Конвейерная обработка запросов к памяти.
Архитектура конвейера (pipelining) позволяет начать цикл считывания из памяти, не дожидаясь окончания считывания текущего. При этом очередной доступ выполняется, не дожидаясь окончания предыдущего (если запросы независимы). Для этого память разбивается на множество банков и составляется очередь запросов к памяти. Если запрашиваются данные из разных банков, то последующий запрос можно делать, не дожидаясь окончания предыдущего запроса.
3. 8. Кэш-память
Кэш-память − быстродействующая буферная память, расположенная между процессором и основной памятью. Реализуется на всех микропроцессорах, причем, иногда, раздельно для данных и для команд.
Алгоритмы и аппаратура кэширования используются также для выравнивания скоростей работы оперативной и массовой памятей. Кэширование используется также при работе с внешними накопителями. Обычно, для основной памяти в 32-64 Мбайт устраивается кэш в 64-256 Кбайт, с быстродействием в 5-10 раз выше основной.
В кэш-память из оперативной переписываются данные, к которым обращается процессор (при первом обращении), и из кэша производится выборка этих данных при последующих обращениях. Так как скорость работы кэша выше оперативной, процесс вычислений ускоряется. Обычно перепись производится блоками, сразу по несколько слов. Если есть запрос к слову, которое есть кэше, то считывание производится из кэша и операция завершается (кэш-попадание). Если запрашиваемого данного нет в кэше ("промах" кэша), оно считывается в кэш и передается в процессор. При этом возможно вытеснение из кэша данных, размещенных в нем ранее. При записи в кэш используются различные стратегии обновления основной памяти. При работе с кэшем используются различные механизмы преобразования адреса основной памяти в адрес кэш-памяти и определения самого факта наличия нужного данного в кэш-памяти. Рассматриваются три основные схемы управления кэш памяти: ассоциативная, с прямым отображением и частично ассоциативная.
Итак, имеется буферная память данных (ПД) в которой могут храниться блоки данных основной памяти. С каждым блоком ПД связан номер этого блока в основной памяти.
Рассматриваются две основные схемы управления кэш памяти: ассоциативная и с прямым отображением для памяти со следующими параметрами.
Пусть емкость кэша: 2К слов (128 блоков по 16 слов), а основной памяти: 256К
слов - 16384 (128*128) блока по 16 слов.
Адрес основной памяти - 18 бит: 14 - адрес блока, 4 - адрес слова в блоке (сдвиг). Обмен между памятями производится блоками по 16 слов.
3.8.1. Управление работой КЭШа
Обычно устройства управления КЭШем позволяют производить принудительное обновление КЭШа, закачивать данные наперед, отключать кэш.
51
Протокол bus-snooping позволяет CPU получать доступ к информации из КЭШей других
CPU.
Увеличение быстродействия кэш-памяти:
•использование двухуровневой кэш-памяти;
•разделение КЭШей: память для команд и память для данных;
•использование обходного кэш-буфера.
КЭШи в настоящее время имеются двух уровней: процессорный кэш и системный кэш.
Системный кэш обычно служит для согласования работы массовой памяти и ОЗУ процессора. Может быть организован в ОЗУ, причем его размер может задаваться пользователем. Есть рекомендации по использованию в процессорном КЭШе отсроченный способ записи, а в КЭШе второго уровня − прямой способ записи.
Обходной буфер в КЭШе используется при чтении кванта из ОЗУ в кэш; одновременно с записью в кэш, первые строки КЭШа передаются в процессор.
Особенности использование КЭШа.
Кэш данных эффективно используется, если все данные, выбранные за один квант обмена, используются в программе. Кэш команд может эффективно использоваться при выполнении циклов, все команды которого помещаются кэш без перезаписи. Большая роль здесь принадлежит алгоритмам управления КЭШем: стратегии обновления основной памяти и стратегии замещения.
3.9. Архитектура ассоциативной памяти
Доступ к оперативной памяти может производиться также методом ассоциативного поиска, а не по адресам.
Для широкого класса предметных областей представляет интерес архитектура памяти, адресуемая по содержанию, - ассоциативная память. Более того, такая память может быть использована как самостоятельный механизм для накопления и поиска знаний в виде структурированных последовательностей. LEAP - один из первых языков манипулирования ассоциативными структурами данных.
Ассоциативная память - запоминающее устройство, из которого записанные данные могут быть выбраны по любому из записанному в него элементу (элементам), используемому в качестве адреса выборки.
Более конструктивное определение ассоциативной памяти как памяти с одновременным или параллельным доступом ко всем элементам с использованием содержимого данных, а не их адресов.
Ассоциативный поиск может быть произведен в памяти специального вида: ассоциативной. При этом память рассматривается как таблица, в которой некоторые столбцы являются ключевыми и в них производится поиск по заданному образцу (ключу). При отождествлении, в найденной строке таблицы, остальные разряды являются результатом поиска. Аналогия: телефонный справочник, в котором обычный поиск - это задание страницы, строки книги (поиск ФИО и номера телефона), а ассоциативный - поиск ФИО по N телефона. Ассоциативная память - дорога, особенно больших объемов. Способы реализации ассоциативной памяти:
1.Электронные логические схемы по технологии БИС. Используются в качестве буферной памяти, кэш-памяти в процессорах. Реализация такой памяти больших объемов пока недостижимо.
2.Имитация ассоциативной памяти на адресных запоминающих устройств. По этому методу, задаваемый параметр для поиска: образец-ключ с помощью некоторой функции f(k) преобразуются в адрес ячейки памяти, где хранится данное, соответствующее (ассоциативное) этому ключу. Эти методы называются ключевым кодированием, ключевой адресацией, хеш-адресацией (hash addressing), хешированием
52
(hashing). Используются также для организации таблиц идентификаторов при программировании трансляторов. Тривиальный метод хеширования для ключейидентификаторов состоит в выборе в качестве результата (адреса данного) двоичное представление текстовых идентификаторов. При такой адресации требуется память, размер, который (максимальный адрес) должен совпадать с максимально возможным значением результата хеширования. Модификацией приведенной схемы является выбор в качестве функции хеширования следующий алгоритм: цифровое представление ключа делится на n - число ячеек памяти, выделенное для работы; причем остаток - целое из интервала [0,n-1] и используется в качестве адреса. При использовании этого и большинства других алгоритмов хеширования возникает проблема конфликтов (коллизий) адресов. Коллизия происходит тогда, когда для различных ключей к1 и к2, результаты хеширования f(k1)=f(k2). Для разрешения коллизии используются различные методы рехеширования, например, хранение конфликтующих элементов в резервной памяти.
Данное представление ассоциативной памяти наиболее распространенное. Алгоритмы (ре)хеширования выбираются с учетом особенностей предметной области. Возможна аппаратная поддержка алгоритмов: реализация функции хеширования в виде команды, использования "настоящей" ассоциативной памяти для хранения конфликтующих элементов и т.д. Существуют реализации ассоциативного поиска по нескольким ключам.
3.Голографическая ассоциативная память. Пока известны модельные разработки.
3.10.Внешние накопители (ВЗУ)
Для хранения программ и данных вне процессора и его ОЗУ в ЭВМ используются накопители (внешние накопители).
Таковыми вначале были перфокарты, перфоленты, перфорированная кинолента (Урал), магнитные ленты (МЛ), магнитные диски (МД), магнитные барабаны (МБ).
Винчестеры. Абривиатура HDD расшифровывается как Hard Disk Drive что означает - жесткий диск. Это устройство компьютера предназначено для хранения больших массивов информации, ее записи на любые сроки и удаление в любое время. ЖД является энергонезависимой памятью, что означает, что информация остается в целостности при отключении питания компьютера. Технические параметры: емкость (100Мб-300 Гб), тип интерфейса подключения (IDE, SCSI), время поиска (6-13 мс), кэш (емкость), среднее время доступа (чтения) (60 нс.).
Флоппи-диски. Дискеты имеют размеры и емкость: 5,25 дюйма (360 - 1200 Кбайт) и 3.5 дюйма (720 - 1440 Кбайт). Вариации в объеме определяются плотностью записи. Приводы для них могут быть как раздельными, так и комбинированные в одном корпусе.
Стримеры. Стример (streamer) - лентопротяжный механизм, работающий в инерционном режиме. Различаются форматом используемой магнитной ленты: полудюймовые ленты (девятидорожечными), четвертьдюймовые (QIC - картридж), 8-мм , 4-мм (DAT).
Используются для резервного копирования и архивирования данных с жестких дисков. Устройства QIC-80 могут поддерживать без сжатия объемы данных до 400 Мбайт,
а QIC-3010 -более 800 Мбайт.
Оптические диски (CD/DVD). Характеристики оптических дисков меняются очень динамично, приведем наиболее распространенных в настоящее время: 250, 700, 800 Mб
СD-R/CD-RW, 4-10 Гб DVD-R/ DVD-RW.
Флаш – память.
3.11 Организация стек памяти
Пожалуй, одной из наиболее революционных инноваций в технологии программирования 50-х годов стало внедрение в языки программирования концепции
53
подпрограммы, или процедуры. Подпрограмма представляет собой самостоятельную компьютерную программу, включенную в состав более сложной программы (по отношению к подпрограмме она выступает в роли основной или вызывающей программы). В любом месте основной программы можно обратиться к подпрограмме (чаще говорят "вызвать подпрограмму"). Процессор при этом должен перейти на адрес первой команды подпрограммы, а после ее завершения вернуться на адрес команды основной программы, следующий за командой вызова подпрограммы.
В пользу применения подпрограмм в технологии программирования чаще всего выдвигаются два довода — экономия места в памяти и модульность структуры программы. Подпрограмма, в которой закодирован определенный алгоритм, может вызываться многократно, и таким образом экономится место в памяти, но в этом смысле подпрограмма мало чем отличается от цикла. Важнее другое − подпрограммы позволяют структурно разбить программу решения сложной задачи на более мелкие модули, решающие отдельные подзадачи. Такая модульность структуры большой программы существенно облегчает ее разработку.
Механизм поддержки работы с подпрограммами должен включать два основных типа команд − команды вызова подпрограммы и команды возврата из подпрограммы. Команды вызова подпрограммы должны обеспечить переход на первую команду вызываемой подпрограммы, а команды возврата − переход на команду вызывающей программы, следующую за командой вызова. Команды обоих видов относятся к категории команд управления ходом выполнения программы.
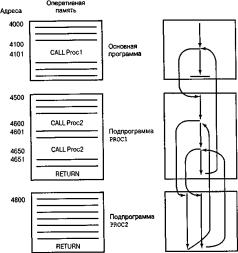
На рис. 10,а показано, как подпрограммы используются в составе программного комплекса. В данном примере имеется основная программа, которая размещена в памяти, начиная с адреса 4000. В основной программе существует вызов подпрограммы PROC1, которая размещена в памяти, начиная с адреса 4500. Когда в процессе выполнения основной программы процессор дойдет до этой команды, он прервет выполнение основной программы и перейдет на выполнение подпрограммы PROC1, поместив ее начальный адрес 4500 в счетчик команд. В теле подпрограммы PROC1 есть две команды вызова подпрограммы PROC2, которая размещена в памяти, начиная с адреса 4800. Дойдя до каждой из этих команд, процессор прекратит выполнять подпрограмму PROC1 и перейдет на выполнение подпрограммы PROC2. Встретив в подпрограмме команду RETURN, процессор вернется в вызывающую программу и продолжит ее выполнение с команды, следующей за командой CALL, которая вызвала переход на только что завершенную подпрограмму. Этот процесс схематически показан на рис. 10,6.
Обращаю ваше внимание на следующие моменты.
1.Подпрограмма может быть вызвана из любого места других программных модулей. Таких вызовов может быть сколько угодно.
2.Одна подпрограмма может быть вызвана из другой, которая, в свою очередь, вызвана третьей. Это называется вложенностью (nesting) вызовов. Глубина вложенности теоретически может быть произвольной.
3.При выполнении возврата из подпрограммы должен обеспечиваться переход именно на ту команду вызова, которая запустила завершенный сеанс выполнения
подпрограммы.
Из всего этого следует, что процессор при выполнении команды вызова подпрограммы должен каким-то образом сохранить адрес возврата (т.е. адрес команды вызывающей программы, следующей за выполняемой командой вызова). Существует три места, где можно было бы сохранить адрес возврата:
•регистр процессора;
•начальный адрес подпрограммы;
•верхняя ячейка стека.
Рассмотрим машинную команду CALL X, которая интерпретируется как "вызов подпрограммы, расположенной по адресу X". Если для хранения адреса возврата
54
использовать регистр RN, то выполнение команды CALL X должно проходить следующим образом (PC — счетчик команд процессора):
Рис. 10. Вложенный вызов подпрограмм: а — команды вызова и возврата; б — последовательность выполнения
RN |
Å |
PC + |
PC |
Å |
X |
В этой записи — длина текущей команды. Затем адрес возврата оказывается в регистре RN, откуда его может извлечь вызванная подпрограмма и сохранить где-либо в памяти для выполнения в дальнейшем возврата в вызывающую программу.
Если будет принято решение сохранять адрес возврата по начальному адресу вызываемой подпрограммы, то при выполнении команды CALL X процессору нужно будет выполнять следующие операции:
X |
Å |
PC + |
PC |
Å |
X + 1 |
Это довольно удобно, поскольку адрес возврата всегда сохраняется в месте, точно известном подпрограмме (точнее, ее разработчику).
Оба описанных подхода работоспособны и используются на практике. Единственным, но довольно существенным их недостатком является невозможность реализации реентерабельных подпрограмм. Реентерабельность подпрограммы означает, что она может быть вызвана повторно еще до завершения текущего вызова. Например, это происходит, если внутри подпрограммы вызывается другая подпрограмма, которая, в свою очередь, вызывает первую. Реентерабельными должны быть и подпрограммы, реализующие рекурсивные алгоритмы.
Стековые структуры в памяти
Стек – это упорядоченная множество элементов данных, только один из которых может быть доступен при каждом обращении. Доступный элемент называется вершиной стека. Количество элементов в стеке или длина стека является переменной величиной. Элементы могут добавляться только в вершину стека и удаляться только из вершины стека. Поэтому стек иногда называют магазинным списком и списком с дисциплиной обслуживания в обратном порядке (LIFO, list-in-first-out list, последним вошел, первым вышел).
На рис. 10 показаны основные операции со стеком. Будем считать, что в какой-то момент времени в стеке содержится некоторое количество элементов данных (буквы т,е,к). Операция PUSH (заталкивание) добавляет новый элемент в вершину стека, а операция POP (выталкивание) удаляет элемент, расположенный в вершине стека. В обоих случаях вершина стека соответственно смещается.
55

Рис. 10. Основные операции по работе со стеком Бинарные операции, требующие двух операндов (умножение, деление, вычитание,
сложение и т.п.) используют в качестве операндов два верхних элемента, которые “выталкиваются” из стека, а результат операции обратно “заталкивается” обратно в вершину стека. Унарные операции, требующие только одного операнда (например, логическое отрицание), используют только один верхний элемент стека (вершину).
Таблица 2.
|
Операции со стеком |
Операция |
Описание |
PUSH |
Добавление нового элемента в вершину стека |
POP |
Удаление элемента из вершины стека |
Унарная операция |
Выполнение определенных действий с верхним элементом |
|
стека. Заменяет элемент данных в вершине стека |
Бинарная операция |
Выполнение определенных действий с двумя верхними |
|
элементами, которые удаляются из стека. Результат |
|
помещается в вершину стека |
Реализация стека
Стек, имеющий описанную дисциплину обслуживания, играет весьма важную роль в реализации многих функций процессора. Одна из функций, связанная с обслуживанием вызовов подпрограмм и возвратом из подпрограмм рассматривается в настоящем параграфе. Стек также часто используется программистом (пример вычисления арифметических и логических выражений в конце параграфа).
Рис. 16. Регистры и память ЭВМ со стековой организацией Указатель стека - регистр для указания адреса вершины стека. Остальные регистры
на рис. 6 несут обычные функции.
Стековая память. Память ЭВМ разделяется на две части, одна из которых отводится для организации стека, а другая (адресная) - для размещения программы и данных. Подобная организация позволяет строить программы, в которых используются:
•адресные команды для загрузки операнда из области данных в стек ;ши извлечения операнда из стека;
•безадресные команды, инициирующие извлечение из стека двух слов (или одного слова), выполнение над ними действий, указанных кодом операции команды, и загрузку результата в стек.
Стековая память состоит из ячеек, причем обмен информацией между остальными устройствами ЭВМ и стековой памятью (стеком) всегда выполняется только через верхнюю ячейку - вершину стека. При записи нового слова (команды, числа, символа и т.п.) все ранее записанные слова сдвигаются на одну ячейку вниз, а новое слово помещается в вершину стека. Считывание возможно только с вершины стека и производится с удалением или без уда Аппаратная реализация стека, как правило, не
56

целесообразна, и поэтому в большинстве ЭВМ стек моделируют, обычно используя в качестве стека просто часть адресной памяти, что позволяет легко менять емкость стека и экономит аппаратуру.
Несмотря на то, что внешне модель стека отличается от аппаратного стека, она функционирует по тому же алгоритму: последним вошел - первым вышел. Это обеспечивается с помощью указателя стека, который содержит адрес плавающей вершины стека. Заметим, что моделируемый стек растет не сверху вниз (ко дну стека), а снизу вверх (от дна стека). Однако это не нарушает алгоритма функционирования такой памяти. На рис. 18. показан стек, организованный в памяти с однобайтовыми словами. Предполагается, что дно стека располагается в ячейке с 8-ричным адресом 1000
При работе со стеком, представленным на рис. 18., следует учесть, что при занесении данного в стек сначала уменьшается значение указателя стека, то есть происходит его настройка на новую вершину, а затем уже производится загрузка в стек; при считывании из стека после извлечения данного из вершины указатель стека увеличивает свое значение. Именно поэтому, когда стек пуст, значение указателя устанавливается на ячейке, следующей за дном стека.
Рис. 12. Модель стека, реализованная в основной памяти Более общим и более надежным подходом является использование для хранения
адреса возврата стека (стековые структуры). Когда ЦП выполняет команду вызова подпрограммы, адрес возврата помещается в верхнюю ячейку стека, а когда он выполняет команду возврата, извлекает этот адрес из верхней ячейки стека (рис. 13).
Рис. 13. Использование стека для вложенного вызова подпрограмм При вызове подпрограммы, как правило, требуется не только сохранить адрес
возврата, но и передать в подпрограмму значения параметров. Для этого можно воспользоваться регистрами процессора. Другой вариант − хранить параметры в памяти сразу же за командой вызова подпрограммы. В данном случае адрес возврата должен указывать на ячейку, следующую за списком параметров, а не за самой командой вызова. Каждый из этих подходов имеет свои недостатки. Если для передачи параметров используются регистры, вызывающая программа и подпрограмма должны быть спроектированы таким образом, чтобы в них обеспечивалось правильное использование этих регистров. При хранении списка параметров в памяти вслед за командой вызова
57
сложно организовать передачу в подпрограмму количества параметров. В обоих случаях весьма затруднительно обеспечить реентерабельность подпрограмм.
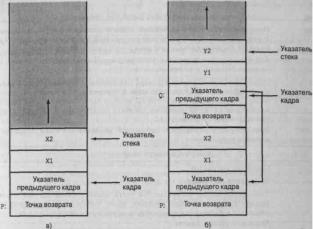
Более гибкий подход предусматривает передачу параметров в подпрограмму через стек. При выполнении команды вызова подпрограммы процессор не только сохраняет в стеке адрес возврата, но и записывает в него значения параметров, которые затем могут быть извлечены из стека подпрограммой. При возврате из подпрограммы через стек можно передать и результаты ее выполнения. Набор параметров вместе с адресом возврата образует так называемый стековый кадр (stack frame).
Пример такого подхода представлен на рис. 9.9. В этом примере предполагается, что в подпрограмме Р объявлены локальные переменные XI и Х2, а в подпрограмме Q, которая может быть вызвана из Р, объявлены локальные переменные У1 и Y2. На рисунке показано, что точкой возврата для каждой подпрограммы является первый элемент соответствующего стекового кадра". Далее в стеке (т.е. в ячейке, расположенной ближе к вершине стека) находится указатель на начало предыдущего стекового кадра. Это необходимо на случаи, если количество и длина списка параметров в стеке будут переменными.
Рис. 9.9. Изменение содержимого стека при вызове подпрограмм Р и Q: а — выполняется подпрограмма Р; б — подпрограмма Р вызвала подпрограмму Q.
При составлении программы вычисления арифметических выражений для таких ЭВМ используют Польскую Инверсную (бесскобочную) Запись (ПОЛИЗ) выражений. В ПОЛИЗе операция записывается не между операндами (X+Y), а после них (XY+).
Подобные выражения можно вычислять по следующему алгоритму:
1)проанализировать каждый символ бесскобочной записи формулы, начиная с крайнего левого символа, до тех пор, пока не встретится знак операции;
2)взять ближайших два операнда (если операция двуместная) или один операнд (при унарной операции), расположенные слева от обнаруженного знака операции, выполнить операцию и результат поместить в формулу на место выделенных операндов и знака операции;
3)если после выполнения пункта 2) формула состоит из одного значения, это значение и есть результат, то есть алгоритм завершен, в противном случае перейти
к пункту 1).
Пример использования такого алгоритма для вычисления по формуле
Y = (А + В • С)/(Е - F),
преобразованной в формулу ABC -+EF-/, (*)
приведен в нижеследующей таблице. Для определенности в ней выбраны следующие числовые значения операндов: А=8, В=2, С=5, Е=6 и F=4.
Шаг |
Формула, подле- |
Левый |
Операнды |
Результат |
Новая формула после |
|
жащаярасчету |
знак |
|
|
выполненияоперации |
58

1 |
825 +64 - / |
|
2 и5 |
10 |
810 |
+ 64 - / |
2 |
8 10 + 64 - / |
+ |
8 и 10 |
18 |
1864 - / |
|
3 |
1864 - / |
- |
6 и4 |
2 |
182 |
/ |
4 |
182/ |
/ |
18и2 |
9 |
9 |
|
Бесскобочная запись является идеальной для проведения вычислений на ЭВМ со стековой организацией.
На рис. 19. изображен расчет выражения (*) с использованием стека
Рис. 19. Пример использования стека для вычисления выражений Предполагается, что при работе со стеком на рис. 19. используются следующие ко-
манды:
PUSH <ад> - загрузка в стек содержимого ячейки с адресом <ад.>, POP <ад> - выгрузка из стека в память по адресу <ад.>,
MUL - умножение содержимого двух верхних ячеек стека,
ADD - сложение содержимого двух верхних ячеек стека,
SUB - вычитание содержимого двух верхних ячеек стека,
DIV - деление содержимого двух верхних ячеек стека.
Заметим, что структуры реальных процессоров являются смешанными, то есть позволяют моделировать все указанные выше виды структур.
59