

Вопросы для самоконтроля по главе
Какая матрица называется платежной?
Что называют нижней (верхней) ценой игры?
Какой элемент матрицы игры называют Седловой точкой или точкой равновесия?
Сформулируйте понятие позиционной игры?
Что называют информационным множеством?
Какой процесс называют нормализацией позиционной игры?
Какие игры называют биматричными?
Выполнение каких неравенств определяет равновесную ситуацию для биматричных игр?
Всегда ли биматричная игра имеет равновесную ситуацию? Если имеет, то сколько?
Тест по главе
Каждый из двух игроков А и В одновременно и независимо друг от друга записывает на листе бумаге любое целое число. Если выписанные числа имеют одинаковую четность, то игрок А получает от игрока В 1 рубль, а если разную, то наоборот – игрок А платит 1 рубль игроку В. Какой вид будет иметь платежная матрица для этой задачи?



а) б) в)
Принцип построения стратегии игрока, основанный на минимизации максимальных потерь, называют принципом …
а) максимина, б) минимакса.
Каким из соотношений связаны верхняя и нижняя цены игры в общем случае?
а![]() )α
≤
,
б) α
=
,
в) α
<
.
)α
≤
,
б) α
=
,
в) α
<
.
4![]()
![]()
![]()
![]() .
32
игра заданна матрицей . Цена
игры и оптимальные смешанные стратегии
игроков А и В соответственно равны
.
32
игра заданна матрицей . Цена
игры и оптимальные смешанные стратегии
игроков А и В соответственно равны
а) = -1, P={1; -1; 0} б) = 0, P={ ; ; 0} в) = 1, P={ ; ; 0}
![]()
![]()
![]()
![]() Q={1
; -1} Q=
{
; }
Q=
{
; }
Q={1
; -1} Q=
{
; }
Q=
{
; }
5.
Если выигрыш первого игрока
![]() а второго
а второго![]() то они связаны соотношением:
то они связаны соотношением:
а)
![]() ;
б)
;
б)![]() ;
в)
;
в)![]() .
.
Глава V. Исследование операций.
5.1. Динамическое программирование
Динамическое программирование есть особый метод оптимизации решений, специально приспособленный к так называемым «многошаговым» или «многоэтапным» операциям.
Постановка задачи
Представим себе некоторую операцию Q, распадающуюся на ряд последовательных шагов, - например, деятельность предприятия в течении нескольких хозяйственных лет; поэтапное планирование инвестиций, управление производственными мощностями в течении длительного срока и т.п. Некоторые операции расчленяются на шаги естественно, другие же требуют искусственного членения. Например, процесс наведения ракеты на цель модно условно разбить на этапы, каждый из которых занимает какое-то время t.
Рассмотрим управляемый процесс. Предположим, что управление можно разбить на n шагов, т.е. решение принимается последовательно на каждом шаге, а управление, переводящее систему из начального состояния в конечное, представляет собой совокупность n пошаговых управлений. В результате управления система переходит из состояния x0 в xn.
Обозначим через ukЄUk управление на k-ом шаге (k=1,2,…,n). Uk – множество допустимых управлений на k-ом шаге.
Пусть u=(u1,u2,…,un )- управление, переводящее систему из состояния x0 в состояние xn. Обозначим через xk состояние системы после k-го шага управления. Получаем последовательность состояний x0, x1, …, xk-1, xk, xk+1, …, xn (рис.5).

u1 u2 uk-1 uk uk+1 uk+2 un
… …
рис.5.
Показатель эффективности рассматриваемой управляемой операции зависит от начального состояния и управления: Z = F(x0,u) (1)
uU – множество возможных управлений.
Сделаем несколько предположений:
Состояние XK системы на k-ом шаге зависит только от предшествующего состояния Хk-1 и управления на k-ом шаге uk и управлений (свойство отсутствия последействия): Xk = k(xk-1, uk), k = 1, n – уравнения состояний (20), k – оператор перехода.
Ц
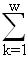 елевая
функция (1) является аддитивной от
показателя эффективности каждого шага,
т.е. выигрыш за всю операцию складывается
из выигрышей на отдельных шагах.
елевая
функция (1) является аддитивной от
показателя эффективности каждого шага,
т.е. выигрыш за всю операцию складывается
из выигрышей на отдельных шагах.
Z = F(x0, u) = fk(xk-1, uk) (3)
fk(xk-1, uk) = Zk – показатель эффективности шага k (4).
Общая постановка задачи ДП. Определить такое допустимое управление uU, переводящее систему из состояния x0 в состояние хn, при котором целевая функция (3) принимает максимальное значение.
Любую многошаговую задачу можно решать по разному: либо искать сразу все элементы решения на всех n шагах, либо же строить оптимальное управление шаг за шагом, на каждом этапе расчета оптимизируя лишь один шаг. Обычно второй способ оказывается проще, чем первый, особенно при большом числе шагов.
Пусть, например, планируется работа группы промышленных предприятий, из которых часть занята выпуском предметов потребления, а остальные производят для них машины. Задача – получить за n лет максимальный объем выпуска предметов потребления. Допустим планируются капиталовложения на первый год. Исходя из узких интересов этого шага, мы должны были бы все наличные средства вложить в производство предметов потребления. Это решение недальновидное. Имея в виду будущее, надо выделить какую-то часть средств и на производство машин. От этого объем продукции за первый год, конечно, снизится, зато будут созданы условия для его увеличения в последующие годы.
Управление на i-ом шаге выбирается не так чтобы выигрыш именно на данном шаге был максимален, а так, чтобы была максимальна сумма выигрышей на всех оставшихся до конца шагах плюс данный.
Однако из этого правила есть исключение. Среди всех шагов есть один, который может планироваться попросту, без оглядки на будущее. Какой это шаг? Очевидно последний! Этот шаг, единственный из всех, можно планировать так, чтобы он сам, как таковой, принес наибольшую выгоду.
Поэтому процесс ДП обычно разворачивается от конца к началу: прежде всего планируется последний, n-ый шаг.
Планируя последний шаг, нужно сделать разные предположения о том, чем кончился предпоследний, (n-1)-ый шаг, и для каждого из этих предположений найти условное оптимальное управление на n-м шаге. «Условное» потому, что оно выбирается исходя из условия, что предпоследний шаг кончился определенным образом.
Далее, «пятясь» назад, оптимизируем управление на (n-2)-м шаге и т.д., пока не дойдём до первого.
Предположим, что все условия оптимальные управления и условные оптимальные выигрыши за весь «хвост» процесса нам известны. Это значит: мы знаем, что надо делать, как управлять на данном шаге и что мы за это получим на «хвосте», в каком бы состоянии ни был процесс к началу шага. Теперь мы можем построить уже не условно оптимальное, а просто оптимальное управление U* и найти не условно оптимальный, а просто оптимальный выигрыш Z*.
Таким образом, в процессе оптимизации управления методом ДП многошаговый процесс «проходится» дважды: первый раз – от конца к началу, в результате чего находится условные оптимальные управления и условные оптимальные выигрыши за оставшийся «хвост» процесса; второй раз - от начала к концу, когда нам остаётся только «прочитать» уже готовое управления U*, состоящее из оптимальных шаговых управлений u1*, u2*, …, un*.
![]() Предположим, что
задача
Предположим, что
задача
Z = F(x0,
u) = fk(xk-1,
uk)
max
= F(x0,
u) = fk(xk-1,
uk)
max
xk=k(xk-1, uk), k=1,5
u kUk,
k=1, n
kUk,
k=1, n
 xkXk,
k=0,
n
имеет решение.
xkXk,
k=0,
n
имеет решение.
Тогда справедлив принцип оптимальности Беллмана: оптимальное управление
u* = (u1*, u2*, …, un*) обладает тем свойством, что каковы бы ни были состояния системы
x*k-1 на любом шаге и управление uk*, принимаемое в этом состоянии; последующие управляющие решения u*k+1, …, u*n должны составлять оптимальную стратегию относительно состояния х*k, полученного в результате управляющего решения uk*, т.е. состояния, к которому придёт система в конце данного шага.
На основании принципа оптимальности Беллмана можно получить основное уравнение ДП, или уравнение Беллмана.
Рассмотрим n-ый шаг: xn-1 – состояние системы к началу n-ого шага, xn – конечное состояние, un – управление на шаге n, а fn(xn-1, un) – целевая функция шага n.
Согласно принципу оптимальности, un нужно выбирать так, чтобы для любых состояний xn-1 получить максимум целевой функции на этом шаге.
Обозначим через Zn*(xn-1) максимум показателя эффективности шага n при условии, что к началу последнего шага система была в произвольном состоянии xn-1, а на последнем шаге управление было оптимальным.
Zn*(xn-1) = max fn(xn-1, un) (5)
![]()
Решив задачу (5), найдём для всех возможных состояний xn-1 две функции: Zn*(xn-1) и Un*(xn-1) – условное оптимальное управление.
Рассмотрим двухшаговую задачу: присоединим к n-му шагу (n-1)-ый (рис.6.)

Для любых состояний xn-2, произвольных управлений Un-1 и оптимального управления на шаге n значение целевой функции на двух последних шагах равно fn-1(xn-2, Un-1) + Zn*(xn-1) (6).
Согласно принципу оптимальности необходимо искать максимум (6) по всем допустимым un-1.
Z![]() *n-1(xn-2)
= max
{ fn-1(xn-2,
un-1)
+ Zn*(xn-1)
}, k
= n-1,
1 (7)
*n-1(xn-2)
= max
{ fn-1(xn-2,
un-1)
+ Zn*(xn-1)
}, k
= n-1,
1 (7)
В результате максимизации получаем две функции: u*n-1(xn-2) и Z*n-1(xn-2)
Далее рассматривается трёхшаговая задача: к двум последним добавляется (n-2)-ой и т.д.
Так для произвольного k получим:
![]() Zk*(xk-1)
= max { fk(xk-1,
uk)
+ Z*k+1((xk-1,
uk)},
k = n-1, 1
Zk*(xk-1)
= max { fk(xk-1,
uk)
+ Z*k+1((xk-1,
uk)},
k = n-1, 1
Уравнение (8) называются уравнениями Беллмана, позволяющими найти предыдущие значения функции, зная последующие. Процесс решения уравнений (5) и (8) называется условной оптимизацией.
В результате условной оптимизации получаем две последовательности:
Zn*(xn-1), Z*n-1(xn-2), …, Z1*(x0) и un*(xn-1), u*n-1(xn-2), …, u1*(x0)
Используя эти последовательности, можно найти решение задачи ДП при данных n и x0:
Zmax = Z1*(x0)