

Неравномерное кодирование для последовательности сообщений
В этом параграфе мы перейдем к решению задачи кодирования последовательностей сообщений. Разумеется, если мы рассматриваем стационарный источник и его распределение вероятностей на буквах не меняется от буквы к букве, то любой из описанных выше способов кодирования может быть использован для кодирования отдельных сообщений источника. Во многих случаях именно такой подход используется на практике как самый простой и достаточно эффективный.
В то же время, можно выделить класс ситуаций, когда побуквенное кодирование заведомо неоптимально. Во-первых, из теоремы об энтропии на сообщение стационарного источника следует, что учет памяти источника потенциально может значительно повысить эффективность кодирования. Во-вторых, побуквенные методы затрачивают как минимум 1 бит на сообщение, тогда как энтропия на сообщения может быть значительно меньше 1.
Итак, рассмотрим последовательность x1, x2, …, xi X = {xi}, наблюдаемую на выходе дискретного стационарного источника, для которого известно вероятностное описание, т.е. можно вычислить все многомерные распределения вероятностей и по ним – энтропию H(x) = H(X).
Пусть указан
некоторый способ кодирования, который
для любых n
для каждой
последовательности
![]() на выходе источника строит кодовое
слово
на выходе источника строит кодовое
слово![]() длины
длины![]() .
Тогдасредняя
длина кода на сообщение, для блоков
длины n определяется
как
.
Тогдасредняя
длина кода на сообщение, для блоков
длины n определяется
как
![]() бит/сообщение
источника.
бит/сообщение
источника.
Подбирая длину блоков, при которой средняя длина кода будет наименьшей, получаем следующее определение для средней длины кода на сообщение
![]() .
.
(Мы пишем нижнюю грань inf вместо минимума, поскольку наименьшее значение скорости может достигаться в пределе при n ).
Рассматриваемое кодирование называется FV-кодированием (fixed-to-variable), поскольку блоки из фиксированного числа сообщений n кодируются кодовыми словами переменной длины. Наша задача – связать достижимые значения средней скорости FV-кодирования с характеристиками источника, в частности, с его энтропией H(x) . Начнем с обратной теоремы кодирования.
Теорема 12.6. Для дискретного стационарного источника с энтропией H(x) для любого FV-кодирования имеет место неравенство
![]() .
.
Прямая теорема кодирования.
Теорема 12.7. Для дискретного стационарного источника с энтропией H(x) и для любого > 0. существует способ неравномерного FV-кодирования такой, для которого
![]() .
.
Итак, выбрав достаточно большую длину блоков n и применив к блокам побуквенное кодирование, мы получим кодирование со средней скоростью
![]() ,
,
где o(n) 0 при n .
К сожалению, этот внешне оптимистический результат оказывается почти бесполезным при решении практических задач. Основное препятствие на пути его применения – это экспоненциальный рост сложности при увеличении длины блоков n. Поясним эту проблему следующим простым примером.
Предположим, что кодированию подлежат файлы, хранящиеся в памяти компьютера. Символы источника – байты и, значит, объем алфавита |X| = 28 = 256. При кодировании последовательностей длины n = 2 объем алфавита вырастает до |X2| = 216 = 65536. Далее при n = 3, 4, … объемы алфавита будут 224 = 16777216, 232 = 4294967296, …. Понятно, что работать с кодами таких размеров невозможно.
Описываемый в следующем параграфе метод арифметического кодирования позволяет эффективно кодировать блоки длины n с избыточностью порядка 2/n и со сложностью растущей только пропорционально квадрату длины блока n. За счет пренебрежимо малого проигрыша в средней длине кода на сообщение сложность может быть сделана даже линейной по длине кода. Неудивительно, что арифметическое кодирование все шире применяется в разнообразных системах обработки информации.
Арифметическое кодирование
При кодировании
кодом Шеннона-Фано и Хаффмана оптимальность
будет обеспечена только в том случае,
если вероятность появления кодируемых
символов кратна 2n,
n = -1,
-2, … При произвольном значении вероятности
появления символа
![]() условие оптимальности
условие оптимальности![]() не выполняется.
не выполняется.
Арифметическое
кодирование обеспечивает более точное
выполнение этого равенства при
произвольной величине
![]() .
.
Рассмотрим для
простоты дискретный постоянный источник,
выбирающий сообщения из множества
X = {1, …, N},
с вероятностями {P1,
…, PN}.
Наша задача состоит в кодировании
последовательностей множества
![]() .
.
Мы хотели бы
применить к ансамблю
![]() достаточно простой и эффективной
побуквенный код. Упрощение состоит в
том, ни кодер ни декодер не хранят и не
строят всего множества из|Xn|
кодовых
слов. Вместо этого при передаче конкретной
последовательности
достаточно простой и эффективной
побуквенный код. Упрощение состоит в
том, ни кодер ни декодер не хранят и не
строят всего множества из|Xn|
кодовых
слов. Вместо этого при передаче конкретной
последовательности
![]() кодером
вычисляется кодовое слово
кодером
вычисляется кодовое слово
![]() только для данной последовательности
только для данной последовательности
![]() .
Правило кодирования, конечно, известно
декодеру и он восстанавливает
.
Правило кодирования, конечно, известно
декодеру и он восстанавливает
![]() по
по
![]() ,
не имея полного списка кодовых слов.
,
не имея полного списка кодовых слов.
Идея арифметического
кодирования заключается в следующем.
Сообщения буквы в тексте встречаются
с определенными вероятностями
![]() при этом справедливо равенство
при этом справедливо равенство![]() .
.
Интервал 0…1 разбивается на подинтервалы с длинами, равными вероятностям появления символов в потоке, которые называются диапазонами соответствующих символов. Выбирается диапазон для первого символа (буквы), определяется его начало и конец. Появление следующих символов уменьшает ширину этого диапазона. В конце текста образуется достаточно узкий диапазон и число, выбранное из этого диапазона в двоичном коде будет определять передаваемую кодовую комбинацию.
Например, символы
“a”,
“b”,
“c”
в потоке встречаются с вероятностями
![]() ;
;![]() ;
;![]() .
Составим таблицу
.
Составим таблицу
|
Символ |
|
Диапазон символа |
|
“b” |
0,6 |
0,0…0,6 |
|
“c” |
0,3 |
0,6…0,9 |
|
“a” |
0,1 |
0,9…1,0 |
Допустим, что
необходимо закодировать текст “bcbab”.
Для первого символа рабочий диапазон
выбирается 0,0…0,6. Диапазон следующего
символа “c”
равен 0,6…0,9. В результате исходный
диапазон 0,0…0,6 сужается по следующему
правилу: начало нового диапазона
![]() равно началу исходного диапазона
равно началу исходного диапазона![]() плюс начало диапазона следующей буквы
плюс начало диапазона следующей буквы![]() ,
умноженное на разность конец исходного
диапазона
,
умноженное на разность конец исходного
диапазона![]() минус начало исходного диапазона
минус начало исходного диапазона![]()
![]() .
.
Конец нового диапазона определяется по правилу
![]()
Здесь
![]() -
конец диапазона буквы “c”.
-
конец диапазона буквы “c”.
С поступлением каждой последующей i-ой буквы начало и конец диапазона определяется по правилу
![]() ;
;
![]() .
.
В этом выражении
![]() и
и![]() соответственно начало и конец диапазона
передаваемой буквы “x”.
соответственно начало и конец диапазона
передаваемой буквы “x”.
Для приведенного примера после буквы “c” педается буква “b”.
Начало и конец следующего диапазона будут равны
![]() ;
;
![]() .
.
При передаче буквы “a” начало и конец диапазона равны
![]() ;
;
![]() .
.
Последняя буква текста “b” имеет начало и конец диапазона текста равные
![]() ;
;
![]() .
.
В этом диапазоне выбирается точка, значение которой определяется по формуле
![]() .
.
Графически процесс кодирования показан на рис. 12.0
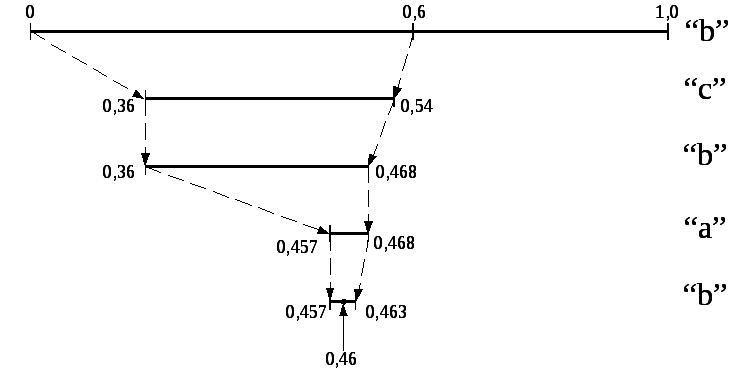
Рис.12.3 Графическая интерпретация арифметического кодирования
Двоичный код этого числа является кодовой комбинацией, обозначающей передаваемый текст.
Дробное число в двоичном коде записывается следующим образом:
![]() .
.
Количество разрядов определяется необходимой точностью записи числа и чтобы это число попадало в интервал закодированного слова.
Для приведенного примера кодовая комбинация имеет вид 01110110. Этой кодовой комбинации соответствует число 0,4609375.
При таком кодировании длина полученного интервала равна произведению вероятностей всех встретившихся символов, а его начало зависит от порядка следования символов.
Определим алгоритм восстановления текста. При кодировании каждый следующий интервал вложен в предыдущий. Это означает, что если принято число 0,4609375, то первым символом в цепочке текста может быть только буква “b”, так как ее диапазон (0,0…0,6) включает это число. Перебором всех возможных символов по приведенной выше методике расчета определяем, что следующая буква “c” и т.д.
Обсудим кратко вопрос о сложности кодирования.
Из описания алгоритма следует, что на каждом шаге кодирования выполняется одно сложение и 2 умножения. Отсюда легко сделать неправильный вывод о том, что сложность кодирования последовательности из n сообщений пропорциональна n. Это неверно, поскольку на каждом шаге линейно растет сложность выполнения самих операций сложения и умножения, т.к. нарастает число двоичных разрядов, необходимых для записи операндов.
Предположим, что для представления вероятностей P1, …, PN использованы числа разрядности d. После первого шага кодирования точное представление Н и K потребует 2d разрядов, после n шагов кодирования кодер и декодер будут работать (в худшем случае) с числами разрядности nd, и, следовательно, суммарная сложность имеет порядок
![]() .
.
Таким образом, можно говорить о том, что сложность арифметического кодирования пропорциональна n2. На самом деле, возможна практическая реализация арифметического кодирования со сложностью пропорциональной n.
Отметим еще одну чрезвычайно важную особенность арифметического кодирования. Его легко адаптировать к случаю источников с памятью. Если, например, в качестве модели источника рассматривается простая цепь Маркова, то алгоритм кодирования остается прежним за тем исключением, что вместо одномерных вероятностей P(xi) нужно использовать условные вероятности P(xi|xi-1).