

Хеширование
Мы рассматривали методы поиска. Очевидно, что эффективными из них являются те, которые минимизируют число сравнений ключей друг с другом. В идеале желательно иметь такую организацию таблиц, при которой не было бы ненужных сравнений.
Рассмотрим возможность такой организации. Если каждый ключ должен быть извлечен за один доступ, то положение записи внутри такой таблицы может зависеть только от данного ключа. Оно не может зависеть от расположения других ключей, как это имеет место в дереве [3].
Наиболее эффективным способом организации такой таблицы является массив, где каждая запись хранится по некоторому конкретному смещению по отношению к базовому адресу таблицы. Если ключи записей являются целыми числами, то сами ключи могут использоваться как индексы в массиве. До трех цифр ключа такой подход применим, но если ключ должен состоять из 7 цифр. Как быть в этом случае? Необходим некоторый метод преобразования ключа в какое-либо целое число внутри ограниченного диапазона. В идеале в одно и то же число не должны преобразовываться два различных ключа. К сожалению, такого идеального метода не существует.
Рассмотрим подходы, которые приближаются к идеальному. Вернемся к задаче поиска по ключу, состоящему из 7 цифр. Если использовать массив для записей, то в качестве индекса записи в этом массиве попробуем использовать три последние цифры.

Рис. 4.7. Записи, хранящиеся в массиве
Такой подход целесообразен, когда в массиве не более 1000 записей. Функция, которая трансформирует ключ в некоторый индекс таблицы, называется хеш-функцией. Если h — хеш-функция, а key — некоторый ключ, то h(key) — значение хеш-функции от ключа key и является индексом, по которому должна быть размещенна запись с ключом key. Если обозначить остаток от деления x на y как mod(x,y), то хеш-функция для вышеприведенного примера есть h(key) = mod(key, 1000). Значения, которые выдает функция h, должны покрывать все множество индексов в таблице.
Этот метод имеет один недостаток. Предположим, что существуют два ключа k1 и k2 такие, что h(k1) = h(k2). Когда запись с ключом k1 вводится в таблицу, она вставляется в позицию h(k1). Но когда хешируется ключ k2, получаемая позиция является той же позицией, в которой хранится запись с ключом k1. Ясно, что две записи не могут занимать одну и ту же позицию. Такая ситуация называется коллизией при хешировании или столкновением. В примере, рассмотренном выше, коллизия при хешировании произойдет, если в таблицу будет добавлена запись с ключом 0596396. Далее рассмотрим возможности, как найти выход из такой ситуации. Следует отметить, что хорошей функцией является такая функция, которая минимизирует коллизии и распределяет записи равномерно по всей таблице. Поэтому желательно иметь массив размером больше, чем число реальных записей. Отметим, что определенная хеш – функция используется для заполнения информационной таблицы и по ней же потом идет поиск и, при необходимости, вставка данных.
Разрешение коллизий при хешировании методом открытой адресации
Вернемся к вопросу возникшей коллизии при вставке записи с ключом 0596396 в имеющийся массив записей и с хеш-функцией mod(key, 1000).
Самым простым способом разрешения возникшей коллизии является помещение записи 0596396 в следующую свободную позицию в массиве. Например, если ячейка свободна, то можно поместить запись туда. Этот метод называется линейным опробованием, и он является примером некоторого общего метода разрешения коллизий при хешировании, который называется повторным хешированием или открытой адресацией. В общем случае функция повторного хеширования rh воспринимает один индекс в массиве и выдает другой индекс. Если ячейка массива h(key) уже занята некоторой записью с другим ключом, то функция rh применяется к значению h(key) для того, чтобы найти другую ячейку, куда может быть помещена эта запись. Если ячейка rh(h(key)) также занята, то хеширование выполняется еще раз и проверяется ячейка rh(rh(h(key))). Этот процесс продолжается до тех пор, пока не будет найдена пустая ячейка [3].
Например, если h(key) = mod(key,1000), то в качестве rh функции можно взять функцию mod(i+1,1000), т.е. повторное хеширование какого-либо индекса есть следующая последовательная позиция в данном массиве, за исключением того случая, что повторное хеширование 999 дает 0.
Любая функция rh(i) = mod(i+c, m), где с — константа, такая что c и m являются взаимно простыми числами (т.е. они одновременно не могут делиться нацело ни на какое число, кроме 1), выдает последовательные значения, которые распространяются на всю таблицу.
Рассмотрим ситуацию, возникающую при повторном хешировании, которая называется скучиванием.
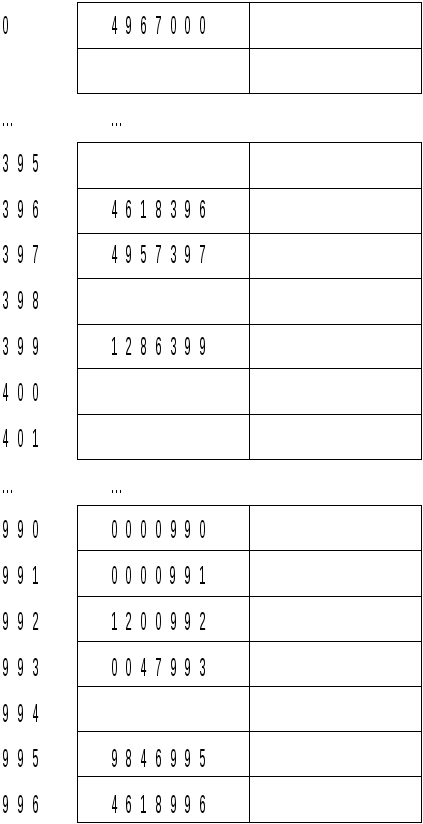
Рис. 4.8
Обратимся к Рис. 4.8, из которого видно, что помещение записи в позицию 994 в пять раз вероятнее, чем в позицию 401. Это происходит из-за того, что любая запись, чей ключ хешируется в позиции 990–994 будет помещена в 994, а в позицию 401 будет помещена только та запись, чей ключ хешируется в эту позицию. Это явление, при котором два ключа конкурируют друг с другом при повторных хешированиях называется скучиванием.
Одним из способов исключения скучивания является использование двойного хеширования, которое состоит в использовании двух хеш-функций: h1(key) и h2(key). Функция h1(key), называемая первичной хеш-функцией, используется первой при определении позиции, в которую должна быть помещена запись. Если эта позиция занята, то последовательно используется функция повторного хеширования
rh(i) = mod(i+ h2(key), m)
до тех пор, пока не будет найдена пустая позиция. Записи с ключами key1 и key2 не будут соревноваться за одну и ту же позицию, если h2(key1) h2(key2).
Другой метод разрешения коллизий при хешировании называется методом цепочек. Он представляет собой организацию связанного списка из всех записей, чьи ключи хешируются в одну и ту же позицию. Предположим, что хеш-функция выдает значения в диапазоне от 0 до m-1. Тогда описывается некоторый массив, например, bucket, размера m. Элемент bucket(i) указывает на список всех записей, чьи ключи хешируются в i. При поиске записи осуществляется доступ к указателю списка, который занимает позицию i в массиве bucket. Если запись не найдена, то она вставляется в конец списка. Обратимся к Рис. 4.9, на котором показан метод цепочек. Предположим, что имеются 14 элементов, хеш-функция равна mod(key, 10). Ключи представлены в таком порядке:
75 66 42 192 91 40 49 87 67 16 417 130 372 227
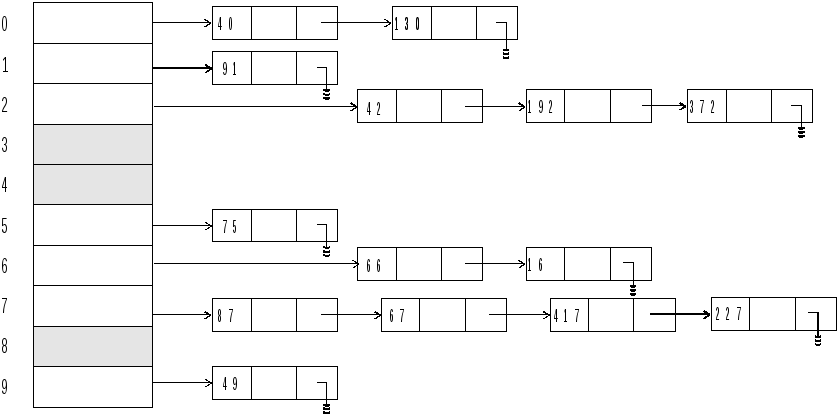
Рис. 4.9. Разрешение коллизий при хешировании методом цепочек