

Алгоритм Фокса
Каждый процессор pij вычисляет свой блок матрицы Cij
На каждом процессоре выделяется место для хранения 4-х блоков
Cij – блок результата
Aij – блок матрицы A, который хранится на текущем процессоре
A1ij – блок матрицы A, который получен с другого процессора
B1ij – блок матрицы B, который получен с другого процессора (блоки правой матрицы все время перемещаются)
Выполняется инициализация
C – обнуляется
A – содержит блок матрицы A данного процессора
B1 – содержит блок матрицы B данного процессора

Алгоритм Фокса (продолжение)
На каждой итерации алгоритма, номер l (l=1,k)
Один процессор каждой строки отправляет свой блок матрицы A на все процессоры своей строки, номер столбца j для строки i=(i-l+1)mod(k)+1. Процессоры принимают эти данные в матрицу A1
Выполняется обычное матричное умножение C=C+A1*B1
Матрица B1 передается соседу сверху
Повторяется для следующего l
Передача блоков матрицы A
Передача блоков матрицы B

Оценка времени Алгоритма Фокса
Время одной итерации равно
Время рассылки блока матрицы A1
Время отправки блоков матрицы B1
Время умножения матриц A1 и B1
Время k итераций в k раз больше
Коэффициент ускорения
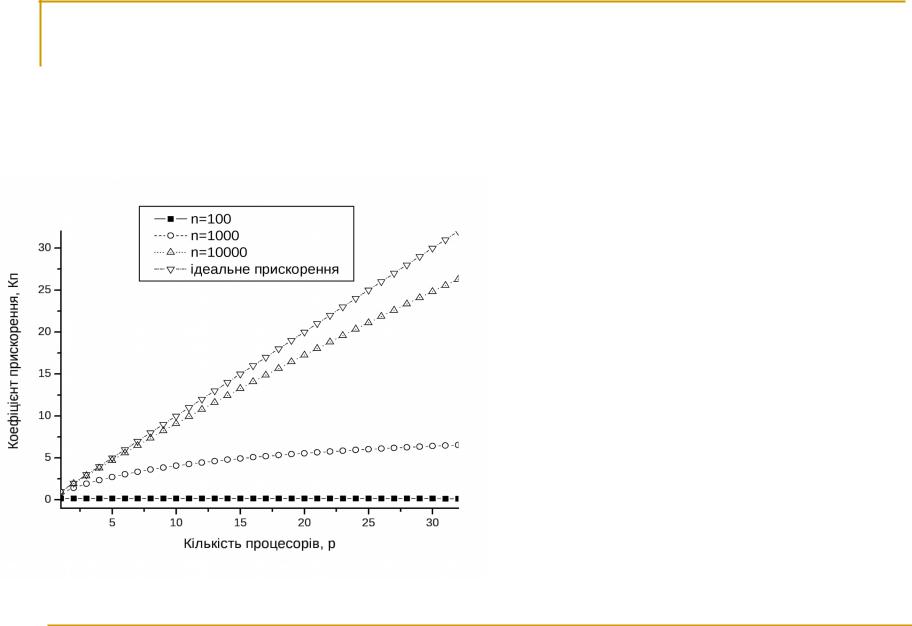
Характеристики
Алгоритм содержит как конвейерные так и параллельные операции
Достаточно эффективен при больших размерностях матрицы
Существуют другие алгоритмы с большим количество синхронных или асинхронных операций

Решение систем линейных уравнений
Есть система линейных уравнений
Матрица A размерности nxn
Матрицы B и x размерности nxm
Матрица x - неизвестна

Методы последовательного исключения неизвестных
Метод Гаусса
Над матрицами A и B выполняются элементарные преобразования, чтобы свести матрицу A к треугольному виду
После чего решение находится с помощью обратного хода метода Гаусса
Исключение неизвестных
В каждой строке выбирается ведущий элемент – самый большой по модулю
Текущая строка вычитается из всех расположенных ниже, нормированных на ведущий элемент
При этом на месте ведущего элемента во всех ниже расположенных строках будут нули

Последовательная
программа
// прямий хід |
//зворотній хід |
//k- нумерує кроки виключення |
for(i=n-1; i>=0; i--){ |
//i- нумеує рядки |
for(l=n;l<n+m;l++){ |
//j – нумерує стовпці матриці A |
for(j=i+1;j<n;j++) |
//l – нумерує стовпці матриці B |
a[i][l]-=a[j][l]*a[i][j]; |
for(k=0;k<n-1; k++){ |
a[i][l]/=a[i][i]; |
for(i=k+1;i<n; i++){ |
} |
a[i][k]/=a[k][k]; |
} |
// ділення на ведучий елемент |
|
// виключення матриць A і B |
|
for(j=k+1;j<n+m;++) |
|
a[i][j]-=a[i][k]*a[k][j]; |
|
} |
|
} |
|
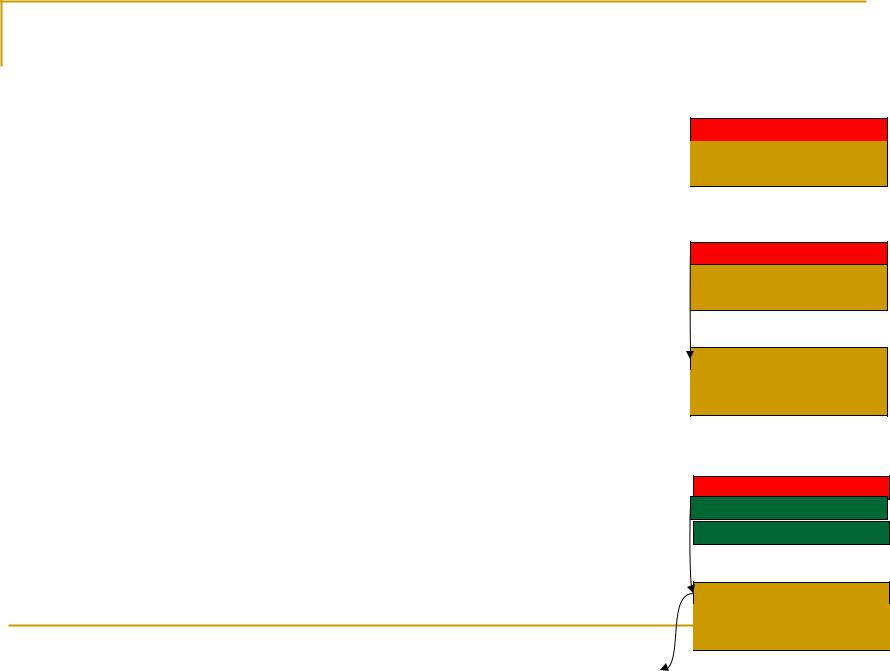
Распараллеливание прямого хода
Строки распределяются по процессорам равномерно, каждый процессор содержит n/p строк, i-й процессор содержит строки с номерами i+kp (k=1,n/p)
Передачу лучше выполнить конвейерно по принципу привилегированной передачи
Первый процессор находит ведущий элемент, вычисляет результат деления своей строки на ведущий элемент
Результат деления и номер ведущего элемента пересылается на следующий процессор
Первый процессор продолжает исключение своих строк
Второй процессор принимает данные от первого , выполняет исключение и тоже передает данные дальше
Процессор1 Ведущий элемент
Процессор1 Передача следующему
Процессор2
Процессор1 Исключение и передача
Процессор2

Реализация
// прямий хід
//k- нумерує кроки виключення //i- нумерує рядки
//j – нумерує стовпці матриці A //l – нумерує стовпці матриці B //p - кількість процсорів
//c – номер поточного процесора //cur – поточний рядок for(k=0;k<n; k++){
if(k%p == c){
// поточний рядок у нас
cur=a[k];
} else {
//прийняти поточний рядок від попереднього в кільці recv(c>0?c-1:p-1,cur);
}
//передати поточний рядок наступному в кільці if(k<n-1)
send(c<p-1?c+1:0,cur);
// кожен процесор містить n/p рядків
for(i=0;i<n/p; i++){
//ділення на ведучий елемент a[i][k]/=cur[k];
// виключення елементів матриць A і B for(j=k+1;j<n+m;++)
a[i][j]-=a[i][k]*cur[j];
}
}
//зворотній хід //кожен процессор має зберігати всі попередні //значення x[i][l]
//кожен процесор виконує n/p виключень
for(i=n+c-p; i>=c; i-=p){
//отримуємо всі обраховані попередні значення x for(j=(i+p)>(n-1)?(n-1):(i+p);j>i;j++){
//всі інші значення x вже отримані recv(c<p-1?c+1:0,x[j])
if(i>0) send(c>0?c-1:p-1,x[j]);
}
for(l=0;l<m;l++){ for(j=i+1;j<n;j++)
a[i][n+l]-=x[j][l]*a[i][j]; a[i][n+l]/=a[i][i];
x[i]=a[i]+n
// відправляємо обрахований рядок if(i>0)
send(c>0?c-1:p-1,a[i]);
}
}

Другие алгоритмы передачи
Обычное кольцо
Модифицированное кольцо
Двойное кольцо
Модифицированное двойное кольцо