

Лабораторная работа №6
Тема:Моделирование системы поддержки принятия решения в среде СУБДCache. Деревья решений. Основы клиент – серверной организацииweb– приложений.
Цель работы: Разработать медицинскую систему поддержки принятия решений.
Теоретические сведения
Современные системы поддержки принятия решения (СППР), возникшие в результате слияния управленческих информационных системи систем управлениябазами данных, представляют собой системы, максимально приспособленные к решению задач повседневной управленческой деятельности, являются инструментом, призванным оказать помощьлицам, принимающим решения(ЛПР). С помощью СППР может производится выбор решений некоторых неструктурированных и слабоструктурированных задач, в том числе и многокритериальных. СППР, как правило, являются результатом мульти -дисциплинарного исследования, включающего теориибаз данных,искусственного интеллекта, интерактивных компьютерных систем, методов имитационного моделирования.
Ранние определения СППР (в начале 70-х годов прошлого века) отражали следующие три момента:
Возможность оперировать с неструктурированнымиилислабоструктурированными задачами, в отличие от задач, с которыми имеет делоисследование операций;
Интерактивные автоматизированные (т.е. реализованные на базе компьютера) системы;
Разделение данных и моделей. Приведем определения СППР: СППР - совокупность процедур по обработке данных и суждений, помогающих руководителю в принятии решений, основанная на использованиимоделей.
СППР - это интерактивные автоматизированные системы, помогающиелицу, принимающему решения, использовать данные имоделидля решения слабо - структурированных проблем. СППР - это система, которая обеспечивает пользователям доступ к данным и/или моделям, так что они могут принимать лучшие решения. Последнее определение не отражает участия компьютера в создании СППР, вопросы возможности включения нормативных моделей в состав СППР и др. В настоящее время нет общепринятого определения СППР, поскольку конструкция СППР существенно зависит от вида задач, для решения которых она разрабатывается, от доступных данных, информации и знаний, а также от пользователей системы. Можно привести, тем не менее, некоторые элементы и характеристики, общепризнанные, как части СППР:
СППР - в большинстве случаев – это интерактивная автоматизированная система, которая помогает пользователю (ЛПР) использовать данные и модели для идентификации и решения задач и принятия решений. Система должна обладать возможностью работать с интерактивными запросами с достаточно простым для изучения языком запросов.
СППР обладает следующими четырьмя основными характеристиками:
СППР использует и данные, и модели;
СППР предназначены для помощи менеджерам в принятии решений для слабоструктурированных и неструктурированных задач;
Они поддерживают, а не заменяют, выработку решений менеджерами;
Цель СППР – улучшение эффективности решений.
При этом «идеальная» СППР:
Оперирует со слабоструктурированными решениями;
Предназначена для ЛПР различного уровня;
Может быть адаптирована для группового и индивидуального использования;
Поддерживает как взаимозависимые, так и последовательные решения;
Поддерживает 3 фазы процесса решения: интеллектуальную часть, проектирование и выбор;
Поддерживает разнообразные стили и методы решения, что может быть полезно при решении задачи группой ЛПР;
Является гибкой и адаптируется к изменениям как организации, так и ее окружения;
Проста в использовании и модификации;
Улучшает эффективность процесса принятия решений;
Позволяет человеку управлять процессом принятия решений с помощью компьютера, а не наоборот;
Поддерживает эволюционное использование и легко адаптируется к изменяющимся требованиям;
Может быть легко построена, если может быть сформулирована логика конструкции СППР;
Поддерживает моделирование;
Позволяет использовать знания.
Классификации СППР
На уровне пользователя делятся СППР на
Пассивные;
Активные;
Кооперативные СППР.
Пассивной СППРназывается система, которая помогает процессу принятия решения, но не может вынести предложение, какое решение принять.Активная СППРможет сделать предложение, какое решение следует выбрать.Кооперативная СППРпозволяет ЛПР изменять, пополнять или улучшать решения, предлагаемые системой, посылая затем эти изменения в систему для проверки. Система изменяет, пополняет или улучшает эти решения и посылает их опять пользователю. Процесс продолжается до получения согласованного решения.
На концептуальном уровне различаются СППР:
Управляемые сообщениями (Communication-Driven DSS);
СППР, управляемые данными (Data-Driven DSS);
СППР, управляемые документами (Document-Driven DSS);
СППР, управляемые знаниями (Knowledge-Driven DSS);
СППР, управляемые моделями (Model-Driven DSS).
СППР, управляемые моделями, характеризуются в основном доступ и манипуляции с математическими моделями (статистическими, финансовыми, оптимизационными, имитационными). Отметим, что некоторые OLAP-системы, позволяющие осуществлять сложный анализ данных, могут быть отнесены к гибридным СППР, которые обеспечивают моделирование, поиск и обработку данных.Управляемая сообщениями (Communication-Driven DSS)(ранее групповая СППР - GDSS) СППР поддерживает группу пользователей, работающих над выполнением общей задачи.СППР, управляемые данными (Data-Driven DSS)или СППР, ориентированные на работу с данными (Data-oriented DSS) в основном ориентируются на доступ и манипуляции с данными.СППР, управляемые документами (Document-Driven DSS),управляют, осуществляют поиск и манипулируют неструктурированной информацией, заданной в различных форматах. Наконец,СППР, управляемые знаниями (Knowledge-Driven DSS) обеспечивают решение задач в виде фактов, правил, процедур.
На техническом уровне различаются СППР:
СППР всего предприятия;
Настольная СППР.
СППР всего предприятияподключена к большим хранилищам информации и обслуживает многих менеджеров предприятия.Настольная СППР– это малая система, обслуживающая лишь один компьютер пользователя.
В зависимости от данных, с которыми эти системы работают, СППР условно можно разделить на:
Оперативные;
Стратегические.
Оперативные СППРпредназначены для немедленного реагирования на изменения текущей ситуации в управлении финансово-хозяйственными процессами компании.Стратегические СППРориентированы на анализ значительных объемов разнородной информации, собираемых из различных источников. Важнейшей целью этих СППР является поиск наиболее рациональных вариантов развития бизнеса компании с учетом влияния различных факторов, таких как конъюнктура целевых для компании рынков, изменения финансовых рынков и рынков капиталов, изменения в законодательстве и др. СППР первого типа получили названиеИнформационных Систем Руководства (Executive Information Systems, ИСР). По сути, они представляют собой конечные наборы отчетов, построенные на основании данных из транзакционной информационной системы предприятия, в идеале адекватно отражающей в режиме реального времени основные аспекты производственной и финансовой деятельности. Для ИСР характерны следующие основные черты:
Отчеты, как правило, базируются на стандартных для организации запросах; число последних относительно невелико;
ИСР представляет отчеты в максимально удобном виде, включающем, наряду с таблицами, деловую графику, мультимедийные возможности и т. п.;
Как правило, ИСР ориентированы на конкретный вертикальный рынок, например финансы, маркетинг, управление ресурсами.
СППР второго типа предполагают достаточно глубокую проработку данных, специально преобразованных так, чтобы их было удобно использовать в ходе процесса принятия решений. Неотъемлемым компонентом СППР этого уровня являются правила принятия решений, которые на основе агрегированных данных дают возможность менеджерам компании обосновывать свои решения, использовать факторы устойчивого роста бизнеса компании и снижать риски. СППР второго типа в последнее время активно развиваются. Технологии этого типа строятся на принципах многомерного представления и анализа данных (OLAP).
При создании СППР можно использовать Web-технологии. В настоящее время СППР на основе Web-технологий для ряда компаний являются синонимами СППР предприятия.
Обобщенная архитектураСППР, состоит из 5 различных частей:
Система управления данными (the data management system - DBMS);
Система управления моделями (the model management system – MBMS);
Машина знаний (the knowledge engine (KE));
Интерфейс пользователя (theuserinterface);
Пользователи (theuser(s)).
Data Mining и деревья решений (decision trees)
Data Miningпереводится как "добыча" или "раскопка данных". Нередко рядом с Data Mining встречаются слова "обнаружение знаний в базах данных" (knowledge discovery in databases) и "интеллектуальный анализ данных". Их можно считать синонимами Data Mining. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных. Цель Data Mining состоит в выявлении скрытых правил и закономерностей в наборах данных. Дело в том, что человеческий разум сам по себе не приспособлен для восприятия больших массивов разнородной информации. Человек к тому же не способен улавливать более двух-трех взаимосвязей даже в небольших выборках. Но и традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, также нередко пасует при решении задач из реальной сложной жизни. Она оперирует усредненными характеристиками выборки, которые часто являются фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты дома на улице, состоящей из дворцов и лачуг и т.п.). Поэтому методы математической статистики оказываются полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining). Современные технологии Data Mining (discovery-driven data mining) перелопачивают информацию с целью автоматического поиска шаблонов (паттернов), характерных для каких-либо фрагментов неоднородных многомерных данных. В отличие от оперативной аналитической обработки данных (online analytical processing, OLAP) в Data Mining бремя формулировки гипотез и выявления необычных (unexpected) шаблонов переложено с человека на компьютер.
Деревья решений (decision trees)являются одним из наиболее популярных подходов к решению задач Data Mining. Они представляют собой способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Под правилом понимается логическая конструкция, представленная в виде "если ... то ...". См. рисунок 1.
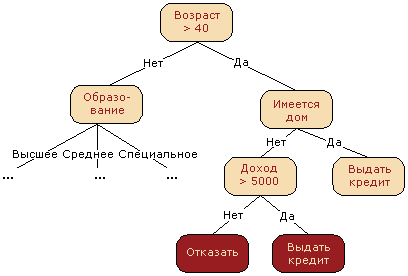
Рисунок 1 – Пример дерева решений.
Области применения деревьев решений
Деревья решений являются прекрасным инструментом в системах поддержки принятия решений, интеллектуального анализа данных (data mining). В состав многих пакетов, предназначенных для интеллектуального анализа данных, уже включены методы построения деревьев решений. В областях, где высока цена ошибки, они послужат отличным подспорьем аналитика или руководителя. Деревья решений успешно применяются для решения практических задач в следующих областях:
Банковское дело.Оценка кредитоспособности клиентов банка при выдаче кредитов.
Промышленность.Контроль за качеством продукции (выявление дефектов), испытания без разрушений (например проверка качества сварки) и т.д.
Медицина.Диагностика различных заболеваний.
Молекулярная биология.Анализ строения аминокислот.
Основы Web – программирования в Cache. Технология CSP
Технология CSP (Caché Server Pages)основной инструмент создания Web-интерфейса для информационных приложений, написанных на Caché. Технология CSP предлагает изящные средства создания быстродействующих, хорошо масштабируемых Web-приложений за короткое время. Она также упрощает дальнейшее сопровождение и развитие таких приложений. CSP-страницы хранятся в CSP-файлах. При обращении к CSP-файлу происходит его трансляция в класс CSP, который затем компилируется с помощью компилятора Caché Server Pages. Этот процесс прозрачен для разработчика и пользователя. Когда браузер, используя HTTP, запрашивает CSP-страницу на Web-сервере, последний, в свою очередь, запрашивает содержание страницы из базы данных Caché. Caché обрабатывает запрос, динамически генерируя HTML-страницу и передавая ее Web - серверу, который в свою очередь передает ее браузеру.
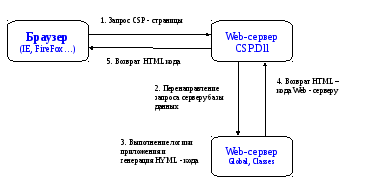
Рисунок 2 – Интеграция Web– сервера и сервера базы данных для обработкиweb– страниц.
При создании CSP-файла используются:
Выражения;
Скрипты, выполняющие код Caché или код JavaScript;
Методы стороны сервера;
CSP-теги;
Стандартные теги HTML.
Выражения Caché
Выражения Caché это заключенные в #(…)# выражения, которые заменяются вычисленными значениями в процессе генерации страниц. Конструкция #(…)# - фундаментальная часть технологии CSP. Обработка содержимого внутри круглых скобок выполняется Caché.
Скрипты, выполняющие код Caché
<script language=”Cache” runat={”server”|”compiler”}>
…
</script>
Тег <script> - стандартный тег HTML, который вызывает скрипт. Он имеет два параметра:
Language = “Cache”– определяет язык скрипта, другими значениями могут быть JavaScript, VBScript, SQL.
Runat = ”server”– определяет, что скрипт выполняется на сервере, когда страница загружена в броузер. Другим значением может быть «compiler», который заставляет выполнить код скрипта во время компиляции страницы, кроме того, может не быть никакого значения для этого параметра, что предполагает выполнение кода скрипта на клиенте, когда страница загружена в броузер.
Содержанием скрипта является текст программы на Caché Object Script, JavaScript или VBScript. Программный код выполняется каждый раз при загрузке страницы.
Подпрограммы, вызываемые на стороне сервера
Cacheподдерживает обращение к подпрограммам, хранимым на сервере, в формах:
#server(…)# - не зависит от настроек браузера. Полный синтаксис:
#server(classname.methodname(args,...))#
#call(…)# -асинхронный и зависит от настроек браузера. Полный синтаксис:
#call(classname.methodname(args,...))#
Теги CSP
Теги Caché имеют следующий общий синтаксис:
<CSP:XXX …>
Где ХХХ – это имя тега. Как встроенные, так и заказываемые теги обеспечивают разнообразные функциональные возможности.
<CSP:Object>- связывает объект Caché с CSP-страницей;
<CSP:Query>- выполняет из CSP-страницы предопределенный запрос и именует результат;
<CSP:Method>- создает метод при определении класса CSP-страницы;
<CSP:If>- формирует содержание, основанное на условии;
<CSP:Loop> - циклическая обработка фрагмента страницы;
<CSP:While>- циклическая обработка фрагмента страницы.
Web – формы
Формы позволяют обеспечивать интерактивную связь сайта с пользователем. Элементы форм (области редактирования текста, поля ввода, меню) позволяют посетителям вводить различную информацию и выбирать нужные опции. При добавлении элемента формы надо указать его имя. Имена нужны только для различения элементов форм. Когда пользователь вводит данные, соответствующему элементу формы присваивается определенное значение. После щелчка на кнопке Submit (запрос) имя элемента и его значение отсылается на сервер. Тег <FORM> устанавливает форму на web- странице. Документ может содержать любое количество форм, но одновременно на сервер может быть отправлена только одна форма. По этой причине данные форм должны быть независимы друг от друга. Синтаксис:
<form action="..."> ... </form>
Дополнительные сведения : http://www.htmlbook.ru/html/form.html
Когда форма отправляется на сервер, управление данными передается CGI-программе, заданной параметром action тега <FORM>. Предварительно браузер подготавливает информацию в виде пары «имя=значение», где имя определяется параметром name тега <INPUT>, а значение введено пользователем или установлено в поле формы по умолчанию. Тег <INPUT> является одним из разносторонних элементов формы и позволяет создавать разные элементы интерфейса и обеспечить взаимодействие с пользователем. Главным образом <INPUT> предназначен для создания текстовых полей, различных кнопок, переключателей и флажков. Хотя элемент <INPUT> не требуется помещать внутрь контейнера <FORM>, определяющего форму, но если введенные пользователем данные должны быть отправлены на сервер, где их обрабатывает CGI-программа, то указывать FORM обязательно. То же самое обстоит и в случае обработки данных с помощью клиентских приложений, например, скриптов на языке JavaScript. Основной параметр тега <INPUT>, определяющий вид элемента — type. Он позволяет задавать следующие элементы формы: текстовое поле (text), поле с паролем (password), переключатель (checkbox), флажок (radiobutton), скрытое поле (hidden), кнопка (button), кнопка для отправки формы (submit), кнопка для очистки формы (reset), поле для отправки файла (file) и кнопка с изображением (image). Для каждого элемента существует свой список параметров, которые определяют его вид и характеристики. Синтаксис:
<form> <input ...> </form>
Дополнительные сведения : http://www.htmlbook.ru/html/input.html
Доступ к полям формы. Класс %CSP.Request
При получении CSP-запроса CSP-сервер создает экземпляры класса %CSP.Request, которые доступны через переменную %request. Каждая форма имеет поля ввода, которые в соответствии со стандартом HTML оформляются в виде: «имя/значение». Переменная %request позволяет получить доступ к полю ввода формы по его имени. Например, для формы с полями ввода и именами соответственно: ID, Fam, Im, переменная %request позволит получить значения этих полей. Переменная %request это объект со своими свойствами и методами, которые приведены в следующей таблице:
Таблица 1 – Свойства объекта %request.
|
Имя |
Возвращаемое значение |
Функция |
Аргументы |
|
Count |
%Library.Integer |
Число значений для заданного имени поля |
Имя поля ввода (%Library.String) |
|
Get |
Соответствует аргументу |
Извлекает данные, посланные в запросе |
Имя поля ввода (%Library.String), необязательный второй параметр задает значение по умолчанию для поля |
|
Kill |
Нет |
Удаляет поле ввода из объекта %request |
Имя поля (%Library.String) |
|
Next |
%Library.String |
Перебрать все поля формы, вернуть имя следующего поля формы
|
Имя предыдущего поля или «» (%Library.String) |