

Концепция удаленного вызова процедур
Идея вызова удаленных процедур состоит в расширении хорошо известного и понятного механизма передачи управления и данных внутри программы, выполняющейся на одной машине, на передачу управления и данных через сеть. Средства удаленного вызова процедур предназначены для облегчения организации распределенных вычислений. Впервые механизм RPC реализовала компания Sun Microsystems, и он хорошо соответствует девизу «Сеть — это компьютер», взятому этой компанией на вооружение, так как приближает сетевое программирование к локальному. Наибольшая эффективность RPC достигается в тех приложениях, в которых существует интерактивная связь между удаленными компонентами с небольшим временем ответов и относительно малым количеством передаваемыхданных. Такие приложения называются RFC-ориентированными.
Характерными чертами вызова локальных процедур являются:
асимметричность — одна из взаимодействующих сторон является инициатором взаимодействия;
синхронность — выполнение вызывающей процедуры блокируется с момента выдачи запроса и возобновляется только после возврата из вызываемой процедуры.
Реализация удаленных вызовов существенно сложнее реализации вызовов локальных процедур. Начнем с того, что поскольку вызывающая и вызываемая процедуры выполняются на разных машинах, то они имеют разные адресные пространства и это создает проблемы при передаче параметров и результатов, особенно если машины и их операционные системы не идентичны. Так какRPCне может рассчитывать на разделяемую память, это означает, что параметрыRPCне должны содержать указателей на ячейки памяти и что значения параметров должны как-то копироваться с одного компьютера на другой.
Следующим отличием RPC от локального вызова является то, что он обязательно использует нижележащую систему обмена сообщениями, однако это не должно быть явно видно ни в определении процедур, ни в самих процедурах. Удаленность вносит дополнительные проблемы. Выполнение вызывающей программы и вызываемой локальной процедуры в одной машине реализуется в рамках единого процесса. Но в реализации RPC участвуют как минимум два процесса — по одному и каждой машине. В случае если один из них аварийно завершится, могут возникнуть следующие ситуации:
при аварии вызывающей процедуры, удаленно вызванные процедуры становятся «осиротевшими»;
при аварийном завершении удаленных процедур становятся «обездоленными родителями» вызывающие процедуры, которые будут безрезультатно ожидать ответа от удаленных процедур.
Кроме того, существует ряд проблем, связанных с неоднородностью языков программирования и операционных сред: структуры данных и структуры вызова процедур, поддерживаемые в каком-либо одном языке программирования, не поддерживаются точно таким же способом в других языках.
Рассмотрим, каким образом технология RPC, лежащая в основе многих распределенных операционных систем, решает эти проблемы.
Чтобы понять работу RPC, рассмотрим сначала выполнение вызова локальной процедуры в автономном компьютере. Пусть это, например, будет процедура записи данных в файл:
m = my_write(fd, but, length)
Здесь fd — дескриптор файла, целое число, buf — указатель на массив символов, length— длина массива, целое число.
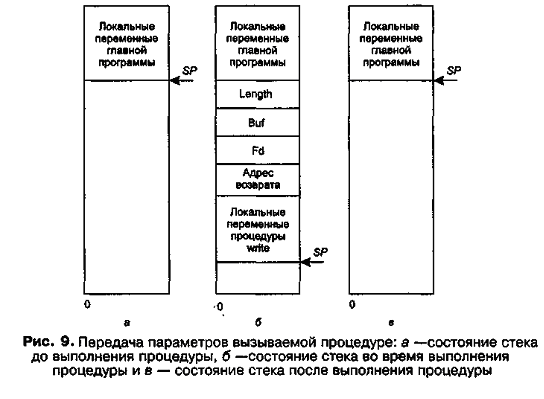
Чтобы осуществить вызов, вызывающая процедура помещает указанные параметры в стек в обратном порядке и передает управление вызываемой процедуреmy_write. Эта пользовательская процедура после некоторых манипуляций с данными символьного массива buf выполняет системный вызов write для записи данных в файл, передавая ему параметры тем же способом, то есть, помещая их в стек (при реализации системного вызова они копируются в стек системы, а при возврате из него результат помещается в пользовательский стек). После того какпроцедура my_write выполнена, она помещает возвращаемое значение m в регистр, перемещает адрес возврата и возвращает управление вызывающей процедуре, которая выбирает параметры из стека, возвращая его в исходное состояние. Заметим,что в языке C параметры могут вызываться по ссылке (by name), представляющей собой адрес глобальной области памяти, в которой хранится параметр, или по значению (byvalue), в этом случае параметр копируется из исходной областипамяти в локальную память процедуры, располагаемую обычно в стековом сегменте. В первом случае вызываемая процедура работает с оригинальными значениями параметров и их изменения сразу же видны вызывающей процедуре. Во втором случае вызываемая процедура работает с копиями значений параметров, и их изменения никак не влияют на значение оригиналов этих переменных в вызывающей процедуре. Эти обстоятельства весьма существенны для RPC.
Решение о том, какой механизм передачи параметров использовать, принимается разработчиками языка. Иногда это зависит от типа передаваемых данных. В языке C, например, целые и другие скалярные данные всегда передаются по значению, а массивы — по ссылке.
Рисунок 9 иллюстрирует передачу параметров вызываемой процедуре: стек до выполнения вызова write (a), стек во время выполнения процедуры (б), стек после возврата в вызывающую программу (в).
Идея, положенная в основу RPC, состоит в том, чтобы вызов удаленной процедуры по возможности выглядел так же, как и вызов локальной процедуры. Другими словами, необходимо сделать механизм RPC прозрачным для программиста: вызывающей процедуре не требуется знать, что вызываемая процедура находится на другой машине, и наоборот.
Механизм RPCдостигает прозрачности следующим образом. Когда вызываемаяпроцедура действительно является удаленной, в библиотеку процедур вместо локальной реализации оригинального кода процедуры помещается другая вер сия процедуры, называемая клиентским стабом (stub — заглушка). На удаленный компьютер, который выполняет роль сервера процедур, помещается оригинальный код вызываемой процедуры, а также еще один стаб, называемый серверным стабом. Назначение клиентского и серверного стабов – организовать передачупараметров вызываемой процедуры и возврат значения процедуры через сети, при этом код оригинальной процедуры, помещенной на сервер, должен быть полностью сохранен. Стабы используют для передачи данных через сеть средстваподсистемы обмена сообщениями, то есть существующие в ОС примитивы send иreceive. Иногда в подсистеме обмена сообщениями выделяется программныймодуль, организующий связь стабов с примитивами передачи сообщений, называемый модулемRPCRuntime.
Подобно оригинальной процедуре, клиентский стаб вызывается путем обычной передачи параметров через стек (как показано на рисунке 9), однако затем вместо выполнения системного вызова, работающего с локальным ресурсом, происходит формирование сообщения, содержащего имя вызываемой процедуры и ее параметры (рисунке 10).
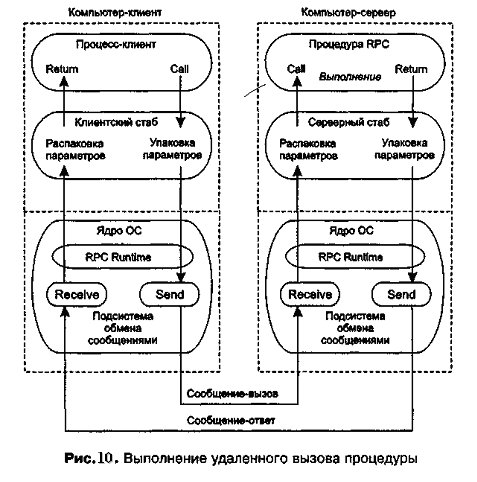
Эта операция называется операцией упаковки параметров. После этого клиентский стаб обращается к примитиву send для передачи этого сообщения удаленному компьютеру, на который помещена реализация оригинальной процедуры. Получив из сети сообщение, ядро ОС удаленного компьютера вызывает серверный стаб, который извлекает из сообщения параметры и вызывает обычным образоморигинальную процедуру. Для получения сообщения серверный стаб должен предварительно вызвать примитив receive, чтобы ядро знало, для кого пришло сообщение. Серверный стаб распаковывает параметры вызова, имеющиеся в сообщении, и обычным образом вызывает оригинальную процедуру, передавая ей параметры через стек. После окончания работы процедуры серверный стаб упаковывает результат ее работы в новое сообщение и с помощью примитиваsendпередает сообщение по сети клиентскому стабу, а тот возвращает обычным образом результат и управление вызывающей процедуре. Ни вызывающая процедура, ни оригинальная вызываемая процедура не изменились оттого, что они стали работать на разных компьютерах.
Связывание клиента с сервером
Рассмотрим вопрос о том, как клиент узнает место расположения сервера, которому необходимо послать сообщение-вызов. Процедура, устанавливающая соответствие между клиентом и серверомRPC, носит названиесвязывание (binding). Методы связывания, применяемые в различных реализацияхRPC, отличаются:
способом задания сервера, с которым хотел бы быть связанным клиент;
способом обнаружения сетевого адреса (места расположения) требуемого сервера процессом связывания;
стадией, на которой происходит связывание.
Метод связывания тесно связан с принятым методом именования сервера. В наиболее простом случае имя или адрес сервераRPCзадается в явной форме, в качестве аргумента клиентского стаба или программы-сервера, реализующей интерфейс определенного типа. Например, можно использовать в качестве такого аргументаIP-адрес компьютера, на котором работает некоторыйRPC-сервер, и номерTCP/UDPпорта, через который он принимает сообщения-вызовы своих процедур. Основной недостаток такого подхода — отсутствие гибкости и прозрачности. При перемещении сервера или при существовании нескольких серверов клиентская программа не может автоматически выбрать новый сервер или тот сервер, который в данный момент наименее загружен. Тем не менее, во многих случаях такой способ вполне приемлем, и ввиду своей простоты часто используется на практике. Необходимый сервер часто выбирает пользователь, например, путем просмотра списка или графического представления имеющихся в сети разделяемых файловых систем (набор этих файловых систем может быть собран операционной системой клиентского компьютера за счет прослушивания широковещательных объявлений, которые периодически делают серверы). Кроме того, пользователь может задать имя требуемого сервера на основании заранее известной ему информации об адресе или имени сервера.
Подобный метод связывания можно назвать полностью статическим. Существуют и другие методы, которые являются в той или иной степени динамическими, так как не требуют от клиента точного задания адреса RPC-сервера, вплоть до указания номера порта, а динамически находят нужный клиенту сервер.
Динамическое связывание требует изменения способа именования сервера. Наиболее гибким является использование для этой цели имени RPC-интерфейса, состоящего из двух частей:
типа интерфейса;
экземпляра интерфейса.
Тип интерфейса определяет все характеристики интерфейса, кроме его месторасположения. Это те же характеристики, который имеются в описании для IDL-компилятора, например файловая служба определенной версии, включающая процедуры open, close, read, write, и т. п. Часть, описывающая экземпляр интерфейса, должна точно задавать сетевой адрес сервера, который поддерживает данный интерфейс. Если клиенту безразлично, какой сервер его будет обслуживать, то вторая часть имени-интерфейса опускается.
Динамическое связывание иногда называют импортом/экспортом интерфейса: клиент импортирует интерфейс, а сервер его экспортирует.
В том случае, когда для клиента важен только тип интерфейса, процесс обнаружения требуемого сервера в сети с экземпляром интерфейса определенного типа может быть построен двумя способами:
с использованием широковещания;
с использованием централизованного агента связывания.
Первый способ основан на широковещательном распространении по сети серверами RPC имени своего интерфейса, включая и адрес экземпляра. Применение этого способа позволяет автоматически балансировать нагрузку на несколько серверов, поддерживающий один и тот же интерфейс, — клиент просто выбирает первое из подходящих ему объявлений.
Схема с централизованным агентом связывания предполагает наличие в сети сервера имен, который связывает тип интерфейса с адресом сервера, поддерживающего такой интерфейс. Для реализации этой схемы каждый сервер RPC должен предварительно зарегистрировать тип своего интерфейса и сетевой адрес у агента связывания, работающего на сервере имен. Сетевой адрес агента связывания (в формате, принятом в данной сети) должен быть известным адресом как для серверов RPC, так и для клиентов. Если сервер по каким-то причинам не может больше поддерживать определенный RPC-интерфейс, то он должен обратиться к агенту и отменить свою регистрацию. Агент связывания на основании запросов регистрации ведет таблицу текущего наличия в сети серверов и поддерживаемых ими RPC-интерфейсов.
Клиент RPC для определения адреса сервера, обслуживающего требуемый интерфейс, обращается к агенту связывания с указанием характеристик, задающих тип интерфейса. Если в таблице агента связывания имеются сведения о сервере, поддерживающем такой тип интерфейса, то он возвращает клиенту его сетевой адрес. Клиент затем кэширует эту информацию для того, чтобы при последующих обращениях к процедурам данного интерфейса не тратить время на обращения к агенту связывания.
Агент связывания может работать в составе общей централизованной справочной службы сети, такой как NDS, X.500 или LDAP (справочные службы более подробно рассматриваются в следующей главе).
Описанный метод, заключающийся в импорте/экспорте интерфейсов, обладает высокой гибкостью. Например, может быть несколько серверов, поддерживающих один и тот же интерфейс, и клиенты распределяются по серверам случайным образом. В рамках этого метода становится возможным периодический опрос серверов, анализ их работоспособности и, в случае отказа, автоматическое отключение, что повышает общую отказоустойчивость системы. Этот метод может также поддерживать аутентификацию клиента. Например, сервер может определить, что доступ к нему разрешается только клиентам из определенного списка.
Однако у динамического связывания имеются недостатки, например дополнительные накладные расходы (временные затраты) на экспорт и импорт интерфейсов. Величина этих затрат может быть значительна, так как многие клиентские процессы существуют короткое время, а при каждом старте процесса процедура импорта интерфейса должна выполняться заново. Кроме того, в больших распределенных системах может стать узким местом агент связывания, и тогда необходимо использовать распределенную систему агентов, что можно сделать стандартным способом, используя распределенную справочную службу (такимсвойством обладают службы NDS, Х.500 и LDAP).
Необходимо отметить, что и в тех случаях, когда используется статическое связывание, такая часть адреса, как порт сервера интерфейса (то есть идентификатор процесса, обслуживающего данный интерфейс), определяется клиентом динамически. Эту процедуру поддерживает специальный модуль RPCRuntime, называемый в ОСUNIXмодулем отображения портов (portmapper), а в ОС семейства Windows — локатором RFC (RPC Locator). Этот модуль работает на каждом сетевом узле, поддерживающем механизмRPC, и доступен по хорошоизвестному порту TCP/UDP. Каждый сервер RPC, обслуживающий определенный интерфейс, при старте обращается к такому модулю с запросом о выделении ему для работы номера порта из динамически распределяемой области, есть сномером, большим 1023). Модуль отображения портов выделяет серверу некоторый свободный номер порта и запоминает это отображение в своей таблице, связывая порт с типом интерфейса, поддерживаемым сервером. КлиентRPC, выяснив каким-либо образом сетевой адрес узла, на котором имеется сервер RPC с нужным интерфейсом, предварительно соединяется с модулем отображенияпортов по хорошо известному порту и запрашивает номер порта искомого сервера. Получив ответ, клиент использует данный номер для отправки сообщений-вызовов удаленных процедур. Механизм очень похож на механизм, лежащий в основе работы агента связывания, но только область его действия ограничивается портом одного компьютера.
Кластеры
По мере развития компьютерной техники и ее интеграции в бизнес-процесс предприятий, проблема увеличения времени, в течение которого доступны вычислительные ресурсы, приобретает все большую актуальность. Надежность серверов становится одним из ключевых факторов успешной работы компаний с развитой сетевой инфраструктурой, например, электронных магазинов, ведущих продажи через Интернет, крупных предприятий, в которых специальные системы осуществляют поддержку производственных процессов в реальном времени, банков с разветвленной филиальной сетью или центров обслуживания телефонного оператора, использующих систему поддержки принятия решений. Всем таким предприятиям жизненно необходимы серверы, которые работают и предоставляют информацию 24 часа в день семь дней в неделю (24х7х365).
Стоимость поломок и простоя оборудования постоянно растет. Она складывается из стоимости потерянной информации, потерянной прибыли, стоимости технической поддержки и восстановления, неудовлетворенности клиентов и т. д. Имеются методики, позволяющие вычислить стоимость минуты простоя и затем на основе этого показателя выбрать наиболее выгодное решение с наилучшим соотношением функциональности и цены.
Существует немало средств для построения надежной системы. Дисковые массивы RAID, например, позволяют не прерывать обработку запросов к информации, хранящейся на дисках, при выходе из строя одного или нескольких элементов массива. Резервные блоки питания в ряде случаев позволят в какой-то степени застраховаться на случай отказа других компонентов. Источники бесперебойного питания поддержат работоспособность системы в случае сбоев в сети энергоснабжения. Многопроцессорные системные платы обеспечат функционирование сервера в случае отказа одного процессора. Однако ни один из этих вариантов не спасет, если из строя выйдет вся вычислительная система целиком. Вот тут на помощь приходит кластеризация. Пожалуй, первым шагом к созданию кластеров можно считать широко распространенные в пору расцвета мини-компьютеров системы "горячего" резерва. Одна или две такие системы, входящие в сеть из нескольких серверов, не выполняют никакой полезной работы, но готовы начать функционировать, как только выйдет из строя какая-либо из основных систем. Таким образом, серверы дублируют друг друга на случай отказа или поломки одного из них. Но при объединении компьютеров желательно, чтобы они не просто дублировали друг друга, но и выполняли другую полезную работу, распределяя нагрузку между собой. Для этого во многих случаях как нельзя лучше подходят кластеры.
Изначально кластеры использовались для мощных вычислений и поддержки распределенных баз данных, особенно таких, для которых требуется повышенная надежность. В дальнейшем их стали применять для сервиса Web. Однако снижение цен на кластеры привело к тому, что подобные решения все активнее используют и для других нужд. Кластерные технологии наконец-то стали доступны рядовым организациям - в частности, благодаря использованию в кластерах начального уровня недорогих серверов Intel, стандартных средств коммуникации и распространенных ОС.
В ряде случаев привлекательность кластера во многом определяется возможностью построить уникальную архитектуру, обладающую достаточной производительностью, устойчивостью к отказам аппаратуры и ПО. Такая система к тому же должна легко масштабироваться и модернизироваться универсальными средствами, на основе стандартных компонентов и за умеренную цену (несравненно меньшую, чем цена уникального отказоустойчивого компьютера или системы с массовым параллелизмом).
Термин "кластер" имеет множество определений. Одни во главу угла ставят отказоустойчивость, другие - масштабируемость, третьи - управляемость. Классическое определение кластера звучит примерно так: "кластер - параллельная или распределенная система, состоящая из нескольких связанных между собой компьютеров и при этом используемая как единый, унифицированный компьютерный ресурс". Таким образом, кластер представляет собой объединение нескольких компьютеров, которые на определенном уровне абстракции управляются и используются как единое целое. На каждом узле кластера (по сути, узел в данном случае - компьютер, входящий в состав кластера) находится своя собственная копия ОС. Впрочем, узлом кластера может быть как однопроцессорный, так и многопроцессорный компьютер, причем в пределах одного кластера компьютеры могут иметь различную конфигурацию (разное количество процессоров, разные объемы ОЗУ и дисков). Узлы кластера соединяются между собой либо с помощью обычных сетевых соединений (Ethernet, FDDI, Fibre Channel), либо посредством нестандартных специальных технологий. Такие внутрикластерные, или межузловые соединения позволяют узлам взаимодействовать между собой независимо от внешней сетевой среды. По внутрикластерным каналам узлы не только обмениваются информацией, но и контролируют работоспособность друг друга.