

Senikov_POE 3к
.pdfгде: au – вес u-го частного параметра оптимизации, yui – результат измерения u-го параметра оптимизации в i-м опыте, yu0 – «идеальное» значение u-го параметра оптимизации.
Если в некотором опыте все частные параметры оптимизации совпадут с идеалом (выражение в круглых скобках), то Yi станет равным нулю. Это и есть то значение, к которому нужно стремиться.
Вес аu вводится для устранения нивелировки частных откликов. Для нахождения значений весов можно воспользоваться экспертными оценками.
Способ 3. Шкала желательности Харрингтона
Назначение шкалы Харрингтона – установление соответствия между физическими и психологическими параметрами. Здесь под физическими параметрами понимаются всевозможные частные параметры оптимизации, характеризующие функционирование исследуемого объекта: технические, эстетические, статистические параметры. Под психологическими параметрами понимаются чисто субъективные оценки экспериментатора желательности того или иного значения отклика. Чтобы получить шкалу желательности, удобно пользоваться готовыми таблицами соответствии между отношениями предпочтения в эмпирической и числовой системах (см.
табл. 2.1).
Таблица 2.1. Стандартные отметки на шкале желательности
Желательность |
Отметки на шкале желательности |
Очень хорошо |
1,00-0,80 |
Хорошо |
0,80-0,63 |
Удовлетворительно |
0,63-0,37 |
Плохо |
0,37-0,20 |
Очень плохо |
0,20-0,00 |
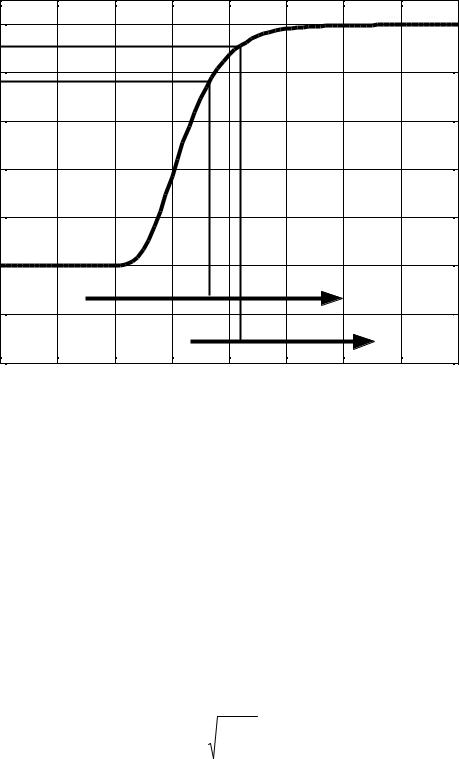
В таблице 2.1 представлены числа, соответствующие некоторым точкам кри-
вой (см. рис. 2.1), которая задается уравнением d = e e y .
11
1 |
|
|
|
|
|
|
|
|
0.8 |
|
|
|
|
|
|
|
|
0.6 |
|
|
|
|
|
|
|
|
0.4 |
|
|
|
|
|
|
|
|
d |
|
|
|
|
|
|
|
|
0.2 |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
100% |
|
|
-0.2 |
|
|
|
0 |
|
|
1000 |
|
|
|
|
|
|
|
|
||
-0.4 |
-4 |
-2 |
0 |
2 |
4 |
6 |
8 |
10 |
-6 |
||||||||
|
|
|
|
y |
|
|
|
|
Рис. 2.1. Функция желательности |
|
|
|
|
|
|
||
На оси ординат нанесены значения желательности, изменяющиеся от 0 до 1. По оси абсцисс указаны значения параметра оптимизации, записанные в условном масштабе. За начало отсчета 0 по этой оси выбрано значение, соответствующее желательности 0,37. Выбор именно этой точки связано с тем, что она является точкой перегиба кривой, что в свою очередь создает определенные удобства при вычислениях.
Кривую желательности обычно используют как номограмму.
После выбора шкалы желательности и преобразования частных параметров оптимизации в частные функции желательности приступают к построению обобщенной функции желательности. Обобщают по формуле
n
D= n du ,
u=1
где D – обобщенная желательность, du - частные желательности.
Способ задания обобщенной функции желательности таков, что если хотя бы одна желательность du = 0, то обобщенная функция будет равна нулю. С другой стороны D=1 только тогда, когда du = 1. Обобщенная функция весьма чувствительна к малым значениям частных желательностей.
Способ задания базовых отметок шкалы желательности, представленный в табл.2.1, один и тот же, как и для частных, так и для обобщенных желательностей. Обобщенная функция желательности является некоторым абстрактным построени-
12
ем, но она обладает такими важными свойствами, как адекватность, статистическая чувствительность, эффективность, причем эти свойства не ниже, чем таковые для любого технологического показателя, им соответствующего. Обобщенная функция желательности является количественным, однозначным, единым и универсальным показателем качества исследуемого объекта и, обладая такими свойствами, как адекватность, эффективность, статистическая чувствительность, и поэтому может использоваться в качестве критерия оптимизации.
3. ФАКТОРЫ
3.1. Количество факторов
Каждый фактор может принимать в опыте одно из нескольких дискретных значений – уровней. Все сочетания уровней факторов составляют множество различных состояний объекта исследования, что, одновременно, составляет число возможных опытов эксперимента. Объекты исследования обычно обладают большой сложностью. Так, простая система с пятью факторами на четырех уровнях имеет 1024 состояний, а для десяти факторов на четырех уровнях их уже 1048576, что вызывает сомнения в возможности проведения такого эксперимента. Отсюда возникает проблема выбора количества факторов и их уровней, необходимых для достижения цели исследования [2].
После выбора объекта исследования и параметра оптимизации нужно рассмотреть все факторы, которые могут влиять на процесс. Неучтенные и неконтролируемые экспериментатором факторы могут значительно увеличить ошибку опыта. При поддержании этих факторов на фиксированных уровнях может быть получено ложное представление об оптимуме, т.к. нет гарантии, что полученный уровень является оптимальным. Таким образом, чем больше факторов рассматривается при проведении эксперимента, тем меньше ошибка эксперимента. С другой стороны большое число факторов увеличивает число опытов
N = pk, |
(3.1) |
где: р – число уровней, k – число факторов.
Таким образом, с одной стороны, для уменьшения ошибки эксперимента количество факторов должно быть максимально, с другой стороны, с увеличением количества факторов в геометрической прогрессии растет число опытов. Итак, выбор факторов является весьма существенным, т.к. от этого зависит успех эксперимента.
3.2. Характеристика факторов
Факторы могут быть непрерывными или дискретными. При планировании эксперимента используют только дискретные значения факторов.
Факторы могут быть количественные и качественные. Качественные факторы: различные вещества, технологические способы, приборы, исполнители и т.п.
13

При планировании эксперимента с качественными факторами производится кодирование с использованием соответствующих шкал.
Фактор считается заданным, если указаны его название и область определения. В выбранной области определения он может иметь несколько значений (уровни фактора), которые соответствуют числу его различных состояний.
3.3. Формализация процесса отбора факторов
Для отбора значимых факторов используются следующие методы:
априорная информация: литература, специалисты;
метод экспертных оценок: априорное ранжирование;
предварительные и отсеивающие эксперименты.
3.4. Кодирование факторов
В большинстве случаев желаемая математическая модель представляет собой уравнение регрессии, то есть геометрическое место точек математических ожиданий условных распределений целевой функции
N |
N |
N |
|
|
y= α0 + αixi |
+ αij xi xj |
+ αii xi |
2 +... , |
( 3.2) |
i=1 |
i j |
i=1 |
|
|
где: α0 ,α1 ,...,αN ,α12 ,... - коэффициенты регрессионной модели, x1,…xK – натуральные в своей размерности значения факторов.
Получить регрессионную модель с натуральными значениями факторов сразу в большинстве случаев не представляется возможным. Поэтому вначале получают полином с кодированными безразмерными значениями факторов
N |
|
N |
|
|
|
N |
|
|
||
y= a0 + ai |
|
i + aij |
|
i |
|
j + aii |
|
i |
2 +..., |
(3.3) |
x |
x |
x |
x |
|||||||
i=1 |
|
i j |
|
|
|
i=1 |
|
|
||
где: x1,...,xk - кодированные (безразмерные) значения факторов, a0, a1,… - коэффициенты, значения которых в общем случае отличны от значений аналогичных коэффициентов модели (3.2).
Кодированные значения факторов определяются соотношением
|
j = |
xj xj0 |
, |
(3.4) |
|
x |
|||||
|
|||||
|
|
λj |
|
||
где: xj – натуральное текущее значение j-го фактора; xj0 – натуральное значение нулевого уровня j-го фактора; λj – половина размаха варьирования j-го фактора, называется обычно интервалом варьирования; j – номер фактора (j=1…k).
Уровень j-го фактора, соответствующий большему значению xjВ, называют верхним, а соответствующий меньшему значению xjН – нижним. Посредине между ними размещен основной (нулевой или базовый) уровень (см. рис.3.1).
14
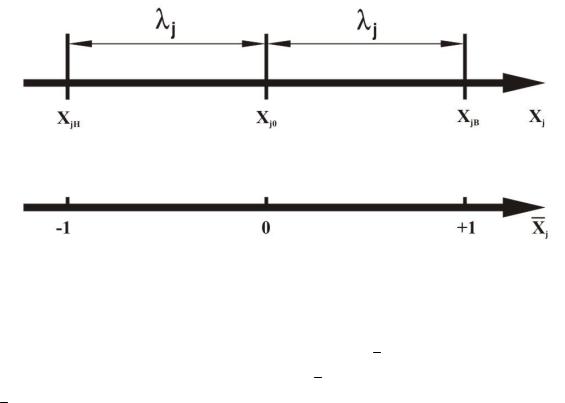
Рис.3.1. Уровни варьирования фактора xj
При кодировании уровней факторов с использованием выражения (4.4) план эксперимента не зависит от физики процесса (явления). На практике стремятся уровни варьирования выбрать так, чтобы получить xj = ±1. Это упрощает эксперимент и обработку его результатов. Значение xj = 1 соответствует нижнему, а значение xj = +1 - верхнему уровням варьирования (см. рис.4.1). В дальнейшем будут рассмотрены эксперименты, в которых кодированные уровни факторов принимают значения -1 или +1.
3.5. Выбор нулевого (основного) уровня
Выбор нулевой точки эквивалентен определению исходного состояния объекта исследования. Для оптимизации желательно, чтобы нулевая точка была в области оптимума или как можно ближе к ней, что ускоряет поиск оптимальных решений. За нулевую также можно принять такую точку, которой соответствует наилучшее значение параметра оптимизации, установленного в результате формализации априорной информации. Еще один вариант: предположим, в некоторой задаче фактор (температура) мог изменяться от 140 до 180 0С. Естественно, за нулевой уровень было принято среднее значение фактора, соответствующее 160 0С.
3.6. Выбор интервалов варьирования факторов
Под интервалом варьирования фактора подразумевается разность между двумя его значениями, принятая за единицу при кодировании (см. рис. 3.1). Интервалы варьирования выбирают с учетом того, что значения факторов, соответствующие уровням +1 и –1, должны быть достаточно отличимы от значения, соответствующему нулевому уровню. Поэтому во всех случаях величина интервала варьирования должна быть больше удвоенной квадратичной ошибки фиксирования данного фактора. Очень большой интервал варьирования нежелателен – это может привести к снижению эффективности поиска оптимума. А очень малый интервал варьирования уменьшает область эксперимента, что замедляет поиск оптимума. При выборе ин-
15

тервала варьирования целесообразно учитывать, если это возможно, число уровней варьирования факторов в области эксперимента. От числа уровней зависят объем эксперимента (3.1) и эффективность оптимизации.
Минимальное число уровней – 2: верхний (+1) и нижний (-1) уровни. Два уровня используются в отсеивающих экспериментах, на стадии движения в область оптимума и при описании объекта исследования линейными моделями. С увеличением числа уровней (моделей второго и более) порядка повышается чувствительность эксперимента, но одновременно возрастает число опытов. Здесь необходимы факторы на 3, 4 или 5 уровнях. Наличие нечетных уровней указывает на проведение опытов в нулевых (основных) уровнях.
Вкаждом отдельном случае число уровней выбирают с учетом условий задачи
ипредполагаемых методов планирования эксперимента. Здесь необходимо учитывать наличие качественных и дискретных факторов. При получении моделей второго порядка качественные факторы не применимы, т. к. они не имеют ясного физического смысла для нулевого уровня. Для дискретных факторов часто применяют преобразование измерительных шкал, чтобы обеспечить фиксацию значений факторов на всех уровнях.
4. РЕГРЕССИОННЫЙ АНАЛИЗ КАК ОСНОВА ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА
Регрессия – статистическая зависимость условного математического ожидания случайной величины от случайного вектора (случайной величины).
Регрессионный анализ – раздел математической статистики, изучающий зависимость между случайными величинами и возможностью её функционального представления по данной выборке.
Регрессионная функция – функция от случайного вектора, дающая для некоторой случайной величины наилучшую оценку в смысле наименьших квадратов [7].
4.1. Уравнение регрессии
Описание исследуемого объекта нельзя получить в виде точной формулы функции, справедливой во всем диапазоне существования аргументов. Оно может быть лишь приближенным и на небольшом участке в окрестностях выбранной базовой точки. Аппроксимация искомой математической зависимости представляет собой некоторый полином - отрезок ряда Тейлора, в который разлагается неизвестная зависимость:
n |
n |
n |
|
|
y= f(x1,x2 ,...xn )= a0 + aixi |
+ aij xixj |
+ aii xi |
2 +... |
(4.1) |
i=1 |
i j |
i=1 |
|
|
где:
ai |
= |
f |
| |
;aij |
= |
2 f |
| |
;aii |
= |
2 f |
| . |
|
|
|
|
||||||||||
|
|
xi x=0 |
|
|
xi xj x=0 |
|
|
x |
2 x=0 |
|||
|
|
|
|
|
|
|
|
|
|
i |
|
|
16
В силу наличия неуправляемых и даже неконтролируемых факторов хi изменение величины y носит случайный характер, а потому уравнение (4.1) не дает нам точной связи между входом и выходом объекта и является лишь условным математическим ожиданием случайной величины y, т.е. уравнением регрессии.
Чтобы найти коэффициенты уравнения регрессии по результатам экспериментов в N точках факторного пространства (что является типичной задачей регрессионного анализа), необходимо выполнение следующих предпосылок:
Результаты наблюдений y1, y2,...,yn выходной величины в N точках факторного пространства представляют собой независимые, нормально распределенные случайные величины.
Выборочные дисперсии опытов однородны, т.е. статистически неразличимы. Это требование означает независимость выборочной дисперсии от местоположения точки факторного пространства, в которой проводится конкретный опыт.
Факторы x1, x2,...,xn измеряются с ошибкой много меньшей, чем величина возможного отклонения параметра оптимизации под влиянием неучтенных факторов.
Тогда задача отыскания коэффициентов уравнения регрессии сводится к решению системы так называемых нормальных уравнений:
N |
~ |
|
|
N |
d |
|
|
|
|
) |
2 |
= (yg |
aixig ) |
2 |
min , |
(4.2) |
|
(yg yg |
|
|
||||||
g=1 |
|
|
|
g=1 |
i=0 |
|
|
|
где: yg- экспериментальные значения параметра оптимизации, полученные в g-ой точке факторного пространства; ~yg - значение выходного параметра, найденные
по уравнению регрессии в тех же точках; d - количество членов в уравнении регрессии.
Выражение (4.2) является основным критерием проверки правильности найденного уравнения регрессии.
Чтобы система нормальных уравнений, которая может быть представлена в виде матрицы, имела единственное решение, необходимо, чтобы матрица была невырожденной, т.е. чтобы вектор-столбцы были линейно-независимы. Чтобы величины коэффициентов уравнения регрессии не зависели от числа членов матрицы, нужно на нее наложить дополнительное условие ортогональности вектор столбцов.
Простейшим примером регрессионной модели является уравнение парной корреляции, где на целевую функцию воздействует один фактор. На практике в реальном производстве на целевую функцию воздействуют много факторов и искомое уравнение регрессии становится многомерным.
4.2. Примеры регрессионных моделей
17
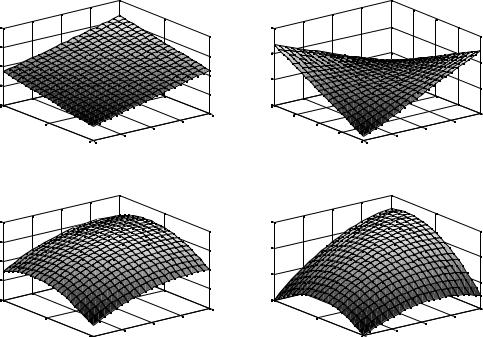
Модели первого порядка без взаимодействий: y = a0 + a1x1,
y = a0 + a1x1 + a2x2, (см. рис.4.1A) y = a0 + a1x1 + a2x2 + a3x3.
Модели первого порядка с взаимодействиями: y = a0 + a1x1 + a2x2 + a12x1x2, (см. рис.4.1B)
y = a0 + a1x1 + a2x2 + a3x3 + a12x1x2 + a13x1x3 + a23x2x3,
y = a0 + a1x1 + a2x2 + a3x3 + a12x1x2 + a13x1x3 + a23x2x3 + a123x1x2x3.
Модели второго порядка без взаимодействий: y = a0 + a1x1 + a11x21,
y = a0 + a1x1 + a2x2 + a11x21 + a22x22, (см. рис.4.1C) y = a0 + a1x1 + a2x2 + a3x3 + a11x21 + a22x22 + a33x23.
Модели второго порядка с взаимодействиями
y = a0 + a1x1 + a2x2 + a12x1x2 + a11x21 + a22x22, (см. рис.4.1.D)
y = a0 + a1x1 + a2x2 + a3x3 + a12x1x2 + a13x1x3 + a23x2x3 + a123x1x2x3 + a11x21 + a22x22 +
a33x23.
18
|
A |
|
B |
4 |
|
10 |
|
3 |
|
5 |
|
|
|
|
|
2 |
|
|
|
1 |
|
0 |
|
|
|
|
|
0 |
|
-5 |
|
1 |
|
1 |
|
|
1 |
0.5 |
1 |
0 |
0.5 |
0 |
0.5 |
|
0 |
-0.5 |
0 |
|
-0.5 |
-0.5 |
|
-1 |
-1 |
-1 |
-1 |
|
C |
|
D |
3 |
|
3 |
|
2 |
|
2 |
|
|
|
|
|
1 |
|
|
|
0 |
|
1 |
|
|
|
|
|
-1 |
|
0 |
|
1 |
1 |
1 |
1 |
|
|
||
0 |
0.5 |
0 |
0.5 |
|
0 |
|
0 |
-1 |
-0.5 |
-1 |
-0.5 |
-1 |
-1 |
Рис.4.1. Графики функций различных регрессионных моделей.
4.3. Проверка значимости коэффициентов регрессии
Проверить значимость коэффициента регрессии означает дать ответ на вопрос, за счет чего коэффициент оказался отличным от нуля – за счет случайных причин (ограниченного числа опытов), либо за счет того, что это объективно имеет место.
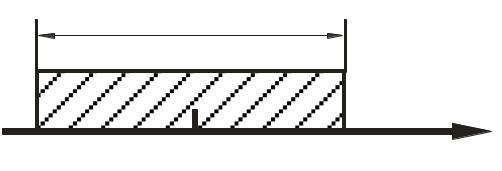
Реализуется обычно следующий алгоритм. Для рассматриваемого коэффициента определяется доверительный интервал (интервальная оценка) Iγ(a), соответствующий доверительной вероятности γ:
Iγ(a) = {аH; aB},
где: аH, aB – границы интервала.
Далее уточняется вопрос, попадает ли в построенный доверительный интервал
Iγ(a) точка a=0 (см. рис.4.2)
19
|
IY(a) |
|
|
аН |
а* |
аВ |
КОЭФФИЦИЕНТ а |
Рис.4.2. Доверительный интервал для коэффициента а: а* - точечная оценка. |
|||
Если это происходит, то нет оснований точечную оценку а*, полученную при статистической обработке, считать значимой, ибо отличной от нуля она могла оказаться за счет ограниченности числа опытов, погрешностей эксперимента и других случайных причин. Следовательно, такой коэффициент (слагаемое с коэффициентом а*) не следует включать в формируемую математическую модель.
5. ПЛАНЫ ЭКСПЕРИМЕНТОВ ТИПА 2K и 2(K-L)
Работу по планированию эксперимента начинают со сбора априорной информации: параметр оптимизации, факторы, наилучшие условия ведения исследования, характер поверхности отклика и т.д. Источники априорной информации: специальная литература, опрос специалистов, результаты однофакторных экспериментов. На основе анализа априорной информации делается выбор экспериментальной области факторного пространства, который заключается в выборе основного (нулевого) уровня и интервалов варьирования факторов. Основной уровень является исходной точкой для построения плана эксперимента, а интервалы варьирования определяют расстояния по осям координат от верхнего и нижнего уровней до основного уровня. При планировании эксперимента значения факторов кодируются путем линейного преобразования координат факторного пространства с переносом начала координат в нулевую точку и выбором масштабов по осям в единицах интервалов варьирования факторов. Используют здесь соотношение (3.4).
5.1. Полный факторный эксперимент типа 2K
Первый этап планирования эксперимента для получения линейной модели основан на варьировании на двух уровнях. В этом случае, при известном числе факторов, можно найти число опытов, необходимое для реализации всех возможных сочетаний уровней факторов (формула 3.1). Эксперимент, в котором реализуются все возможные сочетания уровней факторов, называется полным факторным экспериментом (ПФЭ). Если число уровней факторов равно двум, то имеем ПФЭ типа 2K [3]. Условия эксперимента удобно записывать в виде таблицы, которую называют матрицей планирования эксперимента (табл.5.1).
Таблица 5.1. Матрица планирования эксперимента 22
20