

Informatsia_po_MFYuA / Эконометрика / ЛР_тренд_Эксел
.doc-
Лабораторная работа 1.
-
Построение уравнения регрессии на ПЭВМ
В экономике обычно используются данные двух видов: временные динамические ряды или регрессионные данные.
Типичный временной ряд приведен в табл. 2. В первом столбце находятся какие-либо временные значения (в данном случае, годы), в другом -- какие-либо экономические характеристики (в данном случае – доходы)
Т а б л и ц а 2
Годы Потребление
мяса, кг. 1990 75 1991 69 1992 60 1993 59 1994 57 1995 55 1996 51 1997 50 1998 48 1999 45
Опишем наиболее простой и быстрый способ построения уравнений регрессии для временных рядов. Для временных рядов линия регрессии обычно называется линией тренда, т.е. линией тенденции. Для построения линии тренда необходимо проделать следующие действия:
-
Построить гистограмму (рис. 4).
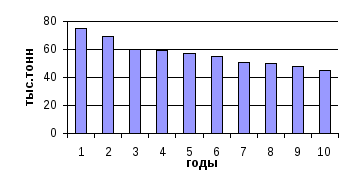
Рис. 4. Среднедушевое потребление мяса
-
С помощью правой кнопки мыши вызвать дополнительное меню и выбрать « Добавить линию тренда» (рис. 5).
.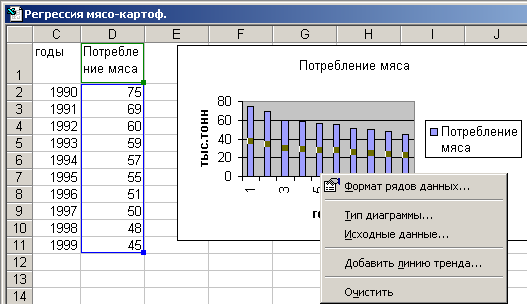
Рис. 5. Регрессия «мясо-картофель»
-
В новом меню последовательно выбрать опции: Линейная, Логарифмическая, Полиномиальная, Степенная, Экспоненциальная (рис. 6).

Рис. 6. Линия тренда (Тип)
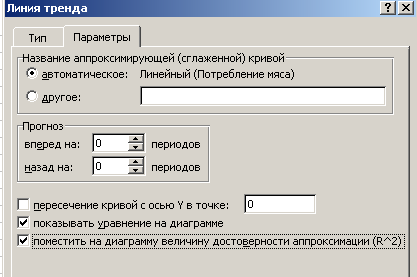 4.
Для каждой опции через дополнительное
меню «Параметры» выбрать две команды:
показать уравнение на диаграмме и
поместить на диаграмме величину
достоверности аппроксимации (рис. 7)
4.
Для каждой опции через дополнительное
меню «Параметры» выбрать две команды:
показать уравнение на диаграмме и
поместить на диаграмме величину
достоверности аппроксимации (рис. 7)
Рис. 7. Линия тренда (Параметры)
В результате получим гистограмму, изображенную на рис. 8.
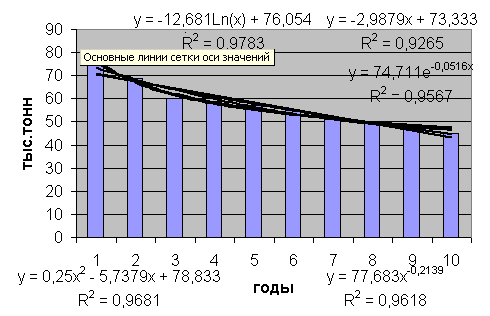
Рис. 8 Гистограмма с линиями тренда
5. Далее по коэффициенту R^2 выбрать наилучшее уравнение. Напоминаем, что считается лучшим то уравнение, у которого R^2 больше. В данном случае наилучшим с этой точки зрения будет логарифмическое уравнение.
6. Используя это уравнение легко сделать прогноз на следующий, 11-й год. Для этого в уравнение y = -- 12,681ln (x) + 76,054 вместо x следует подставить число 11. В результате получаем прогноз на 11-й год, равный 46, 425.
Теперь рассмотрим регрессионную таблицу, в которой приведены данные по потреблению мяса и хлебопродуктов в Красноярском крае за
1990-2000 годы
Т а б л и ц а 3
-
мясо и мясопродукты, включая 2 кат
хлебопродукты
73
109
66
109
63
113
64
117
64
117
64
118
60
114
58
119
56
124
51
124
49
118
Построим уравнение регрессии, взяв за переменную x – хлебопродукты, а за переменную y – мясо и мясопродукты.
Входим в меню «Сервис», «Анализ данных», «Регрессия». Замечание. Если в «Сервисе» нет пакета «Анализ данных», то входим в «Надстройки», подгружаем «Пакет анализа данных» и снова входим в «Сервис». Меню показано на рис. 9.
В результате получаем 4 таблицы и три графика. Все они будут объяснены ниже.

Рис. 9 Окно регрессии
В первой строке табл. 4 находится коэффициент корреляции между переменными Y и X. Величина его указывает на тесноту связи между этими переменными. Если он меньше 0,3, то связь между переменными слабая, если он больше 0,75, то связь сильная, в остальных случаях можно говорить о средней связи между переменными.
Во второй строке записывается R^2, с помощью которого оценивается качество аппроксимации. Чем он больше, тем лучше подобрано уравнение. В нашем случае он равен 0,56.... В этом случае говорят, что выбранное уравнение объясняет 56 % опытных данных.
В третьей строке записывается стандартная ошибка, вычисленная по формуле (2.1).
В последней строке записывается количество опытных данных.
Т а б л и ц а 4
-
Регрессионная статистика
Множественный R
0,751743
R-квадрат
0,565118
Нормированный R-квадрат
0,516797
Стандартная ошибка
4,806857
Наблюдения
11
-
Т а б л и ц а 5
-
Дисперсионный анализ
df
SS
MS
F
Регрессия
1
270,228
270,228
11,69525
Остаток
9
207,952
23,1058
Итого
10
478,181
Объясним по столбцам табл.5. В столбце df записано число степеней свободы. В первой строке пишется число переменных в уравнении регрессии k (в нашем случае k = 1). Ниже число, которое вычисляется по формуле n-k-1. Здесь n равно числу опытов. В строке «Итого» записана сумма предыдущих двух строк.
В столбце с заголовком SS записаны ошибки. В первой строке «объясняемая» часть ошибки, которая равна 270,228
Во второй – «необъясняемая» часть равная 207,952
В строке «Итого» эти ошибки суммируются и записывается общая ошибка аппроксимации. Заметим, что R2 = SSрегрес/ SSитого= 270,228/478,181 = 0,565118
В столбце MS записаны следующие числа: MS1 = 270,228, MS2 = =23,1058, которые понадобятся нам для вычисления F.
В последнем столбце вычисляется F по формуле F= MS1/ MS2=34,5623, обозначается Fвыч и сравнивается с Fтаб.= F(k, n-k-1).
Если Fвыч> Fтаб, то уравнение адекватно опытным данным с вероятностью 95 %, в противном случае можно говорить о неверно выбранном виде уравнения. В нашем случае Fтаб.= F(1, 10)= 4,96 < 11,7. Поэтому можно говорить, что уравнение адекватно опытным данным.
Рассмотрим следующую таблицу (табл.6).
-
Т а б л и ц а 6
|
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
Нижние 95% |
Верхние 95% |
|
Y-пересечение |
180,767 |
35,131 |
5,146 |
101,295 |
260,238 |
|
Переменная X 1 |
-1,03 |
0,301 |
-3,42 |
-1,711 |
-0,349 |
Во втором столбце находятся коэффициенты уравнения регрессии, имеющего вид y =.-1,03*x + 180,767. В третьем - числа, равные стандартным ошибкам полученных коэффициентов. Чем больше ошибка, тем менее точно найден соответствующий коэффициент. В четвертом столбце вычислена
t-статистика, полученная делением соответствующего коэффициента на стандартную ошибку.
Вычисленную t-статистику сравнивают с табличными значениями tтаб= =t(n-1). Если tтаб> abs(tвыч)., то коэффициент с вероятностью 95 % равен нулю, в противном случае он значимо от нуля отличается. В нашем случае tтаб= t(n-1) = t(10) = 2,228. Поэтому свободный член нашего уравнения регрессии и коэффициент при ln t значимо от нуля отличаются.
Последние два столбца определяют нижнюю и верхнюю границы интервала, куда с вероятностью 95 % попадает наш коэффициент. Первый коэффициент принадлежит интервалу [101,295; 260,238], а второй – [- 1,711;
- 0,349].
Рассмотрим табл. 7
Т а б л и ц а 7
-
Наблюдение
Предсказанное Y
Остатки
1
68,49892934
4,501070664
2
68,49892934
-2,498929336
3
64,37901499
-1,379014989
4
60,25910064
3,740899358
5
60,25910064
3,740899358
6
59,22912206
4,770877944
7
63,3490364
-3,349036403
8
58,19914347
-0,199143469
9
53,04925054
2,950749465
10
53,04925054
-2,049250535
11
59,22912206
-10,22912206
В первом столбце табл. 7 приведены номера опытов, во второй - значения Y вычисленные по уравнению регрессии, в третьем - разность между теоретическими значениями и начальными данными Y.
Далее построим три графика: график остатков, график нормального распределения и график подбора (рис. 10; 11; 12 соответственно). На графике подбора (рис. 12) изображены данные исходные и предсказанные по уравнению регрессии. Остальные графики также необходимы для анализа уравнения регрессии, но их смысл будет пояснен после изложения теоремы Гаусса-Маркова.

Рис. 10
Рис. 11

Рис. 12