

Введение
В.1. Основные определения
Слово «организация» происходит из французского и позднелатинского языков и означает:
- внутренняя упорядоченность, согласованность, взаимодействие частей целого; совокупность процессов или действий, ведущих к образованию и совершенствованию взаимосвязей между частями целого.
В вычислительной технике термин «организация» применяется по отношению к разным уровням средств: сетям ЭВМ, комплексам, системам, отдельным ЭВМ, ее устройствам, процессорам, блокам, функциональным узлам, интегральной элементной базе; входным языкам, программному и информационному обеспечению и т.д. Следовательно, его смысл в ВТ зависит от вида рассматриваемого объекта и взгляда на его роль и способ построения.
В данной дисциплине ограничимся рассмотрением двух основных видов организации ЭВМ и систем, которые определяются двумя взглядами на их функционирование и построение: взглядом пользователя и взглядом разработчика.
Для пользователя важен набор функций и услуг ЭВМ, обеспечивающих эффективное решение его задачи. Его не интересует вопросы технической реализации этих функций.
При проектировании ЭВМ в первую очередь создается ее абстрактная модель, которая описывает функциональные возможности машины и предоставляемые ею услуги.
Функциональная организация ЭВМ – это абстрактная модель совокупности функциональных возможностей и набора услуг, обеспечивающих эффективное решение прикладных задач и предоставляемых пользователю при поэтапном выполнении последовательности действий, автоматически выполняемых в ходе решения его задачи.
В узком смысле в основе функциональной организации ЭВМ лежат принципы двоичного кодирования информации, программного управления, адресности информации в памяти; однородности памяти, позволяющей производить над командами программ те же операции, что и над численными данными.
В широком смысле функциональная организация ЭВМ достаточно полно может быть описана с учетом следующего перечня способов и средств:
- Способы кодирования данных при вводе, представления чисел, адресации, управления файловой системой; система команд;
- Набор периферийных устройств и носителей информации;
- Средства интеллектуализации ввода-вывода (ввод с речи, читающие сканеры, речевой вывод, графический ввод-вывод и т.д.)
- Тип операционной системы, набор драйверов и утилит, средства обработки прерываний и услуги управляющих программ;
- Способ программного управления(по последовательности команд, по данным, по запросу);
- Виды алгоритмических языков программирования;
- Средства автоматизации программирования (интерпретаторы и компиляторы, средства отладки и редактирования программ);
- Средства создания и управления базами данных и знаний;
- Средства защиты от несанкционированного доступа и вирусов;
- Функции программ технического обслуживания, в том числе средства организации отказоустойчивых вычислений.
С другой стороны разработчик ЭВМ должен обеспечить рациональную техническую реализацию названных функций на серийно производимых физических средствах: элементной базе, типовых узлах, блоках и устройствах. При проектировании ЭВМ для описания технических средств широко используются структурные схемы, которые отражают взгляд разработчика на организацию ЭВМ. Отсюда происходит следующий второй вид организации.
Структурная организация ЭВМ– это физическая модель, которая устанавливает состав и принципы взаимодействия основных функциональных частей машины без детализации их технической реализации.
Структурная схема – это графическое отображение структурной организации.
По степени детализации различают структурные схемы на нескольких уровнях средств вычислительной техники: сети ЭВМ, комплексы, системы, отдельные ЭВМ, устройства, процессоры, блоки, узлы, интегральная элементная база. Для полного описания структурной организации ЭВМ или системы необходимо составить иерархическую систему структурных схем всех названных уровней (альбом структурных схем), в том числе структурные схемы БИС, СБИС и УБИС элементной базы.
Следует заметить, что структурные схемы по ГОСТу ЕСПД применяются также для описания абстрактной модели и функциональной организации ЭВМ, например, для наглядного структурирования алгоритмов, пакетов программ, операционных систем, файловых систем, баз данных и т.п. однако эта группа структурных схем не имеет отношения к структурной организации технических средств ЭВМ.
Структура ЭВМ или системы – это организация системы из отдельных недетализированных ее частей с такими их взаимосвязями, которые отображают распределение функций между ними.
В.2. Тенденции развития организации ЭВМ и систем.
Основная тенденция – это широкое внедрение методов параллельной обработки информации (параллелизма) и связанного с ними комплексирования средств вычислительной техники.
Такой подход позволяет существенно повысить производительность ЭВМ и создать необходимые предпосылки для построения отказоустойчивых вычислительных систем. Затраты на введение параллелизма и комплексирование значительно меньше, чем на создание новой технологии производства более быстродействующей элементной базы. На любом уровне развития элементной базы они дают дополнительное мощное средство для повышения производительности ЭВМ на несколько порядков. За последние полвека она выросла в 2 миллиарда раз. Выигрыш в быстродействии за счет развития микроэлектронной элементной базы, который можно оценить по уменьшению времени такта с 2 мкс до 1 нс, составил 2000 раз. Остальная доля в повышении производительности еще в 1 миллион раз получена путем применения новых способов организации, новых архитектур, и в основном – за счет параллельной обработки данных и согласования скорости работы процессора и памяти. Последнее достигнуто увеличением числа уровней в иерархии запоминающих устройств до 9, в том числе применением до 4 уровней КЭШ-памятей между регистрами процессора и основной памятью, дисковой КЭШ-памяти между основной памятью и магнитными дисками.
В параллельных системах всегда имеются избыточные ресурсы, которые можно гибко использовать как для повышения производительности, так и для повышения надежности. Структуры многопроцессорных и многомашинных систем могут быть приспособлены к автоматической реконфигурации (отключению неисправных устройств) и продолжению работы после сбоев и отказов.
Сохраняет актуальность давно известный подход в организации ЭВМ – сочетание алгоритмического и неалгоритмического принципов вычислений. Он использовался в прошлом веке в аналоговых и аналого-цифровых ЭВМ и системах, отличался от последовательного алгоритмического более высокой степенью параллелизма и позволил достичь сравнительно высокой производительности, но, к сожалению, за счет потери точности вычислений и логических возможностей. Сейчас он активно развивается в потоковых цифровых ЭВМ и макропотоковых параллельных вычислительных системах, программно управляемых последовательностью данных (операндов) по степени их готовности к дальнейшим вычислениям, а не последовательностью команд, как это принято в традиционных ЦВМ фон Неймановской архитектуры. Кроме этого неалгоритмический подход успешно применяется в аналого-цифровых вычислительных комплексах (АЦВК) и специализированных потоковых микропроцессорах, аналоговых процессорах нечетного логического вывода (FC- фазикомпьютерах), аналоговых и аналого-цифровых электронных и оптоэлектронных нейрокомпьютерах.
Комплексирование средств вычислительной техники - это создание крупномасштабных систем обработки информации с целью повышения эффективности использования и расширения сферы применения ЭВМ путем объединения с помощью линий связи и дополнительных аппаратных и программных средств комплексирования многих ЭВМ, процессоров и устройств в вычислительные системы, комплексы и сети. Комплексируемые устройства и средства комплексирования производятся в виде модульных агрегатируемых устройств с унифицированными и стандартными интерфейсами.
В.3. классификация вычислительной техники по способу комплексирования
Известны следующие классы скомплексированных систем:
- Однопроцессорная многозадачная мультипрограммная вычислительная система – комплекс центрального обрабатывающего процессора, процессора ввода-вывода, периферийных процессоров (контроллеров периферийных устройств), объединенных параллельным системным интерфейсом (системной шиной).
- Многомашинные вычислительные комплексы (ММВК) с небольшим удалением ЭВМ друг от друга и обменом информации по параллельному интерфейсу на расстоянии не более 100 м.
- Многопроцессорные вычислительные комплексы (МПВК) с применением в центральном обрабатывающем ядре агрегатируемых процессорных модулей, многомодульной многопортовой общей оперативной памяти (ООП) и с использованием общего поля периферийных устройств;
- Многопроцессорные вычислительные системы (МПВС), в том числе интегральные микроэлектронные многопроцессорные платформы на ультрабольших интегральных схемах (УБИС), как развитие МПВК с построением центрального ядра в виде единого конструктивного модуля, содержащего несколько процессоров и модулей локальной и общей памяти с максимально возможной степенью связности и пропускной способностью внутрисистемного интерфейса;
- Многопроцессорные вычислительные системы с перестраиваемой структурой (МПВС с ПС) – развитие МПВС с введением во внутрисистемный интерфейс центрального ядра специальных коммутаторов или в прикладные программы процессоров специальных операторов адресной маршрутизации; в последнем варианте возможно программное управление структурой и архитектурой центрального ядра при неизменных физических линиях связи между процессорами, например в транспьютерных сетях;
- Системы телеобработки (СТО) для централизованной обработки информации, собираемой по линиям связи с удаленных терминалов;
- Сети ЭВМ (вычислительные сети ) - развитие ММВК с удалением ЭВМ друг от друга на расстояние более 100 м и обменом информацией по последовательному интерфейсу через сеть передачи данных (СПД), в том числе локальные вычислительные сети (ЛВС) с небольшим удалением ЭВМ (до 1 км) и простым дешевым моноканалом связи, подключаемым к ЭВМ через адаптер или модем; глобальные вычислительные сети (Гл ВС) с произвольным удалением ЭВМ и сложной разветвленной СПД, содержащей в узлах связи коммуникационные (коммутационные) микро-ЭВМ, в местах стыка с
ЛВС – шлюзы и серверные ВС, а в регионах – поисковые машины (ММВК или МПВК баз данных);
- Кластерные вычислительные системы (кластер рабочих станций - COW) – развитие ЛВС с модификацией моноканалов, серверов и программного обеспечения для отказоустойчивого параллельного распределенного решения ответственных сложных задач отдельных предприятий и организаций;
- Метакомпьютер – развитие Гл ВС для использования всех ресурсов мировой сети ЭВМ с целью решения задач уникальной сложности: параллельно и территориально распределено на множестве рабочих станций и серверов сети;
- Аналого – цифровые вычислительные комплексы (АЦВК), в которых к ведущей цифровой ЭВМ через устройство преобразования и сопряжения (УПС), содержащее аналого-цифровые и цифро-аналоговые преобразователи информации, подключается сателитная аналоговая вычислительная машина (АВМ), используемая обычно для ускорения решения дифференциальных уравнений в обыкновенных или частных производных.
В дальнейшем изложении все названное многообразие скомплексированных средств вычислительной техники условимся называть общим термином «вычислительная система (ВС)».
В.3.1. Классификация ЭВМ и ВС по областям применения.
В настоящие время сложилось следующее подразделение ЭВМ и систем в зависимости от области их применения:
- Персональные компьютеры (ПЭВМ) - это самые дешевые настольные ЭВМ, ориентированные наконечного пользователя,имеющие «дружественный пользовательский интерфейс», а также инструментальные средства для автоматизации разработки прикладных программ на основе удобной операционной системы, напримерWindows;
- Х-терминалы – это бездисковые настольные ЭВМ, не выполняющие локальной обработки, подключаемые к главной (ведущей) ВС посредством сети связи и передающие задания на обработку прикладных программ глобальной ВС по принципу телеобработки, а также ориентированные на ускорениеотображенияграфической информации (быстрое рисование и прокручивание кадров изображений на экране монитора); содержат мощный графический процессор, построенный по двухпроцессорной и многопроцессорной архитектуре, а также особую операционную систему Х-Windowsи сетевые протоколы, напримерTCP/IP;
- Рабочие станции – это наиболее мощные настольные ЭВМ, обладающиеполными мультимедиа возможностями и ориентированные на профессиональных пользователей (чаще всего специалистов в области ЭВМ и программного обеспечения), снабженные такой же быстродействующей графической подсистемой, как и Х-терминалы, и мощной операционной системойUNIX, но менее «дружественной», чемWindows;
- Серверы – это главные, ведущие ЭВМ в многомашинных ВС, ориентированных на территориально распределенную обработку по модели вычислений типа «клиент-сервер», где в качестве клиентских ЭВМ могут использоваться ПЭВМ или рабочие станции; типы серверов определяются их назначением: файл-сервер, сервер базы данных, принт-сервер, вычислительный сервер, сервер приложений (предпоследний организует параллельные распределенные вычислительные процессы, а последний – выполнение сложных пакетов прикладных программ); строятся как многопроцессорные ВС, снабжаются дисковыми ВЗУ большой емкости, в том числе дисковыми массивамиRAID; управляются последними модификациями мощных операционных системUNIXиWindowsNT;
- Мейнфреймы – наиболее мощные ВС общего назначения (большие универсальные ЭВМ) с непрерывным круглосуточным режимом эксплуатации, которые чаще всего используются как главные ЭВМ (хост-машины) вычислительных сетей и по сути являются суперсерверами, построенными по архитектуре МПВС и часто называемыми супер-ЭВМ;
- Кластеры – это многомашинные локальные вычислительные сети высокой готовности с минимально возможным временем простоя и временем восстановления после отказа, позволяющие при отказе процессора или дискового ВЗУ быстро перераспределить работу на резервные устройства; кластер - это объединение машин, которое представляется как единое целое для операционной системы, системного программного обеспечения, прикладных программ и пользователей.
В.4 Понятие об архитектуре ВС
Архитектура ВС – это комплекс общих вопросов, характеристик и параметров, которые определяют ее функциональную и структурную организацию и существенны для пользователя, интересующегося в первую очередь ее функциональными возможностями, а не деталями технического исполнения.
Основные элементы архитектуры можно описать двумя способами:
- Перечнем способов и средств функциональной организации, архитектурой системы команд и альбомом структурных схем;
- Составом и взаимодействием модулей технических средств, программного и информационного обеспечения.
Технические средства ВС – совокупность модульных агрегатируемых устройств ЭВМ, в том числе нескольких ЭВМ, процессоров, модулей ОЗУ, терминалов и прочих периферийных устройств.
Программное обеспечение ВС – комплекс системных и управляющих программ, автоматизирующих обработку прикладных программ и обеспечивающих эффективное использование технических средств и всех ресурсов ВС, в первую очередь важнейших из них: машинного времени и памяти. Сюда входят также программные средства автоматизации программирования и программы технического обслуживания, в том числе средства повышения живучести ВС и организации отказоустойчивых вычислений.
Информационное обеспечение ВС – это коллективно используемые пользователями ВС наборы данных и знаний, долговременно хранящиеся во внешней памяти. Данные и знания сосредотачиваются в автоматизированных банках данных (АБД) и знаний (АБЗ). В большинстве современных ЭВМ и систем обычно АБД и АБЗ используют тот же основной комплекс технических средств, что и прикладные программы и системное ПО. Для ускорения доступа к данным могут создаваться проблемно-ориентированные многопроцессорные машины баз данных: файловые серверы, поисковые машины. Для организации коллективного доступа к АБД и АБЗ используется дополнительный системный управляющий программный комплекс – система управления базой данных (СУБД) или базой знаний (СУБЗ). Он взаимодействует с системным ПО и прикладными программами. СУБЗ отличается от СУБД тем, что, кроме СУБД, в ней имеется дополнительная сложная программная оболочка, осуществляющая контакт с экспертами какой – либо отрасли знаний, которые поставляют в базу факты и правила своей отрасли, а также выполняющая логические выводы из накопленных фактов по заданным правилам. Поэтому СУБЗ часто называют экспертными системами.
В.5 Методология и разделы теории ВС
ВС относятся к наиболее сложным искусственным системам, проектирование и прогнозирование поведения которых невозможно без глубокого теоретического исследования их основных принципов функционирования и характеристик.
Основным методом теории ВС, как сложных систем, является системотехнический подход к их исследованию и проектированию.
Основной принцип системотехники – представление системы в виде совокупности взаимодействующих ее частей с учетом тесной ее связи с окружающей средой и взаимообусловленности всех ее свойств и характеристик: производительности, надежности и сложности, стоимости.
При системотехническом подходе к сложным системам ограничивают глубину исследования (степень детализации) их структурной и функциональной организации. В теории ВС в качестве конечных элементов детализации рассматриваются устройства ЭВМ и модули ПО и информационного обеспечения: процессоры, запоминающие устройства, каналы ввода-вывода, контроллеры, периферийные устройства; модули ОС, драйверы, утилиты, компиляторы, планировщики, диспетчеры, сортировщики, программы логического вывода, загрузчики, файлы и т.п.
Главные исследуемые в системотехнике ВС факторы – принципы организации взаимодействия между устройствами ЭВМ, программными модулями, устройствами и программами, а также способы организации связи между ними; влияние их параметров, способов организации взаимодействия между ними, архитектуры и структуры системы в целом на ее основные показатели и характеристики.
Основная профессиональная ориентация выпускников по данной специальности – теоретик, системотехник, системный архитектор: по спецификации учебника [1]. Основные рабочие места в «кремниевой мастерской», проектирующей СБИС и УБИС: архитектор, инженер системотехнической и схемотехнической САПР. Рабочие места на предприятиях средств ВТ, автоматики и робототехники – инженер - системотехник и схемотехник в конструкторских бюро и чаще всего инженер по установке и эксплуатации всех видов САПР: от системотехнического до САПР печатных плат, ПЛИС и БМК; организатор промышленного производства.
Массовые рабочие места – инженер по комплектации, компоновке, установке и эксплуатации ЭВМ и программного обеспечения; системный программист, прикладной программист.
Все названные области трудовой деятельности требуют знания архитектуры ЭВМ, комплексов и систем, умения прогнозировать ожидаемый эффект от применения средств ВТ, выбирать подходящие вычислительные устройства и программные средства, численно оценивать ожидаемые характеристики вычислительных систем. Значительную часть этих знаний и умений можно получить в результате изучения теории ВС.
Теория ВС состоит из двух разделов:
- Архитектура ВС;
- Метрическая теория ВС.
Раздел «архитектура ВС» охватывает принципы общей структурной и функциональной организации системы, которые определяют способы организации вычислительных процессов и включают в себя методы представления данных; состав, назначение и принципы взаимодействия технических средств, программного и информационного обеспечения. Исследование архитектур ВС направлено на выявление и выбор способов построения систем, рациональных вариантов распределения функций между техническими и программными средствами, состава системы и конфигурации связей между устройствами, способов организации вычислительных процессов.
Метрическая теория ВС занимается количественной оценкой показателей, которые характеризуют качество структурной и функциональной организации системы. В рамках метрической теории исследуется влияние организации системы и режимов ее функционирования на производительность, надежность, стоимость и другие ее характеристики, а также решаются задачи численного обоснования выбора варианта архитектуры системы в целом, оптимальных параметров и внешних характеристик входящих в ее состав устройств ЭВМ и модулей системного ПО. В конечном итоге выполняется структурная и параметрическая оптимизация вычислительной системы.
1. Элементы архитектуры ЭВМ, комплексов и систем
Установочная лекция. Раздел выносится на самостоятельное изучение по учебникам {1-4}. Обязательно изучить в учебнике {3} с.5-137, 191-280:
Классификация систем обработки данных (СОД).
Режимы работы СОД и режимы обработки данных.
Состав и особенности программного обеспечения ВС.
Производительность ВС: пиковая, номинальная, комплексная, системная.
ММВК: слабосвязанные, прямосвязанные, сателитные.
МПВК. Типы внутрисистемных интерфейсов: с общей шиной, многошинные, многовходовые (многопортовые) общие ОЗУ, перекрестные коммутаторы.
Отказоустойчивые МПВК.
МПВК на базе микропроцессоров: кластеры Сm,Cmm.
Технические средства комплексирования ММВК и МПВК: общие оперативные ЗУ (ООЗУ);
Канал прямого управления между процессорами;
Адаптер канал-канал; переключатель общей шины; адаптер межпроцессорной связи в многошинных МПВК.
Конвейерные ВС. Матричные ВС с общим управлением (ПС2000). Ассоциативные ВС.
Функционально – распределенные ВС (ФРВС).
МПВС с перестраиваемой структурой.
Системы телеобработки (СТО).
Глобальные вычислительные сети (ГлВС).
Сеть передачи данных, узлы связи, сеть ЭВМ и терминальная сеть. Логическая, физическая и программная структура ГлВС. Удаленные процессы и порты. Уровни управления и протоколы.
Локальные вычислительные сети (ЛВС). Множественный доступ к моноканалу. Мосты и шлюзы. Сетевой адаптер. Сетевое ПО.
Основы теории ВС. Системотехническое проектирование и эксплуатация ВС.
На лабораторных занятиях изучаются математические и методологические основы метрической теории ВС, как развитие и углубление концептуального раздела «Основы теории ВС» {3}: с.221-266. Основное внимание обращается на приобретение практических навыков использования в инженерной практике программно – аналитических моделей и имитационного моделирования ЭВМ, комплексов и систем, как основы систем автоматизации системотехнического проектирования ВС. Осваивается методика формализации, алгоритмизации и реализации имитационных моделей ВС: составления концептуальной модели и схемы имитационной сети (СИМ). СИМ рассматривается как главный инженерный инструмент подготовки модели к вводу в инструментальную (моделирующую) ЭВМ независимо от используемого языка моделирования: GPSS, сети Петри, Е-сети, естественный узко специализированный язык меню и таблиц. Поэтому задачи по составлению СИМ на основе исходного словесного описания структуры и режима работы ВС включены в экзаменационные билеты. Список задач приведен в методических указаниях {5}, часть 2. требуемая для решения этих задач информация о концептуальных моделях ЭВМ и систем имеется в учебниках {1-4,7}.
2. Особенности архитектуры ЭВМ и систем с неалгоритмическим принципом вычислений и перспективы создания цифровых ВС с массовым параллелизмом
В ХХ столетии в условиях недостаточной степени интеграции и быстродействия микроэлектронной элементной базы цифровых ЭВМ сравнительно высокой производительности средств ВТ достигали путем применения параллельных неалгоритмических вычислений на основе непрерывной (аналоговой) формы представления (НФП) обрабатываемых математических величин:
Xмаш (tмаш) =mxxм (mttm),
где Xмаш ,tмаш - машинные величины зависимой переменной Х и ее аргументаt;
Xм,tm– математические величины переменной Х и аргументаt;
Mx,mt– масштабы переменной Х и аргументаt.
НФП – это представление каждого мгновенного значения математической величины пропорциональным ему мгновенным значением машинной переменной, в качестве которой используется физическая величина, например электрическое напряжение или ток. В этом случае абсолютная погрешность Δ вычислений определяется классом точности изготовления электрических элементов и стабильностью работы электронных компонентов, с помощью которых реализуются физические машинные переменные. Она проявляется при обратном преобразовании машинных величин в искомые математические величины:
Хм (tм) = 1/mx*Xмаш (tмаш/mt) +Δ/mx
Относительную погрешность операционных блоков:
обл = 100 Δобл/Umax,
где Umax– предельное значение физической машинной величины на выходе блока; удалось снизить дообл = 0,01….0,1% благодаря применению прецезионных резисторов и конденсаторов и операционных усилителей с очень большим коэффициентом усиления
Ку =
![]() ……
……![]() ,
,
Охваченных глубокой отрицательной обратной связью, а при термостатировании элементов – до обл = 0,001%.
Использование НФП позволило реализовать неалгоритмический принцип вычислений (НПВ) путем ввода в машину и реализации решения задачи в общепринятой аналитической форме ее описания. Наиболее часто использовавшийся вид НПВ – аналоговое математическое моделирование по методу непрямой аналогии. Модель решаемой задачи строилась по блочно-операционному принципу, когда каждой операции и функции исходного уравнения (оригинала) в модели соответствовал подобный операционный блок: сумматор, интегратор, функциональный блок, блок деления и умножения, блок запаздывания и т.п.
Используя достаточный набор типовых операционных блоков с избыточным числом каждого из типов блоков, можно решать определенный класс математических задач. Аналоговая вычислительная машина (АВМ) – это достаточный набор операционных блоков, коммутаторов для ручного или автоматического соединения блоков между собой, устройство управления со счетчиком времени, цифровой вольтметр и блок питания.
Программирование АВМ выполняется за два этапа:
1. Составление схемы аналоговой модели, которая представляет собой структурную схему соединения типовых операционных блоков друг с другом в соответствии с заданной задачей.
Для АВМ, ориентированных на решение нелинейных дифференциальных уравнений в обыкновенных производных, такая схема модели составляется элементарно по методу понижения порядка. Достаточно соединить в последовательной цепи число интеграторов, равное порядку решаемого уравнения, а на вход первого интегратора подать напряжение, пропорциональное высшей производной и образованное сумматором из выходных величин тех же интеграторов, так как они пропорциональны величинам низших производных. Суммируются только те низшие производные, которые входят в запись исходного уравнения. Тем самым в схеме модели уравнения замыкается несколько обратных связей. После пуска АВМ в этой замкнутой цепи наблюдается переходный процесс, ординаты которого пропорциональны ординатам искомого решения. Электрические сигналы (переменные напряжения) передаются от блока к блоку модели последовательно, но вычисления во всех блоках выполняются параллельно и одновременно. Тем самым достигли большого повышения скорости решения по сравнению с однопроцессорной ЦВМ, так как в последней вычисление только одного интеграла выполняется путем многошагового накопления суммы элементарных площадей прямоугольников или трапеций с достаточно малым шагом приращения аргумента.
2. Масштабирование модели, заключающееся в пропорциональном пересчете коэффициентов исходного уравнения в настраиваемые параметры (величины сопротивлений) операционных блоков АВМ, которое выполняется по методам теории подобия с учетом масштабов переменных.
Наиболее успешно применялись АВМ, проблемно ориентированные на решение нелинейных дифференциальных уравнений в обыкновенных и частных производных. Первые назывались электронные АВМ, а вторые – электрические сеточные АВМ. Электрическая модель задачи в частных производных представляла собой достаточно густую плоскую или объемную решетку (сетку) резисторов, в узлах которой считывали величины напряжения, пропорциональные ординатам искомых функций двух или трех переменных.
Основной недостаток данного аналогового НПВ – увеличение погрешности решения с увеличением порядка решаемых уравнений до 1….5 % .
Точность вычислений повышали путем частичного или полного перехода от аналогового к цифровому моделированию, сохраняя основное преимущество НПВ – возможность параллельного функционирования операционных блоков в вычислительном процессе. Использовались два подхода:
1) Реализация операционных блоков на цифровой элементной базе, сохраняя математическое моделирование по методу непрямой аналогии, как и в АВМ;
2) Разделение сложной задачи на две взаимодействующие части, одна из которых решается цифровым процессором, а другая – аналоговым. ЭВМ по первому подходу назывались гибридными вычислительными машинами (ГВМ), например производились цифровые дифференциальные анализаторы (ЦДА) и цифровые интегрирующие машины (ЦИМ). По второму подходу строились аналого-цифровые вычислительные комплексы (АЦВК).
Наконец, к концу ХХ столетия были созданы потоковые ЦВМ, основанные на НПВ и новом принципе потокового программного управления по степени готовности операндов, т.е. управления последовательностью данных, а не команд, как это было принято в ЦВМ фон Неймана. Это позволило использовать для повышения производительности ЦВМ естественный параллелизм операций, имеющийся в большинстве решаемых задач. Сейчас осваиваются макропотоковые цифровые ВС, позволяющие на нескольких процессорах параллельно обрабатывать фрагменты программ по принципу НПВ по степени готовности их входных данных.
Таким образом, в прошлом столетии одновременно с алгоритмическим принципом вычислений в ЭВМ фон Неймана успешно развивался и прошел ряд этапов НПВ:
- Аналоговое математическое моделирование;
- Цифровое математическое моделирование по методу непрямой аналогии;
- Аналого-цифровое моделирование;
- Неалгоритмическое потоковое программирование по степени готовности данных;
В настоящее время аналоговое математическое моделирование в машинах, основанных на аналоговой электронной и оптоэлектронной элементной базе, применяется сравнительно редко в тех случаях, когда это дает выигрыш по сравнению с цифровой схемотехникой в 100…1000 раз по производительности, потребляемой энергии и габаритам. Серийно производятся аналоговые СБИС нечетной логики и процессоров нечетного логического вывода, имитирующие в системах автоматики рассуждения и действия человека; а также электронные и оптоэлектронные аналоговые СБИС нейрокомпьютеров. Применяются однотактные аналоговые оптические устройства преобразования Фурье плоских изображений.
Наибольший экономический эффект был получен от применения АЦВК. Они успешно применялись и в ряде случаев продолжают эксплуатироваться при проектировании, моделировании и отладке
- Цифровых САУ сложных объектов управления: тепловозов, электровозов, самолетов, космических ракет, ракет систем ПРО, тепловых, химических и ядерных реакторов, роботов и т.п.
- При исследовании переходных процессов в проектируемых БИС и СБИС;
- При имитации систем самолета и окружающей среды в пилотных тренажерах.
В ХХIвеке АЦВК сняты с производства и заменяются цифровыми мультипроцессорными и мультикомпьютерными ВС (классификация США) в связи со следующими недостатками АЦВК:
- Возрастание погрешности из-за сателитной АВМ;
- Необходимость разворачивания производства прецезионных АВМ и УПС с более сложной и дорогой технологией и метрологией, чем у ЦВМ;
- Существенное усложнение системного ПО ведущей ЦВМ комплекса по сравнению с базовым ПО ЦВМ, например потому, что она должна выполнять функции робота-программиста и оператора АВМ;
- Ограниченный класс математических задач, ускорить решение которых удалось в АЦВК.
Из всего многообразия цифровых параллельных многопроцессорных комплексов и систем конкурентоспособными по производительности с АЦВК являются ВС с массовым параллелизмом.
Классический пример таких цифровых
МПВС с массовым параллелизмом – это
гиперкубовые супер-ЭВМ США типа СМ-1,2,3
, содержащие 65536 одноразрядных
последовательных микропроцессоров,
размещенных в
![]() кластерных СБИС, каждая из которых
состоит из 16-ти одноразрядных
микропроцессоров и имеет 12-ть
последовательных портов ввода-вывода.
Каждая СБИС по гиперкубовому принципу
соединяется с 12-ю непосредственными
соседями. Они уже 20 лет эксплуатируются
в научных и проектных центрах США. Опыт
их эксплуатации показал, что цифровые
ВС массового параллелизма могут по
производительности превзойти АЦВК.
Например, на младшей модификации системы
СМ-1 удалось запрограммировать цифровую
модель всех переходных процессов
проектируемой БИС, содержащей до 8000
транзисторов.
кластерных СБИС, каждая из которых
состоит из 16-ти одноразрядных
микропроцессоров и имеет 12-ть
последовательных портов ввода-вывода.
Каждая СБИС по гиперкубовому принципу
соединяется с 12-ю непосредственными
соседями. Они уже 20 лет эксплуатируются
в научных и проектных центрах США. Опыт
их эксплуатации показал, что цифровые
ВС массового параллелизма могут по
производительности превзойти АЦВК.
Например, на младшей модификации системы
СМ-1 удалось запрограммировать цифровую
модель всех переходных процессов
проектируемой БИС, содержащей до 8000
транзисторов.
Еще большей производительности удалось
добиться в мультикомпьютерах с массовым
параллелизмом (МРР – массово параллельные
процессоры) типа CrayT3E,OptionWhire.
Первый из них содержит 2048, второй – 9416
тридцатидвух или шестидесятичетырех
- разрядных микропроцессоров, соединенных
по топологии кубической решетки. Пиковая
производительность первого – 1,2 Тфлопс,
а второго – 100 Тфлопс (![]() оп.с пл. запятой/с).
оп.с пл. запятой/с).
Однако пока такие супер-ЭВМ являются
весьма дорогими, энергоемкими и
крупногабаритными. Например, система
с массовым параллелизмом CrayХ1,
изготовленная в 2002 году, содержит 4096
процессоров, имеет производительность
52TFLOPS(![]() опер.с пл. запятой в секунду), емкость
памяти 64 Тбайт, но весит 170 т, имеет
жидкостное охлаждение, потребляет 120
Кват электроэнергии и стоит 16,5 млн.
долл.
опер.с пл. запятой в секунду), емкость
памяти 64 Тбайт, но весит 170 т, имеет
жидкостное охлаждение, потребляет 120
Кват электроэнергии и стоит 16,5 млн.
долл.
В этих супер-ЭВМ внедряется неалгоритмический макропотоковый принцип параллельной обработки параллельных фрагментов сложных программ (потоков, нитей по терминологии ОС UNIX?WindowsNT), который позволит автоматизировать распараллеливание, повысить степень загрузки множества процессоров и приблизить реальную производительность к пиковой.
3 Теоретические основы архитектуры параллельных ЭВМ и систем
3.1 Способы организации параллельной обработки информации
Правительства всех развитых стран мира рассматривают высокопроизводительные параллельные вычисления в ЦВМ как стратегически важнейшую задачу, решение которой обеспечивает не только техническое лидерство в области ВТ, но и конкурентоспособность экономики страны на мировом рынке.
Применяются следующие способы организации параллельной обработки информации:
1) Псевдопараллелизм на основе мультипрограммирования и разделения времени процессора, поддерживаемый современными операционными системами (ОС) UNIXиWindowsNTи заключающийся в совмещении во времени различных этапов обработки разных задач в многозадачном режиме, например счета в процессоре, ввода, вывода, обращения в ВЗУ; или в разбиении процессорного времени на кванты и выделении квантов разным задачам с циклическими их прерываниями;
2) Параллельные вычисления с одновременным решением разных задач или параллельных частей одной и той же сложной задачи на нескольких процессорах или ЭВМ;
3) Конвейерная обработка – частный случай второго способа, который выделяют как отдельный способ в связи с его особой важностью и массовостью применения.
Вся история развития современных однопроцессорных ЭВМ и микропроцессорных систем – это постепенное внедрение и усовершенствование следующих методов и устройств параллельной обработки:
Параллельные многоразрядные сумматоры и АЛУ;
Конвейерные арифметические узлы АЛУ;
Конвейеры команд – конвейерные блоки управления процессорами с блоками опережающей выборки команд и предсказания условий переходов;
Сверхпараллельная аппаратно избыточная арифметика: однотактные матричные блоки умножения / деления и кодоуправляемые сдвигатели барабанного типа;
Параллельные многомодульные многопортовые ОЗУ;
Несколько уровней кэш-памяти;
Псевдопараллелизм на основе мультипрограммирования и разделения времени центрального процессора;
Контроллеры прямого доступа в основную память;
Суперскалярная организация микропроцессоров;
Мультискалярные многопроцессорные платформы на УБИС.
Дальнейшая тенденция введения параллелизма – переход к мультипроцессорным и мультикомпьютерным ВС, в том числе к кластерным ВС, супер-ЭВМ с массовым параллелизмом с программируемой структурой и отказоустойчивой организацией вычислений.
В задачах обработки информации встречается несколько характерных типов параллелизма, например, для одних характерен параллелизм операций, а для других – параллелизм данных.
Поэтому мы начнем изучение архитектур параллельных ВС с того, какой отпечаток откладывает тип параллелизма решаемой задачи на функциональную и структурную организацию ВС, как наилучшим образом приспособить последние к типу параллелизма задачи, а далее – как организовать ВС, чтобы удовлетворить все типы параллелизма решаемых задач, т.е. как достичь повышения производительности одной и той же ВС на разных типах параллелизма задач.
3.1.1. Естественный параллелизм независимых задач
Он наблюдается, если в ВС поступает поток несвязанных между собой задач. В этом случае повышение производительности сравнительно просто достигается путем введения в ВС ансамбля независимо параллельно работающих процессоров, подключенных к внутрисистемным интерфейсам многомодульной общей ОП и инициализации процессоров ввода – вывода (ПВВ).
Структура ансамблевой ВС состоит из 4 ярусов параллельных ансамблей: mмодулей ООП;nпроцессоров; р процессоров ввода-вывода, каждый из которых инициализируется и программируется, как контроллер прямого доступа в память, любым изnцентральных процессоров; множество разных периферийных устройств, имеющих параллельный прямой доступ в модули ООП через параллельные ППВ и составляющих общее поле ПУ для центральных процессоров.
Структура ансамблевой ВС без детализации интерфейсов

.
……….
Число модулей ОП m>n+pдля того, чтобы обеспечить возможность параллельного обращения в память всехnцентральных обрабатывающих процессоров и всех р ПВВ и повысить отказоустойчивость. Резервные (m-n-p) модули ООП необходимы для быстрого восстановления системы при отказе рабочего модуля памяти, используя их для хранения копий ССП процессоров и процессов в контрольных точках программ, которые используются для организации рестартов программ при отказах модуля ООП или процессора.
В данном варианте структурной организации ВС имеется возможность при параллельном решении независимых задач под каждую их них временно объединять пару: Пi+ОПjкак автономно функционирующую ЭВМ. Предварительно этот же модуль ОПjвременно работал в паре: ПВВк+ОПj, и в ОПjв буфер ввода были из ПУ загружены программа задачи и данные. По окончании обработки программы процессором Пiв модуле памяти ОПjсоздается и заполняется буфер вывода, а затем модуль ОПjвременно вводится в пару с любым свободным ПВВ: ОПj+ПВВrдля вывода результатов на свободное в данный момент времени ПУ.
Структура ВС с ансамблевой организацией является упрощенной базовой физической моделью МПВК и МПВС и имеет такое же важное начальное познавательное значение как и структура упрощенной гипотетической фон Неймановской ЭВМ, с которой начинается изучение вычислительных машин в главе 3 базового учебника Цилькера Б.Я. {1}.
Для того, чтобы один и тот же модуль ОПjобщей памяти в разные моменты времени мог объединяться либо с процессором Пi, либо с процессором ввода-вывода ПВВ, необходимо правильно подобрать схемы и топологии интерфейсов. Внутрисистемный интерфейс многомодульной ООП целесообразно строить в виде матричного перекрестного коммутатора (кроссбара), в каждом узле которого размещается параллельный ключ, замыкающий накоротко под управлением ведущего процессора линии параллельных интерфейсов ведомого процессора Пiи модуля памяти ОПj. Кроссбар позволяет временно создавать множество параллельных ЭВМ {Пi+Пj} и параллельных соединений {ОПj+ПВВк} с общим полем ПУ.
Структура ансамблевой ВС с детализацией интерфейсов

Интерфейс инициализации ПВВ может быть построен по схеме общей шины (ОШ2), так как последовательности команд инициализации и программирования ПВВ являются короткими и передаются сравнительно редко.
Интерфейс управления ключами кроссбара также можно реализовать в виде общей шины (ОШ1), содержащей линии адреса ключа и линии кода его состояния (замкнут, разомкнут). Состояния всех ключей необходимо хранить в памяти ведущей ЭВМ в специальной системной таблице.
Интерфейс ввода-вывода целесообразно строить также в виде кроссбара для того, чтобы создать возможность параллельного прямого доступа нескольких ПУ в несколько модулей {ОПj} через инициализированные ведущим процессором {ПВВ}. Ключи этого кроссбара 2 управляются ведущим процессором по дополнительному интерфейсу типа «общая шина» (ОШ3), который используется также для передачи сигналов системных вызовов процедур организации ввода от ПУ в ведущий процессор.
По классификации США данная система относится к мультипроцессорным ВС типа SMP(SymmetricMultiprocessor) – симметричный мультипроцессор с однородным доступом к общей памяти. Программы мультисистемной ОС (МОС) обычно выполняются одним из процессоров, а вернее временно созданной управляющей ЭВМ, например парой (П1, ОП1), в память ОП1 которой в режиме начальной загрузки записывается ядро ОС. Такой модуль ОП1,закрепленный за ведущим процессором, называется управляющей памятью. ВSMPвсе процессоры по начальной загрузке равноправны. Любой из них может быть зафиксирован в качестве ведущего. Поэтому все процессоры подключаются к трем общим шинам управления, но до отказа ведущего только он один управляет ключами в кроссбарах, инициализирует ПВВ, воспринимает по ОШЗ сигналы системных вызовов периферийных устройств. Такой принцип организации МОС ВС называется «ведущий - ведомый». При отказе ведущего процессора необходимо повторно выполнить режим начальной загрузки и закрепить функции ведущего за любым из исправных ведомых процессоров. При отказах любых других устройств системы: ведомых процессоров, модулей ОП, ПВВ, ПУ начальная перезагрузка не требуется, вычислительные процессы не уничтожаются и автоматически продолжаются на исправных устройствах путем реконфигурации структуры (отключения неисправных устройств от интерфейсов высокоимпедансными ключами) и рестарта кратковременно прерванных программ с предыдущих контрольных точек. Поэтому для организации отказоустойчивых вычислений в состав МОС ВС вводится дополнительная ОС надежности (система мониторинга ресурсов).
Основная дополнительная задача МОС ВС по сравнению с ОС однопроцессорной ЭВМ – это оптимальное распределение задач между параллельными процессорами по критерию максимальной их загрузки, или минимизации времени их простоев. Эти функции выполняют системные программы «планировщик» и «диспетчер». Оптимальным является асинхронный принцип загрузки и запуска задач в процессорах, не ожидая, пока закончится обработка других задач в других процессорах. Если пакет входных задач, накопленный в ВЗУ, снабжен управляющими картами задач, то оптимальное планирование и диспетчеризация асинхронной обработки задач сводится к составлению и реализации оптимального расписания моментов запуска последовательностей задач на разных процессорах. Для этого в управляющей карте каждой из задач пакета необходимо указывать предварительно оцененное время ее процессорной обработки (вычислительную сложность задачи).
Несмотря на независимость задач в совокупности их асинхронных параллельных вычислительных процессов возможны конфликты между ними за владение общими ресурсами системы: 1) услуги общей МОС, например обработка прерываний по вводу – выводу одновременно для нескольких задач, или их обращения к общей ОС надежности при отказах; 2) одновременные обращения в общую базу данных, обычно хранящуюся на ВЗУ большой емкости; 3) конфликты на занятие требуемых групп ключей в кроссбарах и т.п. Конфликты разрешаются с помощью специальных механизмов МОС: а) приоритетных очередей; б) синхропримитивов синхронизации асинхронных процессов обычно на входе к общим ресурсам.
Если в МОС ввести дополнительный механизм синхронизации со взаимоисключением процессов при работе с общим ресурсом, то функциональные возможности данной системы можно расширить на обработку совокупности слабосвязанных задач. Под ними подразумеваются такие задачи, фактическое время обработки каждой из которых ( с учетом обращения к ПУ) значительно больше затрат времени на обмен информацией между ними. Обмен данными осуществляется через буфер обмена (почтовые ящики), создаваемые в модулях {ОПj} или в общих ВЗУ. Тогда путем синхронизации необходимо обеспечить, чтобы процессы впустую не работали с переполненными и пустыми почтовыми ящиками и одновременно не выполняли в них процедуры записи – чтения.
Очень важным свойством данного типа ВС по сравнению с однопроцессорными ЭВМ является возможность повышения скорости обработки программ МОС. В критические интервалы времени возникновения конфликтов многих ведомых процессов за услуги общих модулей МОС обработка одинаковых и разных запросов к МОС может распараллеливаться также, как и прикладных программ. Для этого МОС из копий своих управляющих модулей создает комплект (пакет) независимых задач максимального уровня приоритета, которые на время своей обработки временно вытесняют из ведомых процессоров менее приоритетные прикладные задачи.
Если между задачами или параллельными фрагментами (ветвями) сложной задачи наблюдается сильная связь, т.е. время требуемое для передачи информации между ними сравнимо или превышает процессорное время каждой из них, то при ансамблевой организации трудно получить большой выигрыш в производительности, и поэтому с целью его увеличения переходят к другим способам организации центрального обрабатывающего ядра системы.
3.1.2 Естественный параллелизм данных
Он наблюдается в таких задачах, когда по одной и той же программе или редко модифицируемой программе многократно обрабатываются разные подмножества данных, поступающие в систему либо одновременно, либо последовательно в виде потока подмножеств данных.
Характерные вычислительные задачи с одновременным поступлением данных – операции многоместного сложения и умножения данных:
![]() ,
,
![]()
выполняемые в фон Неймановских ЭВМ путем многократной реализации двухместных операций и накопления конечного результата из ряда промежуточных.
Задачи с потоком подмножеств входных данных: цифровая обработка сигналов, обработка данных в читающих сканерах, устройствах ввода данных в ЭВМ с речи, статистическая обработка данных и т.д.
Устройство ЭВМ, всегда работающее в условиях естественного параллелизма входных данных, - это устройство управления процессором, на вход которого в работающей ЭВМ поступает непрерывный поток кодов команд, каждая из которых подвергается однотипной обработке: вызов кода команды из памяти, расшифрование кода операции, вызов операндов из памяти.
При параллелизме данных повышение производительности возможно на основе следующих способов организации ЭВМ и систем:
- Параллельная поразрядная обработка всего множества Nоперандов, аналогично параллельной поразрядной обработке двух операндов в многоразрядном сумматоре АЛУ;
- Конвейерная обработка;
Конвейеры удобнее использовать при последовательном потоке операндов, но они могут быть применены и при одновременном их поступлении в систему, если в ОЗУ создать буфер для их хранения, а поток операндов организовать искусственно путем последовательного их считывания из буфера. Конвейеры широко используются и в микропроцессорах, и в супер – ЭВМ. Поэтому выделяется особый отдельный способ конвейерной обработки информации, который мы рассмотрим ниже.
Вначале рассмотрим основные виды организации параллельных ВС по принципу параллельной поразрядной обработки, применяемые при достаточно большой мощности N>100 множества операндов.
3.1.2.1 Векторные вертикальные, ассоциативные и ортогональные процессоры
Задачи скалярной обработки векторов также приводят к параллелизму данных при большом числе mкомпонентов в векторах,
например, при скалярном сложении двух m-компонентных векторов:
A+B=(a1,a2,….,am)+(b1,b2,….,bm)=(a1+b1,a2+b2,….,am+bm),
где аi, bi –n-разрядные двоичные числа.
Каждая пара одноименных компонент обрабатывается однотипно. Для ускорения операции сложения векторов при большой их размерности m>20 можно применить параллельную поразрядную обработку массива 2mхnбит.
Простейшим подходящим методом структурной организации является построение вычислителя в виде вертикальной последовательно – параллельной ЭВМ. В ней применяется вертикальное АЛУ, содержащее mпараллельно включенных одноразрядных сумматоров (ОСМ). Каждая пара компонент обрабатывается поразрядно последовательно заnтактов, начиная с младших разрядов, а всеmпар компонент суммируются параллельно одновременно. Конечно, необходимm-разрядный регистр для временного хранения единиц переноса в старшие разряды. Выигрыш по скорости по сравнению с однопроцессорной ЭВМ с многоразрядным (n-разрядным) сумматором будет тем больше, чем больше размерностьmвекторов.
Для того, чтобы он появился, необходимо выполнение следующего неравенства:
n<Nц*m, илиm>n/Nц,
где Nц – число микрокоманд (тактов) в командном цикле однопроцессорной ЭВМ.
Например, при n=32,Nц = 10 выигрыш возможен приm>4, а приm=100 выигрыш составит
= (Nц*m)/n= (10*100)/3230 раз.
Чем больше размерность векторов, тем больше выигрыш. Поэтому оправданы большие затраты на создание супер-ЭВМ США типа СМ 1,2,3, содержащих 65536 одноразрядных микропроцессоров, которые при обработке длинных векторов с m>1000 дают повышение производительности более, чем в 300 раз. Конечно, эти машины уникальные и дорогие.
Возрастание сложности вертикального АЛУ с увеличением mможно существенно замедлить за счет потери выигрыша по скорости в 6 раз, если применить ассоциативную вертикальную поразрядную обработку. Функциональная организация ассоциативного последовательно – параллельного процессора (АППП) основана на двух базовых процедурах при работе с памятью:
1) Поиск ячейки в памяти по совпадению;
2) Последовательное преобразование состояний найденных в результате поиска запоминающих элементов. Этот принцип организации называется «опрос - запись»
Структурная схема АППП содержит
-Вертикальное ассоциативное арифметическое устройство (ВАУ) не фон Неймановской организации, состоящее из ассоциативной памяти (АсЗУ) небольшой емкости 3 xmбит и ПЗУТб, в котором хранятся таблицы истинности арифметических и логических операций;
-Микропрограммное устройство управления (МУУ);
-Регистр индикаторов адресов ячеек ассоциативного ЗУ (РгИА);
-Буферное ОЗУ емкостью 2nxmбит, хранящее массив 2mдвоичных слов –n-разрядных компонент двух обрабатываемых векторов А и В;
-Регистр маскирования разрядов ОЗУ (РгМ), не участвующих в данном шаге обработки.
РгМ
МУУ cmi
bmi ami
АсЗУ
cki
bki aki
c2i
b2i a2i c1i
b2i a2i
Тm . . . . . . . . Tk. . . T2 T1
?
ПЗУ Тб
Опросное словоCj,bj,aj




3
РгИА






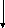

Сложение двух m-компонентных векторов А и В выполняется путем последовательной обработки пар одноименных разрядных срезов всех компонент заnкомандных циклов, каждый из которых состоит из шести микрокоманд:
1. Параллельное чтение из ОЗУ за два такта двух одноименных i-х вертикальных разрядных срезов всехmкомпонентов векторов А и В и запись их в АсЗУ соответственно в столбцыaиb.
Значения переносов {Cki} в первом столбце АсЗУ при этом сохраняются неизменными. Они были получены в предыдущем (i-1)-м командном цикле, как единицы переноса из (i-1)-го в данныйi–й разряд. При сложении младших разрядов (приi=0) в первом командном цикле содержимое первого столбца АсЗУ обнуляется.
2-5. За четыре одинаковых двухтактных микрокоманды 2-5 выполняется опрос и модификация содержимого АсЗУ в результате подачи во все его ячейки из ПЗУТб четырех опросных трехразрядных слов {Cjbjaj}, а именно 2,4,5 и 7-й строк таблицы истинности, не отмеченных точками . Опрос выполняется 4-мя, а не 8-ю строками, так как в отмеченных точками строках левые входные биты совпадают с правыми выходными, т.е.Sj=bj,Cj+1=Cj, и такие ячейки АсЗУ не нужно модифицировать. Эти микрокоманды называются «опрос-запись» АсЗУ. В каждой из них проверяется совпадение входного опросного слова (Cjbjaj) со всеми словами {Cki,bki,aki}1 m во всех ячейках АсЗУ одновременно. В тех ячейках, где опросное слово совпадет с их содержимым, образуется выходной признак совпадения «1», который записывается в соответствующий триггер регистра РгИА. Это слово индикаторов используется МУУ в качестве слова маски при записи в АсЗУ во втором такте под управлением МУУ из ПЗУТб правой выходной части опросной строки (Cj+1Sj) вместо их старых содержимых {Cki,bki}.
|
|
aj |
bj |
cj |
sj |
Cj+1 |
|---|---|---|---|---|---|
|
|
0 |
0 . |
0 . |
0 . |
0 . |
|
2 |
0 |
0 |
1 |
1 |
0 |
|
|
0 |
1 . |
0 . |
1 . |
0 . |
|
4 |
0 |
1 |
1 |
0 |
1 |
|
5 |
1 |
0 |
0 |
1 |
0 |
|
|
1 |
0 . |
1 . |
0 . |
1 . |
|
7 |
1 |
1 |
0 |
0 |
1 |
|
|
1 |
1 . |
1 . |
1 . |
1 . |
В шестой микрокоманде командного цикла за один такт переписывается в ОЗУ столбец одноразрядных сумм на место i-го столбца вектора В: {bki}1m := {Ski}1m . При этом возможность выборки из ОЗУ в первой микрокоманде только двух столбцов битi-х разрядных срезов компонент векторов А и В и записи в ОЗУ в шестой микрокоманде столбца одноразрядных сумм в одинi-й разрядный срез вектора В гарантируется маскированием остальных разрядных срезов словами масок, загружаемыми из МУУ в РгМ.
Итак, сложение двух m-компонентных векторов А и В выполняется за 6nмикрокоманд вместоmкомандных циклов, требуемых в однопроцессорной ЭВМ фон Неймана.
Выигрыш по производительности возможен при выполнении неравенства
6n<Nцm, илиm>6n/Nц
Например, при n= 32,Nц = 10 микрокоманд выигрыш АППП по производительности возможен лишь приm> 20, приm= 100 иm= 1000 соответственно составит:
= (Nц *m)/6n5 раз приm= 100,
= 50 раз при m=1000.
Функциональные возможности АППП расширяются значительно проще, чем вертикальных АЛУ, так как в нем не требуется усложнять структуру, а достаточно только дополнить содержимое ПЗУТб новыми таблицами истинности других операций.
Е сли
в традиционную ЭВМ фон Неймана
дополнительно ввести рассмотренный
АППП, то можно ускорить исполнение
векторных команд. ЭВМ такой организации
называется ортогональным параллельным
процессором (ОПП). В нем необходимо ОЗУ
с ортогональной организацией, которое
имеет два вида обращения: горизонтально
– по словам, вертикально по их разрядным
срезам.
сли
в традиционную ЭВМ фон Неймана
дополнительно ввести рассмотренный
АППП, то можно ускорить исполнение
векторных команд. ЭВМ такой организации
называется ортогональным параллельным
процессором (ОПП). В нем необходимо ОЗУ
с ортогональной организацией, которое
имеет два вида обращения: горизонтально
– по словам, вертикально по их разрядным
срезам.
ОРТОЗУ




ГСАЛУ

Горизонтальное скалярное АЛУ выполняет традиционную скалярную обработку. Вертикальный АППП используется для ускорения обработки векторов. Он может использоваться как сопроцессор, которому ГСАЛУ будет передавать управление, если в последовательности команд программы встретится векторная команда аналогично передаче управления сопроцессору с плавающей запятой.
3.1.2.2 Ассоциативные вычислительные системы
Значительно больший выигрыш по производительности за счет параллелизма данных можно получить, если центральное обрабатывающее ядро ВС построить по принципу массового параллелизма. Наиболее простой способ его структурной организации – соединение множества обрабатывающих устройств (ОУ) друг с другом по топологии решетки – матрицы, в узлах которой помещаются однотипные (однородные) ОУ с близкодействующими связями друг с другом, т.е. а возможностью обмена информацией только с 4 ближайшими соседями.
В современных мультикомпьютерах в качестве
ОУ используются мощные микропроцессоры
с кэш-памятями, представляющие собой
многоразрядные микро-ЭВМ. Можно ли,
сохраняя выигрыш по производительности
по сравнению с однопроцессорной ЭВМ,
снизить капитальные затраты и стоимость
ВС за счет упрощения ОУ. Теоретически
это достижимо, если в качестве ОУ
применить максимально упрощенные
функциональные узлы, но обязательно
обладающие функциональной полнотой.
Каждое из таких ОУ в отдельности не
сможет обрабатывать информацию в
отличии от микропроцессорных ОУ. Однако
в массе таких простых взаимодействующих
ОУ путем внешней их настройки и
маскирования, организации пересылки
информации из одной ОУ в другое с помощью
внешнего микропрограммного управления
возможно параллельное выполнение
множества арифметических и логических
операций. Иными словами, на массе
одинаковых взаимодействующих управляемых
простых функциональных узлов с логической
полнотой можно построить операционную
часть однородного параллельного АЛУ.
Чтобы отличать их от однородных структур
процессорных ячеек, они называются
однородными вычислительными средами
(ОВср).
современных мультикомпьютерах в качестве
ОУ используются мощные микропроцессоры
с кэш-памятями, представляющие собой
многоразрядные микро-ЭВМ. Можно ли,
сохраняя выигрыш по производительности
по сравнению с однопроцессорной ЭВМ,
снизить капитальные затраты и стоимость
ВС за счет упрощения ОУ. Теоретически
это достижимо, если в качестве ОУ
применить максимально упрощенные
функциональные узлы, но обязательно
обладающие функциональной полнотой.
Каждое из таких ОУ в отдельности не
сможет обрабатывать информацию в
отличии от микропроцессорных ОУ. Однако
в массе таких простых взаимодействующих
ОУ путем внешней их настройки и
маскирования, организации пересылки
информации из одной ОУ в другое с помощью
внешнего микропрограммного управления
возможно параллельное выполнение
множества арифметических и логических
операций. Иными словами, на массе
одинаковых взаимодействующих управляемых
простых функциональных узлов с логической
полнотой можно построить операционную
часть однородного параллельного АЛУ.
Чтобы отличать их от однородных структур
процессорных ячеек, они называются
однородными вычислительными средами
(ОВср).
Известна отечественная разработка такой ассоциативной ОВср с матричной топологией, в которой в качестве ОУ применен n-разрядный параллельный функциональный регистр, который на входе и выходе содержит простейшие логические элементы И, И-НЕ для управления записью-чтением, ассоциативным опросом для формирования индикатора совпадения содержимого регистра с входным опросным словом. Назовем его ассоциативный регистр (АсРг). Функциональная организация такой АсОВср аналогична организации рассмотренного выше АППП. Однако с целью повышения производительности модифицирована структурная организация путем совмещения АсЗУ и ОЗУ прежнего АППП в матрице среды и преобразования всех ячеек его ОЗУ в ассоциативные регистры, которые и выполняют теперь роль ОУ. По линиям связи между АсРг (ОУ) в матрице ОВср передаются: 1) единицы переноса в старшие разряды; 2)n-разрядные слова данных, например, для организации накапливающего сложения, причем число параллельно функционирующих накапливающих сумматоров может быть очень большим, не менее, чем число строк или столбцов в матрице. Степень однородности в ОВср весьма высока, так как одинаковы между собой всеn-разрядные АсРг и схемы их разрядов. Схемаi- го разряда параллельного АсРг основана наRSтриггере.
 Каждыйi-разряд АсРг
связан сi-й ячейкой
управляющее матрицы следующими
сигналами:
Каждыйi-разряд АсРг
связан сi-й ячейкой
управляющее матрицы следующими
сигналами:
f
f2
f2 – сигнал разрешения считывания по адресу, как из ячейки ОЗУ,
Считыв. изУМ
y

 2i=Xi*Mi,y1i=Xi*Mi
- маскированные входные сигналы
опроса разряда;
2i=Xi*Mi,y1i=Xi*Mi
- маскированные входные сигналы
опроса разряда;
F
Индикатор
совпадения f1
Запись из УМ Y1i i– выходной сигнал индикации – двоичный
признак срвпадения входной информации
(y1i,y2i)
с содержимым триггера
i– выходной сигнал индикации – двоичный
признак срвпадения входной информации
(y1i,y2i)
с содержимым триггера
( XTi , XTi). Он через управляющую матрицу передается в микропрограммное УУ как
основной аргумент предикатов условных переходов и формируется логической схемой равнозначности:







Fi = Xi Xti = y1i XTi + y2i XTi = Xi Mi XTi + Xi Mi XTi =Xi XTi +XiXTi ,
если Mi= 0, т.е.i-й разряд не маскирован.
На выходе АсРг разрядные индикаторы совпадения Fiобъединяются коньюнктивно:
F=i =1 n
Fiи тем самым
образуется индикатор совпаденияFмаскированногоn-
разрядного входного слова Мх с
содержимым регистра. Функциональная
логическая полнота обеспечивается
совмещением при обработке трех логических
операций: отрицание, поразрядная
равнозначность и коньюнкция индикаторов.
Подобная АсОВср комплексируется с
ведущей ЭВМ как ускоритель обработки
массивов векторов и матриц, ускоритель
выполнения многоместных операций,
например![]() .
.
Такой комплекс фон Неймановской ЭВМ и АсОВср называется ассоциативной вычислительной системой. Причем АсОВср – это только однородная параллельная операционная часть ускоряющего ассоциативного параллельного процессора, имеющего трехслойную структуру.
Структурная схема ассоциативного параллельного процессора
Вед. ЭВМ
Программы обработки массивов данных и
массивы данных заготавливаются ведущей
ЭВМ и загружаются в ОЗУ этого процессора.
Подпрограммы составляют из команд
параллельной обработки массивов, которые
отличаются от команд фон Неймановской
машины тем, что в качестве адресуемых
(в ОЗУ данных) операндов используют не
отдельные слова, а массивы слов,
загружаемых в АсРг матрицы ОУ. Результаты,
выгружаемые из матрицы ОУ в ОЗУ данных
могут быть также массивами результатов
или отдельными словами, как например в
многоместных операциях
![]() .
.
Параллельная обработка содержимых регистров ОУ выполняется многошаговыми командными циклами по микропрограммам команд, хранящимся в памяти микропрограммного устройства управления (МУУ). Применяется принцип общего управления матрицей ОУ, аналогичный принципу SIMD(OKMD) – одиночный поток команд и множественный поток данных, то есть в каждом шаге (такте) исполнение микрокоманды во всех ОУ матрицы одновременно выполняется одна и та же микрооперация. Если необходимо, чтобы некоторые ОУ эту микрооперацию не выполняли, они в этом шаге маскируются. Используя набор стандартных микроопераций типа: опрос, запись, считывание, передача; и маскирование, можно образовать набор базовых микрокоманд, из которых можно составить микропрограммы исполнения множества команд параллельной обработки массивов данных. Используется тот же метод поразрядной ассоциативной обработки массивов, что и в предыдущем АППП. При этом опрос выполняется строками таблиц истинности, а модифицирующая запись в регистры ОУ выполняются правыми выходными частями строк тех же таблиц истинности, которые хранятся в памяти МУУ.
Микропрограммы параллельных операций над массивом данных, загруженным в регистры ОВ среды, составляют на основе следующих базовых микрокоманд:
1) «запись» в регистр ОУ по адресу как в ОЗУ, применяемую чаще всего при загрузке массивов данных в матрицу ОУ из ОЗУ данных;
2) «считывание» из регистра по адресу как в ОЗУ , применяемую чаще всего для выгрузки данных из матрицы ОУ в ОЗУ данных;
3) «опрос» для ассоциативного поиска регистра или группы регистров с таким же содержимым как и опросное слово, применяемую для нахождения регистров, содержимое которых далее модифицируется путем «записи»;
4) «опрос-запись» - основная микрокоманда ассоциативной обработки по таблице истинности, как и в предыдущем АППП;
5) «опрос-считывание»
6) «опрос-передача-запись»;
Последние две микрокоманды используются для организации передачи единиц переноса, поиска пары ячеек: передатчика и приемника и выполнения накапливающего сложения с фиксацией результата в ячейке-приемнике.
Сложение двух n-разрядных чисел, хранящихся в 2 регистрах ОВсреды, выполняется последовательно по разрядам по 4nмикрокоманд типа «опрос-запись», сохраняя модифицируемую единицу переноса в одном триггере третьего регистра. Конечно, это большое замедление по сравнению с параллельным сумматором однопроцессорной ЭВМ. Однако при больших размерах матрицы ОУ эта потеря скорости компенсируется за счет того, что за то же время можно одновременно сложить массу пар операндов, напримерNпар = 1000 при числе регистров в матрицеN= 2048, учитывая, что в третьих регистрах, не вошедших в пары можно хранить доnединиц переноса в каждом их них дляnпар слагаемых.
Сложение двух чисел в ОВ среде можно значительно ускорить по сравнению с АППП и приблизить его скорость к скорости вычислений в неассоциативном вертикальном АЛУ, если регистры ОУ расчленить сигналом настройки на К байтовых зонах. Для этого в микрокоманды вводится дополнительная микрооперация «настройка», по сигналу которой, подаваемому с УМ на ячейку ОВсреды, расчленяется общий индикатор Fячейки на К признаков совпадений в каждом из К байт в отдельности:
F1 = i=0 7 Fi, F2= i=8 15 Fi, ………., Fk= i=n-8 n-1 Fi
Тогда ассоциативный опрос и последующую модифицирующую запись можно выполнять в каждом байтовом регистре. Для ускорения сложения слагаемые загружаются в регистры ОУ по другому способу, который называется «разряд на зону». В байтовой зоне вначале размещаются две группы по 3 бита от 2-х пар слагаемых: Ci(1) bi(1) ai(1) , Ci(2)bi(2) ai(2) на одинi- й разрядный срез.
Д алее
за 4 двухтактные микрокоманды «опрос -
запись» (за 8 тактов) одновременно
опрашиваются всеnразрядных
зон, не обращая внимание на то, что в 1,n-1– й зонах единицы
переноса из младших разрядов еще не
поступили. Опрос выполняется для обоих
их возможных значенийCi=1
иCi=0. После модифицирующей
записи в зоне младших разрядов образуются
2 двухбитных результата для двух пар
слагаемых:
алее
за 4 двухтактные микрокоманды «опрос -
запись» (за 8 тактов) одновременно
опрашиваются всеnразрядных
зон, не обращая внимание на то, что в 1,n-1– й зонах единицы
переноса из младших разрядов еще не
поступили. Опрос выполняется для обоих
их возможных значенийCi=1
иCi=0. После модифицирующей
записи в зоне младших разрядов образуются
2 двухбитных результата для двух пар
слагаемых:
(0 b0 (1) a0 (1) 0; 0 b0 (2) a0 (2)) → (C10 (1) S00 (1) 00; C10 (2) S00 (2) 00),
где
C10(1), C10(2) - значения единиц переноса в 1-й разряд для первой и второй пар соответственно, образованный по заранее известному нулевому значению переноса в младший разряд; а в остальных разрядных зонах – по два двухбитных претендента на результат вi–ом разряде двух пар слагаемых:
(Ci+1,0 (1) Si0 (1) , Ci+1,1(1) Si1 (1); Ci+1,0 (2) Si0 (2), Ci+1,1 (2) Si1 (2)).
Цепь сквозного переноса организуется управляющими ячейками однородной управляющей матрицы, непосредственно связанной с матрицей ОВсреды. По микрооперации «настройка» все первые, третьи, пятые и седьмые триггеры всех nразрядных зон сигналамиf2 (считывание) подсоединяются ко входамnуправляющих ячеек, а выходы последних – сигналамиf1 (запись) ко входам соседних старших разрядных зон. Управляющая матрица последовательно за (n-1) тактов, используя эту заготовленную цепь переноса, анализирует значения единиц переноса и стирает в регистрах зон неправильные разрядные результаты. По всегда правильному значению переноса С10 из младшего в первый разряд выбирается в зоне последнего один из 2-х претендентов С20S10или С21S11 , а другой стирает. Аналогично по оставшемуся значению переноса С20 или С21 во второй разрядной зоне стирается неправильный претендент С30S20 или С31S21 и так далее.
Микропрограмма ускоренного сложения двух чисел выполняется за (n+7) тактов вместо 8nтактов без разбиения на зоны, т.е. быстрее в 7 раз. Все эти процедуры выполняются по микроподпрограмме «опрос-передача-запись» , где подразумевается передача единиц переноса, а по записи в итоге одно из двух слагаемых замещается суммой. Ускорение достигается за счет сокращения в 2 раза максимального числа параллельно обрабатываемых пар слагаемых, так как на две пары требуется 8nбит памяти ОВсреды:Nпар=2Nn/8n=N/4. выигрыш в производительности по сравнению с однопроцессорной ЭВМ:
=(Nпар*Nц)/n+7,
где Nц – число тактов в командном цикле однопроцессорной ЭВМ,
n– разрядность слагаемых.
При N= 2048 ОУ,Nц = 10 тактов иn= 32 выигрыш составит более, чем 100 раз:
= (512*10)/32+7 130 раз.
Ассоциативные ВС эффективны при массовом
параллелизме данных, например при
скалярной обработке массивов векторов
и матриц. Входящий в их состав ассоциативный
параллельный процессор имеет уникальную
архитектуру системы команд, включающую
команды многоместных операций, например
многоместное сложение
![]() с числом слагаемых доNс
= ½N, равному половине
числа ОУ в ОВ среде.
с числом слагаемых доNс
= ½N, равному половине
числа ОУ в ОВ среде.
Она выполняется гораздо быстрее, чем в однопроцессорных ЭВМ, так как микропрограмма такого сложения основана на методе пирамидальной свертки слагаемых. Свертка выполняется путем параллельно-последовательной обработки пар строк и столбцов в матрице слагаемых, вначале загруженных во все регистры ОВ среды. При этом ускоряется накапливающее сложение. Накапливающее параллельное сложение пар слагаемых и промежуточных сумм выполняется шагами. В каждом шаге все незамаскированные ОУ одновременно функционируют по микропрограмме «опрос-передача-запись» и выполняют сложение за (n+7) тактов. Назовем группуnполузон (полу байтов), в которых запоминается результат сложения пары слагаемых приемником, а другую группуnполузон, где хранится второе забываемое слагаемое источником. Вначале в матрицу можно загрузить по принципу «разряд на зону» не более, чемNс =N/2 слагаемых, или образоватьNс =N/4 источников и столько же приемников.
П
/ V окажем
порядок образования промежуточных сумм
в матричной ОВсреде в процессе
пирамидальной свертки на простом примере
приNс = 16 слагаемых.
Обозначим источник , а приемник
замаскированные полузоны -
окажем
порядок образования промежуточных сумм
в матричной ОВсреде в процессе
пирамидальной свертки на простом примере
приNс = 16 слагаемых.
Обозначим источник , а приемник
замаскированные полузоны -
V V V V












/ / / V V V V / / / / V V V V / / / / /











/ V / VVV
/ V














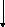









IШагIIшагIIIшагIVшаг
8пар 4 пары 2 пары 1 пара
слагаемых слагаемых слагаемых слагаемых
Требуемое число шагов пирамидальной
свертки на квадратной матрице слагаемых
размером
![]() равно α=2log2*√Nc
равно α=2log2*√Nc
Выигрыш в производительности по сравнению с двухместным накапливающим сложением в однопроцессорной ЭВМ:
![]()
При N=2048 ОУ,Nc= 0,5N= 1024 слагаемых,
Nu= 10 тактов и разрядной сеткеn= 32 выигрыш составил26 раз.
Этот метод ускорения выполнения многоместных операций применим не только в ассоциативных ВС, но и в любой ВС с матричной организацией центрального обрабатывающего ядра. Данный пример показывает, что простая матричная организация с близкодействием (решетка) может приводить к потере производительности из-за необходимости дальних передач операндов. При этом приходится тратить дополнительные такты на их многократную перегрузку из памяти одного ОУ в память другого на дальнем маршруте. Поэтому в матрицу ОУ вводятся дополнительные кольцевые сквозные горизонтальные и вертикальные интерфейсы и тем самым переходят к матрично - торроидальной организации, в которой пересылка через одну промежуточную ячейку ОУ необходима только в случае, если адрес приемника потребует перехода со строки в столбец или наоборот.
В настоящее время создается ассоциативная ВС, в которой матрица ОУ сочетает в себе подматрицы ассоциативных ОВсред и распределенные по ней процессоры фон-Неймана. Топология матрицы ОУ представляет собой совокупность двоичных деревьев, листья которых являются подматрицы асс.ОВср. В узлах деревьев располагаются процессоры фон-Неймана, а корни всех параллельных деревьев объединяются общей системной шиной, к которой подключается ведущая ЭВМ. Тем самым сочетается массово-параллельная ассоциативная обработка массивов данных и параллельная многопроцессорная обработка (свертка) промежуточных результатов
Каждое дерево с листьями реализуется в одной ультрабольшой ИС: САМ 2000 (чип ассоциативной памяти) с числом листьев-ячеек однородной ассоциативной среды, равным 1024-м 32-х разрядным ячейкам.

3.1.3 Конвейерный способ параллельной обработки информации
Конвейерная организация параллельных ЭВМ и вычислительных устройств применяется для повышения производительности при наиболее распространенном частном случае параллелизма данных, когда они поступают на обработку потоком последовательно. Такой поток данных может быть естественным, но внутри ЭВМ он чаще создается искусственно путем последовательной выборки слов данных из памяти.
В
Вх.
Вых.
Входные операнды поступают на первое ОУ1, а выходные результаты образуются на выходе последнего ОУк. Операнды обрабатываются последовательно по мере прохождения через все ОУ конвейера. Такая структурная организация – это частный случай матричной организации (решетки), так как используется одна строка матрицы с направленной передачей информации. Конвейерная обработка основана на разделении исполняемой функции на более мелкие части, называемые ступенями, выделении для каждой из них отдельного обрабатывающего устройства и совмещении во времени исполнения разных частичных ступенчатых функций для разных аргументов функции (операндов). В качестве обрабатывающих устройств могут применяться программируемые микропроцессоры или функциональные блоки в виде непрограммируемых специализированных вычислительных устройств. Первые применяются в конвейерных вычислительных системах, вторые - в структурах современных ЭВМ и микропроцессоров. Каждое из ОУiнастраивается на выполнение одной операции или микрооперации, множество которых должно выполняться последовательно. Поэтому конвейер дает наибольший выигрыш по производительности (ускорение) только на линейных участках программ без ветвлений и при достаточно длинном потоке входных данных.
3.1.3.1 Синхронные и асинхронные линейные конвейеры
Непрограммируемые конвейеры, составленные из аппаратно реализованных неоднородных (неодинаковых) функциональных блоков, широко применяются в современных микропроцессорах для ускорения вычислений и ускорения расшифровки и исполнения естественного непрерывного потока команд в устройствах управления процессорами.
Чаще всего используются синхронные линейные конвейеры с буферными регистрами (БР) между функциональными блоками (ФБ) для хранения промежуточных результатов на случай, если следующий ФБi+1имеет большее время обработки, чем предыдущий ФБi, чтобы исключить потери операндов. Кроме этого для исключения потерь промежуточных операндов необходимо синхронизировать темп их продвижения по конвейеру с работой самого медленного ФБ. Поэтому передача данных от одного ФБ к другому осуществляется только в строго определенные периодические моменты времени в моменты подачи на все ФБ единого общего синхроимпульсаSк. Период между синхроимпульсами называется конвейерным тактом Тк. Очевидно, что с таким же периодом должны подаваться входные операнды на вход конвейера на первый ФБ1. Такое синхронное продвижение можно организовать путем одновременного стробирования приема данных во входные регистры всех ФБ. Поэтому целесообразно между соседними ФБiи ФБi+1 поместить 2 буферных регистра: БРiвых и БРi+1,вх. Первый для исключения потери операндов из-за разной скорости работы блоков ФБi и ФБi+1, а второй для организации их синхронного продвижения на один шаг вправо.
Структура синхронного конвейера
Для выбора конвейерного такта Тк прежде всего необходимо найти наибольшее из

времени обработки данных в ФБ:
Тс max=max{Tci}
Однако этого недостаточно. Нужно также учесть время записи промежуточных результатов в буферные регистры Тбр и максимальную величину «перекоса» между моментами поступления в ФБiсинхроимпульсов Тпк. Последний может возникнуть из-за разных длин электрических цепей передачи импульса на входы ФБi. Тогда конвейерный такт следует вычислить по формуле
Тк1 = Тс мах + Тбр + Тпк. (1)
Однако и этого недостаточно. Если поток входных операндов однородный и времена обработки соседних операндов (в соседних конвейерных тактах) примерно одинаковы во всех ступенях, т.е. (Тci,j+1)min, то можно попользоваться формулой (1).
Если же такой однородности достичь не удается, т.е. возможны ситуации (Тci, j+1)min<<(Тci, j)max, то возможны «гонки» внутри ФБ, при которых в выходной регистр БРiвых может раньше записаться результат (j+1)-го входного операнда, чем предыдущегоj-го, и тем самым сорвется последовательность вычислений. В этом случае рекомендуется применить дополнительную оценку конвейерного такта по формуле:
Тк2 = Тсмах + Тс min, (2)
И окончательно выбрать среднее значение из двух оценок:
Тк=(Тк1+Тк2)/2
Время начальной загрузки конвейера, как интервал времени от начала входного потока данных до появления первого результата на выходе конвейера, равно времени прохождения всего конвейера
Тнз = К*Тк
Несмотря на то, что каждый входной операнд пребывает на обработке в конвейере в течении времени, равного Тнз, обработка потока операндов ускоряется, так как выходные результаты образуются на выходе конвейера с периодом, равным Тк, т.е. значительно чаще, так как Тк<Тнз, а именно в К раз чаще.
Как зависит достигаемое ускорение от длины входного потока операндов. Пусть входной поток передается за Nконвейерных тактов. Это может быть группа изNодиночных операндов,Nпар операндов, илиNтроек и т.д. операндов. Тогда наилучшее время обработки этого входного потока в синхронном конвейере с К ступенями и конвейерным тактом Тк равно
ТNK = (K+(N-1))*Tk,
т.к. К тактов расходуются на начальную загрузку конвейера до появления первого результата, а остальные (N-1) результатов выдаются с периодом Тк.
В однопроцессорной ЭВМ без конвейера время обрабртки составит N*Тнз =NKTk. УскорениеSравно
S=NKTk/(K+(N-1))Tk=NK/K+(N-1)
LimN→S=K. На очень длинных или непрерывных потоках входных операндов вытгрыш равен числу ступеней конвейера. Другая характеристика производительности – это пропускная способность
P=S/KTk=N/Tk(K+(N-1)),
LimN→ P= 1/Tk, т.е. на непрерывном потоке входных операндов пропускная способность равна частоте тактирования конвейера.
Уменьшить требуемую величину конвейерного такта и соответственно повысить пропускную способность можно в синхронизованном асинхронном конвейере. В нем для уменьшения времени простоев ФБ с малым временем обработки на входах ФБ с большим временем обработки помещаются очереди входных операндов в виде регистрового буфера типа FIFO(первый пришел – первый вышел). Данные от одного ФБ к другому передаются сразу же после завершения обработки в предыдущей ступени и без глобальной синхронизации, если очередь на входе следующего ФБ пуста или не переполнена. При переполнении какой-либо очереди об этом сообщается предыдущей ФБ, и он приостанавливает обработку, сохраняя не переданный результат в своем выходном регистре. Эта процедура называется квитированием.
С
Кв.
Орj
Ор,,j+1

l2
очередь

 Тс1 Тс2 Тск
Тс1 Тс2 Тск

Несколько уменьшается время загрузки
Тнз =
![]() i< КТсмах.
Синхронизация применяется только на
входе. Операнды загружаются в конвейер
периодически с конвейерным тактом,
задаваемым стробами приема во входной
регистр ФБ1.
i< КТсмах.
Синхронизация применяется только на
входе. Операнды загружаются в конвейер
периодически с конвейерным тактом,
задаваемым стробами приема во входной
регистр ФБ1.
Подобрана следующая эмпирическая формула для оценки требуемого конвейерного такта:
Ткаmax{min{Tci}, {Tci/li}}, (3)
г де
из второго множества исключается элемент
поTj=min{Tci}, так как на входе ФБjсразу целесообразно выбрать минимальную
длину очереди lj = 1. Отсюда следует, что
длины очередейliимеет
смысл увеличивать только до тех пор,
когда все элементы второго множества
станут меньше, чемtj:
де
из второго множества исключается элемент
поTj=min{Tci}, так как на входе ФБjсразу целесообразно выбрать минимальную
длину очереди lj = 1. Отсюда следует, что
длины очередейliимеет
смысл увеличивать только до тех пор,
когда все элементы второго множества
станут меньше, чемtj:
Tci/li<tj=min{Tci}, i=1,k , ij.
После этого их увеличение уже не приводит к уменьшению Тка и повышению пропускной способности, так как они будут определяться самыми быстрыми из ФБ. Следовательно, если оптимально подобрать длины очередей, то пропускная способность асинхронного конвейера будет определяться самыми быстрыми из ФБ, а не самыми медленными, как это наблюдается в синхронных конвейерах. На основании формулы (3) показано, что спектр требуемых длин очередей целесообразно выбирать по формулам:
 li
Tci/Tk, ij,
i=1,k ,
li
Tci/Tk, ij,
i=1,k ,
где j=arg min {Tci}, a lj=1;
Тк – требуемое значение конвейерного такта, которое должно подчиняться неравенству:
Tkti=min{Tci}.
3.1.3.2 Нелинейные конвейеры
Линейные конвейеры ускоряют обработку линейных ветвей программ при большой степени параллелизма данных. Чаще всего на линейных участках программируется вычисление одной функции. В тоже время в наследуемых последовательных программах, подлежащих распараллеливанию при обработке на современных суперскалярных процессорах, до их появления применялось совмещение на линейных участках последовательного вычисления нескольких функций от аргументов, найденных ранее. В суперскалярных и многопроцессорных системах вычисления на таких участках распараллеливаются на несколько функциональных блоков или процессоров. Однако при высокой степени параллелизма аргументов ускорение обработки возможно и с меньшими затратами аппаратных средств, если совместить параллельно - последовательное вычисление нескольких функций в одном многофункциональном конвейере с использованием одних и тех же его функциональных блоков в режиме разделения времени для выполнения разных этапов формирования разных функций. В этом случае линейная последовательная цепь ФБ не подходит и приходится применять пропуски некоторых ФБ обходными линиями связи и цепи с обратными связями. Такие многофункциональные конвейеры называются нелинейными.
Структура нелинейного конвейера с совмещением вычисления двух функций Х и У.

Для разрешения конфликтов между функциями за владение одним и тем же ФБ и исключения гонок необходимо синтез структуры конвейера (распределение операций между ФБ и проведение связей между ФБ) одновременно верифицировать по таблицам последовательного использования ФБ в процессе вычисления функций, а далее – по временным диаграммам. Например, в приведенной выше структуре конфликты удастся исключить, если таблицы использования ФБ будут следующими
|
NTk |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
1 |
2 |
3 |
4 |
5 |
6 |
|
ФБ1 |
x |
. |
|
, |
|
х |
. |
х |
у |
. |
|
, |
у |
. |
|
ФБ2 |
|
х |
. |
х |
. , |
|
, |
|
|
|
у |
. |
|
, |
|
ФБ3 |
|
|
х |
. |
х |
. , |
х |
. , |
|
у |
. |
у |
. , |
у |

NTk– номер конвейерного такта в процедуре вычисления функции.
Если не совмещать вычисление двух функций, то запуск очередного конвейерного вычисления функции Х на новом наборе аргументов можно было бы выполнять или на 2-ом (обозначено точками), или на 4-м (обозначено запятыми), или на 7-ом такте; а функции У-или на 2-ом, или на 4-ом такте, или 6-ом такте, или позже. Запуск совместного параллельного с Х вычисления функции У можно было бы начинать или на 3-ем, или на 5-ом такте. Однако следующий конвейерный запуск совместного вычисления функций Х и У на новых наборах их входных аргументов можно выполнять только на каждом 7-ом такте от их начальных запусков. Иначе возникают конфликты между ними за владение одними и теми же ФБ. Например, совместный начальный запуск можно выполнять так: Х – на 1-ом такте, У – на 5-ом такте, а далее выполнять их конвейерные запуски в следующей последовательности: Х – на 7-ом, 13-ом, 19-ом, и т.д. тактах; У – на 11-ом, 17-ом, 23-ем и т.д. тактах. Следовательно, минимальный конвейерный такт в данном нелинейном конвейере приходится увеличивать в 6 раз по сравнению с линейным. На это можно пойти при высоком быстродействии элементной базы с целью снижения аппаратной сложности.
3.1.3.3 Конвейеризация вычислений в процессорах
В современных микропроцессорах широко используются арифметические конвейеры. Функциональные узлы, реализующие операции с плавающей запятой, все конвейеризованы. Распределение процедур между ФБ ступеней конвейеров соответствует естественной последовательности фаз в алгоритмах выполнения операций.
Структура линейного синхронного конвейера сложения (вычитания) с плавающей запятой:

ПЭ – подготовительный этап (распаковка чисел с ПЗ на знак, порядок и мантиссу; проверка на нуль всех разрядов порядка по IEEE754 как признак равенства нулю операнда).
ВП – выравнивание порядков (сдвиг мантиссы числа с меньшим порядком вправо).
СМТ – суммирование мантисс, определение знака результата.
ПП – проверка переполнения поля порядка результат.
ЗЭ – заключительный этап (нормализация мантиссы результата сдвигом и проверка потери значимости мантиссы или порядка).
Структура линейного конвейера умножения с плавающей запятой

ПЭ – подготовительный этап (распаковка чисел с ПЗ на знак, порядок и мантиссу; проверка на равенство нулю сомножителей).
СПР – сложение порядков (для смещенных порядков вычитание величины смещения).
ППП – проверка переполнения порядка и потери значимости.
УМТ – умножение мантисс как чисел с фиксированной запятой (округление до длины поля мантиссы).
ЗЭ – заключительный этап (нормализация мантиссы результата, проверка переполнения порядка и потери значимости).
Подвергаются конвейеризации также функциональные узлы целочисленного умножения и деления. В современных микропроцессорах эти операции выполняются в однотактных (одношаговых) узлах сверхпараллельной аппаратной избыточной арифметики. Широко применяются матричные умножители и делители, построенные на матричном массиве одноразрядных сумматоров, соединенных цепями переносов и имитирующих процедуру умножения в столбик. К сожалению, в большинстве вариантов матричных умножителей (делителей) требуется большая глубина массива сумматоров (число строк матрицы). Так как матричный умножитель – это многослойная комбинационная схема, задержка ее сравнительно велика. Из-за этого приходится увеличивать длительность такта между соседними парами входных сомножителей, что приводит к снижению производительности. Если схему умножителя разрезать на несколько слоев и между слоями поместить буферные регистры, то образуется многоступенчатый конвейер, который при параллелизме данных (длинном потоке пар сомножителей) позволит уменьшить такт между соседними их парами, так как он станет конвейерным. Последний, как известно, при этом выбирается по формуле
Tk‘ =max{Tci}<![]() ,
где Тсi– задержкаi-го
слоя комбинационной схемы матричного
умножителя.
,
где Тсi– задержкаi-го
слоя комбинационной схемы матричного
умножителя.
Конечно, в конвейерном такте нужно учесть еще и задержку буферных регистров:
Тк = Тк’ + Тбр = Тсmax+ Тбр.
Однако при числе ступеней в конвейерном умножителе, равном К, сомножители могут подаваться на вход с интервалом в К раз меньшим, чем в случае отсутствия конвейеризации. Настолько же повысится темп появления результатов на выходе.
Схема конвейеризованного матричного умножителя Брауна для четырехразрядных сомножителей
b0
b1
b2
b3
P7 P6 P5 P4 P3 P2 P1 P0
ПС – полусумматор, имеющий два входа для слагаемых (используется в младших разрядах, где перенос С-1= 0).
СМ – полный сумматор, имеющий все необходимые три входа, в том числе для единицы переноса из соседнего младшего разряда.








- условные обозначения триггеров – защелок соответственно первого, второго, третьего и четвертого буферных регистров (БР) между соседними ступенями конвейера. Так как ступени представляют собой параллельно включенные комбинационные схемы с разными величинами задержек по разным входам, для синхронизации и продвижения результатов предыдущих ступеней в следующие без потерь и гонок целесообразно применить БР с двойной памятью, где каждый разряд «триггер - защелка» - это два последовательно соединенных триггера, управляемых по записи и перезаписи одним синхроимпульсом. Вначале по переднему фронту импульса стробируется запись в первый триггер результатов логической обработки на предыдущей ступени, где обработка началась по заднему фронту предыдущего синхроимпульса. Затем по заднему фронту импульса содержимое первого триггера переписывается во второй на вход следующей ступени, где начинается логическая обработка. Тем самым исключаются гонки между логическими цепями разной длины в каждой из ступеней конвейера.
Заметим, что такой конвейерный умножитель можно применить в качестве функционального блока на пятой ступени описанного выше конвейерного умножителя с плавающей запятой. Это позволит удлинить последний на число ступеней этого конвейера и выровнять времена обработки Tciво всех образовавшихся ступенях умножителя с плавающей запятой. При реальной длине разрядной сетки сомножителей, равнойn=32; 64 разряда, расходы оборудования на буферные регистры очень усложняют схему. Тогда идут на компромисс, и число ступеней конвейера уменьшают вдвое – втрое по сравнению с разрядностью.
С целью дальнейшего повышения производительности в операционной части процессора может применяться множество параллельных конвейеров, обрабатывающих как согласные, так и встречные, и ортогональные потоки данных. Процессор, построенный на параллельных синхронных конвейерах, называется систолическим, а на параллельных асинхронных конвейерах – волновым.