

Тема 5. Решение экономических задач компьютерными средствами
1. Информатика в экономике: Учебное пособие/Под ред. Б.Е. Одинцова, А.Н. Романова. – М.: Вузовский учебник, 2008.
2. Информатика: Базовый курс: Учебное пособие/Под ред. С.В. Симоновича. – СПб.: Питер, 2009.
3. Информатика. Общий курс: Учебник/Соавт.:А.Н. Гуда, М.А. Бутакова, Н.М. Нечитайло, А.В. Чернов; Под общ. ред. В.И. Колесникова. – М.: Дашков и К, 2009.
4. Информатика для экономистов: Учебник/Под ред. Матюшка В.М. - М.: Инфра-М, 2006.
5. Экономическая информатика: Введение в экономический анализ информационных систем.- М.: ИНФРА-М, 2005.
Понятие и классификация моделей объектов, процессов и систем
Главная же причина создания моделей состоит в бесконечной сложности окружающего человека мира, в котором изучаемые им процессы и объекты имеют огромное количество свойств и взаимосвязей. Чтобы понять, как действует реальный объект, приходится вместо него рассматривать его упрощенное представление – модель.
Модель (лат. modulus) – это упрощенный объект-заменитель объекта-оригинала, в котором отражаются его существенные особенности (свойства). Чем меньше подробностей оригинала отражено в модели, тем она проще.
Существуют
Образные (материальные, предметные) – это физические модели. Они воспроизводят геометрические и физические свойства оригинала и всегда имеют материальное воплощение, отражая внешние свойства и частично внутренние устройства объекта-оригинала. Примерами здесь могут служить детские игрушки, скелет человека, макет солнечной системы и т.д.
Класс образных (материальных) моделей можно разделить на подклассы: опытные, учебные и игровые. Опытные модели – это уменьшенные искусственно созданные копии каких-либо реальных процессов (аэродинамическая труба, воссоздающая движение воздуха, синхрофазотрон, воссоздающий реальное движение частиц), учебные - наглядные пособия, тренажеры, обучающие программы, игровые модели - экономические, спортивные, деловые, бытовые.

Некоторые классы моделей
Знаковые (абстрактные) модели, в отличие от образных (материальных) не имеют внешнего (реального) сходства с оригиналом. Их основу составляет теоретический метод познания окружающей среды и по признаку формы воплощения они бывают: вербальные (мысленные), математические и информационные.
Вербальные (мысленные) модели формируются в воображении человека в виде некоторого образа, который затем выражается (вербализуется) в словесной форме.
Логико-лингвистические модели – это особая форма вербализации связей между объектами. Цель создания такого рода моделей состоит в описании объектов и связей таким образом, чтобы его преобразование и обработка могла осуществляться логическими средствами. Примером такой модели может служить запись
В настоящее время модели подобного рода развились в семантические сети, нечеткие выводы, в которых особое место занимает понятие «лингвистическая переменная».
С усложнением сфер моделирования, и, как правило, невозможностью натурного воспроизведения требуемых свойств оригинала, стало развиваться математическое моделирование.
Под математическим моделированием подразумевается процесс установления соответствия реальному объекту математического объекта, отражающего цели моделирования.
Математические модели воспроизводят реальные объекты и их связи с помощью математических символов (алгебраических, дифференциальных и конечно-разностных уравнений, предикатов и т.д.). Такого рода модели исследуются либо аналитически, (стремление получить явные зависимости для искомых величин) либо численно (при отсутствии общего решения отыскивается частное).
Математические модели, в соответствии с природой воспроизводимых процессов, можно разделить на детерминированные, вероятностные (стохастические) и имитационные (компьютерные).
Некоторые знания об окружающем мире условно можно характеризовать как определенные, отражающие вполне устоявшиеся взаимосвязи объектов, что подтверждается практикой. Модели, которые воспроизводят эти связи, обычно называются детерминированными, так как отражают причинно-следственные отношения между объектами или процессами. Задавая в этих моделях причину (исходные данные, значение переменных, значение параметров и т.д.) можно определить следствие (скорость, рентабельность, индекс валют и т.д.). Детерминированные модели можно разделить на дискретные и непрерывные.
Дискретные детерминированные модели воспроизводят процессы в отдельные промежутки времени. Например, формула расчета рентабельности, предназначенная для определения показателя на конец месяца, является дискретной детерминированной моделью, так как все переменные рассматриваются в качестве фиксированных величин на некотором промежутке времени.
Непрерывные детерминированные модели отражают процессы в любой момент времени. Для этого довольно используют дифференциальные уравнения. С их помощью выражается движение маятника, скорость изменения прибыли, зависящей от объемов продаж и т.д.
Стохастические модели воспроизводят вероятностные процессы и события. Если имеет место процесс, дальнейшая эволюция которого определяется только состоянием в предшествующий момент, а переход из состояния в состояние происходит в дискретные моменты времени, то воспроизводят с помощью цепей Маркова.
Стохастические модели оперируют вероятностями, которые не всегда можно получить, поэтому вместо них часто используют статистические модели. В основе такого моделирования лежит понятие парной регрессии – уравнения связи, которое может иметь разное количество переменны.
Известны линейные и нелинейные регрессии:
линейная:
![]() ;
;
нелинейная:
![]() (полином);
(полином);
![]() (гипербола).
(гипербола).
Имитационные модели. Моделирование сложных объектов и процессов сталкивается с трудностями как на этапе составления соответствующих детерминированных или стохастических уравнений, так и на этапе их решения. Основное препятствие состоит в формализации и математическом описании общесистемных ситуаций на базе умозрительного анализа взаимозависимостей составляющих их событий.
Такого рода трудности стимулировали разработку иного пути воспроизведения связей сложных объектов: это конструирование общесистемных ситуаций на компьютере, то есть имитирование моделируемого процесса.
Для этого необходимо:
а) необходимо задать границы пространства состояний объекта,
б) описание перемещения изучаемой точки,
в) указать правила расчета распределения вероятности скачка состояния при выходе точки за границу пространства,
г) указать правила расчета распределения вероятности скачка точки при поступлении входного сигнала,
д) указать правила расчета координат выходного сигнала.
Важная особенность моделей такого рода состоит в получении информации о состоянии объекта в произвольный момент времени. Сегодня достаточно широко используются модели, имитирующие природные аномалии, техногенные катастрофы, распространение заболеваний и т.д.
Информационные модели. Наибольшие трудности в обработке информации на компьютере встречаются на начальном этапе, предназначенном для приведения неформального описания экономических процессов (бизнес-процессов) к формальному. Нужная степень формализации достигается путем постепенной последовательной смены одного описания другим. Первое описание, как правило, выполняется в виде информационной модели, видов которых существует достаточно много, а последнее - на одном из языков программирования. Поэтому особое место в информатике занимают информационные модели, которые рассмотрим более подробно.
Информационные модели отражают информационные потоки между различными объектами. Они состоят из:
а) идентификаторов объектов;
б) идентификаторов потоков данных;
в) объемных, временных, частотных и других характеристик, как самих объектов, так и входящих и исходящих потоков данных;
г) последовательности процедур обработки потоков данных.
Цель информационного моделирования состоит в отражении в наглядной форме процессы сбора внешней и внутренней информации, ее регистрации на машинных носителях, передачи, обработки с указанием последовательности расчетов и использования.
Особенность такого рода моделей заключается в их графическом представлении, но при этом имеется возможность матричного или аналитического способа их отображения.
Наиболее распространенными графическими формами информационных моделей являются: диаграммы потоков данных (DFD), диаграммы IDEF1, сети Петри, сети управления и планирования, модели баз данных, модели баз знаний и т.д.
В информатике особенно широко используются такие информационные модели как табличные, иерархические и сетевые. Табличные модели отображают объекты и их свойства в виде списка, а их значения размещаются в ячейках прямоугольной формы. Наименования однотипных объектов размещены в первом столбце (или строке), а значения их свойств размещаются в следующих столбцах (или строках). Иерархические модели предназначены для выражения отношений соподчинения между объектами. Объект нижнего уровня может входить в состав только одного элемента более высокого уровня. Сетевые модели необходимы для отражения систем, в которых связи между элементами имеют сложную структуру.
Перечисленные информационные модели используются также и для создания и функционирования баз знаний – деревьев вывода, семантических сетей, деревьев целей, фреймов и т.д.
Заканчивая описание наиболее популярных моделей, используемых в практике управления, следует отметить, что большинство из них, так или иначе, реализуется с помощью компьютеров, то есть преобразуются в компьютерную модель. Поэтому далее необходимо рассмотреть сущность и этапы создания таковой.
Компьютерное моделирование
Компьютерная модель является представлением процесса обработки информации об объекте на алгоритмическом или программном языке, позволяющим использовать компьютер в практике управления.
Для того, чтобы создать такую модель, как правило, необходимо
1) выполнить постановку задачи,
2) создать собственно компьютерную модель,
3) затем осуществить компьютерный эксперимент и, наконец,
4) сделать анализ полученных результатов.
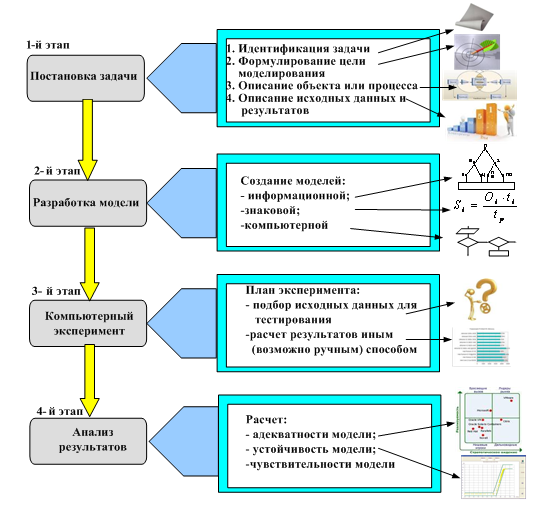
Этапы компьютерного моделирования
. Анализ результатов
Анализ результатов полученных с помощью созданной модели - заключительный этап моделирования. По полученным расчетным данным проверяется, насколько результаты соответствуют целям моделирования. Для модели определяют ее:
адекватность;
устойчивость;
чувствительность.
Адекватность - это степень соответствия модели и реального объекта (процесса) в важных интервалах параметров и исходных данных заданной точности. Модель может быть адекватна для одного диапазона одних параметров и неадекватна для других. В результате анализа адекватности определяют также область адекватности, т.е. диапазон тех значений исходных данных и параметров, где модель соответствует объекту. При планировании эксперимента и обработке результатов поиск границ области адекватности обязателен.
Для определения адекватности можно использовать характеристики модели, которые делят на три группы:
корректность;
достоверность;
устойчивость.
Характеристика адекватности связана с корректностью модели, если сравнение модели производится с набором требований, предъявляемых к полученным результатам. Для характеристики адекватности, описывающей корректность, может использоваться эталонная модель, представленная неким стандартом - описанием способа получения нужных значений характеристик или критерием оценки достоверности или описанием принадлежности некоторому отношению (или истинности соответствующего предиката) и др.
Адекватность модели может также характеризоваться достоверностью, если с ее помощью оценивается «близость» значений некоторых характеристик модели и реальных характеристик объекта.
Устойчивость модели – это уровень изменения выходных параметров при изменении входных. Если в модели при малых изменениях входных параметров сильно меняются выходные, то имеет место высокий уровень ее чувствительности. В различных ситуациях может быть либо слишком высокая чувствительность, либо недостаточная. Высокая чувствительность модели ведет к неустойчивости результатов, низкая - к тому, что ее параметры являются несущественными, что указывает на необходимость их дополнительного изучения.
Если полученные результаты не соответствуют целям поставленной задачи, значит, на предыдущих этапах были или неправильно отобраны свойства объекта или допущены ошибки в формулах на этапе формализации или использован неудачный метод или не та среда моделирования и т.д. В этом случае модель корректируется.
Модели и структуры данных
С точки зрения компьютерной обработки различают структурированные и неструктурированные сообщения (исходные данные).
Неструктурированные вводятся, хранятся и передаются на естественном языке, а структурированные – на искусственном.
Понятие “структура” используется в том случае, если возникла необходимость представить множество каких-либо элементов и отношений (связей) между ними.
Поэтому обработка данных с помощью компьютера требует определения их структуры, то есть порядка размещения однотипных связанных данных в его памяти.
Структура данных зависит от цели их обработки и специфики отражаемых реальных объектов или событий. В дальнейшем под структурой данных будет пониматься совокупность элементов данных, между которыми указаны связи (отношения). Связи между элементами устанавливают порядок доступа к ним в процессе обработки. Элементы данных размещаются в ячейках памяти, имеющих адреса.
Так как структура данных указывает на способ их организации в памяти компьютера, поэтому, как правило, под структурой данных подразумевают структуру хранения данных. Известны следующие типовые структуры данных: линейные (одномерный массив, двумерный массив), и нелинейные (списочные структуры, древовидные и сетевые).
Линейные одномерные массивы
Данная структура предполагает размещение элементов данных в непрерывной последовательности ячеек памяти компьютера
Наиболее важными из однородных (линейных) структур данных являются очередь и стек. Очередь содержит элементы, выстроенные друг за другом в цепочку, у которой есть начало и конец. Добавлять новые элементы можно только в конец очереди, забирать элементы можно только из начала.

Двумерные массивы
На рис. 6.10б указан способ хранения данных в виде двумерного массива. Он применяется в том случае, если длина строки или столбца известны. Как правило, при обработке двумерных массивов известны и номера строк и номера столбцов (матрицы). Тогда для поиска нужного элемента достаточно указать номер строки и номер столбца.
Нелинейные структуры
Списочные структуры
Довольно часто данные в компьютере располагаются не в последовательных ячейках, а в произвольных частях памяти. Для того, что бы задать связь между различными элементами данных применяют указатели. Списочная линейная структура представлена на рис. 6.10а. В ней первая ячейка содержит адрес первого элемента данных, вторая элемент данных и адрес следующего элемента данных и т.д. Последняя ячейка содержит элемент данных и указатель конца списка.
Двухсвязный линейный список представлен на рис. 6.10б. Каждый элемент списка, кроме первого и последнего, содержит три поля, первое и третье из которых имеют указатели на предыдущий и последующий элементы.
Цикличный линейный список, представленный на рис. 6.10в, позволяет организовать переход с последнего элемента списка на первый. Образуется кольцо, выход из которого возможен после получения некоторого сигнала.

Рис. 6.10. Списочная структура данных: линейная (а), двухсвязная (б), циклическая (в)
Древовидная структура используется в случае необходимости отражения отношений соподчиненности между объектами или процессами. Деревом называется множество элементов, называемых узлами, таких, что:
между узлами имеет место отношение типа «исходный - порожденный».
Есть только один узел, не имеющий исходного – корень.
Все узлы, за исключением корня, имеют только один исходный.
Ни один порожденный узел не может стать исходным.
На рис. 6.11 представлено две формы моделирования иерархических отношений: иерархическое дерево, отражающее отношение соподчиненности (а) и структура данных, позволяющая отразить эти отношения в памяти компьютера (б).
Узел иерархической структуры данных в данном случае содержит три поля: одно для размещения собственно данных и два для указателей (на подчиненный и на соседний узел).
В информатике существует ряд разновидностей деревьев.
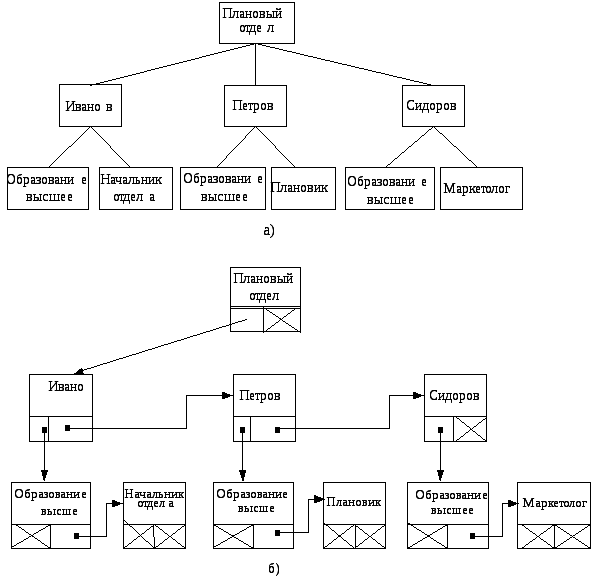
Рис. 6.11. Древовидная структура: а) иерархическая структура, б) древовидная структура данных
Бинарное дерево
Особое значение прибрели бинарные деревья (binary tree)) упорядоченное дерево, каждая вершина которого или пустая или состоит из одного корня и двух бинарных поддеревьев.
Сетевая структура представляет собой структуру наиболее общего вида, так как способна воспроизводить большинство связей между объектами. На рис. 6.14а представлена сеть автомобильных дорог, а на рис. 6.14б структура данных, позволяющая представить эту сеть в памяти компьютера. Для этого в сети используется два типа узлов: те, что отражают название города (тип 1), и те, что отражают расстояние между ними (тип 2). На рис. 6.14в указано содержание узла типа 1, а на рис. 6.17г – типа 2.

Рис. 6.14. Сеть автомобильных дорог- а), сетевая структура данных - б), содержание узлов первого типа - в), содержание узлов второго типа - г)
С понятием «структура данных» тесно связано понятие «модель данных», что можно представить следующим образом:
Модель данных - это структура данных с заданными над ними операциями для обработки. Содержательно структура данных является составной частью модели данных.
Различают следующие базовые модели данных: реляционные (двумерные массивы), иерархические и сетевые. Кроме перечисленных известно множество моделей, отражающих цели их создателей (сущность-связь, бинарные модели, семантические сети и т.д.).
Реляционная модель основывается на понятии “отношение”, и представляется совокупностью таблиц. На рис. 6.15 приведены базовые понятия данной модели.

Рис. 6.15. Основные понятия реляционной модели базы данных
Домен – это множество значений, принимаемых свойствами (характеристиками) отражаемого объекта.
Атрибут – это имя множества значений, входящих в домен. Атрибуты используются в качества средства для обращения к доменам.
Кортеж – это множество элементов из доменов, составляющих одну строку отношения (таблицы).
Отношение – это множество кортежей, отражающих свойства объекта.
Таблицы, входящие в реляционную модель, строятся в рамках ограничений, диктуемых операциями их обработки. Это следующие ограничения:
таблица должна иметь имя (например, ДЕТАЛЬ, ПОСТАВЩИК, ПОСТАВКИ);
таблица должна быть простой, то есть не содержать составных столбцов, например, у поставщика должен быть только один номер телефона;
в таблице не должно быть одинаковых строк;
должен быть известен первичный ключ, используемый для поиска или выполнения других логических операций.
В компьютере таблицы реляционной модели обрабатываются с помощью операций реляционной алгебры.
Понятие алгоритма, его свойства и способы описания
Алгоритм – это точное предписание о выполнении в определенном порядке некоторой системы операций (шагов) для решения всех задач некоторого типа.
Точно указать шаги в алгоритме с помощью естественного языка, в силу его неоднозначности, достаточно сложно. Поэтому обращаются к символьным, то есть искусственным языкам. Наиболее распространенными формами искусственных языков, используемых для представления алгоритмов, являются:
- формульное описание, предназначенное для представления процесса решения несложных задач, базирующихся на локальных вычислениях;
- задание алгоритмов в виде блок-схем, широко распространенное для представления большого числа логических условий;
- словесное описание правил в виде фраз естественного языка с ограниченным синтаксисом.
Формульное описание алгоритма
Примером задания алгоритма в формульном виде может служить представление процесса начисление заработной платы сотруднику:
Задание алгоритмов с помощью блок-схем
Достаточно часто алгоритмы записываются в виде блок-схем, которые являются графическим представлением последовательности действий. В этом случае, они состоят из отдельных блоков. Их начертание определено российским стандартом ГОСТ 19.701-90 (единой системой программной документации), который разработан путем прямого применения международного стандарта ISO 5807-85.
Блоки алгоритма отражают содержание элементарного действия, а связывающие их направленные линии – последовательность выполнения. Для создания блок-схем используют стандартные графические изображения.

Рис. 6.16. Основные графические изображения, используемые при описании алгоритмов.
Блоки могут связываться в одну из следующих конструкций:
линейная (последовательная);
простой выбор;
множественный выбор;
цикл.
Рассмотрим представление некоторых основных алгоритмических конструкций с помощью блок-схем.
Линейный алгоритм
Блок схема рассмотренного ранее линейного алгоритма вычисления значения «F» в графической форме, представлена на рис.6.17)

Рис.6.17. Линейная конструкция алгоритма
Линейная структура указывает на последовательность операций, которые следует выполнить в определенной последовательности.
Простой выбор
Конструкция «простой выбор» реализует правило: если выполняется ‹условие 1›, то производится Операция 1, иначе производится Операция 2 (см. рис.6.21).

Рис.6.18. Изображение алгоритма простого выбора на блок-схеме
Рис.6.19. Пример конструкции «простой выбор»
Множественный выбор
Конструкция ”множественный выбор” используется в том случае, если имеется несколько вариантов условий, которые отражают взаимоисключающие случаи. Добавим в предыдущий пример дополнительные условия

Рис.6.20. Пример конструкции «множественный выбор»
Цикл
Циклом называется многократно повторяемый участок вычислений. Вычислительный процесс, содержащий один или несколько циклов, называется циклическим. По количеству выполнения циклы делятся на циклы с определенным (заранее заданным) числом повторений и циклы с неопределенным числом повторений. Количество повторений последних зависит от соблюдения некоторого условия, задающего необходимость выполнения цикла.
Если условие проверяется в начале цикла - тогда речь идет о цикле с предусловием (Рис.6.21).

Рис.6.21 Фрагмент алгоритма цикла с предусловием
Если условие проверяется в конце цикла, то имеем дело с циклом с постусловием (рис.6.22).

Рис.6.22 Фрагмент алгоритма цикла с постусловием
Любой алгоритм, представленный блок-схемой, это образование из связанных между собой или вложенных друг в друга четырех конструкций перечисленных ранее. Описание алгоритма в виде блок-схемы хорошо обозримо и его легко модифицировать.
Существуют различные подходы к разработке алгоритмов. Большинство из них базируются на принципе «сверху – вниз» когда на начальных этапах разработки создается общая схема, содержащая основные крупные блоки. Далее производится их последовательная детализация, то тех пор, пока не станет возможным реализация алгоритма на языках программирования.
Однако, в ряде случаев уместно использования принципа «снизу вверх». Тогда используется заранее определенный и корректный набор подалгоритмов, на их основе создаются функционально завершенные подзадачи более высокого уровня. От них происходит переход к все более общим алгоритмам, до тех пор, пока не будет достигнуто решение поставленной задачи.
Сказанное выше можно проиллюстрировать следующей схемой (рис.6.23). На ней показано, что при нисходящем проектировании алгоритма (сверху-вниз), при создании модуля более высокого уровня (Модуль 1) нижестоящие подалгоритмы (в нашем случае Модуль 2 и Модуль 3) на первом этапе не детализируются.

Рис. 6.23. Схема, поясняющая разницу между двумя подходами при создании алгоритмов
Их разработкой занимаются уже после окончания работ над алгоритмом более высокого уровня.
При проектировании с использованием восходящего проектирования алгоритмов (рис. 6.26) сначала создаются (или берутся готовыми из библиотеки алгоритмов), модули нижнего уровня (в нашем случае это Модуль В и Модуль С), а затем на из основе формируется алгоритмический модуль более высокого уровня и, возможно, даже общий алгоритм решения поставленной задачи.
Словесное описание алгоритма
Если использование формульных зависимостей при создании алгоритмов не представляется возможным, то алгоритм можно задать в виде словесного описания правил с помощью синтаксически ограниченных фраз естественного языка.
Дальнейшим развитием этого подхода, является использование псевдокода. Псевдокод - компактный (зачастую неформальный) язык описания алгоритмов, использующий ключевые слова языков программирования, но опускающий несущественные подробности и их специфический синтаксис.
Псевдокод обычно опускает детали, так как главная его цель - обеспечить понимание алгоритма человеком, сделать описание более воспринимаемым, чем исходный код на языке программирования. Псевдокод широко используется в учебниках и научно-технических публикациях, а также на начальных стадиях разработки компьютерных программ.
Например, рассмотренный ранее алгоритм оформления счета на псевдокоде имеет следующий вид:
начало алгоритм оформления счета
нц для i:=1 до количество_строк делать
сумма_по_строке[i]:=количество_предметов[i]*цена[i];
кц;
сумма_счета:=0;
нц для i:=1 до количество_строк делать
сумма_счета:= сумма_счета + сумма_по_строке[i];
кц;
сумма_скидки :=0;
нц для i:=1 до количество_строк делать
если сумма_по_строке[i]<250000 и сумма_по_строке[i]>=100000 то
скидка[i]:= сумма_по_строке[i]*0.01;
сумма_скидки := сумма_скидки+ скидка[i];
конец_если;
если сумма_по_строке[i]<1000000 и сумма_по_строке[i]>=250000 то
скидка[i]:= сумма_по_строке[i]*0.025;
сумма_скидки := сумма_скидки+ скидка[i];
конец_если;
если сумма_по_строке[i]>=1000000 то
скидка[i]:= сумма_по_строке[i]*0.05;
сумма_скидки := сумма_скидки+ скидка[i];
конец_если;
кц;
сумма_счета:= сумма_счета- сумма_скидки;
затраты_на_доставку :=0;
нц для i:=1 до количество_строк делать
если срочность_доставки = истина то
затраты_на_доставку := затраты_на_доставку + вес[i]*10000;
иначе
затраты_на_доставку := затраты_на_доставку + вес[i]*1000;
конец если;
кц;
кц алгоритм оформления счета.
В этой записи начало алгоритма обозначено «начало алгоритм оформления счета», его конец «кц алгоритм оформления счета». Используется понятие оператора - наименьшей автономной исполняемой части языка псевдокода. Как правило, оператор заканчивается знаком «;», а весь алгоритм знаком «.».
В псевдокоде широко используются выражения: “:=” - операция присваивания, “+”, ”-“, “*” и “/” - операции сложения, вычитания, умножения и деления, соответственно, а также логические функции “и”, “или”, “не” (&, |, ^, and,or, not). Кроме численных, используются логические переменные, принимающие значения истина/ложь (true/false) и знаки “>”- больше, ”<”- меньше, “=”- равно.
Номера строк счета в описании алгоритма, обозначаются в квадратных скобках, как элементы массива с номером «i». Следует отметить, что ключевые слова в псевдокоде выделяются жирным шрифтом и/или подчеркиванием.
Решение задач с использованием типовых алгоритмов обработки данных
Линейные алгоритмы в псевдокоде представляют простую последовательность операторов. Например,
сумма_счета:=0;
сумма_счета:= сумма_счета- сумма_скидки;
затраты_на_доставку :=0;
Простой выбор задается конструкцией «если»
если <условие> то <действие 1> иначе <действие 2> кц_если;
Здесь конец_если означает окончание действия условия. Например,
если срочность_доставки = истина то
затраты_на_доставку := затраты_на_доставку + вес[i]*10000;
иначе
затраты_на_доставку := затраты_на_доставку + вес[i]*1000;
конец если;
Множественный выбор при “n” условиях обычно записывают с помощью оператора «выбор»:
выбор
при <условие 1>: <действие 1>;
при < условие 2>: <действие 2>;
……………………..
при < условие n-1>: <действие n-1>;
при < условие n>: <действие n>;
конец_выбора
так для рассмотренного ранее примера можно записать
выбор
при сумма_по_строке[i]<250000 и сумма_по_строке[i]>=100000 :
скидка[i]:= сумма_по_строке[i]*0.01;
сумма_скидки := сумма_скидки+ скидка[i];
при сумма_по_строке[i]<1000000 и сумма_по_строке[i]>=250000 :
скидка[i]:= сумма_по_строке[i]*0.025;
сумма_скидки := сумма_скидки+ скидка[i];
при сумма_по_строке[i]>=1000000 :
скидка[i]:= сумма_по_строке[i]*0.05;
сумма_скидки := сумма_скидки+ скидка[i];
конец_выбора;
Циклические вычисления в псевдокоде записываются тремя основными способами.
Циклы с фиксированным числом повторений
нц для <переменная>:=<начальное значение> до <конечное значение> шаг <величина шага> делать
<тело цикла>
кц;
Здесь нц и кц – начало и конец цикла, шаг – величина, на которую увеличивается переменная, а тело цикла – набор выполняемых инструкций. По умолчанию шаг считается равным 1. Ключевое слово делать означает, что все инструкции вплоть до окончания цикла, будут повторяться многократно.
Эту конструкцию можно проиллюстрировать фрагментом примера, рассмотренного выше
нц для i:=1 до количество_строк делать
сумма_счета:= сумма_счета + сумма_по_строке[i];
кц;
Рис.6.10 Фрагмент алгоритма, иллюстрирующий запись цикла с фиксированным числом повторений на псевдокоде
Циклы с предусловием обычно записываются следующим образом
нц пока <условие> делать
<тело цикла>
кц
а циклы с постусловием
нц делать
<тело цикла>
пока <условие>
кц
Различие между ними заключается в том, что в первом условие проверяется до выполнения инструкций тела цикла, а во втором после.
Практика показывает, что для автоматизации экономических расчетов необходимо большое количество разнообразных прикладных программам, входящих в состав информационных систем. Поэтому создается и постоянно совершенствуется технология разработки программ, под которой понимается совокупность методов и инструментальных средств, предназначенных для разработки, отладки, тестирования программных продуктов, а также создания соответствующей документации.
В настоящее время наибольшее распространение получили технологии так называемого процедурного программирования, которые реализуются с помощью языков программирования FORTRAN, Pascal, Си и многих других. Они в наибольшей степени приспособлены для традиционной компьютерной архитектуры, основанной на схеме фон Неймана.
Программа на процедурном языке состоит из последовательности операторов, пошагово реализующих решение задачи. Например, оператор присваивания изменяет содержимое памяти, оператор условного перехода направляет вычислительный процесс по той или иной ветви алгоритма и т.д. Выполнение программы означает последовательное исполнение операторов, преобразующих исходное состояние памяти в требуемый результат.
Существуют различные технологии программирования, реализуемые, как правило, последовательным выполнением следующих этапов:
- анализ и постановка задач;
- проектирование - разработка спецификаций;
- проектирование – разработка алгоритмов;
- написание исходных текстов программ и их трансляция;
- тестирование и отладка программ;
- испытания и сдача программ;
- сопровождение программ.
Из них наиболее трудоемким является написание исходных текстов программы, а также их тестирование и отладка. Кратко рассмотрим содержание перечисленных этапов создания программного продукта.
Анализ и постановка задач
На данном этапе осуществляется определение целей, которые достигаются при решении задачи и условий, необходимых для их достижения. При этом выполняется анализ обрабатываемой информации, определяются формы выдачи результатов, производится описание используемых данных - их типов, структуры, диапазонов изменения величин, и т. п. Результат этого этапа оформляется в виде технического задания на разработку.
Разработка спецификаций.
На данном этапе выполняется создание законченного описания поведения разрабатываемой программы. Оно включает пользовательский сценарий – все возможные варианты взаимодействия между пользователями и программным продуктом. Тем самым определяются функциональные требования к нему.
Кроме того спецификации содержит и нефункциональные требования. Например, ограничения связанные с дизайном, производительностью, выбранными проектными решениями и т.д. Разработка спецификаций должна производиться в соответствии с существующими стандартами, в которых содержатся рекомендации к структуре и методам описания требований к программным продуктам. Хорошо выполненная спецификация позволяет на этапе написания текстов программ одновременно и эффективно работать целой команде программистов независимо друг от друга, тем самым, обеспечивая сокращение сроков работ.
Разработка алгоритмов
Для того чтобы получить решение поставленной задачи, необходимо составить соответствующий алгоритм – полное, однозначное и исчерпывающее описание последовательности действий, предназначенных для достижения поставленной цели. На этом этапе выбираются методы проектирования алгоритма, формы его записи (смотри предыдущий параграф), требуемые тесты и правила проверки алгоритма. Методы проектирования алгоритмов могут различными: нисходящее или восходящее проектирование, использование принципа модульности и/или структурного программирования (см. выше).
Широко используются структурные принципы алгоритмизации, когда алгоритмы формируются из базовых алгоритмических конструкций, таких как следование, ветвление, повторение. Их последовательное применение и вложение друг в друга с соблюдением определённых правил, позволяет решить практически любую поставленную задачу. При структурированной разработке алгоритмов правильность алгоритма можно проследить на каждом этапе его построения и выполнения.
На структурном подходе основан модульный метод проектирования и разработки алгоритмов. Модуль – это некоторый алгоритм или его блок, имеющий конкретное наименование, выполняющий определенную функцию и имеющий стандартный вход и выход. Модуль должен обладать свойством структурной замкнутости и функциональной определенности. Структурная замкнутость означает независимость структуры программы от конструкции отдельного модуля. Функциональная определенность состоит в том, что модуль выполняет функции, свойственные ему одному.
При использовании модулей достигается:
- функциональная целостность и завершенность, так как каждый модуль реализует только одну функцию;
- автономность и независимость от других модулей;
- эволюционируемость, то есть отдельный модуль может быть модернизирован независимо от остального алгоритма;
- открытость перед другими пользователями и разработчиками для модернизации и использования;
- корректность и надежность, так как исполнение модуля возможно только единственным образом (у него есть только одна точка входа).
Преимущества модульного проектирования алгоритмов заключается в том, что:
- разработка алгоритма большого объема может производиться различными исполнителями;
- создается библиотека наиболее часто используемых алгоритмов;
- облегчается тестирование алгоритмов и обоснование их правильности;
- упрощается проектирование и модификация алгоритмов;
- уменьшается сложность разработки алгоритмов и программных комплексов;
- повышается наблюдаемость вычислительного процесса (то есть, по результатам проведенных отдельных вычислений становится легче понять общее состояние системы) при реализации алгоритмов.
Тестирование алгоритмов
Это проверка правильности работы алгоритма на специально заданных тестовых примерах – задачах с известными входными данными и соответствующими им результатами. Набор тестовых данных должен быть с одной стороны минимальным, а с другой стороны достаточно полным. Он должен обеспечивать максимально проверку для каждого типа наборов входных данных. Однако, тестирование сложных алгоритмов не всегда дает полную гарантию правильности.
Гарантию правильности дает лишь описание его работы и полученных результатов с помощью системы аксиом и правил вывода – то есть верификация алгоритма, что является достаточно сложной задачей.
Технологии программирования (модульное, структурное, объектно-ориентированное)
Технологии прграммирования реализуются с помощью систем программирования, под которыми понимается комплекс средств, предназначенный для создания и эксплуатации программ на конкретном языке программирования. Система программирования включает:
входной язык программирования;
редактор для написания и модификации текстов программ на алгоритмическом языке;
транслятор с входного языка на язык машины;
редактор связи;
библиотеку стандартных подпрограмм;
средства отладки.
Различные классы задач имеют свою специфику, и поэтому для своего решения требуют учета их особенностей, что достигается выбором соответствующего стиля и технологии программирования. Сегодня наиболее популярными являются следующие стили программирования:
а). Структурное.
b). Модульное.
c). Объектно-ориентированное.
d). Case – технологии (Computer-aided software engineering).
e). Функциональное.
f). Логическое.
g). Интернет-программирование (web-программирование).
а).Структурное программирование
В основе структурного программирования лежит представление программы в виде иерархической структуры блоков (фрагментов программы). Компьютерная программа, в этом случае состоит из базовых конструкций: последовательного исполнения, ветвления и циклов, которые были рассмотрены в предыдущем параграфе. Их количество и последовательность определяется решаемой задачей.
Базовые конструкции могут вкладываться друг в друга произвольным образом. Других средств управления последовательностью выполнения операций при структурном программировании не допускаются. Все элементы программ должны представлять собой логически целостные вычислительные блоки.
Базовые элементы программы оформляются как подпрограммы - процедуры или функции. В тексте основной программы, используется инструкция вызова требуемой подпрограммы. После ее исполнения, программа продолжает работу со следующей инструкции.
Разработка программы ведётся пошагово, методом «сверху вниз». Сначала пишется текст основной программы, в котором, вместо каждого связного логического фрагмента текста, вставляется вызов подпрограммы, которая будет выполнять этот фрагмент.
На начальном этапе разработки реальные, работающие подпрограммы, заменяются на так называемые «заглушки», которые какое-то время могут быть «пустыми», то есть не выполнять каких-то действий. Именно с ними программа верхнего уровня проверяется и отлаживается.
Если будет получена правильная последовательность вызова программных модулей, то это означает, что общая структура программы верна. После этого, подпрограммы-заглушки последовательно заменяются на реально работающие подпрограммы. Разработка каждой из них ведётся тем же методом, что при создании основной программы. Разработка заканчивается тогда, когда не останется ни одной «заглушки», которая не была бы удалена, что представляется следующим текстом:
Такая последовательность создания программного продукта гарантирует, что на каждом этапе разработки программист имеет дело с обозримым и понятным ему множеством фрагментов программного кода. Тем самым повышается уверенность, что общая структура всех более высоких уровней программы верна.
При сопровождении и внесении изменений в программу выясняют, в какие именно процедуры нужно внести изменения, которые не затрагивают иные части программы. Это повышает гарантии того, что при внесении изменений и исправлении ошибок не выйдет из строя какая-то часть программы, находящаяся в данный момент вне зоны внимания программиста.
Структурное программирование иначе называют еще программированием без операторов безусловного перехода (GOTO). Неправильное, необдуманное, произвольное использование которых приводит к получению запутанных, плохо структурированных программ, которые практически невозможно понять.
Структурное программирование сделало тексты программ читабельными. Облегчилось их понимание, стало возможным разработка программ в промышленном режиме, когда программу может без особых затруднений понять не только её автор, но и другие программисты. Это позволяет разрабатывать и сопровождать крупные программные комплексы силами больших коллективов разработчиков, даже в условиях изменений в составе персонала. Следует отметить, что многие языки, например Pascal, специально ориентированы на структурное программирование.
b). Модульное программирование
Модульное программирование является фундаментом многих используемых сегодня технологий программирования, базирующихся на самодостаточных кодовых модулях. Им не требуется внешняя поддержка, поэтому, как правило, они могут работать на различных аппаратных платформах и под различными операционными системами. Любую часть логической структуры модульной программы можно изменить, не вызывая изменений в остальных частях программы.
Модуль характеризуются тем, что:
- на входе программный модуль получает определенный набор исходных данных, выполняет их содержательную обработку и возвращает один набор результатных данных;
- модуль в состоянии выполнить все предписанные ему операции (функциональная завершенность);
- результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей (логическая независимость);
- обмен информацией между модулями должен быть по возможности минимизирован;
- модуль должен быть обозримого размера и сложности.
Модульный подход обладает рядом неоспоримых преимуществ, однако, он накладывает определенные ограничения на программиста и требует аккуратности на этапе проектирования. Модульное программирование поддерживается многими алгоритмическими языками, начиная от Модула, который был одним из первых языков этого класса, и кончая развитием идей модульности в языках Модула-2, Аda-95 и др..
с). Объектно-ориентированное программирование.
Очевидно, что при создании программного продукта должны быть заранее известны состав и структура входных и выходных данных. Внутренние (рабочие) данные определяются уже в процессе проектирования и разработки программного продукта. В задачах связанных с экономической сферой, в отличии от вычислительных задач, проектирование структур данных является отдельной проблемой и удачное ее решение определяет эффективность созданной программы.
Любая модификация структур внутренних данных неизбежно приводит к изменению алгоритмов обработки и, следовательно, к изменению текстов программ. Такое изменение может быть вызвано уточнением постановки задачи, сменой объектов предметной области, которые эти данные описывают. Это влечет коррекцию структур данных, алгоритмов и в конце счете текстов программных модулей.
Объединение специфических понятий языков программирования высокого уровня, таких как - тип данных, процедура, функция, запись и относящихся к одному определенному объекту алгоритма, заложило основу для возникновения объектно-ориентированного программирования. Его специфика заключается в рассмотрении данных в неразрывной связи с методами их обработки, что позволяет условно записать следующее:
Объект = Данные + Операции
Такой подход позволяет программировать не вдаваясь в отработку деталей программ, которые могут уточняться в процессе реализации программного продукта. Объектно-ориентированное программирование представляет следующие преимущества:
удобный и простой способ введения новых понятий, наиболее близких к понятиям реального мира;
простая разработка компонент многократного применения;
легкая модифицируемость (адаптируемость) программ;
локализация свойств и поведения объектов в одном месте.
Каждый объект характеризуется состоянием (свойства объекта) и возможностью выполнять некоторые действия (методы объекта). Например, для объекта «Накладная» это могут быть переменные, в том числе структуры данных, в которых хранятся значения реквизитов документа, внешний вид документа, значения строк и т.д. Для выполнения требуемых действий обращаются (вызывают) к методам объекта, например, печать, вывод на экран, добавление строки и т.п.
Если изменится объект реального мира – документ «Накладная», то в программе надо будет только в одном месте внести изменения в виртуальный объект, либо создать новую разновидность объекта, учитывающую эти изменения. Таким образом, ООП позволяет создавать программы «более близкие» к реальному миру и легко адаптирующиеся к изменениям.
Каждый объект в ООП всегда принадлежит некоторому классу.
Класс объектов — это обобщенное (абстрактное) описание множества однотипных объектов. Объекты являются конкретными представителями своего класса, их принято называть экземплярами класса. Например, класс КОШКИ - понятие абстрактное, а экземпляр этого класса МОЙ КОТ ФИЛЯ - понятие конкретное. Основными понятиями ООП можно считать – абстрагирование инкапсуляцию, наследование и полиморфизм.
Абстрагирование – это выделение только значимые характеристики объекта.
Инкапсуляция – это объединение данных и методов, работающих с объектом, в некий класс и скрывающий детали его реализации от пользователя. Инкапсуляция делает объекты похожими на маленькие программные модули, у которых имеется интерфейс использования в виде подпрограмм. Переход от понятий "структура данных" и "алгоритм" к понятию "объект" значительно повысил ясность и надежность программ.
Наследование – это свойство системы, позволяющее описать новый класс объектов на основе уже существующего. При этом частично или полностью заимствуются его функции. Класс, от которого производится наследование, называется базовым или родительским. Новый класс – потомком, наследником или производным классом.
Полиморфизм – это свойство системы использовать объекты с одинаковым интерфейсом без информации об его типе и внутренней структуре. Это означает, что в производных классах можно изменять работу уже существующих в базовом классе методов. При этом весь программный код, управляющий объектами родительского класса, пригоден для управления объектами дочернего класса без всякой модификации.
Объектно – ориентированное программирование обычно используется при разработке крупных программных комплексов коллективом программистов. Проектирование системы в целом, создание отдельных компонент и их объединение в конечный продукт в этом случае часто выполняется разными людьми. Языками, поддерживающими данную технологию являются: C++, Java, Delphi и многие другие.
d). Case – технологии (Computer-aided software engineering)
Современные CASE- средства охватывают широкую область поддержки многочисленных технологий проектирования информационных систем (ИС): от простых средств анализа и документирования до средств автоматизации всего жизненного цикла программного обеспечения. CASE-средства – это программные средства, поддерживающие процессы создания и сопровождения ИС, включая анализ и формулировку требований, проектирование прикладного ПО (приложений) и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом. CASE-средства вместе с системным ПО и техническими средствами образуют полную среду разработки ИС. Их компонентный состав включает:
графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически связанных диаграмм, образующих модели ИС;
библиотеку стандартных программных модулей;
репозиторий;
средства разработки приложений, включая языки 4GL и генераторы кодов;
средства конфигурирования пакета;
средства документирования;
средства тестирования;
средства управления проектом;
средства реинжениринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций.
Современный рынок программных средств насчитывает около 300 различных CASE-программ, которые активно используются ведущими западными фирмами. На Российском рынке CASE-средств наиболее известными пакетами являются: Vantage Team Builder (Westmount I-CASE), Designer/2000, Erwin+Bpwin, CASE-аналитик, System Architect,Visible Analyst Workbench, EasyCASE.
В современных CASE-пакетах используются практически все известные методологии проектирования. CASE-технология - это не только методология, но и инструментарий. Сейчас на рынке существует большое количество CASE-пакетов. Например, построитель мета-моделей данных CA ERwin Data Modeler, который позволяет проводить их описание, анализ и моделирование.
Он включает в себя три стандартные методологии: IDEF0 (функциональное моделирование), DFD (моделирование потоков данных) и IDEF3 (моделирование потоков работ).
e). Функциональное программирование
Обычные традиционные (императивные) языки высокого уровня, такие как Pascal, Cи, Ada и др. последовательно выполняют инструкции (операторы) программы и результаты размещаются в памяти.
В парадигме функционального программирования основным понятием является функция. Известно, что математические функции выражают связь между исходными данными и результатом. Процесс вычисления также имеет вход и выход, поэтому функция вполне может использоваться для описания вычислений.
Функциональная программа представляет собой набор определений функций. Функции определяются через другие функции или рекурсивно через самих себя. При выполнении программы функции получают параметры, вычисляют и возвращают результат, при необходимости вычисляя значения других функций.
На функциональном языке программист не должен описывать порядок вычислений. Нужно просто описать желаемый результат как систему функций. Функциональное программирование, нашло большое применение в теории искусственного интеллекта и её приложениях. К его основным особенностям можно отнести краткость и простоту, строгую типизацию, модульность, отсутствие (как правило) побочных эффектов.
Программы на функциональных языках обычно короче и проще, чем те же самые программы, написанные в других система программирования. Кроме этого, функциональные языки программирования лучше приспособлены к организации параллельных вычислений. Раз все функции для вычислений используют только свои параметры, можно вычислять независимые функции в произвольном порядке или параллельно, на результат вычислений это не повлияет.
Следует отметить, что в традиционных языках программирования (например, Си++) вызов функции приводит к вычислению всех аргументов. Этот метод вызова функции называется «вызов по значению». Если какой-либо аргумент не использовался в функции, то результат вычислений пропадает, следовательно, вычисления были произведены впустую. В каком-то смысле противоположностью «вызова по значению» является «вызов по необходимости», который используется в функциональных языках программирования. В этом случае аргумент вычисляется, только если он нужен для получения результата.
В функциональном программировании широко используется понятие рекурсии, способа общего определения множества объектов или функций через эти же функции и объекты, с использованием ранее заданных частных определений.
Понятие функционального программирования часто связывают с языком Lisp (от английского сокращения LISt Processing language - «язык обработки списков») В настоящее время известно множество его реализаций. Например, Common Lisp стандартизованный диалект языка Lisp. Он был разработан с целью объединения разрозненных его диалектов.
Common Lisp - мультипарадигменный (то есть, поддерживающий несколько парадигм) язык программирования общего назначения. Он поддерживает комбинацию процедурного, функционального и объектно-ориентированного программирования. Его используют в самых разных проектах – в интернет-серверах, серверах приложений, в клиентах взаимодействующих с реляционными и объектными базами данных, в научных расчётах и игровых программах.
f). Логическое программирование
Согласно логическому подходу к программированию, программа представляет собой совокупность правил или логических высказываний. Также в ней допустимы логические причинно-следственные связи, в частности, на основе операции импликации (импликация, от латинского « implicatio» - сплетение, тесно связываю, логическая связка, соответствующая грамматической конструкции если ..., то).
В логическом программирование программы пишутся не в виде последовательности инструкций, а в виде множества фактов и правил. Процесс выполнения программы состоит в выводе нужных результатов из этого множества. Логическое программирование относится к декларативному программированию, поскольку программа на нём скорее описывает свойство задачи, нежели алгоритм её решения. Основано оно на автоматическом доказательстве теорем, и на теории и аппарате математической логики с использованием математических принципов резолюций.
Языки логического программирования позволяют выполнить описание проблемы в терминах фактов и логических формул, а собственно решение проблемы выполняет система с помощью механизмов логического вывода. Самым известным языком логического программирования является Prolog, со всеми своими многочисленными диалектами (такими как - Arity Prolog, B-Prolog, Ciao Prolog, Arity/Prolog32, CxProlog/ IF/Prolog, JIProlog и др.).
Они широко используются для создания баз знаний и экспертных систем и исследований в сфере искусственного интеллекта. На его основе создаются логические модели баз знаний и логические процедуры вывода и принятия решений.
Следует отметить также Visual Prolog, который использует «визуальное программирование». Разработка программ в нем производится специальными графическими средствами без традиционного программирования на алгоритмическом языке. В результате эта система программирования, отличается логичностью, простотой и эффективностью.
g). Интернет-программирование (web-программирование)
Раздел программирования, в рамках которого создаются программы интернет-приложений, реализующие разнообразные интернет-технологии называются интернет - программированием. Программы интернет-приложений называются скриптами. Существует две основные категории скриптов – клиентские, то есть выполняемые на компьютере пользователя и серверные, предназначенные для использования на интернет-сервере.
Как правило, клиентские скрипты исполняются с помощью браузеров, специальных программ, с помощью которых просматриваются интернет-страницы. Эти скрипты представляют собой некие команды на специализированном языке программирования, которые заключаются среди общего кода web-сайта. Самыми распространенными клиентскими языками программирования являются JavaScript, VBScript, ActionScript и Java.
Примерами серверных скриптов могут служить «стандартные» программы, которые используются на интернет-страницах: счетчики посещаемости сайта, программы на сервере, поддерживающие голосование и гостевые книги на сайте и так далее. Важной стороной работы серверных скриптов – возможность с их помощью организации взаимодействия с системой управления базами данных имеющихся на сервере. При написании серверных скриптов используются языки Perl, ASP, WebSQL и Java Server Pages.
Дальнейшее развитие технологий создания программного обеспечения чрезвычайно важно, так как оно является составной частью современных информационных технологий. Их совершенствование особенно важно при создании таких новых систем, как облачные вычисления, новые поколения мультимедийных поисковых систем, аналитическое программное обеспечение, технологии передачи и хранения информации, 3d-моделирования и много другого, без чего невозможно решение задач экономики.
Методы и этапы решения экономических задач на компьютере
Имея алгоритм решения задачи можно переходить к его записи на языке программирования. Один и тот же алгоритм может быть реализован на различных языках. Выбор языка программирования, кодирование на нем, уточнение в процессе написания программ способов организации данных – это отдельная, самостоятельная и достаточно сложная задача.
Существует несколько подходов к классификации алгоритмических языков. Первая из них отталкивается от уровня языка. Чем он выше – тем ближе алгоритмический язык к живому человеческому, как правило, английскому языку. Чем ниже уровень языка – тем он ближе к тому, что используется для кодирования команд при аппаратной реализации вычислительного устройства.
Здесь определяющим является тип решаемой задачи. Для сложных задач, оперирующих достаточно абстрактными понятиями, следует выбирать языки высокого уровня. Экономические задачи, как правило, относятся к этой категории. Для задач, тяготеющих к реализации алгоритмов управления конкретными устройствами (так называемое «приборное программирование») выбирают языки более низкого уровня.
Большое значение имеет тип решаемой задачи. Представляется совершенно естественным, что при создании программного продукта для работы, например, с базами данных следует выбирать специализированный язык высокого уровня, предназначенный именно для этих целей. Разработка интеллектуальных информационных систем потребует применить языки, поддерживающие логическое или функциональное программирование. Писать программные приложения для работы в сети Интернет следует на языке, подходящем для этих целей.
После выбора языка для создания программного продукта, производится непосредственно кодирование алгоритмов. Сначала определяются переменные - именованные области памяти, по имени которых можно получить доступ к данным. Далее программисты описывают разработанные ранее алгоритмы с помощью выбранного языка программирования в соответствии с диктуемыми им правилами.
Важными моментом является то, что при написании следует уделять повышенное внимание комментариям к программе на «человеческом» языке, разъясняющим смысл написанного кода. Это позволяет лучше понять написанное другому программисту и, даже, быстрее вспомнить его автору программы через некоторое время.
В результате получаются текстовые исходные файлы.
Для того, чтобы программа, написанная на языке высокого уровня могла бы быть исполнена, текст ее, необходимо подвергнуть трансляции – переводу ее конструкций в вид, позволяющий исполнять их на компьютере. Он осуществляется с помощью специализированных программ – трансляторов.
Существует два подхода в трансляции:
– перевод отдельного оператора программы и немедленное ее исполнение программой-интерпретатором, что называется интерпретацией;
- перевод всей программу полностью в исполняемый код, после чего становится возможным ее выполнение программой компилятором.
Для одного и того же языка программирования могут быть написаны как интерпретаторы, так и компиляторы. Обычно считается, что интерпретаторы несколько проще для создания, но программы с их помощью выполняются медленнее.
При компилировании исходная программа первоначально преобразуется в некую промежуточную форму, называемую объектным кодом (объектным модулем). Затем производится компоновка программы - то есть увязка всех ее частей и получение исполняемого (загрузочного) модуля, пригодного для запуска на компьютере. Компоновка производится с помощью специальной программы, называемой компоновщиком.
Если в программе используются стандартные функции, например, sin, exp и т.д., соответствующие им программные модули выбираются из библиотеки используемой системы программирования и вставляются в объектный модуль при компоновке. Тогда же сам объектный модуль преобразуется в соответствии с реальными адресами основной памяти, куда и будет размещаться программа для выполнения.
Процесс компиляции состоит из двух основных этапов − анализа и синтеза (рис. 6.24). На первом этапе производится разбор исходного текста программы. То есть распознаются отдельные конструкции алгоритмического языка, использованные в программе, затем создаются и заполняются таблицы идентификаторов (переменных). Результатом анализа становится некое внутреннее представление программы, понятное компилятору.
Далее, на этапе синтеза из этого внутреннего представления программы и информации из таблицы идентификаторов, генерируется результирующая объектная программа.
Компилятор производит анализ исходного текста программы на наличие синтаксических ошибок. При их обнаружении он выдает соответствующую информацию о допущенных ошибках.
Процесс компиляции состоит из следующих основных этапов

Рис. 6.24. Схема компиляция программ
Лексический анализ. Компилятор читает символы программы на исходном языке и строит из них слова (лексемы) исходного алгоритмического языка. В результате его работы получается информация пригодная для синтаксического разбора.
Синтаксический разбор − в тексте исходной программы выделяются синтаксические конструкции, и проверяется синтаксическая правильность программы (отсутствие синтаксических ошибок).
Семантический анализ − проверяется текст исходной программы с точки зрения семантики (смысла) входного языка.
Подготовка к генерации кода – выполняются некие предварительные действия, такие как - идентификация элементов языка, распределение памяти и т.п.
Генерация кода – на этом этапе порождается текст результирующей программы.
На рис.6.27 показаны также таблицы идентификаторов, в которых специальным образом организованные наборы данных, хранящие информацию об элементах исходной программы. Содержимое таблицы идентификаторов используется для порождения текста результирующей программы. В процессе компиляции нужно хранить информацию о переменных, константах, функциях и т.п. Конкретный состав таблицы идентификаторов зависит от используемого входного языка программирования.
Порядок выполнения фаз компиляции различен в разных версиях компиляторов. В одних компиляторах просмотр текста исходной программы сопровождается выполнением всех фаз компиляции и получением результата − объектного кода. В других − над исходным текстом выполняются только некоторые фазы компиляции, и получается не конечный результат, а набор некоторых промежуточных данных, которые снова подвергаются обработке.
Интерпретатор - это программа, которая воспринимает текст исполняемой программы на исходном высокого языке уровня и сразу же выполняет её. Следует отметить, что не все языки программирования это допускают. В интерпретаторах отсутствует оптимизация, поэтому выполнение программы менее эффективно, чем с помощью аналогичного компилятора и, следовательно, они уступают компиляторам в производительности.
Преимуществом интерпретаторов является независимость выполнения программы от архитектуры вычислительной системы. При переходе на другую архитектуру при использовании компилятора требуется откомпилировать программу заново, т.к. объектный код всегда ориентируется на определенную архитектуру.
Многие языки программирования, которые используются в сети Интернет, предусматривают механизм интерпретации исходного текста программы вместо компиляции. Например, HTML (Hypertext Markup Language) язык описания гипертекста. положен в основу функционирования большинства структур сети Интернет. Языки Java и Java Script сочетают функции компиляции и интерпретации. На первом этапе исходная программа в них компилируется в некоторый двоичный код, который является промежуточным и не зависит от архитектуры целевого компьютера. Этот код передается по сети и выполняется принимающим компьютером в виде интерпретации.
Тестирование и отладка программ
Основная цель тестирования – проверить, отвечает ли разработанная система исходным спецификациям. Разработку тестовых данных и программы испытаний рекомендуется выполнять параллельно с этапами проектирования и программирования.
Важнейший этап в технологии создания программного продукта – это отладка. Ее цель в проверке синтаксической и логической правильности программы, в определении того, что она нормально функционирует на всем требуемом диапазоне входных данных. Во время отладки обнаруживают, локализуют и устраняют имеющиеся в программе ошибки.
На начальном этапе отладки выявляются синтаксические ошибки. Транслятор проверяет правильность написания формальных конструкций, таких как соответствие количества открытых и закрытых скобок в тексте, правильность написания операторов языка программирования, правильность задания переменных в программе и тому подобное. Как правило, эти ошибки возникают из-за небрежности и невнимательности программистов. Указание на них выводятся в специальный файл листинга транслятора.
После устранения синтаксических ошибок приступают к основной части отладки. Чтобы понять, где возникла ошибка, необходимо знать текущие значения переменных и тот путь (ту ветвь алгоритма) по какому выполнялась программа. Искусство тестирования программ состоит в том, чтобы создать по возможности полную систему тестов, проверяющую все возможные ветви вычислений.
Существуют различные технологии отладки. Например, с использованием специализированных программ отладчиков, которые визуализируют результаты пошагового выполнения программы в различных режимах. То есть, можно проследить переменные при поочередном выполнении операторов или функций (модулей алгоритма). Отладчики дают возможность производить остановку выполнения на заданных строках исходного кода программы или при достижении определённого условия. Другой распространенный прием заключается в выводе текущего состояния переменных в критических точках программы.
Процесс отладки заключается в том, что производятся запуски программы на различных наборах тестовых данных. Программист, осуществляющий отладку, должен иметь контрольный результат (полученный заранее) для каждого набора тестовых данных и сверять с ним работу проверяемой программы.
В случае расхождения между контрольным и фактическим результатами, выясняют проблемный участок алгоритма и выявляют допущенные ошибки. Анализ результатов тестирования используется для подготовки предложений по совершенствованию и оптимизации программного продукта.
К сожалению, отладка не может гарантировать, что программа абсолютно корректна, даже если все тесты прошли успешно. Отладка может доказать некорректность программы, но она не может доказать ее правильности. Особенность отладки заключается еще и в том, что после исправления одиночной ошибки процесс тестирования начинается практически заново, так как требуется проверить работу ранее использованных тестов.
Очень часто отладчик, компоновщик, компилятор и редактор, предназначенный для ввода исходных текстов программ, объединяют в интегрированную среду программирования. Такой подход очень удобен, так как позволяет осуществлять весь цикл разработки программного модуля, от написания исходного текста до отладки.
Испытание и сдача программ
После завершения отладки программа передается в опытную эксплуатацию к заказчику. Во время нее проверяется соответствие программы требованиям технического задания, производится обучение персонала работающего с ней. При необходимости производится доработка программного продукта. Далее следует подготовка документации, требуемой стандартами для эксплуатации программного продукта. После чего подписывается акт о сдаче программного продукта в промышленную эксплуатацию (программный продукт поступает в продажу) и производится его тиражирование.
Сопровождение программ
Работа с программным продуктом не заканчивается после начала эксплуатации. После ее сдачи начинается этап сопровождения, в ходе которого устраняются обнаруживаемые пользователями ошибки. В реальной практике на этом этапе происходит уточнение первоначальных требований, формулировка новых.
Если же программный продукт тиражируется, то дополнительно требуется обучение работы с ним потребителей. Поэтому необходимо иметь организационную структуру (отдел, фирму и т.п.), которая будет оперативно решать подобные задачи.
Выше были рассмотрены этапы общей технологии создания программного продукта. Однако, имеются некоторые специализированные системы программирования, используемые при написании конкретных программ. В основном они касаются процесса кодирования, то есть описания алгоритма средствами языков программирования.
Информационные ресурсы и технологии для решения экономических задач на компьютере
Информационные ресурсы, их классификация и содержание
По мере перехода от индустриальной эпохи к постиндустриальной значимость отдельных факторов производства поменялась. От экономики, основной чертой которой была фирма, общество идет к экономике, основой которой становится информационная сеть. В результате произошло смещение в интенсивности использования различных ресурсов.
Современное производственное предприятие, организация, офис в процессе своего функционирования потребляет следующие ресурсы:
трудовые;
материальные;
финансовые;
ресурсы для обеспечения безопасности;
информационные (интеллектуальные).
Все ресурсы, за исключением последних, являются традиционными. Их характерная черта – ограниченность (одноразовость) в использовании. В отличие от них информационные ресурсы являются многоразовыми, не подлежащими физической амортизации.
Так как традиционных ресурсов на планете становиться все меньше и цена на них растет, поэтому сегодня важнейшая проблема любой фирмы, любого производства заключается в сокращении их потребления, то есть сокращении зависимости от них. Еще классик экономической мысли Вальрас более 150 лет тому назад предвидел общество, в котором основная доля цены на продукт будет связана с созданием большей части добавленной стоимости за счет знаний, то есть информационных ресурсов.
Сокращение потребления традиционных ресурсов за счет информационных демонстрируется с помощью условного примера на рис. 7.7, где используются следующие обозначения:
![]() ,
,
![]() ,
,![]() ,
,![]() -
объемы потребляемых материальных и
других традиционных ресурсов и
информационных ресурсов в периоды
времени
-
объемы потребляемых материальных и
других традиционных ресурсов и
информационных ресурсов в периоды
времени![]() и
и![]() ;
;
![]() ,
,
![]() ,
,![]() ,
,![]() -
объемы производимого товара
-
объемы производимого товара![]() ,
,![]() в периоды времени
в периоды времени![]() и
и![]() .
.

Рис. 7.7. Демонстрация замещения традиционных ресурсов информационными
Пусть,
при некотором объеме традиционных (![]() )
и информационного (
)
и информационного (![]() )
ресурсов в период времени
)
ресурсов в период времени![]() производятся товары в объемах
производятся товары в объемах![]() и
и![]() .
Пусть далее в последующий период
.
Пусть далее в последующий период![]() необходимо увеличить на некоторую
величину
необходимо увеличить на некоторую
величину![]() объем
производимого товара
объем
производимого товара![]() при условии соблюдения равенства
потребляемых ресурсов. Достичь это
можно лишь за счет соответствующего
сокращения объема производства другого
– товара
при условии соблюдения равенства
потребляемых ресурсов. Достичь это
можно лишь за счет соответствующего
сокращения объема производства другого
– товара![]() .
Но если необходимо сохранить его объем
производства при некотором увеличении
традиционных
ресурсов, то достичь этого можно только
за счет привлечения большего объема
информационных ресурсов (новых знаний
в области производственных, торговых,
логистических, финансовых, оптимизационных
и других технологий, организации труда,
материалов и т д.).
.
Но если необходимо сохранить его объем
производства при некотором увеличении
традиционных
ресурсов, то достичь этого можно только
за счет привлечения большего объема
информационных ресурсов (новых знаний
в области производственных, торговых,
логистических, финансовых, оптимизационных
и других технологий, организации труда,
материалов и т д.).
В процессе развития сетевой экономики выясняется, что нарушается один из экономических законов - закон убывающей доходности, который П. Самуэсоном, сформулирован следующим образом: "увеличение некоторых затрат по отношению к другим неизменным затратам приводит к увеличению общего количества продукции. Но после определенного момента дополнительная продукция получаемая от прибавления тех же самых дополнительных затрат, по всей видимости, будет становиться все меньше и меньше" [31 с. 23]. Тогда фирма, стремясь стабилизировать рентабельность, вводит ограничения на объем выпуска, уменьшая капиталовложения на столько, чтобы прибыль была на среднем уровне.
В информационной сфере знания не испытывают перенасыщения, скорее наоборот – действует закон возрастающей доходности. Вложив в знания (исследования, ОКР) один раз значительные средства и получив результат производитель получает экономию по переменной затрат, поскольку сложная продукция отличается высокой стоимостью изготовления, но относительно низкой стоимостью при тиражировании. Сделав единовременные затраты производитель получает возрастающий все доход. Иллюстрация поведения затрат приведена на рис. 7.8.

Рис. 7.8. Иллюстрация законов убывающей и возрастающей предельной доходности для различных ресурсов
Если раньше целевой программой любого производства было стремление к увеличению количества материальных благ за счет увеличения материальных ресурсов, то сегодня это возможно лишь за счет уменьшения зависимости от материальных ресурсов, то есть за счет их более интенсивного использования: знаний новых технологий, новых материалов, новых методов управления, конъюнктуры рынка, тенденций валют, новых организационных приемов и т.д. В ближайшей, а особенно в отдаленной перспективе основными источниками богатства для большей части населения будут не природные ресурсы, а знания и коммуникации (Стюарт Т. Богатство от ума. Мн. Парадок, 1998).
Далее под информационными ресурсами будет пониматься информация, зафиксированная на материальном носителе и хранящаяся в информационных системах предприятий, организаций, библиотек, архивов, фондов и т.д. в виде баз данных, баз знаний, файлов, отдельных документов.