

Взаимное отделение адресных пространств задач - механизм защиты реализуется через использование таблиц дескрипторов. Адресация через дескрипторы делает "невидимым" для программы не принадлежащее ей адресное пространство. Все попытки обращения по "чужим" адресам вызывают прерывание выполнения задачи по защите памяти. Для обращения же к разделяемым программам или данным используются специальные механизмы. ( Процессоры Intel)
Использование LDT позволяет вывести дескрипторы, описывающие критические области памяти, из GDT, что разрешит доступ к ним лишь отдельным задачам. Все потоки одного процесса разделяют одно АП, изолированное от остальной части системы. При переключении задач старое содержимое регистра LDTR сохраняется в сегменте состояния задачи TSS, а в регистр загружается селектор LDT входящей задачи. Эти действия совершаются аппаратно.
35 СРЕДСТВА ЗАЩИТЫ ПАМЯТИ: ЗАЩИТА ПО УРОВНЯМ ПРИВИЛЕГИЙ, ПРИВИЛЕГИРОВАННЫЕ КОМАНДЫ И КОМАНДЫ, ЧУВСТВИТЕЛЬНЫЕ К УРОВНЯМ ПРИВИЛЕГИЙ). ПОДДЕРЖКА В INTEL.
Второй известный способ защиты, применяемый в процессорах Intel, организация кольцевой защиты, основанной на понятии иерархии привилегий. Каждой программе, выполняемой в системе, приписывается свой уровень привилегий, определяющий ее права. Максимальными правами обладают наиболее привилегированные программы, они же являются наиболее защищенными. Систему защиты в таком случае можно изобразить как набор колец. Каждый уровень защиты образует кольцо из программ, имеющих данный уровень привилегий.
Процессоры семейства Intel позволяют организовать защиту в соответствии с 4 уровнями привилегий (от 0 до 3).
Система, в |
которой все программы получают нулевой уровень |
привилегий - это |
||||
система, в которой данный механизм не используется. |
|
|
|
|
||
Второй вариант защиты - традиционная защита, |
в которой используется два уровня |
|||||
защиты через деление на супервизор и |
пользователя. В этом |
случае |
программы |
|||
операционной |
системы выполняются на |
уровне |
привилегий |
0, |
а |
программы |
пользователей (прикладные задачи) - на уровне привилегий 3.
При более полном использовании средств защиты в иерархию привилегий включаются и промежуточные значения, соответствующие кольцам, отделяющим наиболее привилегированные системные программы от прикладных программ. Наиболее критичные и редко изменяемые процедуры ОС (ее ядро) получают
уровень привилегий 0, менее критичные и подверженные изменениям (например, драйверы) - 1, уровень 2 может быть отведен для разработчиков комплексных систем, например, СУБД, а уровень 3 остается для конечных пользователей - прикладных программистов.
Механизм привилегий поддерживается включением полей уровня привилегии сегмента
в дескриптор сегмента, привилегии страницы - в дескриптор |
страницы, |
поля |
запрашиваемого уровня привилегий в селектор логического адреса |
при обращении к |
|
памяти. С наличием нескольких уровней привилегий в системе связаны следующие понятия:
CPL - текущий уровень привилегий, который определяется по уровню привилегий кодового сегмента, исполняемого в данный момент времени; RPL - уровень привилегий запроса, который определяется уровнем привилегий процедуры, обращающейся к памяти; этот уровень фиксируется
в двух младших разрядах селектора адреса;
52
DPL - уровень привилегий дескриптора целевого сегмента, к которому происходит обращение;
EPL - эффективный уровень привилегий запроса, который численно равен наименее привилегированному из значений RPL и CPL:
EPL = max(RPL, CPL).
Уровень привилегий задачи определяется уровнем привилегий исполняемого кодового сегмента. Текущий уровень привилегий CPL поддерживается процессором автоматически. Он определяется равным содержимому поля DPL сегмента, адресуемого в данный момент регистром CS. При этом установленное значение CPL помещается в двух младших битах регистра CS, замещая значение RPL находящегося там селектора.
Все сегменты, имеющиеся в системе, распределяются по кольцам защиты в соответствии с уровнями их привилегий, записанными в полях DPL
их дескрипторов.
Проверка привилегий в системе осуществляется при реализации кольцевой защиты в ситуациях межсегментных обращений: доступ к сегменту данных или сегменту стека, межсегментные передачи управления в особых случаях, при обработке прерываний, при
вызовах процедур или при переходах. |
|
|
||||
Порядок |
получения |
исходной |
информации для |
проверки привилегий в |
||
межсегментных ситуациях показан на рис.2.22. |
|
|||||
Видимый селектор |
Невидимый дескриптор |
|
||||
┌──────────┐ |
┌───────────┬───┬─────┐ |
|
||||
CS │ |
├ ─ │ . . . |
CPL ... │ |
|
|
|
|
└──────────┘ |
└───────────┴─┬─┴─────┘ ┌────────────┐ |
|||||
|
│ |
│ |
│ |
|
|
|
|
│ |
│ |
│ |
|
|
|
|
└──────────│ Механизм │ |
|
||||
|
|
|
│ проверки │ |
|
|
|
Селектор целевого |
Дескриптор целевого │ привилегий │ |
|
||||
сегмента |
сегмента |
│ |
│ |
|
||
┌───────────────────────────────│ |
│ |
|||||
│┌──────────│ │
┌──────┬─┴─┐ ┌───────────┬─┴─┬─────┐ └────────────┘
│RPL├ ─ │ . . . DPL ... │
└──────┴───┘ └───────────┴───┴─────┘
Рис.2.22. Проверка уровней привилегий при межсегментных обращениях В любой ситуации, связанной с возможной межсегментной передачей управления, выполняются следующие проверки:
-ссылается ли селектор на правильный тип дескриптора;
-выполняются ли правила соответствия привилегий.
Последнее условие в данном случае намного сложнее, чем это было при обращении к сегментам данных. В целом эти правила при межсегментных передачах считаются выполненными, если:
- изменение уровня привилегий происходит только при адресации через дескрипторы специального типа - шлюзы; такая ситуация возникает, например, при вызове процедур неподчиненных сегментов кода, системных вызовах, при реализации обработки прерывания, если обработчик - задача; при этом кодовый сегмент, выбранный шлюзом, должен иметь уровень привилегий более высокий или равный CPL, а для RPL селектора шлюза, DPL дескриптора шлюза и CPL должно выполняться условие (RPL <= DPL ) & (CPL <= DPL);
53
- команды передачи управления подчиненному сегменту не изменяют
текущий уровень привилегий (то есть биты поля RPL регистра CS не изменяются на поле DPL дескриптора нового подчиненного сегмента кода); подчиненные кодовые сегменты доступны на уровнях привилегий CPL, не превышающих DPL подчиненного кодового сегмента, то есть передача управления разрешается только на внутренние более защищенные кольца (для дескриптора подчиненного сегмента DPL и текущего значения CPL должно быть верно условие DPL <= CPL);
-переходы к неподчиненным сегментам без использования шлюзов выполняются на том же уровне привилегий;
-команды возврата, не переключающие задачи, возвращают управление кодовому сегменту с тем же или меньшим уровнем привилегий.
36.Статическая и динамическая компоновка программ: определение, сравнение и примеры.
Компоновка программ и загрузка на выполнение (компоновка = связывание).
1.Отдельно оттранслированные программные модули связываются в одну программу;
2.Выполняется привязка к памяти, то есть настройка адресов. Можно выполнить компоновку и загрузку в памяти на выполнение как две отдельные задачи – в ОС есть две утилиты для решения этих задач: компоновщик (редактор связей) и загрузчик. Загрузчик выполняет загрузку программы в память на выполнение и дополнительно выполняет настройку адресов. Другой вариант – использование связывающих загрузчиков – то есть программ, которые в процессе загрузки на выполнение устанавливают связи между модулями. Связывание может быть динамическим и статическим. При статической компоновке все ссылки между программными модулями разрешаются до начала
выполнения программы. Результат статического связывания – исполнимый программный модуль с простой структурой. Весь программный код, все данные, которые используются в программе, подключены к этому программному модулю. Плюс – отсутствие накладных расходов на поиск адресов, на разрешение ссылок. Минус – неэффективное использование ресурса, в частности память – один и тот же код для стандартных процедур дублируется многократно. Также недостаточная гибкость для настройки, для переработки программ – при изменении какой-либо стандартной функции нужно редактировать все программы, которые ее используют.
Понятие динамической компоновки, организация DLL. В этом случае разрешение ссылок откладывается либо на момент загрузки программы, либо на время ее выполнения. Существует 2 случая динамической компоновки: явная (во время выполнения) и неявная (в момент загрузки). I) Для неявного случая, при разработке библиотеки, программист должен с помощью специальных директив дать указания (которые перейдут компоновщику) транслятору, о том, какие объекты должны быть доступны извне. Из этой информации в заголовок библиотеки будут включены записи, аналогичные записям-определителям (секция Exports, в ней экспортируем имена). У загружаемого исполнимого модуля, использующего библиотеки, в заголовке должна быть сформирована таблица импорта, подобная записи внешних ссылок (R). Порядок поиска библиотеки: 1). В папке, где находиться exe-файл. 2). Windows\system\… и в текущей папке. 3).По переменной окружения PATH. Основной недостаток такого способа – при отсутствии хотя бы одной функции программа не будет запускаться на выполнение, даже если эта функция не используется. II). Для явной компоновки загрузка DLL отодвигается по времени до момента, когда функции будут использоваться в программе. При запуске исполнимого модуля экономится объем дисковой памяти, потому что код программы из exe не переписывается в pagefile.
54
Пример (DLL, возведение числа в квадрат):
//MathFuncsDll.cpp #include "MathFuncsDll.h" #include "stdafx.h"
extern "C" __declspec(dllexport) double Square(double x)
{return x * x;}
//MathFuncsDll.h
#ifndef _DLLTEST_H_ #define _DLLTEST_H_
extern "C" __declspec(dllexport) double Square(double x); #endif
//неявное подключение
#include <iostream> #include <windows.h> #include "MathFuncsDll.h"
#pragma comment(lib, "MathFuncsDll.lib") //добавление параметров компоновщика (имя библиотеки)
using namespace std;
void main()
{
printf("Function is loaded. Test : \n"); double x = 1;
double result = Square(x); printf("Square(%f) = %f\n", x, result);
}
//явное подключение
#include <iostream> #include <windows.h> using namespace std;
void main()
{
HINSTANCE myDll; //дескриптор загруженного библиотечного модуля myDll = LoadLibrary(L"MathFuncsDll.dll"); //пытаемся выгрузить dll if (myDll == NULL)
{
printf( "Error! Unable to load library.\n"); return;
}
else
{
printf( "Library is loaded.\n" );
double (*Sqr) (double); //Square - это указатель на функцию
(FARPROC &)Sqr = GetProcAddress(myDll, "Square"); //Получаем адрес функции if (Sqr == NULL)
{
printf("Error! Unable to load function.\n" ); FreeLibrary(myDll);
return;
}
else
{
printf("Function is loaded. Test : \n"); double x = 1.1;
double result = Sqr(x); printf("Square(%f) = %f\n", x, result); FreeLibrary(myDll);
}
}
}
55

37 Упрощённая структура объектного модуля и принцип работы связывающего загрузчика, редактора связей (одно- и двухпроходовые). Упрощённая структура исполнимого файла.
Упрощенная структура объектного модуля. Состоит из записей разных форматов,
которые содержат поля. Sign – запись. В зависимости от Sign определяются поля внутри самой записи (как записи с вар частью). Записи: 1) T (title) – запись-заголовок, содержащая поля: name (имя объектного модуля), size (объем памяти, который требуется для размещения всего объектного модуля). 2) B (body) – содержит тело объектного модуля. Поля: code (собственно код, содержащийся в этой записи, получен в результате трансляции), size (сколько места занимает этот конкретный код этой записи). Записей B может быть несколько. 3)D (definition) – запись-определение, описывает программные модули, доступные извне. Поля: name (имя, по которому будем разыскивать внешний объект (процедура, функция, глобальная переменная или константа), addr (адрес объекта внутри этого модуля, в котором он описан)). 4) R (reference) - внешняя ссылка – на объект, описанный вне этого программного модуля Поля: name (имя, соответствующее этой внешней ссылке), addr (смещение поля, которое должно содержать ссылку); 5) M – запись-модификатор – описывает поле, подлежащее настройке, настройка проходит внутри одного модуля, без использования внешних объектов. Описывает те ссылки, которые «частично» были разрешены во время трансляции, то есть это ссылки внутри модуля, которые были настроены относительно начала этого модуля. Эти ссылки должны настраиваться дополнительно в зависимости от адреса, по которому будет загружаться модуль, так как транслятор этого не знает. Поля: addr (адрес поля (относительно модуля), которое надо модифицировать). В реальных объектных модулях М может содержать дополнительную информацию (например, ссылки на другие модули из-за которых нужна настройка). 6). E (end) – конец программного модуля. Поля: addr (адрес точки входа в программу, это поле не обязательное, может быть пустым, это точка входа для процедуры main – только для того модуля, где она находится).
Принцип работы связывающего загрузчика.
PS – файлы, содержащие программные модули, подготовленные компилятором.
ESD (External Symbols Dictionary) – словарь внешних символов (внешний символ - любой объект доступный извне).
1) В модулях должна содержаться информация о неразрешенных ссылках. 2) Должны быть описания тех объектов (констант, переменных, процедур, функций), которые в данном модуле доступны извне.
3)Должна быть информация, сколько памяти
потребуется выделить для модуля. В ESD хранятся имена, адрес (берется из модуля и настраивается для дальнейшего использования) – нужен для ссылок. Можно организовать в виде дерева. В итоге в оперативной памяти получаем готовую к выполнению программу. Алгоритм для двухпроходового связывающего загрузчика. 1-ый проход: прочитать все модули и составить ESD; 2-ой проход: считываем код из модулей, загружаем в память (при загрузке используется ESD для разрешения ссылок). Программа на псевдокоде.
Алгоритм загрузчика в два прохода. 1-ый проход:
GetStartAddr (Start); CA<-Start; {Start нужен для второго прохода, поэтому введем
CA – адрес загрузки текущего модуля}
While (не закончились объектные модули) do begin (*1)
56
Open(s); {открываем программный модуль}
While (не конец S) do begin (*2) read(S, CR); {CR – текущая запись}
if (CR.sign = T) then CL<-CR.size {сохраняем размер. CL будем использовать для увеличения Start}
else if (CR.sign = D) then begin (*3)
WA<-CR.addr + CA; {настроили адрес загрузки} Insert (ESD, CR.name, WA);
end (*3) end (*2) CA<-CA + CL;
end (*1);
CL<-CR.size;{Закончился первый проход}
2-ой проход:
CA<-Start; ExecAddr<-Start; CC<-Start;
While (не конец списка модулей) do begin (*1)
Open(S); {размер объектного модуля может не соответствовать суммарному размеру всех записей, содержащих код}
While (не конец S) do begin (*2) read(S,CR);
case(CR.sign) do T:CL<-CR.size; C: begin (*3)
StMem(CC,CR.code); {сохраняем код в память по адресу СС}
CC<-CC+CR.size; end (*3)
R: begin (*4) {вызываем функцию, которая будет возвращать адрес, найденный для внешней ссылки. Если ссылка не определена – возвращает nil}
if (Find(ESD,CR.name)=nil) then begin (*5)
write(“неразрешимая внешняя ссылка”+CR.name); ErrorCode<-1; end(*5) else begin (*6) {нашли ссылку, выполняем настройку}
StMem (CR.addr+CA, Find (ESD, CR.name)); end (*6) end (*4)
M: StMem (CR.addr+CA {сюда записываем}, GetMem (CR.addr) + CA {отсюда
берем}); //по уст. ссылке берем адрес, увеличиваем его и кладем по тому же адресу
E: if (not Empty (CR.addr) {не пустое поле записи}) then {определена точка
входа}
if ExecAddr! =Start then Write(“повторное определение”) else ExecAddr<-CR.addr + CA;
end(*2); CA<-CA + CL;
end (*1);
Предполагаемый вариант однопроходного загрузчика.
CA<-Start; ExecAddr<-Start; CC<-Start;
While (не конец списка модулей) do begin (*1)
Open(S);{размер объектного модуля может не соответствовать суммарному размеру всех записей, содержащих код}
While (не конец S) do begin (*2)
57
read(S,CR); case(CR.sign) do T:CL<-CR.size; C: begin (*3)
StMem(CC,CR.code); {сохраняем код в память по адресу СС}
CC<-CC+CR.size; end (*3)
R: begin (*4) {вызываем функцию, которая будет возвращать адрес, найденный для внешней ссылки. Если ссылка не определена – возвращает nil}
if (Find(ESD,CR.name)=nil) then {не нашли в текущем ESD, однако он может быть не полным, добавим вспомогательный список, содержащий возможно неописанные имена, потом дополнительно проверим данный вспомогательный список, по окончании перебора всех модулей} addToTempList (CR.name);
else begin (*6) {нашли ссылку, выполняем настройку}
StMem (CR.addr+CA, Find (ESD, CR.name)); end (*6) end (*4, R)
M: StMem(CR.addr+CA {сюда записываем},GetMem(CR.addr) + CA {отсюда
берем} ); |
E: if (not Empty (CR.addr) {не пустое поле записи}) then {определена |
точка входа} |
|
if ExecAddr!=Start then Write(“повторное определение”) else ExecAddr<-CR.addr + CA;
D: begin (*7) WA<-CR.addr + CA; {настроили адрес загрузки}
Insert(ESD,CR.name,WA); end (*7) |
|
|
end (*case); |
|
|
end(*2); |
|
|
CA<-CA + CL; |
end (*1); |
{перебрали все модули, теперь рассмотрим |
вспомогательный список, содержащий ранее не найденные имена} while (не конец вспомогательного списка)
if (Find(ESD, getNodeFromTempList() {возвращает голову списка. Это будет имя})=nil) then begin (*5)
write(“неразрешимая внешняя ссылка” + getNodeFromTempList()); ErrorCode<-1;
end(*5);
38 Понятие прерывания, классификация прерываний. Примеры (Intel).
Понятие прерывания. Прерывание – это прекращение выполнения текущей последовательности команд (то есть последовательности команд активной программы) вследствие некоторого события.
Классификация Прерываний. В зависимости от причин Прерываний: внешние
(асинхронные) по отношению к активной программе, внутренние - связаны с выполнением активной программы: делятся на несколько групп:
1.Добровольное Прерывание программы (обращение к системным функциям, к ОС за ресурсами, специальная команда INT [interrupt]);
2.Прерывания, связанные с невозможностью выполнения ЦП выбранной команды (например, деление на ноль, передано управление на данные, изменение кода программы вследствие переполнения массива, обращение по несуществующему адресу). Такие Прерывания называются исключениями, или исключительными ситуациями (ИС).
ИС: а) Нарушение, отказ – исключение, которые распознается до начала выполнения команды, вызвавшей это исключение, например, обращение к незагруженной странице, выход за установленный предел сегмента, нарушение правил проверки привилегий. При этом возможен рестарт выполнения команды, вызвавшей исключение;
58
б) Ловушка – распознается в ходе выполнения команды. Выполнение команды начато, но процессор не может получить нормальный результат. Например, деление на 0 – в некоторых процессорах а), в некоторых б); переполнение при умножении – результат не вмещается в разрядную сетку. Рестарт команды не выполняется, можно возобновить выполнение со следующей команды;
в) Авария, сбой - серьезная ошибка, выход из программы, прекращение выполнения программы. Программа не может продолжить выполнение (процессор не успевает запомнить условия возникновения ошибки, восстановить контекст нельзя). Например, аппаратные ошибки (технические неисправности), несовместимые или недопустимые значения в системных таблицах, т.е. причины, неизбежно ведущие к прекращению процесса (программы); используются для фиксации фатальных ошибок. Классификация Прерываний может быть более сложной. Это определяется характеристиками аппаратуры и СПО.
Каждому номеру (0-255) прерывания или исключения соответствует элемент в таблице дескрипторов прерываний IDT (Interrupt Descriptor Table).
39 Общая схема обработки прерываний, программно-аппаратная реализация, аппаратная поддержка механизма прерываний в Intel.
Общая схема обработки прерываний и аппаратная поддержка механизма прерываний в Intel: В любой современной ВС обработка Прерываний является программно-аппаратной.
Шаги: 1) Генерация Прерывания, его распознавание, фиксация. Сначала процессор идентифицирует источник Прерывания, назначая ему номер (код, вектор) от 0 до 255. Полученный процессором вектор позволяет ему выбрать соответствующий обработчик. Для внешних Прерываний запрос на Прерывание генерирует внешняя по отношению к процессору схема – это прерывание от внешнего устройства. Внешние источники Прерываний выдают свои запросы на Прерывания не напрямую процессору, а через специальную схему, которых называется контроллером Прерываний (КП). Функция этой схемы – разгрузить процессор. КП при нескольких одновременных запросах на Прерывания от нескольких источников определяет самый приоритетный, то есть самое важное Прерывание. Он идентифицирует прерывание, определяет его вектор (в Intel 8 бит). Часть кодов резервируется за самим процессором для его внутренних прерываний. Также фирма Intel зарезервировала часть векторов для возможных расширений, остальные находятся в распоряжении программиста. В механизме обработки прерываний допускается каскадное соединение нескольких КП. Прерывания распознаются, фиксируются процессором всегда на границе выполнения команд (до начала или после завершения). Перед выполнением команды процессор проверяет вход на наличие прерываний. Можно запретить процедуру реагировать на прерывания, которые запрашивается через вход inter. Для этого используется специальный флажок IF [interrupt flag]. Если флажок установлен, процессор может разрешить КП передать код прерывания по шине данных. Можно запретить не все прерывания, а выборочно – замаскировать некоторые виды прерываний. КП являются программируемыми, их можно настраивать, в частности, можно задать маску, которые запретит прерывания от одного или нескольких внешних источников. Внутренние прерывания процессора запретить нельзя, они не маскируются. Есть внешние прерывания, запросы на которые передаются на вход специальных немаскируемых прерываний процессора NMI (not mask interrupt). Прерывания могут быть вложенными, т.е. могут возникать при выполнении программы обработки прерывания. Получится цепочка, в которые реализуется дисциплина LIFO.Некоторые обработчики прерываний могут мешать друг другу. Программисты обработчиков должны это учитывать. Самое простое – разработчик может запретить мешающие этому обработчику прерывания;
59
2) Запоминание контекста на момент прерывания. Минимальный контекст запоминается процессором автоматически – точка возврата из прерывания и регистр флагов. В реальном режиме Intel к какой команде возврат зависит от типа ИС. В защищенном режиме контекст может быть более содержательным. Может запоминаться информация об ошибке (код). Содержание контекста зависит от типа прерывания (например, для страничной ошибки – адрес, при обращении по которым ошибка возникла). В защищенном режиме обработка прерывания может быть реализована отдельными задачами. Аппаратно сохраняется в TSS (task status segment);
3) Поиск обработчика прерываний. Информация об обработчиках прерываний хранится в специальных таблицах. В реальном режиме таблицы векторов прерываний хранятся по нулевому адресу. Каждый элемент таблицы – точка входа в процедуру обработки прерывания. В таблице 256 элементов. Каждая строка 4 байта: сегмент и смещение. С шины данных процедур снимает код прерывания – это номер элемента в таблице. В защищенном режиме для подключения обработчиков прерываний используется таблица IDT (interrupt descriptor table). Таблица IDT содержит системные дескрипторы – шлюзы 3-х типов: шлюзы прерываний (автоматически сбрасывается IF), шлюзы ловушек (это другие ловушки), шлюзы задач (не нужно заботиться о сохранении контекста). {шаги 1, 2, 3 – аппаратно};
4)Обработка (программная часть);
5)Возобновление выполнения программы (IRET – восстанавливает еще и регистр флагов в отличие от RET). {В некоторых системах 3 – программно}
40 Структурная схема обработки исключений в Windows (SEH): обработка завершения и локальная раскрутка.
Структурная схема обработки исключений в Win32: Схема обработки прерываний в среде Windows, т.е. сервис, предоставляемый в распоряжение программиста для обеспечения своей собственной обработки прерываний SEH (Structured Exception Handling) состоит из 2-х конструкций: 1) обработка завершения; 2) обработка исключения. {Более ранней схемой обработки исключений было использование конструкции on error (вложить их друг в друга нельзя)}
Обработка завершения: Назначение этой конструкции состоит в том, чтобы обязательно был выполнен фрагмент кода, завершающий выполнение блока операторов в программе, независимо от условий, которые могут возникнуть при выполнении этих операторов. Конструкция __try {/*защищенный блок*/} __finally {/*обработчик завершения*/} позволяет выполнить обработчик завершения независимо от того, произошла ли ошибка при выполнении операторов защищенного блока: осуществляется корректный выход из любой ситуации, которая может произойти при выполнении операторов защищенного блока.
Пример 1:
DWORD ProcEx1() {DWORD dwTemp;
__try{WaitForSingleObject (hSem, INFINITE); dwTemp=5;
return dwTemp} __finally{ReleaseSemaphore (hSem, 1, NULL)}; dwTemp=9;/*никогда не будет выполняется*/
return dwТemp;/*никогда не будет выполняется*/} //всегда возвращает 5.
60
После выполнения блока finаllу функция фактически завершает работу. Любой код за блоком finally не выполняется, поскольку возврат из функции происходит внутри блока try. Так что функция возвращает 5 и никогда — 9.
Каким же образом компилятор гарантирует выполнение блок finally до выхода из блока try? Дело вот в чем. Просматривая исходный текст, компилятор видит, что Вы вставили return внутрь блока try. Тогда он генерирует код, который сохраняет возвращаемое значение (в нашем примере 5) в созданной им же временной переменной.
Затем создаст код для выполнения инструкций, содержащихся внутри блока finally, — это называется локальной раскруткой (local unwind) Точнее, локальная раскрутка происходит, когда система выполняет блок finаllу из-за преждевременною выхода из
блока try. Значение временной переменной, сгенерированной компилятором, возвращается из функции после выполнения инструкций в блоке finаllу.
Чтобы все это вытянуть, компилятору приходится генерировать дополнительный код, а системе — выполнять дополнительную работу. На разных типах процессоров поддержка обработчиков завершения реализуется по-разному. Например, процессору А1рhа понадобится несколько сотен или даже тысяч машинных команд, чтобы перехватить преждевременный возврат из try и вызвать код блока finаlly.
Локальная раскрутка — преждевременный выход из блока try (из-за операто ров goto, longjump, continue, break, return и т. д.), вызывающий принудительную передачу управления блоку finаllу.
41 Структурная схема обработки исключений в Windows (SEH): обработка исключений и глобальная раскрутка.
Структурная схема обработки исключений в Win32: Схема обработки прерываний в среде Windows, т.е. сервис, предоставляемый в распоряжение программиста для обеспечения своей собственной обработки прерываний SEH (Structured Exception Handling) состоит из 2-х конструкций: 1) обработка завершения; 2) обработка исключения. {Более ранней схемой обработки исключений было использование конструкции on error (вложить их друг в друга нельзя)}
Обработка исключений: Конструкция: __try{/*защищенный код*/} __except(фильтр исключений) {/*обработчик исключений*/}
Если при выполнении кода из блока __try {...}, возникает ИС, то ОС перехватит его и приступит к поиску блока __except. Найдя его, она передаст управление фильтру ИС. Фильтр ИС м. получить код ИС и на основе этого кода принять решение, передать управление обработчику или же сказать системе, чтобы она искала предыдущий по вложенности блок __except. Фильтры: 1) EXCEPTION_EXECUTE_HANDLER=1 (говорит системе, что для этого блока __try есть обработчик исключения и он готов обработать это исключение); 2) EXCEPTION_CONTINUE_SEARCH=0 (говорит системе, чтобы она искала предыдущий по вложенности блок __except); 3)
EXCEPTION_CONTINUE_EXECUTION=-1 (говорит системе, чтобы она снова продолжала выполнение с того места кода, который вызвал ИС)
Пример3: PBYTE MemDup(PBYTE pbSrc, int cb){PBYTE pbDup=NULL; __try{ pbDup=(PBYTE)malloc(cb); memcpy(pbDup,pbSrc,cb);}/*копируем блок памяти длиной cb байт из pbSrc в pbDup*/ __except(EXCEPTION_EXECUTE_HANDLER) {free(pbDup); pbDup=NULL;} return(pbDup);} //используем EXCEPTION_EXECUTE_HANDLER, чтобы
61
перехватить все исключения, какие могут возникнуть при выполнении кода из блока _try {...}.
Глобальная раскрутка (ГР): Если фильтр ИС возвращает EXCEPTION_EXECUTE_HANDLER, то дальше происходит ГР. ГР приводит к продолжению обработки всех вложенных блоков try-finally, выполнение которой началось вслед за блоком try-except, и только после этого управление получает сам обработчик исключений. Алгоритм работы ГР: 1) Запомнить место нахождения try; 2) Найти самый «нижний» try; 3) WHILE (try не достигнут) DO BEGIN IF (у текущего блока есть finally)
THEN (выполнить finally); (найти предыдущий вложенный try) END; 4) Выполнить except.
42 Определение файла, атрибуты файлов и именование файлов, понятие каталога (справочника, директории, папки). Примеры.
Файл – это поименованная совокупность данных, объединенных общим назначением, структурированных, содержащих данные в определенном формате, хранящихся на внешних запоминающих устройствах. Чаще всего используются дисковые файлы. Именование файлов обеспечивает для пользователей и программистов доступ к данным, не зависящий от внешних устройств, их характеристик. Длина имени ограничена, некоторые символы запрещены. Эти ограничения определяются операционными системами. Тип файла определяет его организацию, формат представления информации в нем. Информация о типе файла обозначается для пользователя расширением имени файла. У каждого файла есть атрибуты. Значения атрибутов представляются отдельными битами байта, у файла может быть несколько атрибутов сразу. Названия битов байта атрибутов в соответствии с их номерами: 0 - только для чтения; 1 - скрытый; 2 - системный; 3 - метка тома; 4 - файл представляет подкаталог; 5 - атрибут архива.
Понятие каталога и иерархическая организация файл системы на дисках.
Каталоги – файлы, содержащие системную информацию. Каталоги состоят из записей. Каждая запись в этом списке записей имеет определенную структуру, содержат имя, информацию о начальном адресе файла, его атрибуты, дату и время его последней модификации. Информация о расположении каждого блока дисковой памяти, распределенного файлу, храниться в специальной управляющей области диска, называемой таблицей размещения файлов (FAT). Каталог, может содержать файлы и подкаталоги. Т.о. получаем древовидную структуру. У каждого каталога, кроме корневого имеется свое имя. Для выбора конкретного каталога на диске нужно перечислить последовательно все каталоги, которые нужно пройти по ветвям дерева для того, чтобы попасть в искомый каталог. Такой список имен каталогов, разделенных символами '\', называют путем.
Каталог, прямо или косвенно включающий в себя все прочие каталоги и файлы файловой системы, называется корневым. В Unix-подобных ОС он обозначается символом / (дробь, слеш), в DOS и Windows исторически используется символ \ (обратный слеш), но с некоторого времени поддерживается и /.
Термин папка (англ. folder) был введён для представления объектов файловой системы в графическом пользовательском интерфейсе путём аналогии с офисными папками. Он был впервые использован в Mac OS, а в системах семейства Windows
— с выходом Windows 95. Эта метафора стала использоваться в большом числе операционных систем: Windows NT, Mac OS, Mac OS X, а также в средах рабочего стола для систем семейства UNIX.
В этой терминологии папка, находящаяся в другой папке, называется подпапка, вложенная папка или дочерняя папка. Все вместе папки на компьютере представляют иерархическую структуру (дерево каталогов).
43 Понятие и функции файловой системы как подсистемы ОС.
Существует два понятия файловых систем:
62

1. Файловая система как совокупности программ операционной системы (подсистема, часть ОС), реализующих функции управления
данными, размещаемыми на внешних запоминающих устройствах. 2. Файловая система как совокупность данных, размещаемых на внешних запоминающих устройствах, а также служебной информации, используемой для организации хранения этих данных, поиска и выполнения операций над ними.
На каждом внешнем запоминающем устройстве создается своя файловая система. Файловая система ОС отвечает за выполнение следующих операций над файлами: создание и уничтожение, копирование и перемещение на новое место, переименование, поиск файлов по различным признакам, открытие файлов для последующего чтения или записи данных, закрытие файлов после выполнения операций над ними. Для реализации своих функций ФС должна реализовать управление внешней памятью: выделять дисковое пространство для размещения на нем файлов, организовывать быстрый поиск файлов и доступ к хранящимся в них данным, обеспечить надежность и отказоустойчивость работы внешних устройств. Выполнение этих функций требует реализации специальных утилит проверки дисков, выявляющие как их физические повреждения, так и ошибки в файловой системе. Эти утилиты при обнаружении ошибок исправляют их, восстанавливая файловую систему, собирая «мусор». Для хранения данных на внешних устройствах все ОС реализуют разрывные распределения дискового пространства (память на диске выделяется кластерами, не обязательно смежными). Переключение между этими участками требует дополнительного времени. Для ускорения доступа к данным все ОС включают утилиты дефрагментации дисковой памяти. Файлы, расположенные отдельными фрагментами, переписываются в непрерывный участок памяти; файлы или фрагменты, на которые нет ссылок в справочнике, уничтожаются. Файловая система анализирует статистику работы с файлами, чтобы расположить чаще используемые файлы на более быстрых устройствах, собрать вместе совместно используемые файлы. Особенно важны эти функции для сетевых ОС, управляющих работой мощных файл-серверов. В таких ОС реализуется избыточность при хранении данных, оптимизируется способ их размещения на массивах дисков сервера. Сама ОС, представляющая собой комплекс программ, также хранится на диске. При установке системы она размещается на системном диске в корневом каталоге и в специально создаваемых при инсталляции системных каталогах. При ошибках на системном диске есть возможность восстановить систему с помощью загрузочных дисков, которые содержат основные компоненты ОС и утилиты.
Подсистема ввода-вывода и управление внешними устройствами. Управление вводом/выводом и внешними устройствами – еще одна функция ОС, обеспечивающая работу с данными. Данные, которые обрабатываются программой, должны быть помещены в оперативную память, только тогда над ними можно выполнять операции в программе. ОС организует по запросам программ обмен информацией между ОЗУ и внешними (периферийными) устройствами (т.е. обеспечивает ввод/вывод), следит за состоянием устройств, организует бесконфликтную работу с ВУ всех выполняющихся программ, устанавливая порядок доступа к ним. Базовая система ввода/вывода (BIOS) находится в ПЗУ каждого IBM-совместимого ПК. Модуль BIOS реализует наиболее простые и универсальные функции по управлению стандартными периферийными устройствами. В нем содержатся аппаратно-зависимые драйверы стандартных устройств (консольного дисплея и клавиатуры и т.п.); тестовые программы для контроля работоспособности оборудования; программа начальной загрузки. Любая ОС опирается на функции BIOS, поэтому BIOS можно считать как частью аппаратуры, так и «железным» компонентом ОС, установленной на ПК.
63
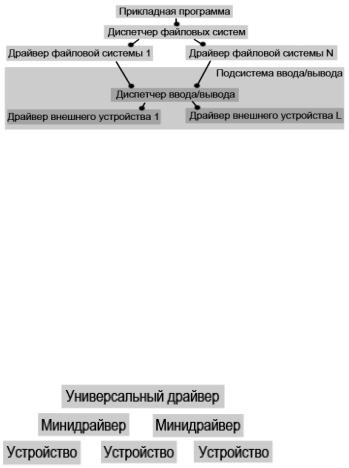
Иерархическая организация файловых систем (как подсистем ОС). Современные ОС включают для реализации управления данными, как минимум, компоненты двух уровней: файловую подсистему и подсистему управления вводомвыводом. Однако для обеспечения максимальной гибкости количество уровней иерархии расширяется.
Реализация файловых систем как драйверов обеспечивает возможность установки новых файловых систем
после установки ОС. Разработчики программного обеспечения могут создавать собственные файловые системы и подключать их, что обеспечивает возможность дополнительной защиты, ориентации управления данными именно на потребности конкретной программы, работающей с внешними устройствами, оптимизации файловой системы. Диспетчер файловой системы обеспечивает независимость разработки прикладной программы от особенностей файловых систем, арбитраж при выполнении операций над файлами. Диспетчер ввода-вывода обеспечивает обслуживание файловой системы, единообразие при работе с различными типами устройств и переадресацию запросов драйверам соответствующих устройств. В свою очередь иерархия может быть расширена за счет выделения нескольких уровней управления внешними устройствами.
Структура файловой системы Windows 95. Файловая система Windows 9x имеет многоуровневую архитектуру. Installable File System Manager – диспетчер устанавливаемой файловой системы. Отвечает за арбитраж доступа к компонентам файловой системы. Драйверы файловой системы являются компонентами нулевого кольца кода ОС.
Поддерживаются: VFAT – 32-битный драйвер
FAT, 32-битный драйвер файловой системы CD-ROM (VCDFS), 32-битный сетевой редиректор для подключения к серверам сетей Microsoft, а также Novell NetWare. Редиректоры отвечают за переадресацию запроса при обращении к сетевым дискам. Может быть загружено любое число редиректоров. Подсистема блочного ввода/вывода включает:
1.Диспетчер ввода/вывода (системный VxD-драйвер), обеспечивающий сервис для файловой системы, отвечающий за поддержку очередности запросов и маршрутизацию запросов к соответствующим драйверам устройств. Загружает и инициализирует драйверы устройств защищенного режима. Получает запросы от VFAT и VCDFS и обеспечивает доступ к локальным дискам и дисковым устройствам.
2.Порт-драйвер – монолитный драйвер защищенного режима, обеспечивающий связь с конкретным дисковым устройством (например, контроллером жесткого диска).
64

3. SCSI-
слой реализует архитектуру универсального драйвера 32-битного защищенного режима. Обеспечивает высокоуровневые функции свойственные SCSI-
устройствам. Для обработки запросов на аппаратно-зависимые операции ввода/вывода он использует минипорт-драйвер. Это «заглушка», обеспечивающая связь с устройствами.
4. Минипорт-драйвер разрабатывается изготовителями дисковых устройств для учета их особенностей.
44 Логическая и физическая организация файлов. Буферизация ввода/вывода. Примеры.
Логическая организация файлов. Логическая организация файлов – это организация данных, размещенных на внешних устройствах, с точки зрения прикладной программы, работающей с этими данными, выполняющей операции над ними. Простейший способ организации – файл представляет собой неструктурированную последовательность байтов. В этом случае программу при выполнении операций над файлами «не интересует» содержимое файла. Такой подход в ОС UNIX и Windows. Плюсы: обеспечивает максимальную простоту файловой системы и файловая система может обеспечить считывание данных «побайтно» или блоками заданного размера. «Смысл» байтам «присваивается» конкретными программами, создающими файлы и обрабатывающими размещенную в них информацию. Существует несколько способов организации файлов: файлы с последовательной организацией, файлы с прямой организацией, файлы с индексной организацией (прямой доступ по ключу) и библиотечные файлы. Еще один способ организации файлов – древовидная организация, при которой файл представляет собой дерево записей, упорядоченных по ключу, записанному в определенной фиксированной позиции каждой записи. Такой способ организации файлов обеспечивает быстрый поиск данных по заданному ключу.
При работе на мэйнфреймах способ доступа к файлу указывается при его создании в описании файла, что позволяет ОС применять различные методы хранения на внешних устройствах файлов разных классов (Принципиальное отличие от UNIX и Windows).
Управление внешней памятью и физическая организация файлов. Для реализации своих функций файловая система ОС должна реализовать управление внешней памятью: выделять дисковое пространство для размещения на нем файлов, организовывать быстрый поиск файлов и доступ к хранящимся в них данным, обеспечить надежность и отказоустойчивость работы внешних устройств.
65

Способы физической организации файла Физическая организация файла (ФОФ) – это способ размещения файла на диске.
Основные критерии эффективности физической организации файлов:
•Скорость доступа к данным.
•Объем адресной информации файла.
•Степень фрагментированнности дискового пространства.
•Максимально возможно размер файла.
Фрагментация – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Существует несколько способов физической организации файла. Непрерывное размещение – это простейший вариант ФОФ, при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти:
Достоинства способа: высокая скорость доступа, так как затраты на поиск и считывание кластеров файла минимальны, отсутствие фрагментации на уровне файла, минимален объем адресной информации – достаточно хранить только номер первого кластера и объем файла. Недостатки невозможно сказать, какого размера должна быть непрерывная область, выделяемая файлу, так как файл при каждой модификации может увеличить свой размер, фрагментация на уровне кластеров, из-за которой нельзя выбрать место для размещения файла целиком. Из-за этих недостатков на практике используются другие методы, при которых файл размещается в нескольких, в общем случае
несмежных областях диска.
Размещение файла в виде связанного списка кластеров дисковой памяти.
При таком способе в начале каждого кластера содержится указатель на следующий кластер:
Достоинства: Адресная информация минимальна расположение файла может быть задано одним числом – номером первого кластера, фрагментация на уровне кластеров отсутствует, так как каждый кластер может быть присоединен к цепочке кластеров какого-либо файла, файл может изменять свой размер, наращивая число кластеров.
Недостатки: Сложность организации доступа к произвольно заданному месту файла – чтобы прочитать пятый по порядку кластер файла, необходимо последовательно прочитать четыре первых кластера, прослеживая цепочку номеров кластеров, количество данных файла в одном кластере не равно степени двойки (одно слово израсходовано на номер следующего
кластера), а многие программы читают данные кластерами, размер которых равен степени двойки, Фрагментация на уровне файлов (файл может разбиваться на несмежные фрагменты).
Буферизация (кэширование) ввода/вывода. Запросы к блок-ориентированным ВУ с прямым доступом перехватываются подсистемой буферизации, называемой также дисковым кэшем. Буфер – это область памяти, используемая для промежуточного
66
хранения данных при выполнении операций ввода/вывода. Буфер инициализируется при открытии файла. При поступлении запроса на чтение некоторого блока диспетчер дискового кэша просматривает свой буферный пул, находящийся ОП, и если требуемый блок имеется в кэше, копирует его в буфер запрашивающего процесса. Подготовка следующих данных для чтения может осуществляться ОС параллельно с работой программы (то есть операции ввода/вывода выполняются асинхронно). При записи данные также сначала попадают в буфер. На диск они переписываются при заполнении или же по требованию программы. Операция вывода считается выполненной при завершении обмена с кэшем, то есть реализуется механизм отложенной записи на диск.
45 Логическая организация файлов: файлы с последовательной организацией и индексированные файлы. Поиск на внешних устройствах, B-деревья: определение и построение, выполнение операций. Примеры.
Логическая организация файлов. Логическая организация файлов – это организация данных, размещенных на внешних устройствах, с точки зрения прикладной программы, работающей с этими данными, выполняющей операции над ними. Простейший способ организации – файл представляет собой неструктурированную последовательность байтов. В этом случае программу при выполнении операций над файлами «не интересует» содержимое файла. Такой подход в ОС UNIX и Windows. Плюсы: обеспечивает максимальную простоту файловой системы и файловая система может обеспечить считывание данных «побайтно» или блоками заданного размера. «Смысл» байтам «присваивается» конкретными программами, создающими файлы и обрабатывающими размещенную в них информацию. Существует несколько способов организации файлов: файлы с последовательной организацией, файлы с прямой организацией, файлы с индексной организацией (прямой доступ по ключу) и библиотечные файлы. Еще один способ организации файлов – древовидная организация, при которой файл представляет собой дерево записей, упорядоченных по ключу, записанному в определенной фиксированной позиции каждой записи. Такой способ организации файлов обеспечивает быстрый поиск данных по заданному ключу.
При работе на мэйнфреймах способ доступа к файлу указывается при его создании в описании файла, что позволяет ОС применять различные методы хранения на внешних устройствах файлов разных классов (Принципиальное отличие от UNIX и Windows).
Последовательная организация. При последовательной организации файл представляет собой «массив», в котором в каждый момент содержится определенное число записей (от 0 и более): R0 R1 ... R(i-1) Ri R(i+1) ... Rn. Для того чтобы прочитать запись Ri необходимо прочитать все предшествующие ей записи, т.е. запись Ri может быть прочитана только после записи Ri–1. Записи в файле могут иметь переменный размер. Тогда каждой записи должно предшествовать поле, содержащее ее длину: L0 R0 L1 R1 ...
L(i-1) R(i-1) Li Ri L(i+1) R(i+1) ... Ln Rn. Поле длины может располагаться и после записи, тогда допустимо считывание записей и при «обратном» – с конца – просмотре файла. Файлы с такой организацией могут размещаться на любых внешних устройствах. Эта организация удобна, когда обрабатывается весь массив записей. Если необходимо обработать только определенные записи, то этот способ неудобен, т.к. в худшем случае для поиска нужной записи необходимо выполнить n сравнений.
Файлы с прямой и индексной организацией. Многие системы допускают возможность прямого доступа к записи в файле по ее номеру. Минус в том, что программист должен сам «помнить» номера записей, содержащих нужную информацию. Для этого он должен построить специальный файл, содержащий эту информацию, причем
67
записи в этом файле могут быть упорядочены для ускорения поиска нужной информации. Обычно ускорение происходит еще и за счет того, что записи вспомогательного значительно короче, чем записи основного файла, содержащего полную информацию. Если система сама берет на себя задачу организации таких вспомогательных файлов (таблиц), то говорят об индексной организации файлов. Файлы с индексной организацией имеют более сложную организацию: кроме основного файла, представляющего собой массив записей, строится вспомогательная таблица (индекс), содержащая ключевую информацию для поиска, а также данные о местоположении записи в основном файле (смещение начала файла); кроме того, если записи могут иметь переменную длину, в каждой строке (элементе, записи) индекса содержится и размер записи. Записи в основном файле не упорядочиваются, хранятся в нем в том порядке, в каком были созданы. Записи в индексе обычно упорядочиваются для ускорения поиска. Ключи могут быть составными, например, могут состоять из фамилии, имени и отчества. Ключи могут быть и внешними по отношению к соответствующей записи. Индексы могут быть многоуровневыми. Строится «индекс для индекса»: индекс второго уровня. Для его создания таблица индексов первого уровня разбивается на блоки, содержащие определенное количество элементов. Каждый блок идентифицируется ключом (обычно это ключ последнего элемента в блоке).
Используются древовидные структуры для организации индексов. Использовать бинарные деревья весьма не эффективно, т.к. придется читать данные поэлементно, а обработка данных на внешних устройствам осуществляется блоками. Поэтому используют B-деревья - сбалансированное, сильно ветвистое дерево во внешней памяти (поиск, добавление и удаление элементов за O(log n). B-дерево с n узлами имеет высоту O(log n)). N- минимальная степень б – дерева, не меньшая 2. Если происходит обращение к одному элементу, расположенному во внешней памяти, то без больших затрат можно обратиться и к целой группе элементов; поэтому в каждой вершине дерева располагается не один элемент, а группа элементов, называемых страницей.
Обращение к странице требует всего одного обращения к диску, что позволяет значительно сэкономить время на числе обращений и, тем самым, снизить сложность алгоритмов поиска, включения и исключения.
•Каждая вершина может содержать не более чем 2n элементов;
•Все листья находятся на одном уровне;
•В вершине элементы упорядочены по ключу;
•Для всех вершин (кроме корня) есть ограничения: от n до 2n элементов включительно;
•Страницы могут быть заполнены не полностью;
•В корне от 1 до 2n элементов включительно;
•Если внутренняя страница содержит К элементов, то у нее К + 1 дочерних страниц.
46 Управление внешней памятью: карты памяти и списки. Примеры
(FAT, NTFS).
Управление внешней памятью и физическая организация файлов. Для реализации своих функций файловая система ОС должна реализовать управление внешней памятью: выделять дисковое пространство для размещения на нем файлов, организовывать быстрый поиск файлов и доступ к хранящимся в них данным, обеспечить надежность и отказоустойчивость работы внешних устройств.
Физическая организация файлов (на примере FAT и NTFS). FAT (File Allocation Table - таблицы распределения данных; таблица FAT в MS-DOS [FAT12, FAT16, FAT-16]
68
иWindows 95/98/ME [FAT32, FAT-32]). FAT - таблица для динамического распределения дискового пространства под файлы. Число в аббревиатуре указывает размер элемента таблицы в битах. Единицей распределяемой памяти является кластер. В FAT записывается номер кластера или служебная информация о его состоянии. Переход с FAT16 на FAT32 вызван тем, что при использовании FAT16 размер дискового раздела не может быть больше 2 Гбайт. Таблица обеспечивает связи одного распределяемого блока (одного или нескольких кластеров) с другим. В FAT находятся списки кластеров, распределённых файлам. Все свободные кластеры отмечены нулями. Таким образом, если файл занимает несколько кластеров, то эти кластеры связаны в список. При этом элементы таблицы FAT содержат номера следующих используемых данным файлом кластеров. Конец списка отмечен в таблице специальным значением. Номер первого кластера, распределённого файлу, хранится в элементе каталога, описывающего данный файл. Если размер диска таков, что для представления всех секторов недостаточно 12-ти разрядов, можно увеличить размер кластера, например, до восьми секторов. Однако большой размер кластера приводит к неэффективному использованию дискового пространства. FAT имеет древовидную структуру. В корневом каталоге располагаются 32-байтовые элементы, которые содержат информацию о файлах и других каталогах. Корневой каталог занимает непрерывную область фиксированного размера. Размер корневого каталога задаётся при форматировании и определяет максимальное количество файлов и каталогов, которые могут быть в нём описаны. Вслед за корневым каталогом на логическом диске находится область файлов и подкаталогов корневого каталога.
NTFS (New Technology File System). NTFS обеспечивает комбинацию эффективности
инадёжности, отсутствующую в FAT. Она разработана для быстрого выполнения стандартных файловых операций типа чтения, записи и поиска, а так же операций типа восстановления файловой системы после сбоев на больших дисках. NTFS так же имеет возможности безопасности, необходимые для файловых серверов и высокопроизводительных рабочих станций в корпоративной среде. Эта файловая система поддерживает управление доступом к данным и привилегии владельца, что является важным для защиты данных. NTFS файловая система Windows NT и Windows 2000, поддерживающая объектно-ориентированные приложения, рассматривая файлы как объекты с атрибутами, определенными пользователями или системой. Подразумевает также метод логической разметки диска, управления дисковой памятью и организации доступа к файлам. NTFS обеспечивает все возможности файловых систем FAT и HPFS без их ограничений. Поддерживается также Windows 95. Каждый файл на разделе NTFS представлен записью в специальном файле, называемом главной файловой таблицей (Master File Table) . NTFS резервирует первые 16 записей таблицы для системной информации. Первая запись этой таблицы описывает саму MFT; за ней следует зеркальная запись MFT. Если первая запись MFT окажется разрушенной, то ОС использует вторую запись для отыскания зеркального файла MFT, первая запись которого идентична первой записи MFT. Расположение сегментов данных MFT и её копии записаны в секторе начальной загрузки. Дубликат сектора начальной загрузки находится в логическом центре диска. Третья запись MFT — файл регистрации, используется для восстановления целостности файловой системы при сбоях. Семнадцатая и последующие записи главной файловой таблицы используются собственно файлами и каталогами (которые так же рассматриваются как файлы). Главная файловая таблица отводит определённое количество пространства для каждой записи файла. Атрибуты файла записываются
в распределённое пространство MFT. Небольшие файлы и каталоги могут полностью содержаться внутри записи главной файловой таблицы. Подобный подход обеспечивает очень быстрый доступ к файлам. Записи каталога помещены внутри главной файловой таблицы так же, как и записи файла. Вместо данных каталоги содержат индексную
69

информацию. Небольшие каталоги находятся полностью внутри структуры MFT. Большие каталоги организованы в B-Tree, имея записи с указателями на внешние кластеры, содержащие элементы каталога, которые не могут быть записаны внутри MFT.
47 Управление вводом/выводом, понятие драйвера внешнего устройства, драйверы виртуальных устройств.
Управление вводом/выводом и внешними устройствами. Понятие драйвера. Еще одна функция ОС, обеспечивающая работу с данными. ОС организует по запросам программ обмен информацией между ОЗУ и внешними устройствами (то есть обеспечивает ввод/вывод), следит за состоянием устройств, организует бесконфликтную работу с ВУ всех выполняющихся программ, устанавливая порядок доступа к ним. Для управления внешними устройствами на компьютерах устанавливаются специальные программы – драйверы. Драйверы образуют «прослойку» между ядром ОС и внешними устройствами, скрывая их особенности от работающих с этими устройствами программ. При изменении конфигурации ВС нет необходимости в переустановке всей системы, достаточно установить новый драйвер внешнего устройства.
Архитектура «универсальный драйвер/минидрайвер» (используется в Win 9x).
Универсальный драйвер включает большую часть кода, необходимую конкретному классу устройств для «общения» ОС и устройства. Содержит код для управления целой категорией устройств в рамках общего стандарта для этой категории. Минидрайвер – небольшой простой драйвер, содержащий дополнительные инструкции, необходимые для управления конкретным устройством, учитывающий его особенности.
Общая схема программы прерывания драйвера. 1. сохранение всех регистров; 2)
чтение команды из заголовка (и считывание дополнительной информации при необходимости); 3) передача управления процедуре выполнения команд с заданным кодом и ее выполнения, если команда поддерживается драйвером; 4) передача данных (если этого требует выполнение команды); 5) установка слова состояния устройства; 6) восстановление регистров; 7) возврат управления ОС.
Драйвер виртуального устройства (Virtual Device Driver). В системах с большим количеством устройств организация их бесконфликтной работы является сложной задачей. В Windows 9x используется понятие виртуального устройства. Каждое приложение работает не с реальным устройством, а с виртуальным. Запрет прямого обращения к аппаратным ресурсам предотвращает конфликты при одновременной работе с устройствами нескольких программ. Драйверы виртуальных устройств позволяют осуществлять управление системными ресурсами, которые одновременно используются более чем одним приложением (например, виртуальные драйверы дисплея, принтера и т.п.). ДВУ– 32-битный драйвер PM, управляющий каким-либо системным ресурсом (аппаратным или программным) и позволяющий использовать это устройство более чем одному приложению.
48 Понятие драйвера файловой системы. Иерархическая организация файловых систем. Примеры.
Структура файловой системы Windows 95. Файловая система Windows 9x имеет многоуровневую архитектуру. Installable File System Manager – диспетчер устанавливаемой файловой системы. Отвечает за арбитраж доступа к компонентам файловой
70
системы. Драйверы файловой системы являются компонентами нулевого кольца кода ОС. Поддерживаются: VFAT – 32-битный драйвер FAT, 32-битный драйвер файловой системы CD-ROM (VCDFS), 32-битный сетевой редиректор для подключения к серверам сетей Microsoft, а также Novell NetWare. Редиректоры отвечают за переадресацию запроса при обращении к сетевым дискам. Может быть загружено любое число редиректоров. Подсистема блочного ввода/вывода включает:
1.Диспетчер ввода/вывода (системный VxD-драйвер), обеспечивающий сервис для файловой системы, отвечающий за поддержку очередности запросов и маршрутизацию запросов к соответствующим драйверам устройств. Загружает и инициализирует драйверы устройств защищенного режима. Получает запросы от VFAT и VCDFS и обеспечивает доступ к локальным дискам и дисковым устройствам.
2.Порт-драйвер – монолитный драйвер защищенного режима, обеспечивающий связь с конкретным дисковым устройством (например, контроллером жесткого диска).
3. SCSI-
слой реализует архитектуру универсального драйвера 32-битного защищенного режима. Обеспечивает высокоуровневые функции свойственные SCSI-
устройствам. Для обработки запросов на аппаратно-зависимые операции ввода/вывода он использует минипорт-драйвер. Это «заглушка», обеспечивающая связь с устройствами.
4. Минипорт-драйвер разрабатывается изготовителями дисковых устройств для учета их особенностей.
Иерархическая организация файловых систем (как подсистем ОС). Современные ОС включают для реализации управления данными, как минимум, компоненты двух уровней: файловую подсистему и подсистему управления вводомвыводом. Однако для обеспечения максимальной гибкости количество уровней иерархии расширяется.
Реализация файловых систем как драйверов обеспечивает возможность установки новых файловых систем
после установки ОС. Разработчики программного обеспечения могут создавать собственные файловые системы и подключать их, что обеспечивает возможность дополнительной защиты, ориентации управления данными именно на потребности конкретной программы, работающей с внешними устройствами, оптимизации файловой системы. Диспетчер файловой системы обеспечивает независимость разработки прикладной программы от особенностей файловых систем, арбитраж при выполнении
71
операций над файлами. Диспетчер ввода-вывода обеспечивает обслуживание файловой системы, единообразие при работе с различными типами устройств и переадресацию запросов драйверам соответствующих устройств. В свою очередь иерархия может быть расширена за счет выделения нескольких уровней управления внешними устройствами.
49 Понятие защищённой ВС. Классификация угроз и вторжений. Структура системы защиты.
Понятие защищенной ВС. ВС защищенная, если все операции в ней выполняются в соответствии с правилами, которые обеспечивают непосредственную защиту объектов ВС и операций в ней. Понятие объекта включает ресурсы ВС (все ее компоненты, информация, аппаратное и программное обеспечение) и пользователей. Все объекты ВС должны быть зарегистрированы в ней. Для информационных ресурсов должен быть определен порядок работы с ними, допустимые операции. Система защиты должна обеспечивать контроль доступа к данным и их защиту. Все пользователи, пытающиеся получить доступ к информации должны себя идентифицировать определенным способом.
Классификация угроз и вторжений. Угроза безопасности - действие или событие, которое может привести к разрушению, искажению или несанкционированному использованию ресурсов ВС. Угрозы м.б. случайными и умышленными. Источником случайных угроз могут быть ошибки в программном обеспечении, выходы из строя аппаратных средств, неправильные действия пользователей, операторов и т.п. Умышленные угрозы преследуют цели, связанные с нанесением ущерба пользователям сети. Умышленные угрозы м.б. активными и пассивными. При пассивном вторжении злоумышленник только наблюдает за прохождением и обработкой информации, не вторгаясь в информационные потоки. Эти вторжения направлены на несанкционированное использование информационных ресурсов ВС, не оказывая при этом влияния на ее функционирование. Активные вторжения нарушают нормальное функционирование ВС, вносят несанкционированные изменения в информационные потоки, в хранимую и обрабатываемую информацию. Эти угрозы реализуются посредством целенаправленного воздействия на ее аппаратные, программные и информационные ресурсы. Источниками этих угроз могут быть непосредственные действия злоумышленников или программные вирусы и т.п. В общем случае пассивные вторжения легче предотвратить, но сложнее выявить, в то время как активные вторжения легко выявить, но сложно предотвратить. Основные угрозы безопасности: отказ в обслуживании; ошибочное или несанкционированное использование ресурсов ВС, в частности: несанкционированный обмен информацией, раскрытие конфиденциальной информации и отказ от информации.
Структура системы защиты и основные функции ее компонентов. ВС должна обеспечивать защиту ресурсов, прав пользователей ВС. Линии связи являются уязвимым компонентом ВС, поэтому они тоже требуют защиты. Программное обеспечение также должно быть защищено. Все средства защиты ВС могут быть отнесены к одной из следующих групп: защита объектов ВС, защита линий связи, защита баз данных, защита подсистемы управления ВС. Система защиты - совокупность средств и технических приемов, обеспечивающих защиту компонентов ВС, минимизацию риска, которому могут быть подвержены ее ресурсы и пользователи. Они представляют собой комплекс процедурных, логических и физических мер, направленных на предотвращение, выявление и устранение сбоев, отказов и ошибок, несанкционированного доступа в вычислительную систему. Управление защитой - это контроль за распределением информации в открытых системах. Он осуществляется для обеспечения
72
функционирования средств и механизмов защиты, фиксации выполняемых функций и состояний механизмов защиты и фиксации событий, связанных с нарушением защиты.
50 Контроль прав доступа и матрица прав доступа как математическая модель защиты объектов. Примеры: одноранговое разделение ресурсов и защита на уровне пользователей.
Матрица прав доступа как математическая модель защиты объектов.
Математической моделью, описывающей полномочия объектов является матрица доступа. Строки и столбцы матрицы соответствуют объектам вычислительной системы (пользователям и ресурсам). Каждый элемент матрицы описывает права доступа пользователя к соответствующему ресурсу). Реализуется на практике матрица прав доступа через списки прав доступа или мандатные списки. Эти списки приписываются объектам ИВС и соответствуют строкам или столбцам матрицы прав доступа. Эти данные сохраняются в специальных базах данных системы защиты.
Защита на уровне разделяемых ресурсов (одноранговое разделение ресурсов) в
Windows 9x. Если на компьютере запущен сервис однорангового разделения ресурсов, то предусматривается защита на уровне разделяемых ресурсов. Каждому разделяемому ресурсу назначается индивидуальный пароль и только на его основе пользователи получают доступ к этому ресурсу. Для установки защиты на уровне разделяемых ресурсов нужно установить сервис разделяемых ресурсов. Защиту на уровне разделяемых ресурсов можно реализовать в одноранговой сети на компьютерах, работающих под управлением Windows 95/98. Пользователь, работающий в одноранговой сети, может получить доступ к ресурсу, если он знает пароль, который определяет доступ к этому ресурсу. Применение одноранговых серверов в локальных сетях позволяет увеличить защищенное пространство для хранения данных и обеспечить доступ к принтерам, не затрачивая на это значительных средств.
Защита на уровне пользователей в Novell NetWare (пользователи и группы пользователей, единая регистрация в Novell NetWare 4, права на объекты и свойства объектов; контекст и определение прав через прямое назначение, наследование, эквивалентность, фильтры). 1) единая регистрация в Novell NetWare 4: NDS - это специальная база данных, позволяющая эффективно управлять всеми ресурсами сети и группировать их с помощью объектов. Обеспечивает единую регистрацию. Преимущества: 1) позволяет пользователю регистрироваться в сети только один раз; 2) упрощается администрирование (нет необходимости создавать несколько учетных записей для пользователя на каждом сервере), администратор обслуживается лишь одну запись, а информация в процессе тиражирования автоматически распространяется в сети.
2) права на объекты и свойства объектов: существует ещё один способ защиты в Novell NetWare, который позволяет для каждого пользователя сети определить доступные ему каталоги и права доступа данного пользователя к каждому из них, позволяющие пользователю работать с каталогом или файлом определенным образом. Каждое такое "право" определяет какую-либо операцию, которая будет доступна для пользователя или нет, в данном каталоге или для данного файла. Каждое из прав обозначается соответствующей буквой, эти обозначения записываются в квадратных скобках в определенном порядке (каждой букве соответствует определенный бит). Данные обозначения представляют привилегии администратора группы.
3) пользователи и группы пользователей, контекст и определение прав через прямое назначение, наследование, эквивалентность, фильтры: системные ограничения определяются для пользователей, когда эти пользователи создаются. Можно назначать
73
попечительские права пользователям или группам пользователей. После ввода сетевого имени при регистрации в сети пользователь вводит пароль. При создании пользователя могут быть введены требования на время обновления паролей. Администратор назначает права в зависимости от того, какие функции должен выполнять пользователь/группа пользователей. Если пользователь принадлежит к нескольким группам, то он получает права членов каждой из них и администратор может предоставить пользователю дополнительные индивидуальные права. Кроме администраторов с полномочиями супервизора могут быть зарегистрированы - администраторы рабочих групп, которым даны особые права на создание, удаление пользователей в своих группах и управление ими, и администраторы учетных данных пользователей, имеющие возможность управлять пользователями и удалять их, но не создавать.
В NetWare используется два типа контекстов: контекст объекта (пользователя), контекст базы объектов сервера. Контекст объекта - это позиция объекта в дереве NDS. Если два объекта находятся в одном и том же контейнере, то они имеют один и тот же контекст. Контекст базы объектов определяет, в каком объекте серверу следует искать объекты на базе Bindery и используется, чтобы определить, какие объекты доступны через Bindery Services. Объекты Bindery – это объекты, которые созданы в NetWare 3, или другие объекты, не распознаваемые NDS как свои собственные объекты.
Прямое назначение прав – это явное назначение полномочий объекту. Эквивалентность - это когда один объект приравнивается по правам к другому. Этот способ работает при использовании групп и ролевых объектов. Наследование - это метод, при котором права на объекты передаются вниз, на подчиненные уровни дерева. Такие права называются наследуемыми полномочиями. При наследовании права передаются объекту более низкого уровня без явного присваивания. Наследоваться могут только полномочия на объекты, права на файлы и каталоги, права категории. Фильтры (IRF – Inherited Rights Filter) применяются для управления наследованием прав. Фильтр можно применить к любому объекту, этот фильтр является включающим. Правила действия фильтра: не может предоставлять полномочий, он может лишь отменять ранее назначенные права; можно определить фильтр для любого объекта, характеристики, файла и каталога; можно отменить права и характеристики объекта супервизора; права супервизора на файлы и каталоги отменить нельзя.
51. Криптографическая защита. Понятие ключа. Симметричное и асимметричное шифрование. Понятие криптографического протокола. Понятие цифровой подписи.
Криптографическая защита. Криптография – это защита информации с помощью шифрования. Шифрование – это преобразование "открытого текста" с целью сделать непонятным его смысл. Шифрование – наиболее широко используемый механизм защиты информации в ВС. Шифрование используется для обеспечения защиты паролей, применяемых для аутентификации пользователей, для защиты системной информации, для защиты информации, передаваемой по линиям связи, для защиты данных в файлах и базах данных. Криптографический алгоритм (шифр) – это математические функции, используемые для шифрования и расшифрования. Надежность криптографического алгоритма обеспечивается с помощью использования ключей. Функции шифрования и расшифрования зависят от ключей. Выбор конкретного типа преобразования определяется ключом. Зашифрованный текст всегда можно восстановить (расшифровать) в исходном виде, зная соответствующий ключ. Можно использовать различные ключи для шифрования и расшифрования.
74
Криптосистема - алгоритм шифрования, а также множество всевозможных ключей, открытых и шифрованных текстов. Существует две разновидности алгоритмов шифрования с использованием различных типов ключей: криптосистемы с открытым ключом (ассиметричные) и симметричные криптосистемы. Симметричный - криптографический алгоритм, в котором используется один и тот же ключ для шифрования и расшифрования. Ключ, используемый для шифрования сообщения, может быть получен из ключа расшифрования и наоборот. Такие алгоритмы называются одноключевыми. При использовании таких систем отправитель и получатель информации должны договориться о том, какой ключ будет использоваться. Надежность шифрования определяется выбором ключа, поэтому ключ необходимо хранить в тайне. Асимметричный - алгоритм, устроенный так, что ключ, используемый для шифрования, отличается от ключа, применяемого для расшифровки сообщения, и ключ расшифрования не может быть вычислен через ключ шифрования. Поэтому ключ шифрования не требуется держать в тайне, и он называется открытым. Ключ же расшифрования является тайным. Ассиметричные системы шифрования используются для шифрования не сообщений, а ключей при их передаче по сети. Работа с ключами является уязвимым местом в любой криптосистеме. Ключи нуждаются в такой же защите, как и информация. Необходимо обеспечивать секретность ключей. Хороший ключ представляет собой случайный битовый вектор. Чтобы снизить вероятность взлома, необходимо изменять ключ. Если надо передать ключи, то они должны передаваться в зашифрованном виде, по защищенным линиям связи, недоступным для прослушивания. Ключи могут передаваться по частям, а для передачи каждой части можно использовать новую линию связи. Ключи должны проверяться при получении на подлинность.
Протокол – это совокупность правил, определяющих процедуру взаимодействия, т.е. последовательность шагов, которые предпринимаются двумя или большим количеством сторон для совместного решения какой-либо задачи. Криптографический протокол - протокол, в основе которого лежит криптографический алгоритм. Их используют для совместной подписи договора или удостоверения личностей, например. Здесь криптография нужна, чтобы предотвратить или обнаружить вмешательство посторонних лиц, не являющихся участниками взаимодействия, не допустить мошенничество. Криптографический протокол гарантирует, что стороны, участвующие в решении определенной задачи, не могут сделать или узнать больше того, что определено соответствующим протоколом.
Цифровые подписи. Для подтверждения подлинности документа люди используют личные подписи. С развитием электроники встала проблема виртуального подтверждения подлинности документов. Развитие таких технологий требует существования электронных (цифровых) подписей под электронными документами. Для подтверждения подлинности файлов, электронных документов также можно использовать подписи. При получении сообщения участник взаимодействия должен иметь возможность проверки его подлинности. Часто возникают случаи, когда получатель информации должен доказать ее подлинность внешнему лицу. Для этого передаваемым сообщениям должны быть приписаны так называемые цифровые сигнатуры (электронные подписи). Цифровая сигнатура – это строка символов, зависящая как от идентификатора отправителя, так и от содержания сообщения. Никто (кроме самого отправителя информации) не может вычислить его цифровую подпись для конкретного передаваемого им сообщения. Никто (и даже сам отправитель!) не может изменить уже отправленного сообщения так, чтобы сигнатура (электронная подпись под сообщением) осталась неизменной. Получатель должен быть способен проверить, является ли электронно-цифровая подпись (сигнатура), присвоенная сообщению, подлинной. В конфликтной ситуации внешнее лицо должно быть способно проверить, действительно ли цифровая сигнатура, приписанная
75
сообщению, выполнена его отправителе. Используя цифровые подписи можно организовать заключение сделок с использованием вычислительных сетей. Цифровые подписи могут быть реализованы на основе шифрования с секретными ключами (при симметричном шифровании), кроме того, допускается возможность подтверждения фактов передачи сообщений с помощью посредников, участвующих в процессе обмена информацией. Классическим примером схемы электронно-цифровой подписи является алгоритм DSA. Алгоритм DSA реализует схему на основе использования хэш-функций и асимметричного шифрования.
76
1.Примеры задач по обработке исключений
1.Какое значение возвращает функция:
DWORD FuncCounter(void)
{DWORD dwTemp = 0; while (dwTemp < 10)
{
__try
{ if (dwTemp == 2) continue;
if (dwTemp == 3) break;
}
__finally
{ dwTemp ++; } dwTemp ++;
}
dwTemp +=10; return (dwTemp);
}
Ответ: 14
2. Какое значение возвращает функция:
DWORD FuncExm (void) { DWORD dwTemp = 0;
.......................................
__try
{
WaitForSingleObject (g_hSem, INFINITE) ; g_dwProtectedData = 5 ;
dwTemp = g_dwProtectedData ; return (dwTemp);
}
__finally
{
dwTemp = g_dwProtectedData + 100 ; ReleaseSemaphore (g_hSem, 1, NULL) ; return (dwTemp) ;
}
dwTemp = 100 ; return (dwTemp);
}
Ответ: 105
3. Что явится результатом выполнения этой функции: void ExceptFun (void)
{ int x = 0;
char * lpBuffer = NULL ; __try {
*lpBuffer = ‘A’ ;
x= 100 / x ;
}
__except (ExceptFilter(&lpBuffer)) {
MessageBox(NULL, “An Exception occurred”, NULL, MB_OK) ;
}
MessageBox(NULL, “Function completed”, NULL, MB_OK) ;
}
LONG ExceptFilter (char **lplpBuffer) { if (* lplpBuffer == NULL)
{ * lplpBuffer = g_szBuffer ; // Global buffer pointer return (EXCEPTION_CONTINUE_EXECUTION) ;
}
77
return (EXCEPTION_EXECUTE_HANDLER) ;
}
Обоснование:
В первый раз проблема возникает, когда мы пытаемся поместить А в буфер, на который указывает lpBuffer К сожалению, мы не определили lpBuffer как указатель на наш глобальный буфер g_szBuffer — вместо этою он указывает на NULL. Процессор генерирует исключение и вычисляет выражение в фильтре исключений в блоке except, связанном с блоком try, в котором и произошло исключение. В блоке except адрес переменной plBuffer передается функции ExceptFilter. Получая управление ExceptFilter проверяет, не равен ли *lplpBuffer значению NULL, и, если да, устанавливает его так, чтобы он указывал на глобальный буфер g_szBuffer. Тогда фильтр возвращает EXCEPTION_CONTINUE_EXECUTION. Обнаружив такое значение выражения в фильтре, система возвращается к инструкции, вызвавшей исключение, и пытается выполнить ее снова. На этот раз все проходит успешно, и А будет записана в первый байт буфера g_szBuffer. Когда выполнение кода продолжится, мы опять столкнемся с проблемой в блоке try — теперь это деление на нуль. И вновь система вычислит выражение фильтра исключений. На этот раз *lplpBuffer не равен NULL, и
поэтому ExceptFilter вернет EXCEPTION_EXECUTE_HANDLER, что подскажет системе выполнить код в блоке except, и на экране появится окно с сообщением o исключении.
4. Что явится результатом выполнения этой функции: void ExceptFun (void)
{int x = 0;
char * lpBuffer = NULL ;
__try {
*lpBuffer = ‘A’ ;
x= 100 / x ;
}
__except (ExceptFilter(&lpBuffer)) {
MessageBox(NULL, “An Exception occurred”, NULL, MB_OK) ;
}
MessageBox(NULL, “Function completed”, NULL, MB_OK) ;
}
LONG ExceptFilter (char **lplpBuffer) { if (* lplpBuffer == NULL)
{ * lplpBuffer = g_szBuffer ; // Global buffer pointer
}
return (EXCEPTION_EXECUTE_HANDLER) ;
}
Обоснование: как в предыдущем, только в буфер ничего не запишется (я так понимаю). Исключение обработается, программа продолжит работу.
5. При выполнении программы произошло исключение. Какое значение получит переменная I после выполнения данного фрагмента программы при условии, что I изменяется только в указанных операторах, и для данного исключения (покажите порядок вычисления по шагам):
1.Значение выражения Filter1 = EXCEPTION_CONTINUE_SEARCH Значение выражения Filter2 = EXCEPTION_CONTINUE_SEARCH Значение выражения Filter3 = EXCEPTION_EXECUTE_HANDLE
78
2.Значение выражения Filter1 = EXCEPTION_CONTINUE_SEARCH Значение выражения Filter2 = EXCEPTION_CONTINUE_SEARCH Значение выражения Filter3 = EXCEPTION_CONTINUE_EXECUTION
3.Значение выражения Filter1 = EXCEPTION_CONTINUE_SEARCH Значение выражения Filter2 = EXCEPTION_CONTINUE_EXECUTION Значение выражения Filter3 = EXCEPTION_EXECUTE_HANDLE
(Символом √ отмечено место в программе, где произошло исключение)
Пример 1. |
|
|
|
|
|
|
__try { ........ |
I = 0 ; ............ |
|
|
|
|
|
__try { |
........ I = I + 1 ; ............ |
|
|
|
|
|
__try { ........ |
I = I + 2 ; ............ |
|
|
|||
|
__try { ........ |
I = I + 3 ; ............ |
|
|
||
|
|
__try { |
.... |
√ .... I = I + 4 ; ............ |
} |
|
|
|
__except ( Filter1 ){ .... |
I = 0; ..... |
} |
||
|
__finally { ..... |
|
I = I - 3 ; ..... |
} |
|
|
__except (Filter2 ) { .... |
I = 100; .... |
} |
|
|||
__finally { ..... |
I = I - 1 ; ..... |
|
} |
|
|
|
__except (Filter3 ) { .... |
I = 200; .... |
} |
|
|
||
....... I = ? |
|
|
|
|
|
|
Пример 2. |
|
|
|
|
|
|
__try { ........ |
I = 0 ; ............ |
|
|
|
|
|
__try { |
........ I = I + 1 ; ............ |
|
|
|
|
|
__try { ........ |
I = I + 2 ; ............ |
√ ..... |
|
|||
|
__try { ........ |
I = I + 3 ; ..... |
|
|||
|
|
__try { |
.... |
I = I + 4 ; ...... |
|
|
|
|
|
|
__try {…} |
|
|
|
|
} |
|
__finally { … I= 1000; } |
||
|
|
|
|
|
|
|
|
|
__except ( Filter1 ){ .... |
I = 0; ..... |
} |
||
|
__finally { ..... |
|
I = I – 3 ; ..... |
} |
|
|
__except (Filter2 ) { .... |
I = 100; .... |
} |
|
|||
__finally { ..... |
I = I – 1 ; |
..... |
} |
|
|
|
__except (Filter3 ) { .... |
I = 200; .... |
} |
|
|
||
....... I = ? |
|
|
|
|
|
|
Задания по разработке командных файлов и изучение команд пакетной обработки
Написать командный файл или записать оператор (если это возможно), который выполняется из командной строки, для решения следующей задачи:
1.Скопировать заданный файл или группу файлов (все текстовые файлы, все программные файлы, все файлы, имена которых начинаются с символов ‘PLAN’ и содержат до 8 символов, все файлы, имена которых содержат подстроку ‘Rar’, все файлы с именем ‘БАЗА’) в каталоги, список которых задан (DIR1, DIR2, …, DIR9).
2.Скопировать файлы, список которых передается в командный файл через параметры, указанные в командной строке, в каталог, имя которого тоже задается
79
параметром (первым параметром) при вызове командного файла.
3.Последовательно выполнить три командных файла (COM1.BAT, COM2.BAT, COM3.BAT), передав им в качестве параметра строку ‘FILE1.TXT’, вызвав их с помощью одного оператора командной строки.
4.При вызове программ PROG1, PROG2, PROG3 на экран выводятся сообщения. Напишите командный файл, который последовательно вызывает эти программы, передавая им в качестве параметров строки, заданные в качестве параметров при вызове командного файла (сначала все программы получают первый параметр, затем – второй и т.д., пока не закончится список параметров (их число от 1 до 5)). Все сообщения, выдаваемые программами, не должны быть отображены на экране, все сообщения должны попасть в текстовый файл REPORT.TXT.
5.При вызове программ PROG1, PROG2, PROG3 программа PROG1 передает свои результаты в качестве входных данных в программу PROG2, а PROG2 – в PROG3. При работе программ на экран выводятся сообщения. Запишите команду, которая последовательно вызывает эти программы. Все сообщения, выдаваемые программами на экран, не должны быть отображены на экране, сообщения последней вызванной программы должны попасть в текстовый файл REPORT.TXT.
2.Задачи на использование программных методов решения проблемы взаимного исключения
1.Задача: решить программным способом задачу взаимного исключения. Являются ли приведенные ниже процедуры решением поставленной задачи? Если нет, объясните, когда могут возникнуть ошибки?
Решение:
process INIT; common boolean C1. C2;
begin С1:=false; С2:=false; start(P1); start(P2); end; process P1;
Begin
while true do
begin BEFORE1; C1:=true; while C2 do ; CS1; C1:=false; AFTER1;
end
end; process P2;
Begin
while true do
begin BEFORE2; while C1 do ; C2:=true; CS1; C2:=false; AFTER2;
end
end;
Решение:
Нет, не являются решением поставленной задачи. Никто не гарантирует определенную последовательность выполнения команд данных процессов. И любой из двух процессов может быть первым. Таким образом, если последовательность действий: while C1 do, C1:=true, while C2 do, C2:=true, т.е. сначала начинает выполняться P2, затем управление передается процессу P1, который в свою очередь оказывается перед входом в критическую секцию, потом управление передается P2, который также оказывается перед входом в критическую секцию. Следовательно, оба процесса войдут в критическую секцию.
80
2.Решить задачу взаимного исключения, используя логические переменные и процедуру перевода процесса в состояние задержки (приостановки) Delay(T), где параметр T задает время задержки процесса (время, на которое он выводится из конкуренции за время процессора).
Решение:
|
process INIT; |
|
|
|
|
|
|
|
|
common Boolean C1, C2; |
|
|
|
|
|
||
|
common Integer Т1, Т2; |
|
|
|
|
|
||
|
begin |
|
|
|
|
|
|
|
|
С1:=false; С2:=false; |
|
|
|
|
|
||
|
start(P1); start(P2); |
|
|
|
|
|
||
|
end; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
process P1; |
|
|
|
|
process P2; |
|
|
|
begin |
|
|
|
|
begin |
|
|
|
while true do |
|
|
|
while true do |
|
||
|
begin |
|
|
|
|
|
begin |
|
|
BEFORE1 ; |
|
|
|
BEFORE2 |
; |
||
|
|
C1 := true; |
|
|
|
C2 := true; |
||
|
|
while C2 do begin |
|
|
|
while C2 do begin |
||
|
|
|
C1 := false; |
|
|
|
C2 := false; |
|
|
|
|
T1 := random; |
|
|
|
T2 := random; |
|
|
|
|
Delay(T1); |
|
|
|
Delay(T2); |
|
|
|
|
C1 := true; |
|
|
|
C2 := true; |
|
|
end; |
|
|
|
end; |
|
||
|
CS1; |
|
|
|
CS2; |
|
||
|
C1 := false; |
|
|
|
C2 := false; |
|||
|
AFTER1; |
|
|
|
AFTER2; |
|
||
|
end; |
|
|
|
|
|
end; |
|
|
end P1 . |
|
|
|
|
end P2. |
|
|
|
|
|
|
|
|
|||
|
3. Алгоритм Деккера можно сформулировать следующим образом: |
|
||||||
|
|
|
|
|
|
|
|
|
|
Процедура |
|
Первый процесс |
|
Второй процесс |
|||
|
инициализации |
|
|
|||||
|
|
|
|
|
|
|
|
|
procedure INIT; |
|
process P1; |
|
|
|
process P2; |
|
|
common boolean C1,C2 ; |
|
common boolean C1,C2 ; |
|
common boolean C1,C2 ; |
||||
common integer N ; |
|
begin |
|
|
|
begin |
|
|
begin |
|
while true do |
|
|
|
while true do |
|
|
|
C1 := false ; |
|
begin BEFORE1 |
; |
|
|
begin BEFORE2 |
; |
|
C2 := false ; |
|
C1 := true |
; |
|
|
C2 := true |
; |
|
N := 1 ; |
|
while C2 do |
|
while C1 do |
|||
|
start(P1) ; |
|
begin |
|
|
|
begin |
|
|
start(P2) |
|
if N<>1 then |
|
if N<>2 then |
|||
end INIT . |
|
begin |
|
|
|
begin |
|
|
|
|
|
C1 := false ; |
|
C2 := false ; |
|||
|
|
|
while N<>1 do ; |
|
while N<>2 do ; |
|||
|
|
81 |
|
|
|
|
||
|
C1 := true ; |
C2 := true ; |
|
end |
end |
|
end ; |
end ; |
|
CS1 ; |
CS2 ; |
|
C1 := false; N := 2; |
C2 := false; N:=1; |
|
AFTER1 ; |
AFTER2 ; |
|
end |
end |
|
end P1 . |
end P2 . |
Написать алгоритм Деккера для N процессов. |
|
|
var int wish[N+1] = {0,…,0} //желание процесса зайти в CS var int clmt[N+1]={0,…,0} //массив претендентов на вход в CS
var int right = N //номер процесса, у которого право на вход в CS void csBegin (int proc) {
int i; clmt[proc] = 1; do {
while (right!= proc) { //получение права на вход в CS wish[proc] = 0;
if (!clmt[right]) right = proc; //если право принадлежит другому процессу, но //он не претендент, то текущий процесс забирает право себе
}
wish[proc] = 1;
for (i=0; i < N; i++) //проверка «желаний» других процессов if ((i != proc) && wish[i]) break;
}
while (i < N);
}
void csEnd (int proc) { right = N;
wish[proc] = clmt[proc] = 0;
}
Однако этот алгоритм для N процессов не будет работать верно, так как, мы, вообще говоря, не можем гарантировать атомарность элементарных операций.
4.Решается ли в приведенных ниже программах проблема взаимного исключения (random – процедура, генерирующая случайное число, delay(T) – процедура задержки процесса на время T, в течение которого процесс не будет конкурировать за время процессора)?
process INIT; common boolean C1. C2; common integer N; common real T1, T2; begin С1:=false; С2:=false; T1:= random; T2:= random; N:=1; start(P1); start(P2); end;
process P1;
Begin
while true do begin BEFORE1;
C1:=true;
while C2 and (N<>1) do delay(T1);
82
CS1;
C1:=false; N:=2; AFTER1;
end
end; process P2;
Begin
while true do begin BEFORE2;
C2:=true;
while C1 and (N<>2) do delay(T2); CS2;
C2:=false; N:=1;
AFTER2;
end
end;
Решение:
Проблема решается неверно. На входе в Р1: N = 1. Если допустить следующую последовательность выполнения: в P2 C2:=true; (цикл не выполнятся, так как С1 = false), в P1 C1:=true; (цикл пропускается, так как N=1), то оба процесса войдут в критическую секцию.
3.Задачи на работу с семафорами
1.Задача: написать процедуры, моделирующие семафорные примитивы для общего семафора (допускаются только неотрицательные значения целочисленной переменной, моделирующей считающий семафор). При написании процедур можно использовать бинарные семафоры. Ниже приведен код процедур PP и VP, которые моделируют работу семафорных примитивов для общего семафора в соответствии с поставленной задачей. Решена ли задача? Найти в приведенном ниже псевдокоде ошибки, объяснить и исправить их, если они есть.
1.1.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B1, B2; begin B1:=1; B2:=1; S:=value end;
PP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B2); P(B1); S:=S–1; if S>0 then V(B2); V(B1) end;
VP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S+1; V(B1); V(V2 ) end;
После прохождения (S+1) процессов, значение S станет -1, а это недопустимо, так как допускаются только неотрицательные значения). Вариант исправления:
Init: proc (var S: integer; value: integer); common binary semaphore B1, B2; begin B1:=1; B2:=1; S:=value end;
PP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B2); P(B1); if S>1 then { S:=S–1; V(B2); } if S=1 then S:=S–1; V(B1) end;
VP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S+1; V(B1); V(B2 ) end;
83
1.2.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B1, B2; begin B1:=1; B2:=1; S:=value end;
PP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B2); P(B1); S:=S–1; V(B1) end;
VP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S+1; V(B1); V(V2 ) end;
Нет никак условий для S, хотя допускаются только неотрицательные значения (предыдущий вариант исправления).
1.3.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B1, B2;
begin B1:=1; B2:=1; S:=value end;
PP: procedure (var S: integer);
common binary semaphore B1, B2;
Begin P(B2); while S<=0 do; P(B1); S:=S–1; V(B1); V(B2) end;
VP: procedure (var S: integer);
common binary semaphore B1, B2;
Begin P(B1); S:=S+1; V(B1); V(B2 ) end;
Комментарии: Проблема решена неправильно.
1) процесс заходит в РР, а потом в VР, где остановится на «V(B2)» Затем вызовет РР, пройдет Р(В2), завершая VP пройдет условие while и остановится возле «P(B1);»
В итоге получим что все процессы собрались перед «P(B1);» и сделают S отрицательным
Достаточно убрать V(B2) из VP
1.4.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B;
begin B:=1; S:=value end;
PP: procedure (var S: integer); common binary semaphore B;
Begin P(B); if S>0 then S:=S–1; V(B) end;
VP: procedure (var S: integer); common binary semaphore B;
Begin P(B); S:=S+1; V(B) end;
Комментарии: Проблема решена неправильно.
PPдолжен дождаться освобождения ресурса, а он завершает работу.
2.Задача: написать процедуры, моделирующие семафорные примитивы для общего семафора (допускаются любые значения целочисленной переменной, моделирующей
84
считающий семафор). При написании процедур можно использовать бинарные семафоры. Ниже приведен код процедур PP и VP, которые моделируют работу семафорных примитивов для общего семафора в соответствии с поставленной задачей. Решена ли задача? Найти в приведенном ниже псевдокоде ошибки, объяснить и исправить их, если они есть.
2.1.Решение:
Init: proc (var S: integer; value: integer); begin S:=value end; PP: procedure (var S: integer);
common binary semaphore B1, B2;
Begin P(B1); S:=S–1; if S<0 then begin V(B1); P(B2) end Else V(B1) end;
VP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S+1; if S<=0 then V(B2); V(V1 ) end;
Комментарии: Проблема решена неправильно.
Нет инициализации семафоров. Нужно изменить :
Init … begin B1:=1; B2:=0; S:=value end;
2.2.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B1, B2; begin B1:=1; B2:=0; S:=value end;
PP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S–1; P(B2) end;
VP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B2); S:=S+1; V(V1 ) end;
Комментарии: Проблема решена неправильно.
Никак не проверяется значение S.
Можно исправить до измененного варианта 2.1.
2.3.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B; begin B:=1; S:=value end;
PP: procedure (var S: integer); common binary semaphore B;
Begin if S>0 then begin P(B); S:=S–1; V(B) end end; VP: procedure (var S: integer);
common binary semaphore B;
Begin P(B); S:=S+1; V(B) end;
Комментарии: Проблема решена неправильно.
PPпроходит впустую, если S<=0.
2.4.Решение:
85
Init: proc (var S: integer; value: integer); begin S:=value end;
PP: procedure (var S: …); common binary semaphore B1, B2;
Begin P(B1); S:=S–1; if S<0 then P(B2) Else V(B1) end;
VP: procedure (var S: …); common binary semaphore B1, B2;
Begin P(B1); S:=S+1; if S<=0 then V(B2); V(V1 ) end;
Комментарии: Проблема решена неправильно.
Нет инициализации семафоров. Если дополнить процедуру Init :
common binary semaphore B1, B2; begin B1:=1; B2:=1; S:=value end;
При условии, что сначала S=0 и В2=1, потом после РР В2=0,то процесс PP пройдет впустую, а должен встать на ожидание
2.5.Решение:
Init: proc (var S: integer; value: integer); common binary semaphore B1, B2; begin B1:=1; B2:=1; S:=value end;
PP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S–1; if S<0 then P(B2) Else V(B1) end;
VP: procedure (var S: integer); common binary semaphore B1, B2;
Begin P(B1); S:=S+1; if S>0 then V(B2); V(B1 ) end;
Комментарии: Проблема решена неправильно.
Если S=0, то РР проходим , не встав на ожидание.
86
3.Задача “обедающие философы” формулируется следующим образом: “Пять философов садятся обедать за круглый стол, в центре которого стоит одно блюдо со спагетти. На столе имеется пять тарелок и пять вилок между ними. Философ может начать есть, если у него есть тарелка и две вилки, которые он может взять с двух сторон от своей тарелки. Философ может отдать вилки соседям только после того, как он закончит обед”. О соображениях гигиены мы здесь умалчиваем. Может ли описанный ниже на псевдокоде процесс представить алгоритм поведения философа за столом?
3.1.Решение:
Инициализация:
{ “Вилки”, которые используются философами – это разделяемые ресурсы, защищенные бинарными семафорами: }
common B: array[0..4] of binary semaphore; { глобальный массив семафоров} for I:=0 to 4 do B[I]:=1; { все “вилки” свободны }
process Философ(I: Integer);
{Это процесс, описывающий поведение I-го философа. }
{“Вилки”, которыми он ест, защищаются двумя бинарными семафорами. } common B: array[0..4] of binary semaphore
begin { Пытается получить вилки: }
while (P(B[I])=0) or (P(B[(I+1) mod 5])=0) do ;
{Ест спагетти, используя вилки, находящиеся слева и справа } …
{Освобождает вилки: } V(B[(I+1) mod 5]); V(B[I]);
end;
Решение:
Проблема решается неверно. Р (<binary semaphore>) – это, вообще говоря, процедура, а значит, операция сравнения в данном случае недопустима. Более того, если семафор закрыт, эта процедура организует потенциальное ожидание.
3.2.Решение:
Инициализация:
{ “Вилки”, которые используются философами – это разделяемые ресурсы, защищенные бинарными семафорами: }
common B: array[0..4] of binary semaphore; { глобальный массив семафоров} for I:=0 to 4 do B[I]:=1; { все “вилки” свободны }
process Философ(I: Integer);
{Это процесс, описывающий поведение I-го философа. }
{“Вилки”, которыми он ест, защищаются двумя бинарными семафорами. } common B: array[0..4] of binary semaphore
begin
{Пытается получить вилки: } P(B[I]); P(B[(I+1) mod 5]);
{Ест спагетти, используя вилки, находящиеся слева и справа } …
{Освобождает вилки: }
V(B[(I+1) mod 5]); V(B[I]); end;
87
Решение:
Проблема решается неверно. Пусть все философы возьмут по одной вилке (все правые или все левые). Тогда возникает вечное ожидание второй вилки - P(B[(I+1) mod
5]).
Возможное решение:
common B: array[0..4] of binary semaphore; common B1 binary semaphore;
for I:=0 to 4 do B[I]:=1; B1 = 1;
process Философ(I: Integer);
common B: array[0..4] of binary semaphore begin
P(B1);
P(B[I]); P(B[(I+1) mod 5]); V(B1);
//eating
V(B[(I+1) mod 5]); V(B[I]); end;
4. Задачи на понимание алгоритмов решения задач,
связанных с тупиками
1.Рассматривается система с повторно используемыми ресурсами. Дан граф повторно используемых ресурсов. Проверить, не является ли состояние, которое он представляет, тупиковым (выполнить редукцию графа).
2.Рассматривается система с повторно используемыми единичными ресурсами. Дан граф повторно используемых ресурсов. Проверить, не является ли состояние, которое он представляет, тупиковым (различными способами, выбрать оптимальный).
3.Рассматривается система с повторно используемыми ресурсами. Дан граф повторно используемых ресурсов. Проверить, является ли состояние системы выгодным. Проверить, не является ли состояние, которое он представляет, тупиковым (различными способами, выбрать оптимальный).
4.Рассматривается система с потребляемыми ресурсами. Дан граф потребляемых ресурсов. Проверить, не является ли состояние, которое он представляет, тупиковым. Какими способами это можно сделать?
5.Рассматривается система с потребляемыми ресурсами. Дан граф потребляемых ресурсов. Проверить, является ли состояние системы выгодным. Проверить, не является ли состояние, которое он представляет, тупиковым. Какими способами это можно сделать?
6.Рассматривается система с обобщенными ресурсами. Дан граф обобщенных ресурсов. Проверить, не является ли состояние, которое он представляет, тупиковым. Какими способами это можно сделать?
88

5.
6. Задачи на анализ состояний системы
для выявления тупиков
1.Пусть в системе есть два процесса P1 и P2 и два единичных повторно используемых ресурса R1 и R2. Процессы имеют следующее описание:
Процесс 1 |
Процесс 2 |
|
|
process P1 ; |
process P2 ; |
begin ... |
begin ... |
While true do |
While true do |
begin … |
begin … |
request ( R1, 1) ; |
request ( R2, 1) ; |
... |
... |
request ( R2, 1) ; |
request ( R1, 1) ; |
... |
... |
release ( R2, 1) ; |
release ( R2, 1) ; |
... |
... |
release ( R1, 1) ; |
release ( R1, 1) ; |
... |
... |
end |
end |
... |
... |
end. |
end. |
Построить граф состояний системы. Возможны ли в системе тупиковые состояния?
89

2.Пусть в системе есть два процесса P1 и P2 и два потребляемых ресурса R1 и R2, используемых этими процессами. Ресурс R1 производится процессом P1, а R2 – P2. Процессы имеют следующее описание:
Процесс 1 |
|
Процесс 2 |
|
|
|
process P1 ; |
process |
P2 ; |
begin ... |
begin ... |
|
While true do |
While true do |
|
begin … |
begin |
… |
request ( R2, 1) ; |
request ( R1, 1) ; |
|
... |
|
... |
release ( R1, 1) ; |
release ( R2, 1) ; |
|
... |
|
... |
end |
end |
|
... |
... |
|
end. |
end. |
|
Построить граф состояний системы. Возможны ли в системе тупиковые состояния?
90
91

Алгоритм сборки мусора!!!
Экономный алгоритм (Шора-Витта) Этот алгоритм основан на обращении ссылок при обходе активных элементов кучи. Для описания алгоритма введем следующие обозначения: Current - ссылка на текущий элемент; Last - ссылка на последний элемент. Pointers-массив указателей в элементе кучи. Number - номер используемого поля указателя. Поле, в которое записывается маркер (бит сбора мусора), назовем Sign. Через Pointers_Counter обозначим количество полей, содержащих указатели на элементы кучи, в каждом ее элементе. {Выбираем внешние ссылки на структуры данных, размещенных в
куче} |
|
|
|
while есть непустые указатели на немаркированные элементы кучи do |
begin |
(1) |
|
{переход к следующей маркируемой структуре данных в куче} |
|
|
|
Current<-Внешний непустой указатель на немаркированный элемент; |
|
|
|
Last<-nil;{предшествующего элемента нет} {маркировка текущего элемента} |
|
|
|
while Current.Sign = 1 do |
begin (2) {Данный элемент отмечен |
пока |
как |
мусор}{Следовательно, нужно его промаркировать как активный и просмотреть {все его ссылки на другие элементы кучи} {Выбрать новый элемент по ссылке из данного элемента}
Current.Number<-Current.Number+1;
while (Current.Number<Pointers_Counter) and (Current.Pointers[Number]=nil) do {Ищем непустую ссылку на элемент кучи} Current.Number<-Current.Number+1;
if (Current.Number<=Pointers_Counter ) and (Current_Pointers[Current.Number]<>nil)
then
begin (3) {Нашли непустую ссылку - переходим на выбранный по ней элемент,}
92
{ выполняя циклическую перестановку: Current->Last- >Current_pointers[Current.Number]->Current, если элемент еще не выбирался при обходе списка}
P<-Current.Pointers[Current.Number];
if (P.Sign=1) and (P.Number=0) then begin (4) {элемент еще не маркирован,
ссылка не циклическая}
Current.Pointers[Current.Number]<-Last; Last<-Current;Current<-P;
end (4);
end (3) else {Непройденных ссылок больше нет - маркируем элемент} begin (5)
Current.Sign<-0; Current.Number<-0;
if Last<>nil then {Возврат по цепочке к предшествующему элементу и восстановление ссылок обратной перестановкой: Current<-Last<- Current.Pointers[Current.Number]<-Current} begin (6)
P<-Current; Current<-Last;
Last<-Current.Pointers[Current.Number]; Current.Pointers[Current.Number]<-P; end (6) end (5) end; (2) end. (1)
93