

www.basegroup.ru
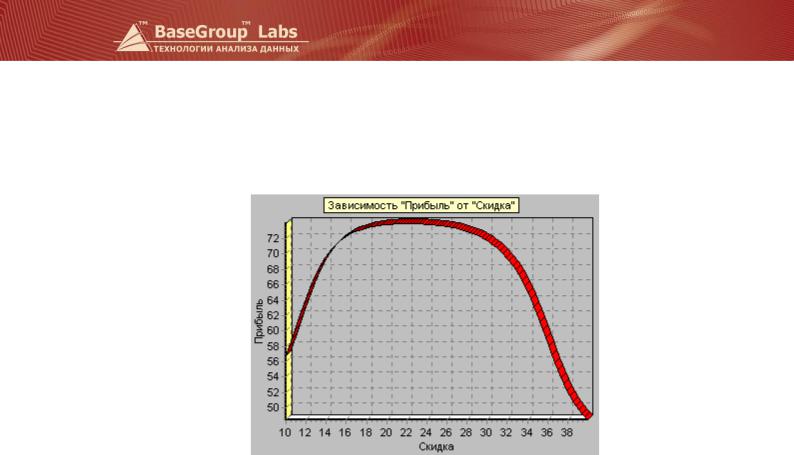
На диаграмме видно, что при максимальной скидке прибыль минимальна. Максимум же прибыли достигается где-то посередине между минимальной и максимальной скидкой. Точный ответ об оптимальной скидке по этой диаграмме получить довольно трудно. Для этого можно воспользоваться другим подходом к анализу. Например, построить модель зависимости прибыли от скидки.
По этой зависимости легко определить, что максимум прибыли достигается при скидке 22%.
Как визуализация, так и построение моделей осуществляются путем применения к данным базовых методов анализа. Это достаточно известные методы, и они используются в самых разнообразных сферах деятельности.
Базовые методы анализа
Online Analytical Processing
Любая система поддержки принятия решений, прежде всего, должна обладать средствами отбора и предоставления пользователю данных в удобной для восприятия и анализа форме. Как правило, наиболее удобными для анализа являются многомерные данные, описывающие предметную область сразу с нескольких точек зрения. Для описания таких наборов данных вводится понятие многомерных кубов (гиперкубов, метакубов). По осям такого куба размещаются параметры, а в ячейках – зависящие от них данные. Вдоль каждой оси представлены различные уровни детализации данных. Использование такой модели данных позволяет повысить эффективность работы с ними: генерировать сложные запросы, создавать отчеты, выделять подмножества данных и т.д. Технология комплексного многомерного анализа данных и предоставления результатов этого анализа в удобной для использования форме получила название OLAP.
OLAP (Online Analytical Processing) – оперативная аналитическая обработка данных. OLAP дает возможность в реальном времени генерировать описательные и сравнительные сводки данных и получать ответы на различные другие аналитические запросы. OLAP-кубы представляют собой проекцию исходного куба данных на куб данных меньшей размерности. При этом значения ячеек агрегируются, то есть объединяются с применением функции агрегации – сумма, среднее, количество, минимум, максимум. Такие проекции или срезы исходного куба представляются на экране в виде кросс-таблицы.
стр. 9 из 192

www.basegroup.ru
Проиллюстрируем идею OLAP-куба на простом примере. Пусть информацию, хранящуюся в базе данных, или подмножество данных, получаемое в результате выполнения запроса, можно представить в виде следующей таблицы.
№ |
|
Город |
|
|
Годовой объем продаж (руб.) |
|
Итого |
|
|||||||||
п/п |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Товар 1 |
|
|
|
Товар 2 |
|
|
|
Товар 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
1 |
|
Москва |
|
525 000 |
|
|
234 000 |
|
|
325 000 |
|
|
1 084000 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
2 |
|
Тула |
|
224 000 |
|
|
|
|
|
|
12 560 |
|
|
236 560 |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
3 |
|
Владимир |
|
|
|
|
|
123 000 |
|
|
425 000 |
|
|
548 000 |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
4 |
|
Самара |
|
78 000 |
|
|
234 000 |
|
|
45 000 |
|
|
357 000 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
5 |
|
Тверь |
|
|
|
|
|
45 000 |
|
|
78 000 |
|
|
123 000 |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Основываясь на данных из таблицы, можно дать ответы на несколько вопросов, которые могут возникнуть при анализе объемов продаж. Например, каков объем продаж каждого товара по одному из городов?
|
|
Владимир |
|
|
|
|
|
Товар 1 |
|
|
|
|
|
|
|
Товар 2 |
|
123000 |
|
|
|
|
|
Товар 3 |
|
425000 |
|
|
|
|
|
Данную выборку можно интерпретировать как одномерную, поскольку объемы продаж расположены только вдоль одного измерения с наименованием товара.
Или: каков объем продаж каждого из товаров по городам?
Город |
|
Товар 1 |
|
Товар 2 |
|
Товар 3 |
|
|
|
|
|
|
|
Москва |
|
525 000 |
|
234 000 |
|
325 000 |
|
|
|
|
|
|
|
Тула |
|
224 000 |
|
|
|
12 560 |
|
|
|
|
|
|
|
Владимир |
|
|
|
123 000 |
|
425 000 |
|
|
|
|
|
|
|
Самара |
|
78 000 |
|
234 000 |
|
45 000 |
|
|
|
|
|
|
|
Тверь |
|
|
|
45 000 |
|
78 000 |
|
|
|
|
|
|
|
Данная выборка является двумерной и может быть представлена в виде «плоского куба», в котором 3-е измерение «отключено».
стр. 10 из 192
www.basegroup.ru
Москва |
525000 |
234000 |
325000 |
|
|
|
|
|
|
Тула |
224000 |
|
12560 |
|
|
|
|
|
|
Владимир |
|
123000 |
425000 |
|
|
|
|
|
|
Самара |
78000 |
234000 |
45000 |
|
|
|
|
|
|
Тверь |
|
45000 |
78000 |
|
|
|
|
|
|
|
|
Товар 1 |
Товар 2 |
Товар 3 |
Чтобы представленный куб превратился в трехмерный, необходимо добавить еще одно измерение данных, т.е. привлечь дополнительную информацию по анализируемым параметрам. Например, если в базе данных предусмотрена информация о квартальном объеме продаж каждого товара по всем городам, то номер квартала может стать этим дополнительным измерением.
Город |
|
|
|
|
|
|
|
Поквартальный объем продаж (тыс. руб.) |
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Товар 1 |
|
|
|
|
|
|
Товар 2 |
|
|
|
|
|
Товар 3 |
|
|
|
||||||
|
I |
|
II |
|
III |
|
|
IV |
|
I |
|
II |
|
III |
|
IV |
|
I |
|
II |
|
III |
|
IV |
|
Москва |
125,0 |
|
125,0 |
|
150,0 |
|
125,0 |
|
85,0 |
|
70,0 |
|
45,0 |
|
34,0 |
|
75,0 |
|
75,0 |
|
75,0 |
|
100,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Тула |
45,0 |
|
55,0 |
|
100,0 |
|
24,0 |
|
|
|
|
|
|
|
|
|
5,0 |
|
5,0 |
|
|
|
2,56 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Владимир |
|
|
|
|
|
|
|
|
|
45,0 |
|
40,0 |
|
25,0 |
|
13,0 |
|
10,0 |
|
10,0 |
|
10,0 |
|
12,5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Самара |
12,5 |
|
15,5 |
|
32,0 |
|
18,0 |
|
85,0 |
|
65,0 |
|
50,0 |
|
34,0 |
|
15,0 |
|
5,0 |
|
17,0 |
|
13,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Тверь |
|
|
|
|
|
|
|
|
|
10,0 |
|
10,0 |
|
10,0 |
|
15,0 |
|
20,0 |
|
15,0 |
|
25,0 |
|
18,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
На основе подобной выборки можно построить трехмерный куб.
стр. 11 из 192

www.basegroup.ru
Такая модель представления данных позволяет получать нужную информацию, производя соответствующие сечения (срезы) OLAP-куба.
Нет необходимости пытаться произвести геометрическую интерпретацию OLAP-куба с размерностью более 3. Действительно, поскольку человеческое сознание «приспособлено» к восприятию трехмерной действительности, все прочие представления сложны для восприятия, тем более, что речь идет не о реальном, а об информационном пространстве. Само понятие «многомерный куб» есть не что иное, как служебный термин, используемый для описания метода.
В принципе, используемое число измерений может быть любым. Однако следует отметить, что задача с большим числом измерений, во-первых, является трудоемкой с точки зрения ее выполнения на ПК и, во-вторых, ее осмысление и интерпретация результатов аналитиком могут быть затруднены и даже приводить к ошибочным решениям. Поэтому с методической точки зрения сложные задачи, требующие анализа данных большой размерности, следует по возможности сводить к нескольким более простым. Аналогично, сложные таблицы, которые содержат большое количество полей и записей, являющихся трудными для чтения, восприятия и анализа, можно разбить на несколько более простых таблиц. Это сделает работу с ними намного более удобной.
Knowledge Discovery in Databases
KDD (Knowledge Discovery in Databases) – извлечение знаний из баз данных. Это процесс поиска полезных знаний в «сырых данных». KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining (DM), постобработки данных и интерпретации полученных результатов.
Привлекательность этого подхода заключается в том, что вне зависимости от предметной области мы применяем одни и те же операции:
1Подготовка исходного набора данных. Этот этап заключается в создании набора данных, в том числе слиянии сведений из различных источников, определение выборки, которая и будет в последствии анализироваться. Для этого должны существовать развитые инструменты доступа к различным источникам данных: файлам разных форматов, базам данных, учетным системам.
2Предобработка и очистка данных. Для того чтобы эффективно применять методы анализа, следует обратить серьезное внимание на вопросы предобработки данных. Данные могут содержать пропуски, шумы, аномальные значения и т.д. Кроме того, данные могут быть избыточны, недостаточны и т.д. В некоторых задачах требуется дополнить данные некоторой априорной информацией. Наивно предполагать, что если подать любые данные на вход системы в существующем виде, то на выходе получим полезные знания. Данные должны быть качественны и корректны с точки зрения используемого метода анализа. Более того, иногда размерность исходного пространства может быть очень большой, и тогда желательно применение специальных алгоритмов понижения размерности: отбор наиболее значимых признаков и отображение данных в пространство меньшей размерности.
3Трансформация данных. Для различных методов анализа требуются данные, подготовленные в специальном виде. Например, некоторые методы анализа в качестве входных полей могут использовать только числовые данные, а некоторые, наоборот, только категориальные.
4Data Mining. На этом шаге применяются различные алгоритмы для нахождения знаний. Это нейронные сети, деревья решений, алгоритмы кластеризации и установления ассоциаций и т.д. Для этого могут использоваться как классические статистические методы, так и самообучающиеся алгоритмы и машинное обучение.
5Постобработка данных. Тестирование, интерпретация результатов и практическое применение полученных знаний в бизнесе.
стр. 12 из 192