

Практикум в STATISTICA
.pdfПрактикум в STATISTICA
Санкт – Петербург 2014

Исследование эффективности прививок
Введение: общий обзор методов
Многие задачи медицины могут быть решены с помощью статистики и все модули системы STATISTICA, так или иначе, используются в медицине. Прежде всего, в медицине статистика используется в задачах, связанных с выборочными обследованиями, с проверкой эффективности различных доз различных лекарств, диагностика заболеваний на основании проводимых медицинских анализов, выявление сезонных факторов и скрытых периодичностей (например, определение того, как рождаемость зависит от месяца или дня недели), оценка интенсивности вызовов скорой помощи в зависимости от времени суток, прогнозирование выздоровления больных, оценка зависимостей между различными переменными, например, как состояние зубов детей связано со способом кормления (кормление грудью или искусственное кормление) и т.д.
Ситуация осложняется тем, что часто исследователь располагает неполными данными (наблюдения могут быть цензурированными, например, пациент переведен в другой госпиталь или выписан и связь с ним утеряна). Для анализа неполных наблюдений применяются специальные статистические методы, реализованные в модуле Анализ выживаемости.
Кроме того, данные могут содержать много пропусков. Методы обработки пропущенных значений доступны в любом модуле системы.
Если анализируются данные небольшого объема и нет никаких обоснованных предположений о форме распределения наблюдаемых величин, применяются методы, реализованные в модуле
Непараметрическая статистика.
Если нужно провести классификацию больных, описываемых несколькими признаками, то следует использовать модуль Дискриминантный анализ. Однако методы дискриминантного анализа "работают", если переменные измерены в достаточно богатой шкале, например, интервальной. Если предикторы измерены в номинальной или порядковой шкале, то используют методы модуля Деревья классификации.
Для задач прогнозирования выздоровления пациентов применяются методы Множественной регрессии. Однако во многих ситуациях приходится иметь дело с кусочно линейными моделями, т.к. до определенного критического момента (например, спустя 23 дня после операции) адекватна одна линейная модель и хороший прогноз дает одно подмножество предикторов. По прошествии критического момента, модель меняется и меняется множество предикторов, позволяющих строить прогноз. Методы модуля Нелинейное оценивание содержат необходимый инструментарий для анализа таких задач.

Специальные методы анализа многовходовых таблиц сопряженности реализованы в модулях Логлинейный анализ и Анализ соответствий.
Широкий круг задач может быть решен в модуле Основные статистики и таблицы.
Исследование эффективности прививок
Рассмотрим следующий пример анализа в модуле Основные статистики и таблицы.
Предположим, вы хотите исследовать, как связаны прививка против определенной болезни и заболеваемость этой болезнью. Случайным образом вы выбираете истории болезней из архива и создаете файл данных, подобный тому, как показан ниже:
Рис.1
Вы хотите установить, как связаны два признака (и связаны ли они вообще): прививка и заболеваемость.
На время оставим в стороне 2 важных вопроса:
Каким образом отобраны истории болезней (не было ли здесь какого-то искусственного подбора, чтобы создать нужный эффект)?
Сколько нужно отобрать историй болезни, чтобы получить статистически значимый результат?
Вернемся к примеру. Заметим, что изучаемые переменные: прививка и заболеваемость являются категориальными, т.к. принимают только 2 значения: да или нет. Субъект попадает в одну из двух категорий.

Такие переменные сильно отличаются, например, от переменных, измеряющих температуру или давление, уровень холестерина, которые измерены в более богатой шкале - интервальной шкале (грубо говоря, являются непрерывными).
Для изучения связей или зависимостей между категориальными переменными разработан специальный аппарат – таблицы сопряженности, к построению которых в системе STATISTICA мы сейчас перейдем.
Отметим, что в файле содержится дополнительная информация: пол, год рождения, дата прививки и, если обследуемый заболел, то также приводится дата заболевания. Эта информация полезна для последующего, углубленного анализа данных, здесь она не используется.
Построение таблицы сопряженности
Идея таблиц сопряженности очень проста. Трудно придумать что-либо более простое и естественное, чем эти таблицы.
В данном примере будет построена таблица 2 на 2 или, как ее еще иногда называют, четырехклеточная таблица, т.к. в ней имеется всего 4 комбинации (да, да), (да, нет), (нет, нет), (нет, да) значений переменных: ПРИВИВКА, ЗАБОЛЕЛ.
Откройте стартовую панель модуля.
Рис.2
В стартовой панели модуля выберите процедуру Таблицы сопряженности,
флагов и заголовков.
Нажмите кнопку ОК, затем в диалоговом окне Задайте таблицы нажмите кнопку Задать таблицы.

Рис.3
Выберите переменные, как показано ниже:
Рис.4
Всего можно выбрать до 6 списков группирующих переменных (т.е. тех переменных, которые задают разбиение пациентов на группы), нам достаточно выбрать только 2 переменные. Нажмите кнопку ОК. Вы снова вернетесь в диалоговое окно задания таблицы, где следует нажать кнопку
Коды.
В появившемся окне, где задаются коды для группирующих факторов, нажмите кнопку Выбрать все.
Рис.5

Окно Задайте таблицы теперь выглядит следующим образом:
Рис.6
Нажмите кнопку ОК. Теперь, в открывшемся диалоговом окне Результаты кросстабуляции, вы можете посмотреть построенную таблицу.
Рис.7
Нажмите кнопку Просмотреть итоговые таблицы и вы увидите нужную таблицу сопряженности. Немного поупражнявшись, вы научитесь строить таблицы сопряженности в системе за несколько минут.
Эта таблица содержит в сжатом виде всю информацию, позволяющую оценить зависимость между категориальными переменными: ПРИВИВКА, ЗАБОЛЕЛ.

Рис.8
Посмотрев на таблицу, вы видите, например, что 1 человек из числа обследуемых – не имел прививок и не заболел (левая верхняя клетка), 3 человека не имели прививок и заболели (следующая клетка в первой строке), 4 человека имели прививки и не заболели (первая клетка во второй строке), 2 человека имели прививки и заболели (вторая клетка во второй строке).
В нижней строке записаны суммы значений по столбцам. В крайнем правом столбце – суммы значений по строкам. Эти значения иногда называют маргинальными или краевыми, т.к. они находятся на краях таблицы.
Графическое представление таблиц сопряженности
Посмотрим теперь на графическое представление данной таблицы. Нажмите кнопку 3М гистограммы и вы увидите гистограмму частот. Это 3-х мерная гистограмма частот.
Рис.9
Нажмите кнопку Категоризованные гистограммы, следующие графики появятся на экране.
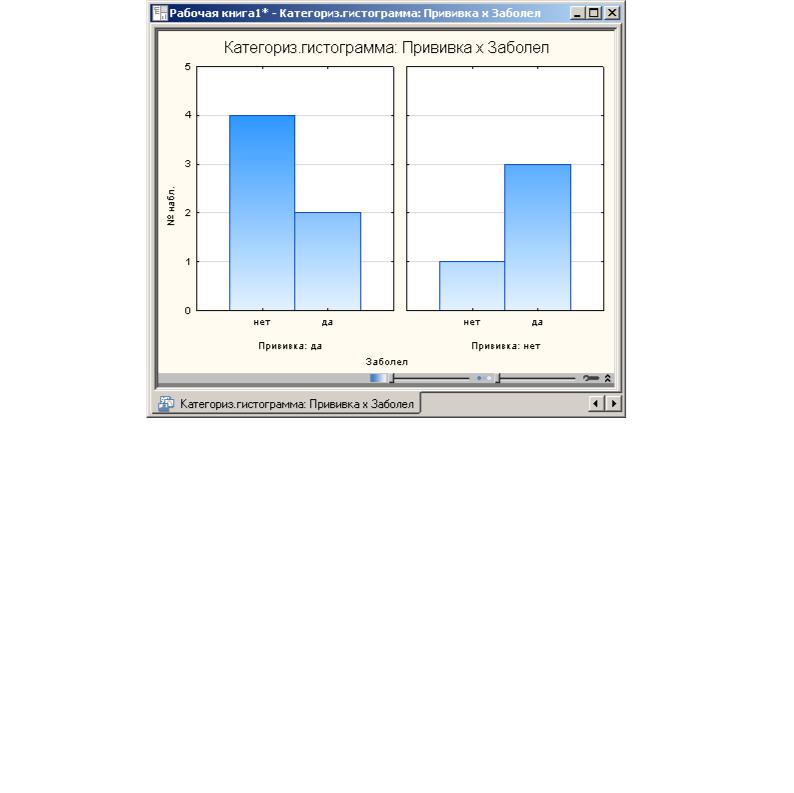
Рис.10
Каждый из этих графиков по-своему удобен и полезен, и мы сейчас продемонстрируем это.
Во втором, категоризованном графике, как вы видите, все обследуемые разбиты на две категории (группы): ПРИВИВКА - нет, ПРИВИВКА – да. Из графика видно, что число заболевших в группе, несделавших прививки, больше числа заболевших в группе, сделавших прививки.
Если прививка не сделана, то число незаболевших 1, а число заболевших 3. Если прививка сделана, то число незаболевших 4, число заболевших 2.
Посмотрим еще один график - график взаимодействий. Нажмите кнопку
График взаимодействий частот. Вы увидите следующий график:
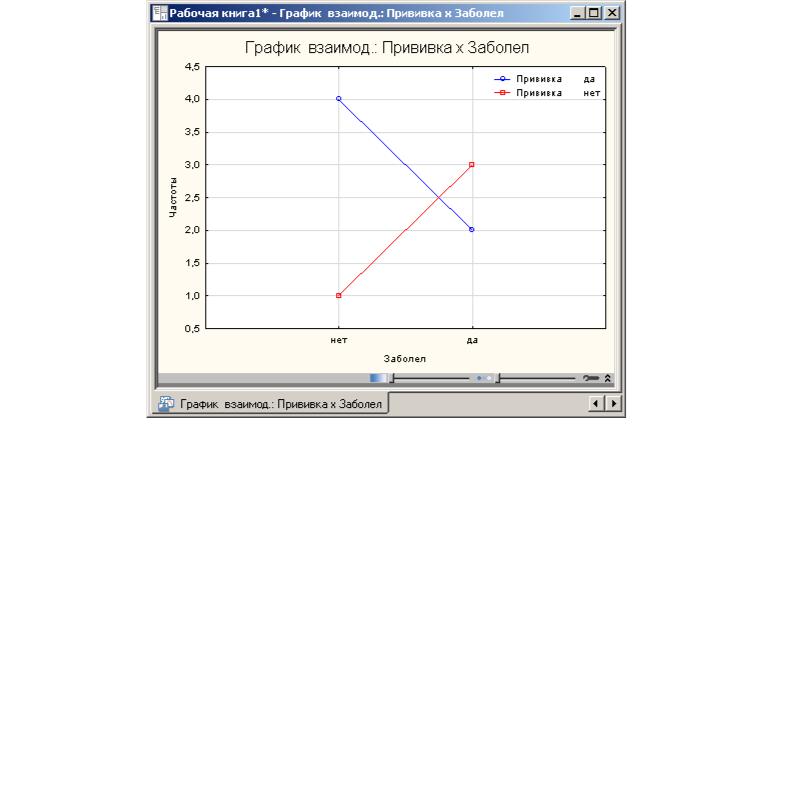
Рис.11
Из графиков также видно, что число людей, сделавших прививки и заболевших, меньше, числа людей, не сделавших прививки и заболевших. Прямые на графике пересекаются, следовательно, факторы взаимодействуют между собой.
Итак, проявление зависимости между признаками на графике взаимодействий – пересечение прямых.
Если бы прямые были параллельны, мы бы сказали, что взаимодействие между факторами отсутствует.
Итак, графики показали зависимость между факторами.
Можно ли сделать какой-либо статистический вывод о зависимости или связи между признаками?
http://statsoft.ru/solutions/ExamplesBase/branches/detail.php?ELEMENT_ID=883#introduction

Анализ выживаемости
1. Сравнение выживаемости в двух и более группах
Обзор и файл данных
Следующие четыре примера основаны на данных Crowley and Hu (1977) о выживаемости пациентов после операции по трансплантации сердца. Данные содержатся в файле Heart.sta.
Откройте этот файл данных через меню Файл - Открыть; скорее всего, он будет расположен в каталоге /Examples/Datasets системы STATISTICA.
Первые шесть переменных в этом множестве данных есть даты, точнее, даты трансплантации сердца (в следующей последовательности: месяц-день-год), и даты, когда соответствующий пациент либо умер, либо был изъят из наблюдения (иными словами, цензурирован, например, с пациентом была утрачена связь).
Переменная Цензурировано - Censored является индикатором цензурирования с кодом, который показывает, является соответствующее наблюдение завершенным или цензурированным (0-завершенное; 1-цензурированное). Переменная Больница - Hospital представляет собой фиктивную группирующую переменную, которая показывает, к какой из трех больниц относится пациент.
Вместо записи данных в шести переменных (месяц, день и год начала наблюдения и месяц, день и год окончания наблюдения) мы можем ввести продолжительность жизни с помощью одной переменной или ввести даты начала и окончания как значения двух различных переменных.