

otvety / 14Вертикальная векторная поразрядная обработка
.docxВекторные вертикальные, ассоциативные и ортогональные процессоры
Задачи скалярной обработки векторов также приводят к параллелизму данных при большом числе m компонентов в векторах,
например, при скалярном сложении двух m-компонентных векторов:
A+B=(a1,a2,….,am)+(b1,b2,….,bm)=(a1+b1,a2+b2,….,am+bm),
где аi, bi – n-разрядные двоичные числа.
Каждая пара одноименных компонент обрабатывается однотипно. Для ускорения операции сложения векторов при большой их размерности m>20 можно применить параллельную поразрядную обработку массива 2m х n бит.
Простейшим подходящим методом структурной организации является построение вычислителя в виде вертикальной последовательно – параллельной ЭВМ. В ней применяется вертикальное АЛУ, содержащее m параллельно включенных одноразрядных сумматоров (ОСМ). Каждая пара компонент обрабатывается поразрядно последовательно за n тактов, начиная с младших разрядов, а все m пар компонент суммируются параллельно одновременно. Конечно, необходим m-разрядный регистр для временного хранения единиц переноса в старшие разряды. Выигрыш по скорости по сравнению с однопроцессорной ЭВМ с многоразрядным (n-разрядным) сумматором будет тем больше, чем больше размерность m векторов.
Для того, чтобы он появился, необходимо выполнение следующего неравенства:
n<Nц*m, или m>n/Nц,
где Nц – число микрокоманд (тактов) в командном цикле однопроцессорной ЭВМ.
Например, при n=32, Nц = 10 выигрыш возможен при m >4, а при m =100 выигрыш составит
= (Nц*m)/n = (10*100)/3230 раз.
Чем больше размерность векторов, тем больше выигрыш. Поэтому оправданы большие затраты на создание супер-ЭВМ США типа СМ 1,2,3, содержащих 65536 одноразрядных микропроцессоров, которые при обработке длинных векторов с m>1000 дают повышение производительности более, чем в 300 раз. Конечно, эти машины уникальные и дорогие.
Возрастание сложности вертикального АЛУ с увеличением m можно существенно замедлить за счет потери выигрыша по скорости в 6 раз, если применить ассоциативную вертикальную поразрядную обработку. Функциональная организация ассоциативного последовательно – параллельного процессора (АППП) основана на двух базовых процедурах при работе с памятью:
1) Поиск ячейки в памяти по совпадению;
2) Последовательное преобразование состояний найденных в результате поиска запоминающих элементов. Этот принцип организации называется «опрос - запись»
Структурная схема АППП содержит
-Вертикальное ассоциативное арифметическое устройство (ВАУ) не фон Неймановской организации, состоящее из ассоциативной памяти (АсЗУ) небольшой емкости 3 x m бит и ПЗУТб, в котором хранятся таблицы истинности арифметических и логических операций;
-Микропрограммное устройство управления (МУУ);
-Регистр индикаторов адресов ячеек ассоциативного ЗУ (РгИА);
-Буферное ОЗУ емкостью 2n x m бит, хранящее массив 2m двоичных слов – n-разрядных компонент двух обрабатываемых векторов А и В;
-Регистр маскирования разрядов ОЗУ (РгМ), не участвующих в данном шаге обработки.
РгМ
МУУ
cmi bmi ami
АсЗУ
cki bki aki
c2i b2i a2i
c1i b2i a2i
Тm
.
.
.
.
.
.
.
.
Tk.
.
.
T2
T1

?
ПЗУ Тб
Опросное слово Cj,bj, aj
Код маски
ВАУ
0…….010……..0……010……0




3
РгИА
Сложение двух m-компонентных векторов А и В выполняется путем последовательной обработки пар одноименных разрядных срезов всех компонент за n командных циклов, каждый из которых состоит из шести микрокоманд:
1. Параллельное чтение из ОЗУ за два такта двух одноименных i-х вертикальных разрядных срезов всех m компонентов векторов А и В и запись их в АсЗУ соответственно в столбцы a и b.
Значения переносов {Cki} в первом столбце АсЗУ при этом сохраняются неизменными. Они были получены в предыдущем (i-1)-м командном цикле, как единицы переноса из (i-1)-го в данный i –й разряд. При сложении младших разрядов (при i=0) в первом командном цикле содержимое первого столбца АсЗУ обнуляется.
2-5. За четыре одинаковых двухтактных микрокоманды 2-5 выполняется опрос и модификация содержимого АсЗУ в результате подачи во все его ячейки из ПЗУТб четырех опросных трехразрядных слов {Cj bj aj}, а именно 2,4,5 и 7-й строк таблицы истинности, не отмеченных точками . Опрос выполняется 4-мя, а не 8-ю строками, так как в отмеченных точками строках левые входные биты совпадают с правыми выходными, т.е. Sj=bj, Cj+1=Cj, и такие ячейки АсЗУ не нужно модифицировать. Эти микрокоманды называются «опрос-запись» АсЗУ. В каждой из них проверяется совпадение входного опросного слова (Cj bj aj) со всеми словами {Cki, bki, aki}1 m во всех ячейках АсЗУ одновременно. В тех ячейках, где опросное слово совпадет с их содержимым, образуется выходной признак совпадения «1», который записывается в соответствующий триггер регистра РгИА. Это слово индикаторов используется МУУ в качестве слова маски при записи в АсЗУ во втором такте под управлением МУУ из ПЗУТб правой выходной части опросной строки (Cj+1 Sj) вместо их старых содержимых {Cki, bki}.
|
|
aj |
bj |
cj |
sj |
Cj+1 |
|
|
0 |
0 . |
0 . |
0 . |
0 . |
|
2 |
0 |
0 |
1 |
1 |
0 |
|
|
0 |
1 . |
0 . |
1 . |
0 . |
|
4 |
0 |
1 |
1 |
0 |
1 |
|
5 |
1 |
0 |
0 |
1 |
0 |
|
|
1 |
0 . |
1 . |
0 . |
1 . |
|
7 |
1 |
1 |
0 |
0 |
1 |
|
|
1 |
1 . |
1 . |
1 . |
1 . |
В шестой микрокоманде командного цикла за один такт переписывается в ОЗУ столбец одноразрядных сумм на место i-го столбца вектора В: {bki}1m := {Ski}1m . При этом возможность выборки из ОЗУ в первой микрокоманде только двух столбцов бит i-х разрядных срезов компонент векторов А и В и записи в ОЗУ в шестой микрокоманде столбца одноразрядных сумм в один i-й разрядный срез вектора В гарантируется маскированием остальных разрядных срезов словами масок, загружаемыми из МУУ в РгМ.
Итак, сложение двух m-компонентных векторов А и В выполняется за 6n микрокоманд вместо m командных циклов, требуемых в однопроцессорной ЭВМ фон Неймана.
Выигрыш по производительности возможен при выполнении неравенства
6n<Nцm, или m>6n/Nц
Например, при n = 32, Nц = 10 микрокоманд выигрыш АППП по производительности возможен лишь при m > 20, при m = 100 и m = 1000 соответственно составит:
= (Nц * m)/6n 5 раз при m = 100,
= 50 раз при m =1000.
Функциональные возможности АППП расширяются значительно проще, чем вертикальных АЛУ, так как в нем не требуется усложнять структуру, а достаточно только дополнить содержимое ПЗУТб новыми таблицами истинности других операций.
Если в традиционную ЭВМ фон Неймана
дополнительно ввести рассмотренный
АППП, то можно ускорить исполнение
векторных команд. ЭВМ такой организации
называется ортогональным параллельным
процессором (ОПП). В нем необходимо ОЗУ
с ортогональной организацией, которое
имеет два вида обращения: горизонтально
– по словам, вертикально по их разрядным
срезам.
ВАППП
ОРТОЗУ


ГСАЛУ
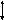
Горизонтальное скалярное АЛУ выполняет традиционную скалярную обработку. Вертикальный АППП используется для ускорения обработки векторов. Он может использоваться как сопроцессор, которому ГСАЛУ будет передавать управление, если в последовательности команд программы встретится векторная команда аналогично передаче управления сопроцессору с плавающей запятой.