

10.4. Коммуникационные сети
А сейчас мы рассмотрим возможные способы реализации коммуникационных сетей в мультипроцессорных системах. Коммуникационная сеть должна обеспечивать передачу данных между любыми двумя модулями системы. Кроме того, сеть может использоваться для широковещательной передачи информации от одного модуля системы ко многим другим. Трафик в сети формируется из запросов (например, на чтение или запись), пересылаемых данных и различных команд.
Каждая конкретная сеть характеризуется такими параметрами, как стоимость, полоса пропускания, реальная скорость передачи данных и простота реализации. Термин полоса пропускания обозначает пропускную способность соединений и определяется как количество битов или байтов данных, которые могут проходить через это соединение за единицу времени. Реальная скорость передачи данных соответствует реальному объему данных, проходящему через соединение за единицу времени. Она меньше полосы пропускания, поскольку при передаче данных могут возникать паузы.
Информация по сети передается, как правило, в виде пакетов фиксированной длины и фиксированного формата. Например, запрос на чтение может представлять собой один пакет, содержащий адрес источника (процессорного модуля) и места назначения (модуля памяти), а также поле команды, где указан тип операции чтения, которую требуется выполнить. Запрос на запись одного слова в модуль памяти тоже может состоять из одного пакета, содержащего записываемые данные. А вот ответ на запрос чтения, включающий целый блок кэш-памяти, может пересылаться в виде нескольких последовательных пакетов. Несколько пакетов может потребоваться и для длинных сообщений.
В идеале полный пакет должен пересылаться между любыми двумя узлами сети за один такт в параллельном режиме. Для этого нужны соединения, состоящие из большого количества проводов. Однако в целях упрощения архитектуры и снижения стоимости сети соединения обычно делают более узкими, а пакеты разделяют на части, каждая из которых может быть переслана за один такт.
Общая шина
Простейший и самый экономичный способ объединения большого количества модулей в единую систему заключается в использовании общей шины. Эта архитектура обсуждалась в предыдущих разделах при обсуждении устройства компьютеров, все сказанное там применимо и к мультипроцессорным системам. Поскольку несколько модулей соединены с одной шиной и каждому из них в любой момент может быть направлен запрос на передачу данных, необходима эффективная арбитражная схема.
Самым простым режимом функционирования системы с общей шиной является режим, при котором шина предоставляется конкретной паре компонентов на все время операции передачи данных. Например в случае, когда процессор выдает запрос на чтение, он занимает шину до тех пор, пока не получит из памяти нужные данные. Поскольку модулю памяти для доступа к данным требуется некоторое время, шина простаивает с момента получения запроса до тех пор, пока память не будет готова вернуть данные. Готовые данные направляются процессору, и когда процесс передачи завершается, шина может быть выделена для выполнения другого запроса.
Существует схема под названием протокол с разделением транзакций, позволяющая использовать время простоя шины для обработки другого запроса. Рассмотрим следующую процедуру обработки последовательности запросов на чтение, поступающих от разных процессоров. После передачи адреса, указанного в первом запросе, шина может быть переназначена для передачи адреса, заданного в другом запросе. В случае, если данный запрос адресован другому модулю памяти, с этого момента два модуля памяти могут обрабатывать полученные запросы параллельно. Если ни один из модулей еще не завершил операцию обращения к памяти, шина может быть выделена третьему запросу и т. д. Когда первый модуль наконец завершит цикл обращения к памяти, он воспользуется шиной для передачи слова запросившему его компоненту. Обратите внимание, что фактическое время между выдачей адреса и получением слова не является критически важным параметром. Операции передачи адреса и данных для различных запросов выполняются независимо и могут чередоваться друг с другом.
Возможность более эффективного использования полосы пропускания шины обеспечивает протокол с разделением транзакций. Достигаемая с его помощью производительность зависит от соотношения времени доступа к памяти и времени передачи данных по шине. Производительность можно повысить за счет усложнения архитектуры шины. А необходимость в ее усложнении вызвана двумя причинами. Во-первых, поскольку модулю памяти нужно знать, от какого источника поступил данный запрос, к запросу должен присоединяться тег идентификации источника. После выполнения запроса этот тег используется для отправки источнику требуемых данных. А во-вторых, не только процессор, но и все остальные модули должны иметь возможность выступать в роли хозяев шины.
Мультипроцессорные системы, в которых применяется шина с разделением транзакций, содержат от 4 до 32 процессоров. Возможность подключения еще большего количества процессоров ограничена полосой пропускания шины. Для увеличения полосы пропускания можно увеличить количество составляющих шину линий.
Сети с координатной коммутацией
На рис. 10.5 показана сеть с коммутируемыми соединениями. Эта схема, разработанная для телефонных сетей, называется координатным коммутатором (crossbar switch). Для наглядности все ключи на рисунке изображены в виде механических выключателей, но на самом деле это, конечно же, электронные ключи. В приведенной схеме любой модуль, Qi, может быть соединен с другим модулем, Qj путем замыкания соответствующего ключа. Сети, в которых существует прямое соединение между любой парой узлов, именуются полносвязными. В полносвязной сети может выполняться множество параллельных операций передачи. Если n узлов должны переслать данные n другим узлам, все эти операции могут быть выполнены одновременно. Сеть, в которой операции передачи никогда не блокируются из-за отсутствия свободного пути, называется сетью без блокировок.
На рис. 10.5 в каждой точке пересечения соединений показан единственный ключ. Однако в реальном мультипроцессоре используются более сложные соединения, и поэтому в каждой точке располагается целый набор ключей. В сети, соединяющей n модулей, число точек пересечения равняется n2, поэтому с увеличением количества модулей возрастает и общее число ключей. В результате сеть получается громоздкой и дорогостоящей. По этой причине координатная коммутация обычно применяется для сетей с небольшим количеством узлов.

Рис. 10.5. Сеть с координатной коммутацией
Многоступенчатые сети
В описанных выше системах с общей шиной и координатной коммутацией используется одноступенчатое соединение между любыми двумя модулями. Можно создать такую сеть обмена, в которой соединение между двумя узлами будет формироваться с помощью нескольких ступеней ключей. На рис. 10.6 показана трехступенчатая сеть, соединяющая восемь модулей. Из-за особенностей структуры соединений ее элементов эта сеть получила название коммутационной сети с перетасовкой (shuffle) — по аналогии с перетасовкой игральных карт путем разделения колоды карт на две части и последующего их объединения с чередованием карт из обеих частей.
Каждый прямоугольник на рис. 10.6 представляет собой переключатель 2х2, который может соединить любой из входов с любым из выходов. Кроме того, если оба входа должны быть соединены с разными выходами, он может соединить их как прямо, так и накрест. Если два входа запросили один и тот же выход, может быть удовлетворен только один запрос. Второй запрос блокируется, пока переключатель не освободится. Можно показать, что сеть с s ступенями может использоваться для соединения 2s модулей. В этом случае существует только один путь от модуля Qj, к модулю Qj. Таким образом, сеть обеспечивает соединение между двумя произвольными модулями. Однако она не в состоянии одновременно обслуживать большое количество запросов. Например, соединение между точками Q0 и Q4 может быть установлено одновременно с соединением между точками Q1 и Q5.

Рис. 10.6. Многоступенчатая сеть типа shuffle
Многоступенчатая сеть дешевле сети с координатной коммутацией. Для соединения n узлов по схеме, показанной на рис. 10.6, необходимо s =log2n ступеней с n/2 переключателями на каждой.
Передача запроса по сети выполняется следующим образом. Источник направляет в сеть двоичную последовательность, представляющую адрес приемника. Эта последовательность передается по сети, и на каждой ступени анализируется очередной ее бит, который определяет состояние переключателя. В нашем примере на ступени 1 используется старший бит, на ступени 2 — средний бит, а на ступени 3 — последний, младший бит. Когда запрос поступает на один из входов переключателя, он маршрутизируется к верхнему выходу, если управляющий бит имеет значение 0, или к нижнему выходу в противном случае. Обратите внимание на пример, приведенный на рис. 10.6, где жирной линией показан маршрут следования по сети запроса от источника Q5 приемнику Q3. Этот маршрут определяется двоичной последовательностью 011, составляющей адрес приемника.
Сети с топологией гиперкуба
Во всех трех описанных выше коммутационных схемах передача запросов между двумя модулями происходит с некоторой задержкой. Эти схемы могут использоваться для реализации мультипроцессоров типа UMA. Далее мы рассмотрим топологии, подходящие только для мультипроцессоров типа NUMA. Первая и наиболее популярная сеть этого типа, соединяющая 2n узлов, имеет топологию n-мерного куба, называемую гиперкубом (hypercube). Помимо коммуникационных схем каждый узел обычно содержит процессор и модуль памяти, а также некоторые средства ввода-вывода.
На рис. 10.7 изображен трехмерный гиперкуб. Здесь кружочками обозначены коммуникационные схемы узлов. Соединяемые узлами функциональные устройства на рисунке не показаны. Ребра куба представляют собой двунаправленные связи между соседними узлами. В n-мерном гиперкубе каждый узел непосредственно связан с n соседними узлами. Двоичные адреса узлам удобнее назначать таким образом, чтобы адреса двух соседних узлов отличались единственным битом, как на рис. 10.7.
Маршрутизация сообщений в гиперкубе выполняется очень просто. Передача сообщения от процессора в узле Ni процессору узла Nj происходит следующим образом. Сначала двоичные адреса источника i и приемника j сравниваются, начиная с младшего бита и заканчивая старшим. Предположим, что они отличаются разрядом р. Далее узел Ni передает сообщение своему соседу, адрес которого, k, отличается от i в разряде p. Узел Nk пересылает сообщение своему соседу, используя ту же схему сравнения адресов. После каждой передачи от одного узла к другому сообщение приближается к узлу-приемнику Nj. Например, для передачи сообщения от узла N2 к узлу N5 требуются 3 пересылки, осуществляемые через узлы N3 и n1. Причем именно это количество пересылок соответствует максимальному расстоянию, проходимому сообщением в n-мерном гиперкубе.

Рис. 10.7. Сеть в виде трехмерного гиперкуба
Сканирование адресов назначения в направлении справа налево не является единственным методом маршрутизации сообщений. Может использоваться любая другая схема, при которой с каждой пересылкой от узла к узлу сообщение приближается к месту назначения, а для дальнейшей маршрутизации на каждом узле используется только локальная информация. Если кратчайший путь передачи сообщения не доступен, оно может быть направлено по более длинному пути. Однако при этом следует избегать зацикливания, когда сообщение проходит по замкнутому маршруту и возвращается к исходной точке, так и не достигнув места назначения.
Сети с топологией гиперкуба используются во множестве систем.
Сети с ячеистой топологией
Одним из самых удобных способов соединения большого количества узлов является ячеистая сеть (mesh network). Пример ячеистой сети с 16 узлами приведен на рис. 10.8. Соединения между ее узлами являются двунаправленными. Такие сети завоевали популярность в начале 1990-х годов и стали быстро вытеснять гиперкубические структуры в архитектуре крупных мультипроцессорных систем.
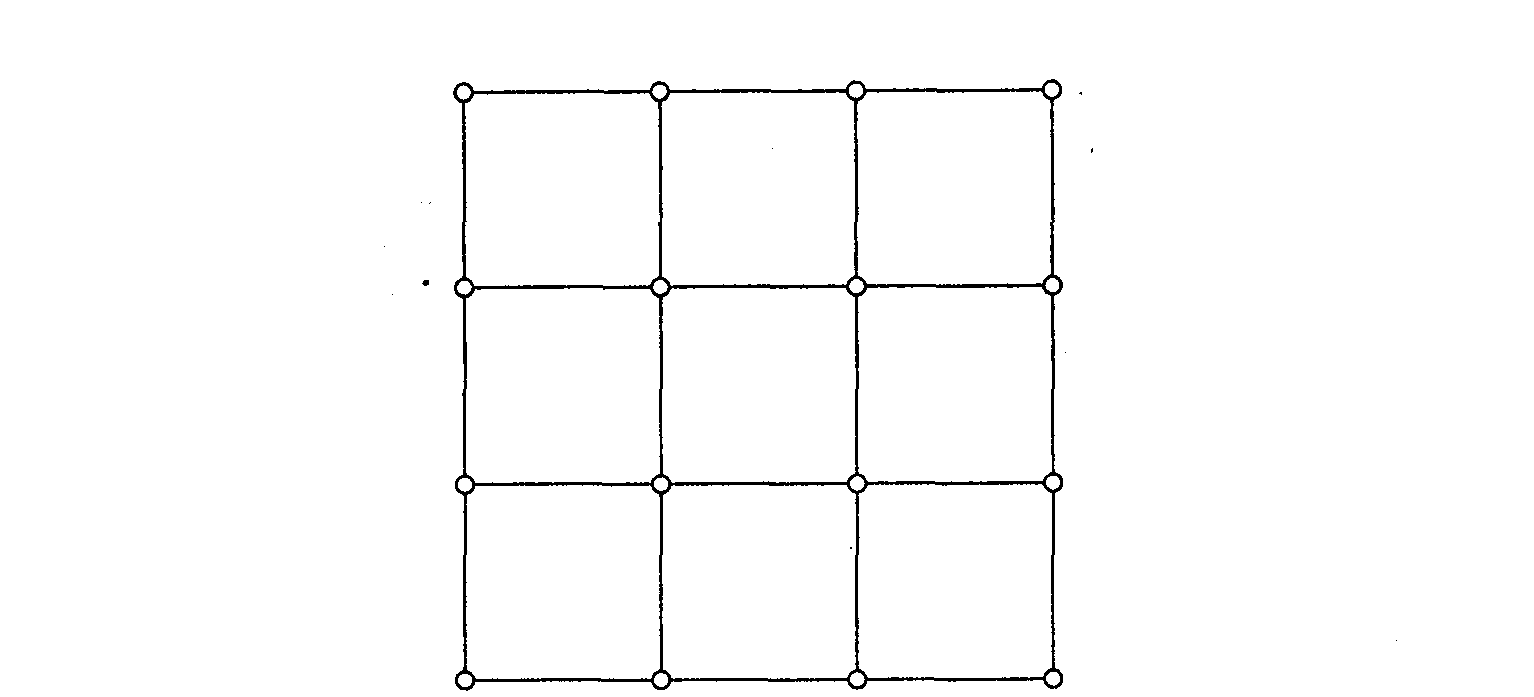
Рис. 10.8. Двухмерная ячеистая сеть
Маршрутизация в ячеистой сети может осуществляться несколькими способами. Один из простейших и наиболее эффективных способов выбора пути между источником Ni и приемником Nj, заключается в том, что сначала выполняется передача данных в горизонтальном направлении от узла Ni к узлу Nj. По достижении столбца, в котором расположен узел Nj, пересылка производится по вертикали. Широко известными примерами мультипроцессорных систем с ячеистой топологией являются компьютер Paragon компании Intel и экспериментальные системы Dash и Flash, разработанные в Стэндфордском университете, а также система Alewife, созданная в Массачуссетском технологическом институте.
Если соединить между собой узлы, находящиеся на противоположных сторонах (рис. 10.8), получится сеть, состоящая из набора двунаправленных горизонтальных колец, соединенных с такими же вертикальными кольцами. В подобных сетях, то есть имеющих тороидальную топологию (torus), значительно сокращается среднее время передачи информации, правда, они сложнее и дороже. Сеть такого типа используется в системах АР3000 компании Fujitsu.
Как обычную, так и тороидальную ячеистую схему можно реализовать в виде трехмерной сети с соединениями между соседними узлами в направлениях Х, Y и Z. Трехмерная тороидальная сеть используется, в частности, в мультипроцессоре Cray T3E.
Сети с древовидной топологией
Еще одной популярной топологией сети обмена является иерархически структурированная сеть в виде дерева. На рис. 10.9, а показано дерево, соединяющее 16 модулей. Каждый родительский узел этого дерева позволяет соединять по два дочерних узла за раз. Узлы промежуточных уровней, такие как узел А, могут соединять один из дочерних узлов с родительским. Таким образом осуществляется взаимодействие между двумя удаленными узлами. Через один узел дерева не может одновременно проходить несколько соединений.
Древовидная сеть хорошо подходит для случаев, когда через корневой узел сети проходит небольшой трафик. Если же трафик возрастает, производительность сети резко снижается, поскольку корневой узел становится ее узким местом. Для повышения пропускной способности сети с древовидной структурой можно увеличить количество соединений на верхних уровнях иерархии. В результате получается толстое дерево (fat tree), где каждый узел имеет более одного родительского узла. Пример сети с топологией толстого дерева показан на рис. 10.9, б. Здесь каждый узел имеет два родительских узла. Подобная сеть использовалась в системе СМ-5 производства Thinking Machines Corporation.

а
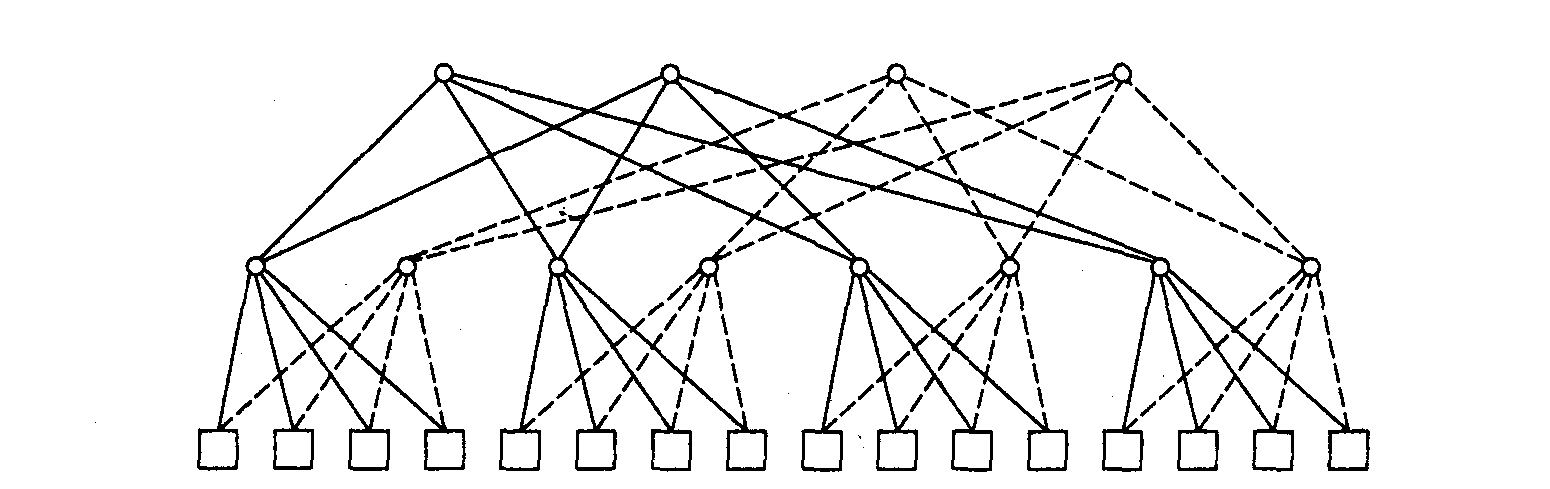
б
Рис. 10.9. Древовидные сети: дерево с четырьмя ветвями (а); толстое дерево (б)
Сеть с кольцевой топологией
Одной из простейших сетевых топологий является кольцевое соединение всех узлов системы (рис. 10.10, а). Главное преимущество такой структуры состоит в простоте ее реализации. Соединения в кольце могут быть достаточно широкими, благодаря чему по ним можно параллельно передавать целый пакет. А вот слишком длинные кольца не эффективны, поскольку среднее время передачи информации между двумя узлами получается слишком большим.
Сети с кольцевой топологией могут служить строительными блоками в топологиях, описанных в предыдущих разделах, в частности в ячеистых, древовидных сетях и гиперкубах. Рассмотрим такой простой пример. При использовании колец в древовидной структуре получается иерархия, показанная на рис. 10.10, б. На этом рисунке изображена двухуровневая иерархия, но возможно и большее количество уровней. В случае использования нескольких маленьких колец вместо одного большого уменьшается задержка при передаче сообщения в пределах кольца, а также задержка во время передачи данных между соседними кольцами. Недостатком этой схемы является то, что кольца верхних уровней нередко становятся узким местом сети, задерживающим значительную часть трафика.

а

б
Рис. 10.10. Сеть с кольцевой топологией: одно кольцо (а); иерархия колец (б)
Сети смешанной топологии
Мы рассмотрели несколько сетевых топологий и попытались описать достоинства и недостатки каждой из них. Разработчики мультипроцессорных систем стараются добиться максимальной производительности за приемлемую стоимость. Поэтому во многих коммерческих системах используются смешанные топологии — их разработчики постарались соединить достоинства нескольких топологий в единой системе. Например, отличным способом объединения нескольких процессоров является комбинация шинной топологии и топологии с координатной коммутацией. Часто встречаются процессорные кластеры, обычно содержащие от 2 до 8 процессоров, соединенные шиной или координатным коммутатором. Такие кластеры выступают в роли узлов сети, объединенных в большую систему с помощью подходящей топологии. В системе AV25000 производства Data General используются кластерные узлы, процессоры которых связаны общей шиной. В единую сеть эти узлы соединяются по кольцевой схеме. В системе Exemplar V2600 производства Hewlett-Packard узлы тоже соединены при помощи кольцевой сети, а процессоры в каждом из них объединены между собой посредством координатного коммутатора. В системе AlphaServer SC производства Compaq узлы сети соединяются в толстое дерево, а процессоры внутри узлов соединены путем координатной коммутации.
Симметричные мультипроцессорные системы
Рассмотрим мультипроцессорную систему, в которой все процессоры имеют одинаковые возможности доступа к модулям памяти и устройствам ввода-вывода, так что с точки зрения операционной системы процессоры являются абсолютно идентичными. Если любой из процессоров может выполнять и ядро операционной системы, и пользовательские программы, система называется симметричной мультипроцессорной системой (Symmetric Multiprocessor, SMP). В такой системе любой процессор может обрабатывать внешние прерывания и инициировать операцию ввода-вывода для любого устройства ввода-вывода.
Симметричные мультипроцессорные системы обычно реализуются на основе шинной сети или сети с координатной коммутацией. Они часто используются в качестве узлов более крупных мультипроцессорных систем. Например, узлы SMP входят в состав описанных выше мультипроцессоров Exemplar V2600 и AlphaServer SC.