

Серьезной проблемой сетей WTA является проблема мертвых нейронов, т.е. тех нейронов, которые ни разу не победили, это увеличивает погрешность распознавания данных. Решением этой проблемы может быть:
метод штрафования (временной дисквалификации) тех нейронов, которые побеждали чаще всего. Дисквалификация слишком активных нейронов может осуществляться либо назначением порогового числа побед, по достижение которого нейрон временно исключается из борьбы, либо уменьшением фактического значения Ui при нарастании количества побед i-того нейрона.
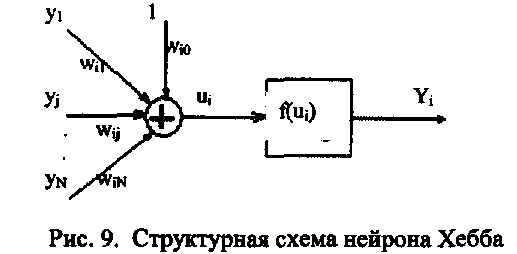
Модель нейрона Хебба
Структурная
схема нейрона Хебба похожа на стандартную,
за исключением, что на входы поступают
выходные сигналы других нейронов.
![]()
 .Хебб
в процессе исследования нервных клеток
заметил, что
связь
между двумя клетками усиливается,
если обе клетки становятся активными
в один и тот же момент времени. По
результатам
наблюдения Хебб предложил правило:"Вес
нейрона изменяется пропорционально
произведению его входного и выходного
сигнала":
.Хебб
в процессе исследования нервных клеток
заметил, что
связь
между двумя клетками усиливается,
если обе клетки становятся активными
в один и тот же момент времени. По
результатам
наблюдения Хебб предложил правило:"Вес
нейрона изменяется пропорционально
произведению его входного и выходного
сигнала":
Обучение по правилу Хебба может проводится как без учителя так и с ним. Во втором случае формула меняется следующим способом.
![]()
При использования правила Хебба веса могут принимать произвольно большие значения, т.к. происходит постоянное их увеличение:
•1![]()
Один из способов стабилизации процесса является использование коэффициента забывания. При этом правило обучения принимает следующий вид:
![]()
Коэффициент
забывания![]() выбирается из интервала (0,1) и как правило
составляет некоторый процент
от коэффициента обучения. При больших
значениях коэффициента забывания,
нейрон много
забывает и плохо обучается. Рекомендуемое
для него значение меньше 0,1.
выбирается из интервала (0,1) и как правило
составляет некоторый процент
от коэффициента обучения. При больших
значениях коэффициента забывания,
нейрон много
забывает и плохо обучается. Рекомендуемое
для него значение меньше 0,1.
Пример
Рассмотрим сеть со следующей структурой
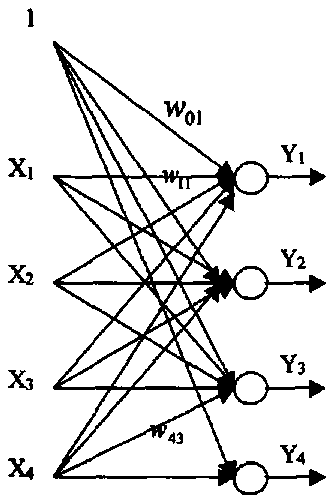
Обучение происходило на 3 векторах:
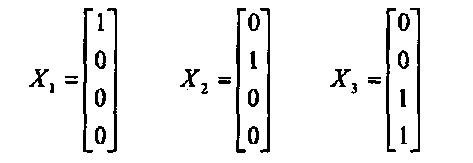
Значение поляризации определено константой и равно 0.5.
Матрица весов инициализирована следующими значениями (столбец- это веса одного нейрона):
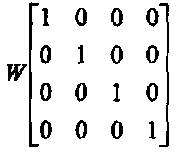
Функция активации выбрана ступенчатого вида:
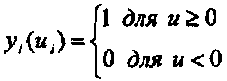
После 40 циклов обучения без учителя значения весов изменились:

Таким образом, видно, первый нейрон реагирует на первый вектор, второй - на второй вектор (их
значения увеличились). Также проявились связи третьего и четвертого нейронов с третьем и
четвертым входами сети.
Сеть легко узнает вектора, если их подать в неизмененном виде. Если же изменить вектор, например
Х3 =[0 0 1 0]г, то сеть проявляет свои ассоциативные свойства и узнает 3 вектор, выдавая на
выходах 3-его и 4-ого нейронов 1 (рис.).
Если входной вектор Х3 =[1 0 1 1]г, то выход будет У =[1 О 1 1]г, т.е. сеть узнает все
вектора, кроме второго, элемент которого отсутствует во входной векторе.


Существуют также 2 другие модели нейронов о которых я не рассказал:
-
стохастическая модель. В ней выходное значение нейрона зависит не только от взвешенной суммы, но и от некоторой случайно величины, значение которой выбирают при каждой реализации из интервала (0,1).
-
нейрон типа "адалайн" использует функцию активации signum

Литература
1. Станислав Осовский "Нейронные сети для обработки информации", изд. "Финансы и статистика", 344 с.,2002 г.
Глава 2. Подбор коэффициента обучения
Правильно
выбрать коэффициент обучения крайне
важно. Слишком малое значение![]() не
позволяет
минимизировать целевую функцию за один
шаг и вызывает необходимость повторно
двигаться
в том же направлении. Слишком большой
шаг приводит к перепрыгиванию через
минимум
функции и фактически заставляет
возвращаться к нему.
не
позволяет
минимизировать целевую функцию за один
шаг и вызывает необходимость повторно
двигаться
в том же направлении. Слишком большой
шаг приводит к перепрыгиванию через
минимум
функции и фактически заставляет
возвращаться к нему.
Существуют
различные способы подбора коэффициента
обучения. Простейший из них (относительно
редко применяемый в настоящее время)
основан на фиксации постоянного значения
![]() на
весь период обучения. Этот способ
практически используется с методом
наискорейшего
спуска, но имеет малую эффективность.
Для каждого слоя выбирается свой
коэффициент
обучения. Один из методов его подбора
сформулирован так:
на
весь период обучения. Этот способ
практически используется с методом
наискорейшего
спуска, но имеет малую эффективность.
Для каждого слоя выбирается свой
коэффициент
обучения. Один из методов его подбора
сформулирован так:
![]()
где![]() -
количество входов i-го
нейрона в слое.
-
количество входов i-го
нейрона в слое.
Другой
эффективный способ основан на адаптивном
подборе коэффициента обучения с учетом
фактической
динамики величины целевой функции в
результате обучения. Согласно этому
методу стратегия изменения
![]() определяется динамикой изменения
погрешности целевой
определяется динамикой изменения
погрешности целевой
ф ункции
(сравнивается ее текущее значение с
предыдущим). Погрешность определяется
следующим
способом;
ункции
(сравнивается ее текущее значение с
предыдущим). Погрешность определяется
следующим
способом;
Погрешность должна постепенно уменьшаться, хотя в некоторых случаях может временно
незначительно возрасти (это считается допустимым).
Обозначим
погрешности на разных итерациях как![]() и
и
![]() ,
а коэффициенты обучения на
,
а коэффициенты обучения на
соответствующих
итерациях -![]() Рассмотрим
2 ситуации:
Рассмотрим
2 ситуации:
![]() (kw
коэффициент
допустимого роста погрешности) В
этом случае
(kw
коэффициент
допустимого роста погрешности) В
этом случае![]() должно
уменьшиться согласно формуле:
должно
уменьшиться согласно формуле:
![]()
![]() - коэффициент
уменьшения
- коэффициент
уменьшения![]()
В
противном случае, когда![]() ,
принимается
,
принимается
![]()
![]() - коэффициент
увеличения
- коэффициент
увеличения![]()
Несмотря
на то, что объем вычислений возрастает,
т.к. нужно рассчитывать ошибку, этот
метод позволяет
значительно ускорить процесс обучения.
Следует отметить, что при использование
этого
метода, значение коэффициента обучения
вначале возрастает, но после некоторого
значения постепенно
уменьшается, но не монотонно, а циклически
возрастая и понижаясь в следующих друг
за другом циклах. Однако,
надо знать, что адаптивный метод сильно
зависит от коэффициентов![]() .
Их
.
Их
можно удачно подобрать для ускорения одной задачи, но те же параметры могут т сильно
замедлить процесс решения другой задачи.
Существуют и другие, более эффективные методы выбора коэффициента. Один из них основан на
аппроксимации целевой функции, с последующим расчетом ее минимума.
Аппроксимируем ее многочленом второй степени:
![]()
Для расчета коэффициентов используются три точки. Соответствующие этим точка значения целевой функции Е1 = E(wl ),Е2 = E(w2), Е2 = E(w2). Получаем
![]()
Коэффициенты![]() рассчитываются
в соответствии с системой линейных
уравнений
рассчитываются
в соответствии с системой линейных
уравнений
описываемых (6)
Для
определения минимума этого многочлена
его производная приравнивается к нулю:
![]()
Это позволяет получить значение минимума коэффициента обучения в виде:
![]()
После подстановки выражений для Е1 ,Е2 ,Е3 в формулу (8) получается:
![]()
Однако
наиболее удачным решением считается
использование градиентных методов, в
которых кроме
значения функции, учитывается также
ее производная. Они позволяют значительно
ускорить
достижение минимума, поскольку используют
информацию о направлении уменьшения
величины
целевой функции. В такой ситуации
применяется аппроксимирующий многочлен
третьего
порядка:![]()
Далее происходят аналогичные вычисления. Подробное описание этого метода можно найти в первоисточниках, посвященных теории оптимизации [39,170].