

LEC02
.pdf#pragma omp for: конфликты (2)
Если в теле цикла потоки меняют значение общей переменной, то возможно искажение данных в этой переменной при одновременной попытке записи.
Ответственность за обнаружение таких конфликтов лежит на программисте. OpenMP не обнаружит конфликт и скомпилирует следующую ошибочную программу:
s = 0;
#pragma omp parallel for num_threads(2) shared(a, s) private(i) for (i = 0; i < 20; i++) {
a[i] = i;
s = s + a[i] ;
}
Массив a заполнится корректно, однако его сумма s будет рассчитана ошибочно, если на какой-либо из итераций поток 0 и поток 1 попытаются модифицировать s одновременно.
21
Защита общих переменных
Если в теле цикла потоки меняют значение общей переменной, то операцию присвоения следует защитить от одновременного изменения.
s= 0;
#pragma omp parallel for num_threads(2) shared(a, s) private(i) for(i = 0; i < 20; i++) {
a[i] = i;
#pragma omp critical s = s + a[i] ;
}
В результате s будет подсчитано корректно, т.к. операция присвоения выполнится не параллельно всеми потоками, а последовательно. Это позволяет решить конфликт между потоками, но негативно повлияет на параллельное ускорение, т.к. соответствующая часть инструкций цикла принудительно помечена как нераспараллеливаемые.
22
#pragma omp atomic
Защита операции присвоения общих переменных возможна также с помощью более быстрой директивы atomic, которую можно использовать только для атомарных аппаратноускоряемых команд вида «load-modify-store», имеющих вид:
•x <операция>= <выражение>;
где <операция> может быть +, , −, /, &, ˆ, |, <<, >> ;
•x++;
•++x ;
•x−− ;
•−− x ;
Примеры:
#pragma omp atomic Counter += 10; #pragma omp atomic
Counter += a++; // ошибка: операция a++ не будет защищена 23
Параметр reduction
Если в теле цикла потоки меняют значение общей переменной, просто накапливая сумму, то возможно более эффективное устранение конфликта:
#pragma omp parallel for num_threads(2) shared(a, s) private(i) reduction(+:s) for(i = 0; i < 20; i++) {
a[i] = i;
s = s + a[i] ;
}
•В результате s будет подсчитано корректно, при этом операция модификации s будет выполняться потоками параллельно (одновременно), т.к. OpenMP создаст локальные копии s для каждого потока. По окончании цикла OpenMP сложит все локальные копии и поместит их в общую переменную s.
•Помимо операции +, параметр reduction умеет работать с другими операциями: -, *, /
•OpenMP самостоятельно инициализирует локальные переменные s значением 0 или 1 (в зависимости от операции), игнорируя начальное значение переменной s.
24
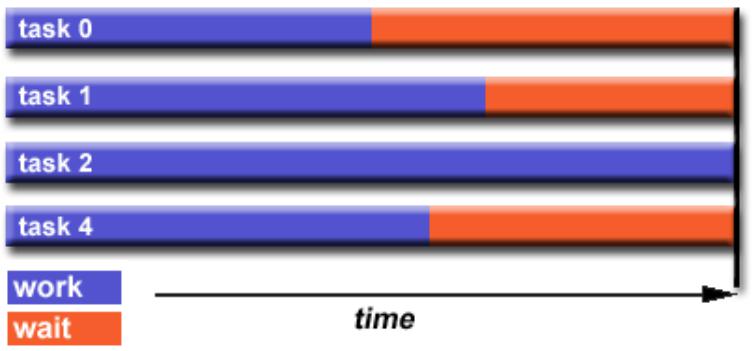
Проблема балансировки нагрузки
25
#pragma omp for schedule
•#pragma omp for schedule(static, chunk_size)
•#pragma omp for schedule(dynamic,chunk_size)
•#pragma omp for schedule(guided, chunk_size)
•#pragma omp for schedule(runtime)
(runtime подставляется из переменной среды окружения OMP_SCHEDULE)
#pragma omp parallel num_threads(8)
{
#pragma omp for schedule(dynamic,1) for (i = 0; i < 8; i++)
printf("[1] iter %d, tid %d\n", i, omp_get_thread_num()); #pragma omp for schedule(static,1)
for (i = 0; i < 8; i++)
printf("[2] iter %d, tid %d\n", i, omp_get_thread_num());
} |
26 |
|