

Компьютерный практикум по статистике
.pdf∙под доверительными интервалами — числовые значения t-статистик и
критическую точку t0,05; n–m–1, найденную с помощью функции СТЬЮДРАСПОБР;
∙под значениями t-статистик — соответствующие P-значения.
6.Выбрать лучшее уравнение и, используя его, ответить на следующие вопросы:
а) Какой процент выборочной дисперсии признака Y обусловлен линей-
ным влиянием включенных в уравнение регрессоров?
б) Каковы точечная и 95%-ная интервальная оценки генерального среднего значения признака Y при значениях регрессоров на первом объекте?
в) Увеличение какого регрессора на единицу его измерения (при неизменных значениях других регрессоров) ведет к наибольшему изменению среднего значения результативного признака; увеличение какого регрессора на единицу его измерения (при неизменных значениях других регрессоров) ведет к наибольшему максимально возможному с 95%-ной вероятностью изменению среднего значения результативного признака?
г) Увеличение среднего значения какого регрессора на 1% (по отношению к его среднему значению) при неизменных значениях других регрессоров ведет к наибольшему процентному изменению среднего значения результативного признака (по отношению к его среднему значению); увеличение среднего значения какого регрессора на 1% (по отношению к его среднему значению) при неизменных значениях других регрессоров ведет к наибольшему максимально возможному с 95%-ной вероятностью процентному изменению среднего значения результативного признака?
РАБОТА 6. Компонентный и факторный анализ [выполняется с применением программы «Факторный анализ» пакета PASW Statistics (SPSS)].
Задача. Изучается система из пяти признаков X(1), X(2), X(3), X(4), X(5) по числовым данным, собранным на n = 52 объектах. Цель — выявить общие
для этих признаков латентные факторы (компоненты), влиянием которых обусловлены вариации признаков и их ковариации. Варианты признаков и их числовые значения приведены для каждого варианта в прил. 4 (они совпадают с вариантами факторных признаков в работе 5). Требуется:
1. Записать модель компонентного анализа и предъявляемые к ней требования. Используя в качестве исходных данных матрицу (52 × 5) значений признаков X(1), X(2), X(3), X(4), X(5) (сохраненную при выполнении п. 2 работы 5), обратиться к программе «Факторный анализ» и реализовать метод главных компонент, задав максимальное число факторов равным пяти.
2.В окне результатов работы программы «Факторный анализ»:
а) выбрав для просмотра таблицу «Total variance explained», определить
доли общей дисперсии признаков (в процентах), приходящиеся на каждую компоненту, и накопленные доли этой дисперсии (в процентах);
б) выбрав для просмотра таблицу «Component matrix»:
∙определить матрицу (5 × 5) нагрузок признаков на компоненты;
∙записать выражения исходных признаков через компоненты и выражения компонент через признаки.
11
3. Снизить размерность системы исходных признаков, ограничившись несколькими первыми главным компонентами, на долю которых приходится не менее 70% общей дисперсии признаков. Дать содержательную интерпретацию этих компонент, используя матрицу нагрузок исходных признаков на главные компоненты и факторную диаграмму (unrotated factor solution). Рассчитать значения отобранных главных компонент на 52 объек-
тах и сохранить эти значения для использования в работе 7 (п. 5).
4.Провести регрессионный анализ признака Y (из работы 5) на ото-
бранные главные компоненты. Сравнить его результаты с окончательными результатами регрессионного анализа признака Y на исходные пять факторных признаков x(1), x(2), x(3), x(4), x(5) (полученными в работе 5).
5.Записать модель факторного анализа и предъявляемые к ней требования. Считая, что число общих факторов не превышает числа главных компонент, на долю которых приходится не менее 70% общей дисперсии
исходных признаков, обратиться к программе «Факторный анализ» и реализовать метод максимального правдоподобия (maximum likehood), воспользовавшись методом «Varimax» для вращения факторного пространства; про-
верить значимость модели факторного анализа. Рассчитать значения полученных общих факторов на 52 объектах и сохранить эти значения для использования в работе 7 (п. 6).
6.Сравнить факторные диаграммы до вращения (unrotated factor solution) и после вращения (rotated solution) и предложить на основании анали-
за матрицы факторных нагрузок и факторной диаграммы после вращения содержательную интерпретацию факторов; сравнить полученные факторы
сглавными компонентами, построенными в п. 4.
7.Провести регрессионный анализ признака Y на общие факторы.
Сравнить его результаты с результатами регрессионного анализа признака Y на исходные пять факторных признаков x(1), x(2), x(3), x(4), x(5) (полученными
в работе 5).
РАБОТА 7. Кластерный анализ [выполняется с применением программ «Hierarchical cluster analysis» и «K-Means cluster» пакета PASW Statistics (SPSS)].
Задача. Изучается система из пяти признаков x(1), x(2), x(3), x(4), x(5) по числовым данным, собранным на n = 52 объектах. Варианты признаков и их чи-
словые значения приведены для каждого варианта в прил. 4 (они совпадают с вариантами факторных признаков в работе 5). Цель — провести классификацию 20 объектов, номера которых приведены в прил. 4. Требуется:
1. Используя в качестве исходных данных матрицу (52 × 5) значений признаков x(1), x(2), x(3), x(4), x(5) на объектах, провести вычисления по программе «Hierarchical cluster analysis», выбрав для классификации все пять признаков, и реализовать метод ближайшего соседа (nearest neighbor) с выбором евклидовой метрики расстояний (euclidean distance), предварительно стандартизовав исходные данные (standardize); построить дендрограмму (dendrogram); сохранить протокол объединения (agglomeration schedule) и матрицу расстояний (proximity matrix).
2.В окне результатов иерархического кластерного анализа:
12
а) просмотрев матрицу расстояний, выписать расстояние между первым и двадцатым объектами и привести формулу его расчета;
б) выписать первые пять строк протокола объединения, объяснить их смысл и привести алгоритм пересчета матрицы расстояний между объектами на каждом шаге объединения;
в) проанализировав по дендрограмме иерархию объединения кластеров (первые пять шагов сопоставить с протоколом объединения), предложить (если это возможно) разбиение исходных 20 объектов на два кластера — класса и указать объекты, относящиеся к каждому классу.
3.Выполнить пп. 1 — 2 для методов дальнего соседа (furthest neighbor) и средней связи (between-groups linkage).
4.Провести вычисления по программе «K-Means cluster», выбрав для классификации пять признаков x(1), x(2), x(3), x(4), x(5) (c предварительной стан-
дартизацией) и указав в качестве количества кластеров число 2.
5.Выполнить пп. 1 — 4, выбрав для классификации не исходные признаки x(1), x(2), x(3), x(4), x(5), а главные компоненты, на долю которых при-
ходится не менее 70% общей дисперсии исходных признаков, (полученные
вработе 6).
6.Выполнить пп. 1 — 4, выбрав для классификации не исходные признаки x(1), x(2), x(3), x(4), x(5), а общие факторы (полученные в работе 6).
7.По результатам пп. 1 — 6 для каждого варианта разбиения вычислить внутриклассовые средние значения признаков x(1), x(2), x(3), x(4), x(5) и
их выборочные дисперсии, после чего выбрать вариант разбиения 20 объектов на два кластера — класса, руководствуясь критерием минимума суммы внутриклассовых дисперсий.
8.Для выбранного варианта разбиения проверить гипотезы о равенстве математических ожиданий каждого из пяти признаков в кластерах и на основании результатов проверки этих гипотез провести содержательную интерпретацию структуры изучаемой совокупности из 20 объектов и предложить названия для построенных кластеров.
9.Провести регрессионный анализ признака Y на признаки x(1), x(2), x(3), x(4), x(5) отдельно для каждого кластера. Сравнить его результаты с результатами регрессионного анализа признака Y на признаки x(1), x(2), x(3), x(4), x(5), полученными в работе 5.
РАБОТА 8. Дискриминантный анализ [выполняется с применением программы «Discriminant analysis» пакета PASW Statistics (SPSS)].
Задача. Изучается система из шести признаков Y, X(1), X(2), X(3), X(4), X(5) по числовым данным, собранным на n = 52 объектах. Варианты признаков и
их числовые значения приведены для каждого варианта в прил. 4 (они совпадают с вариантами результативного и факторных признаков в работе 5). Используя в качестве обучающей выборки разбиение 20 объектов из 52 на две группы, полученное в результате кластерного анализа (п. 6 работы 7), требуется расклассифицировать по этим двум группам оставшиеся 32 объекта, которые в кластерном анализе не рассматривались (считая, что каждый из оставшихся 32 объектов входит в одну и только в одну из этих двух групп). Цель — определить, в какую из групп входит каждый из 32 объек-
13
тов в предположении, что каждая группа подчиняется пятимерному нормальному закону распределения с одинаковой для обеих групп ковариационной матрицей. Требуется:
1. Используя в качестве исходных данных матрицу (52 × 5) значений признаков X(1), X(2), X(3), X(4), X(5) на объектах, провести вычисления по программе «Discriminant analysis», выбрав для классификации все пять признаков. На основании анализа таблицы «Canonical discriminant function coefficients» запи-
сать дискриминантную функцию, построенную программой.
2.Указать, к каким группам были отнесены классифицируемые объекты, и вероятности, с которыми объекты входят в эти группы.
3.Указать объекты, которые в обучающей выборке были неверно отнесены к группам, прокомментировать эти несоответствия.
4.На основании анализа таблицы «Wilks’ Lambda» проверить значи-
мость различий средних значений дискриминантной функции в двух группах.
5.Проверить гипотезы о равенстве математических ожиданий признаков в двух группах и на основании результатов проверки этих гипотез провести содержательную интерпретацию структуры изучаемой совокупности из 52 объектов и предложить названия для групп.
6.Провести регрессионный анализ признака Y на признаки x(1), x(2), x(3), x(4), x(5) отдельно для каждой из двух групп объектов. Сравнить его результаты с результатами регрессионного анализа признака Y на признаки x(1), x(2), x(3), x(4), x(5), полученными в работе 5.
РАБОТА 9. Непараметрический анализ однородности выборок [выполняется с применением программы «Factor analysis» пакета PASW Statistics (SPSS)].
Требуется:
1.Сформулировать содержательную социально-экономическую задачу, состоящую в проверке гипотезы об однородности двух выборок.
2.Сформулировать такую гипотезу и проверить ее с помощью критерия Вилкоксона — Манна — Уитни, приняв уровень значимости равным 0,05.
3.Провести содержательную интерпретацию результатов решения.
РАБОТА 10. Оценка связи между двумя порядковыми случайными величинами [выполняется с применением программы «Factor analysis» пакета
PASW Statistics (SPSS)].
Требуется:
1.Сформулировать содержательную социально-экономическую задачу, состоящую в оценке связи между двумя порядковыми случайными величинами и предложить для этой задачи исходные числовые данные (связанность рангов обязательна!).
2.Вычислить ранговые коэффициенты корреляции Спирмэна и Кендалла и проверить статистическую значимость найденных значений коэффициентов, приняв уровень значимости равным 0,05.
3.Провести содержательную интерпретацию результатов решения.
РАБОТА 11. Оценка связи между порядковой и категоризованной случайными величинами.
14
Требуется:
1.Сформулировать содержательную социально-экономическую задачу, состоящую в оценке связи между порядковой и категоризованной случайными величинами и предложить для этой задачи исходные числовые данные (связанность рангов обязательна!).
2.Вычислить ранговые коэффициенты корреляции Спирмэна и Кендалла и проверить статистическую значимость найденных значений коэффициентов, приняв уровень значимости равным 0,05.
3.Провести содержательную интерпретацию результатов решения.
РАБОТА 12. Оценка связи между несколькими порядковыми случайными
величинами.
Требуется:
1.Сформулировать содержательную социально-экономическую задачу, состоящую в оценке связи между более чем двумя порядковыми случайными величинами и предложить для этой задачи исходные числовые данные (связанность рангов обязательна!).
2.Вычислить коэффициент конкордации и проверить статистическую значимость найденного значения коэффициента, приняв уровень значимости равным 0,05.
3.Провести содержательную интерпретацию результатов решения.
РАБОТА 13. Оценка связи между двумя категоризованными случайны-
ми величинами.
Требуется:
1.Сформулировать содержательную социально-экономическую задачу, состоящую в оценке связи между двумя категоризованными случайными величинами X и Y (каждая из которых должна иметь не менее трех
градаций) и предложить исходные данные для таблицы сопряженности, соответствующей поставленной задаче (см. прил. 5).
2.Приняв уровень значимости равным 0,05, проверить гипотезу о независимости категоризованных случайных величин X и Y с помощью
критериев χ2 и χ2 -информационный.
3.Найти точечные и 95%-е интервальные оценки коэффициентов Чупрова, Крамера и Пирсона; сделать выводы о силе связи между величинами X и Y.
4.Найти точечные оценки направленных и симметризованных коэффициентов нормированной информации и λ и τ -коэффициентов Гудме-
на — Краскала; привести 95%-ные интервальные оценки коэффициентов
λY|X и λ X|Y; выводы о силе зависимости величин и связи между ними.
5.Провести содержательную интерпретацию результатов решения.
РАБОТА 14. Оценка связи между тремя категоризованными случайны-
ми величинами.
Требуется:
1. Сформулировать содержательную социально-экономическую задачу, требующую анализа таблицы сопряженности трех категоризованных случайных величин, каждая из которых имеет две градации, и предложить
15

исходные данные для таблицы сопряженности, соответствующей поставленной задаче (см. прил. 6);
2.Оценить параметры следующих логарифмически линейных моделей:
∙модели с отсутствием парных связей,
∙моделей с одной, двумя и тремя парными связями,
∙насыщенной модели;
3.Проверить адекватность каждой модели, используя критерий χ2 -
информационный, приняв уровень значимости равным 0,05;
4.Сравнить модели и сделать вывод о механизме формирования частот таблицы сопряженности.
5.Провести содержательную интерпретацию результатов решения.
3.МЕТОДИЧЕСКИЕ УКАЗАНИЯ
КВЫПОЛНЕНИЮ РАБОТ И ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
3.1. П о с т р о е н и е и н т е р в а л ь н о г о в а р и а ц и о н н о г о р я д а , о ц е н и в а н и е н о р м а л ь н о г о з а к о н а
р а с п р е д е л е н и я и е г о п а р а м е т р о в
Служба маркетинга оценивает дилеров фирмы по объему продаж. Сведения об объеме ежедневных продаж товара (в тыс. ден. ед.) дилером за последние 100 дней приведены в табл. 3.1.1.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т а б л и ц а |
3.1.1 |
|||
47,0 |
37,2 |
52,4 |
62,8 |
62,0 |
67,3 |
28,2 |
47,7 |
61,0 |
39,1 |
43,1 |
33,1 |
31,5 |
40,2 |
42,3 |
28,8 |
44,3 |
46,0 |
51,3 |
46,3 |
46,7 |
46,3 |
63,4 |
49,1 |
48,1 |
44,9 |
69,7 |
58,7 |
73,8 |
43,5 |
66,6 |
33,9 |
55,4 |
59,0 |
69,2 |
49,2 |
44,8 |
56,8 |
46,2 |
57,6 |
35,6 |
41,5 |
34,8 |
46,4 |
49,7 |
50,3 |
46,8 |
71,9 |
32,6 |
42,6 |
24,2 |
64,5 |
37,2 |
43,5 |
57,6 |
54,7 |
58,7 |
56,0 |
36,3 |
38,8 |
56,9 |
53,2 |
40,6 |
47,6 |
51,3 |
55,6 |
51,4 |
40,9 |
68,8 |
54,9 |
50,7 |
58,3 |
58,6 |
43,6 |
40,8 |
61,1 |
38,0 |
34,4 |
57,1 |
56,4 |
72,1 |
64,4 |
63,0 |
51,1 |
50,0 |
54,5 |
49,7 |
39,5 |
32,3 |
58,3 |
54,4 |
56,2 |
52,1 |
39,7 |
62,4 |
46,9 |
41,6 |
41,8 |
45,7 |
45,5 |
1. Построим интервальный вариационный ряд. В ячейки A1:A101 рабочего листа Microsoft Excel введем данные об объеме продаж из табл. 3.1.1
(в первой строке — заголовок, как показано на рис. 3.1.1). Ширина интервала
=x(max) − x(min)
1+ 3,322lgn
(здесь x(max) — максимальный объем продаж, а x(min) — минимальный, расчет
производится с числом знаков после запятой, на один большим чем в исходных данных). Границы интервалов (aj; aj+1) рассчитываются по правилу:
a1 = x(min) – / 2, a2 = a1 + , a3 = a2 + , …; формирование интервалов заканчивается, как только для конца aν+1 очередного интервала выполняется
условие aν+1 > x(max). Расчет границ интервалов проиллюстрирован рис. 3.1.1.
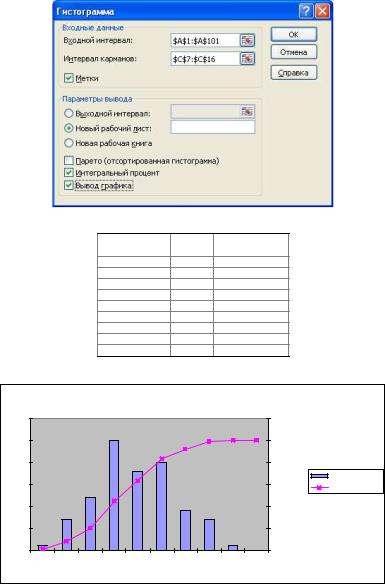
Для расчета интервальных частот и построения полигона и гистограммы воспользуемся программой «Гистограмма» из надстройки «Анализ данных» Microsoft Excel. Для этого в версиях до Microsoft Excel 2003 включительно выберем в меню «Сервис | Анализ данных» Microsoft Excel пункт «Гистограмма». В версиях Microsoft Excel 2007 и 2010 нужно на вкладке «Данные»
нажать кнопку « » и далее выбрать пункт «Гистограмма».
» и далее выбрать пункт «Гистограмма».
16

В окне ввода исходных данных программы «Гистограмма» (рис. 3.1.2) укажем входной интервал (ссылку на ячейки A1:A101, содержащие данные об объеме продаж; выделять заголовок столбца и отмечать флажок «Метки» не будем), интервал карманов (ссылку на ячейки C7:C16, содержащие правые границы интервалов), установим флажок «Метки», которые означает, что в первой строке каждого из диапазонов A1:A101 и C7:C16 содержится
текстовый заголовок. Укажем, что результаты работы программы необходимо вывести на новый рабочий лист. Установим флажок для генерации интегральных процентных отношений — значений выборочной функции распределения, также установим флажок автоматического вывода графика —
гистограммы и кумуляты.
|
A |
B |
C |
1 |
Объем продаж за 100 дней |
Параметры |
Значения параметров |
|
2 |
47,0 |
Объем выборки n |
=СЧЕТ(A2:A101) |
|
3 |
37,2 |
x(min) |
=МИН(A2:A101) |
|
4 |
52,4 |
x(max) |
=МАКС(A2:A101) |
|
5 |
62,8 |
Ширина интервала |
=(C4–C3)/(1+3,322*LOG(C2;10)) |
|
6 |
62,0 |
Границы интервалов |
|
|
7 |
67,3 |
Левые границы |
Правые границы |
|
8 |
28,2 |
=C3–C5/2 |
=B9+C5 |
|
9 |
47,7 |
=B9+C5 |
=B10+C5 |
|
10 |
61,0 |
=B10+C5 |
=B11+C5 |
|
11 |
39,1 |
=B11+C5 |
=B12+C5 |
|
12 |
43,1 |
=B12+C5 |
=B13+C5 |
|
13 |
33,1 |
=B13+C5 |
=B14+C5 |
|
14 |
31,5 |
=B14+C5 |
=B15+C5 |
|
15 |
40,2 |
=B15+C5 |
=B16+C5 |
|
16 |
|
=B16+C5 |
=B17+C5 |
|
|
а) формулы Microsoft Excel |
||
|
|
|
|
|
|
|
A |
B |
C |
|
1 |
Объем продаж за 100 дней |
Параметры |
Значения параметров |
|
2 |
47,0 |
Объем выборки n |
100 |
|
3 |
37,2 |
x(min) |
24,2 |
|
4 |
52,4 |
x(max) |
73,8 |
|
5 |
62,8 |
Ширина интервала |
6,49 |
|
6 |
62,0 |
Границы интервалов |
|
|
7 |
67,3 |
Левые границы |
Правые границы |
|
8 |
28,2 |
20,956 |
27,444 |
|
9 |
47,7 |
27,444 |
33,933 |
|
10 |
61,0 |
33,933 |
40,422 |
|
11 |
39,1 |
40,422 |
46,911 |
|
12 |
43,1 |
46,911 |
53,399 |
|
13 |
33,1 |
53,399 |
59,888 |
|
14 |
31,5 |
59,888 |
66,377 |
|
15 |
40,2 |
66,377 |
72,866 |
|
16 |
|
72,866 |
79,354 |
б) результаты расчетов
Рис. 3.1.1. Расчет границ интервалов
Результаты работы программы «Гистограмма» представлены на рис. 3.1.3. В столбце «Правые границы» на рис. 3.1.3, а указаны правые границы интервалов, в столбце «Частота» — интервальные частоты, а в столбце
17
«Интегральный %» — накопленные частоты, рассчитанные программой. На рис. 3.1.3, б представлен график, построенный программой, — на одной диа-
грамме построены гистограмма и кумулята (впоследствии мы разделим этот график на два).
|
Рис. 3.1.2. Окно ввода данных программы «Гистограмма» |
|||
|
Правые границы Частота Интегральный % |
|
||
|
27,444 |
1 |
1,00% |
|
|
33,933 |
7 |
8,00% |
|
|
40,422 |
12 |
20,00% |
|
|
46,911 |
25 |
45,00% |
|
|
53,399 |
18 |
63,00% |
|
|
59,888 |
20 |
83,00% |
|
|
66,377 |
9 |
92,00% |
|
|
72,866 |
7 |
99,00% |
|
|
79,354 |
1 |
100,00% |
|
|
Еще |
0 |
100% |
|
|
а) числовые результаты |
|
||
|
|
Гистограмма |
|
|
|
30 |
|
120,00% |
|
|
25 |
|
100,00% |
|
|
20 |
|
80,00% |
|
Частота |
|
|
|
Частота |
15 |
|
60,00% |
Интегральный % |
|
|
|
|
||
|
|
|
|
|
|
10 |
|
40,00% |
|
|
5 |
|
20,00% |
|
|
0 |
|
0,00% |
|
|
27,444 33,933 40,422 46,911 53,399 59,888 66,377 72,866 79,354 |
Еще |
|
|
|
Правые границы |
|
|
|
б) графические результаты
Рис. 3.1.3. Результаты работы программы «Гистограмма»
18
|
Добавим к таблице, полученной в результате работы программы «Гис- |
|||||||||||||
тограмма» и уже содержащей правые границы интервалов (aj; aj+1) и интер- |
||||||||||||||
вальные частоты mj , столбцы, содержащие: |
|
|
|
|
||||||||||
∙ |
левые границы интервалов; |
|
|
|
|
|
|
|||||||
∙ |
|
|
|
|
|
|
′ |
|
|
|
|
|
|
|
середины интервалов xj = (aj + aj+1)/2; |
|
|
|
|
||||||||||
∙ |
интервальные частости ˆp |
= m |
/n ; |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
j |
j |
|
|
|
|
|
|
∙ |
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
|
оценки функции плотности внутри интервалов f (x′) =ˆp / . |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
X |
j |
j |
|
Для получения оценок функции распределения в концах интервалов |
|||||||||||||
ˆ |
|
) = |
∑ |
ˆp установим в столбце «Интегральный %» (в результатах рабо- |
||||||||||
F (a |
j+1 |
|||||||||||||
X |
|
k |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
k j+1 |
|
|
|
|
|
|
|
|
|
|
|
ты программы «Гистограмма» рис. 3.1.3) числовой формат значений с двумя |
||||||||||||||
десятичными знаками после запятой. |
|
|
|
|
|
|||||||||
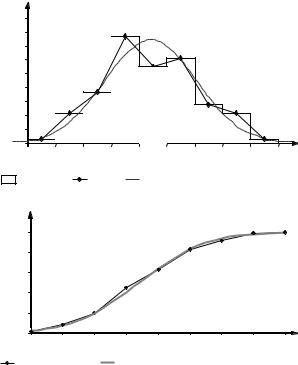
|
Теперь мы можем заполнить первые шесть столбцов табл. 3.1.2, содер- |
|||||||||||||
жащие интервальный вариационный ряд, и построить полигон [ломаную, со- |
||||||||||||||
|
|
|
|
|
′ ˆ |
′ |
|
|
|
|
|
|
|
|
единяющую точки (xj |
; fX (xj )), j = 1, 2, …, ν] и гистограмму [фигуру, состоя- |
|||||||||||||
щую из прямоугольников, в основании которых лежат интервалы группиро- |
||||||||||||||
вания (aj; aj + 1), а высотами являются значения |
ˆ |
′ |
|
|
||||||||||
fX (xj )] на рис. 3.1.4 и кумуля- |
||||||||||||||
|
|
|
|
|
|
|
|
|
ˆ |
|
|
|
|
|
ту [ломаную, соединяющую точки (aj+1; FX |
(aj+1)) , j = 1, 2, …, ν] на рис. 3.1.5. |
|||||||||||||
|
|
|
|
|
f(x) |
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0450 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0400 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0350 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0300 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0250 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0200 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0150 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0050 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
0 |
24,20 |
30,69 |
37,18 |
43,67 |
50,16 |
56,64 |
63,13 |
69,62 |
76,11 |
|
|
|
|
|
Гистограмма |
Полигон |
Функция плотности нормального закона |
||||||||
Рис. 3.1.4. Гистограмма, полигон и функция плотности нормального закона |
||||||||||||||
F(x) |
|
|
|
|
|
|
|
|
1,0000 |
|
|
|
|
|
|
|
|
0,8000 |
|
|
|
|
|
|
|
|
0,6000 |
|
|
|
|
|
|
|
|
0,4000 |
|
|
|
|
|
|
|
|
0,2000 |
|
|
|
|
|
|
|
|
0,0000 |
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
27,444 |
33,933 |
40,422 |
46,911 |
53,399 |
59,888 |
66,377 |
72,866 |
79,354 |
Кумулята |
|
Функция распределения нормального закона |
||||||
Рис. 3.1.5. Кумулята и функция распределения нормального закона |
||||||||
19
20
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т а б л и ц а |
3.1.2 |
|
||||
|
Сере- |
Интер- |
Ин- |
Оценка |
Оценка |
Функция |
Функция рас- |
|
pj = |
|
|
np |
|
m |
|
2 |
|
||||
|
дина |
валь- |
функции |
плотности |
|
|
|
|
j |
j |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Интервал |
ин- |
ная |
терваль- |
функции |
распре- |
нормаль- |
пределения |
F(aj) |
= F(aj + 1)– |
Частота |
после |
объ- |
(npj − mj ) |
|
|||||||
(aj; aj + 1) |
ная час- |
плотности |
нормального |
npj |
|
единения |
|
npj |
|
||||||||||||
терва- |
часто- |
деления |
ного зако- |
|
–F(a ) |
|
|
|
|||||||||||||
|
′ |
|
тость ˆp |
ˆ |
′ |
ˆ |
|
|
|
′ |
закона F(aj + 1) |
|
j |
|
|
интерва- |
|
|
|
||
|
та m |
j |
fX (xj ) |
(a |
|
) |
|
|
|
|
|
|
|
|
|
|
|||||
|
ла xj |
|
|
|
F |
+ |
на fN (xj ) |
|
|
|
|
|
лов |
|
|
|
|||||
|
|
j |
|
|
|
X |
j |
1 |
|
|
|
|
|
|
|
|
|
|
|||
[20,956; 27,444) |
24,20 |
1 |
0,01 |
0,0015 |
0,01 |
|
0,0022 |
0,0187 |
0,0000 |
0,0187 |
1,87 |
|
7,04 |
8 |
|
0,1295 |
|
||||
[27,444; 33,933) |
30,69 |
7 |
0,07 |
0,0108 |
0,08 |
|
0,0077 |
0,0704 |
0,0187 |
0,0518 |
5,18 |
|
|
|
|||||||
|
|
|
|
|
|
|
|
||||||||||||||
[33,933; 40,422) |
37,18 |
12 |
0,12 |
0,0185 |
0,20 |
|
0,0190 |
0,1942 |
0,0704 |
0,1237 |
12,37 |
|
12,37 |
12 |
|
0,0112 |
|
||||
[40,422; 46,911) |
43,67 |
25 |
0,25 |
0,0385 |
0,45 |
|
0,0321 |
0,4002 |
0,1942 |
0,2060 |
20,60 |
|
20,60 |
25 |
|
0,9375 |
|
||||
[46,911; 53,399) |
50,16 |
18 |
0,18 |
0,0277 |
0,63 |
|
0,0374 |
0,6395 |
0,4002 |
0,2393 |
23,93 |
|
23,93 |
18 |
|
1,4677 |
|
||||
[53,399; 59,888) |
56,65 |
20 |
0,20 |
0,0308 |
0,83 |
|
0,0301 |
0,8332 |
0,6395 |
0,1937 |
19,37 |
|
19,37 |
20 |
|
0,0203 |
|
||||
[59,888; 66,377) |
63,14 |
9 |
0,09 |
0,0139 |
0,92 |
|
0,0167 |
0,9426 |
0,8332 |
0,1094 |
10,94 |
|
10,94 |
9 |
|
0,3429 |
|
||||
[66,377; 72,866) |
69,63 |
7 |
0,07 |
0,0108 |
0,99 |
|
0,0064 |
0,9856 |
0,9426 |
0,0430 |
4,30 |
|
5,74 |
8 |
|
0,8876 |
|
||||
[72,866; 79,354) |
76,12 |
1 |
0,01 |
0,0015 |
1,00 |
|
0,0017 |
1,0000 |
0,9856 |
0,0144 |
1,44 |
|
|
|
|||||||
|
|
|
|
|
|
|
|
||||||||||||||
Итого |
— |
100 |
1,00 |
— |
|
|
— |
|
|
— |
— |
— |
— |
— |
|
— |
|
100 |
|
χ42=3,80 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|